1.介绍
t-sne 是一种探索高维数据 (high-dimensional data) 的方法,其多用于机器学习 (machine learning), 此方法可以将高维数据通过低维[一般是2-D]的形式展现出来。
2.使用
这里介绍 python 中的 sklearn.manifold.TSNE
class sklearn.manifold.TSNE(n_components=2, *, perplexity=30.0,
early_exaggeration=12.0, learning_rate='warn', n_iter=1000,
n_iter_without_progress=300, min_grad_norm=1e-07, metric='euclidean',
metric_params=None, init='warn', verbose=0, random_state=None,
method='barnes_hut',angle=0.5, n_jobs=None, square_distances='deprecated'n_components: 嵌入空间的维度,默认为2。
perplexity: 与 nearest neighbor 的数量有关,一般为5-50,不能大于数据的样本点数量。
early_exaggeration: 控制原始空间中的自然簇在嵌入空间中的紧密程度以及它们之间的空间大小。
learning_rate: 学习率,一般选择范围为 [10.0,1000.0]。
n_iter: 达到最优化结果的迭代次数。
n_iter_without_progress: 在终止优化之前无进程的最大迭代次数。原文:(Maximum number of iterations without progress before we abort the optimization, used after 250 initial iterations with early exaggeration.)
min_grad_norm: 梯度的阀值,低于该值则会停止算法。
metric: 计算距离用的度量。
metric_params: 度量的参数。
init: 嵌入的初始化。
verbose: verbose 日志的级别,共 0-9十个级别。
random_state: 确定随机数生成器 (random number generator)。
method: 梯度计算的算法。
angle: 只有在 method='barnes_hut' 时使用,是一种对于此算法速度和准确率的平衡参数。
n_jobs: 近邻搜索时同时进行的工作进程数量。
square_distances: 现在的版本已经用不到这个参数了。
>>> import numpy as np
>>> from sklearn.manifold import TSNE
>>> X = np.array([[0, 0, 0], [0, 1, 1], [1, 0, 1], [1, 1, 1]])
>>> X_embedded = TSNE(n_components=2, learning_rate='auto',
...
init='random', perplexity=3).fit_transform(X)
>>> X_embedded.shape
(4, 2)一个简单的例子
methods
fit(X): 将X嵌入embedded space
X 是shape为(n_samples, n_features)或者 (n_samples, n_samples) 的 ndarray
fit_transform(X): 将X嵌入embedded space 并返回转换的结果(transformed output)
get_params(deep = True): 获取 estimator 的参数
set_params(**params): 设置 estimator 的参数
3. 关于perplexity
'perplexity' 是一个可调整的全局参数,也是我认为最关键的参数,它可以粗略地表示数据在局部 (local) 和整体 (global) 方面平衡注意力。从意义上来讲的话,它描述了一种猜测,每个点周围有几个近距离的近邻点(close neighbors) 。 一般情况下,会选择 5-50 作为perplexity的值,但有时需要更大的值。
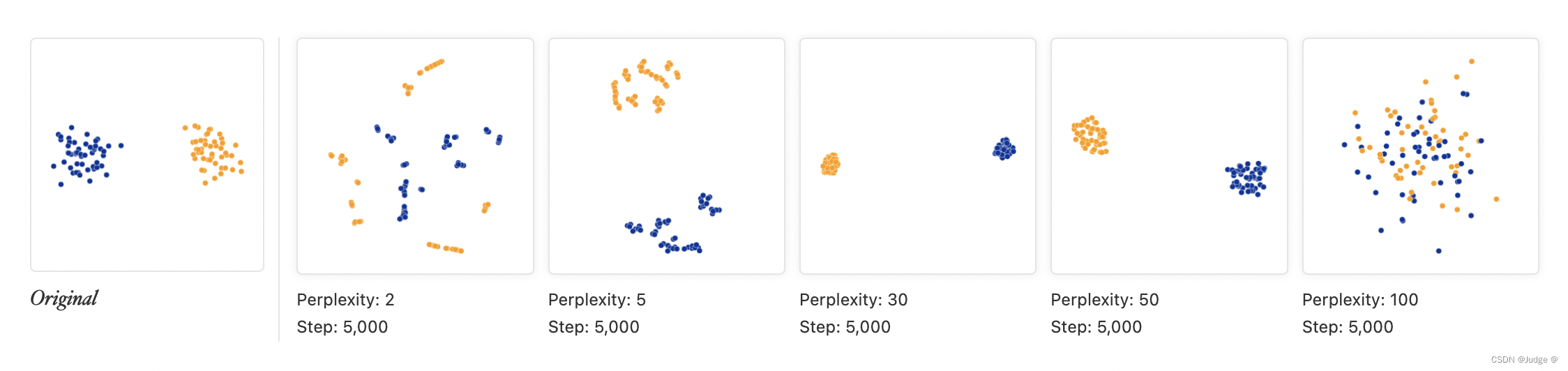
上图表示了在两个类的情况下,数据被表示在2-D平面的例子。可以看到在 perplexity = 2 时,局部变化占主导地位,而 perplexity = 100 时,很难看出什么结果。在5,30,50的情况下,可以看到图像清晰表示出了两个不同的类。
4. t-SNE的一些特性
1.如果数据不同cluster之间的标准差 (standard deviation)不一样,在 t-SNE 处理后的图像上并不会有什么差异(对比相同情况下相同标准差的cluster)
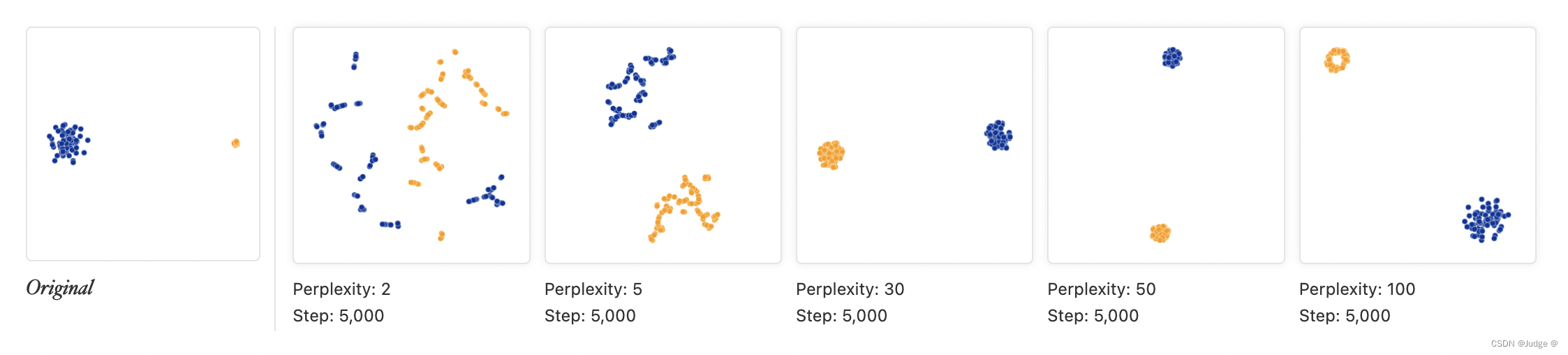
可以对比第一幅图,发现经过 t-SNE 后,两种情况下的表示相似。
这是由于 t-SNE 算法会让距离的概念自动适应区域密度变化(regional density variations)。所以会让集群的大小趋于平衡。
2.在t-SNE 处理后产生的簇直接的距离并不能表示实际情况下的距离,下面两幅图分别展示了相同情况下的三簇高斯分布的点经过 t-SNE 处理后的结果,唯一的不同是第一幅图每一簇有50个点,而第二幅图有200个。
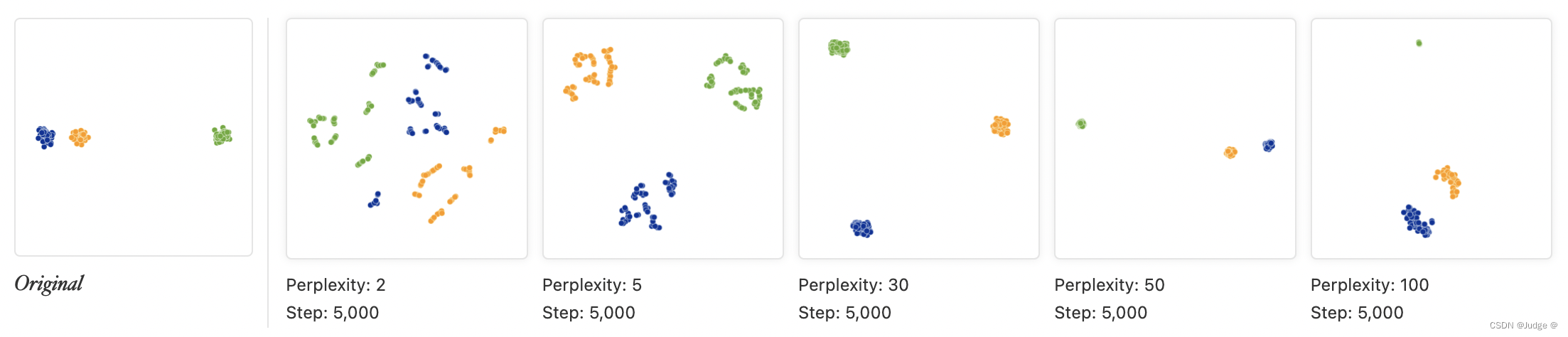
 可以看到,t-SNE 表示的图像,clusters 之间的距离并不相同。
可以看到,t-SNE 表示的图像,clusters 之间的距离并不相同。
References
1.Visualizing data using t-SNE, Maaten, L.v.d. and Hinton, G., 2008. Journal of Machine Learning Research, Vol 9(Nov), pp. 2579—2605.
2. Wattenberg, et al., "How to Use t-SNE Effectively", Distill, 2016. http://doi.org/10.23915/distill.00002
最后
以上就是明亮云朵最近收集整理的关于关于t-SNE(T-distributed Stochastic Neighbor Embedding) t-分布随机近邻嵌入的简单理解的全部内容,更多相关关于t-SNE(T-distributed内容请搜索靠谱客的其他文章。
![[4G&5G专题-85]:架构 - 4G LTE 空口信道映射与信道内部处理流程](https://www.shuijiaxian.com/files_image/reation/bcimg10.png)







发表评论 取消回复