一、概述
1、架构
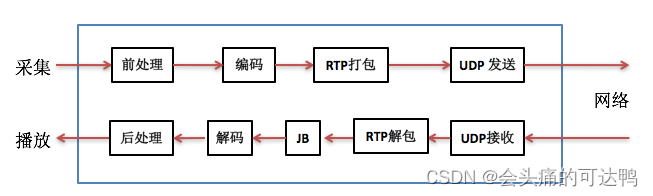
上图中发送方(或叫上行、TX)将从MIC采集到的语音数据先做前处理,然后编码得到码流,再用RTP打包通过UDP socket发送到网络中给对方。接收方(或叫下行、RX)通过UDP socket收语音包,解析RTP包后放入jitter buffer中,要播放时每隔一定时间从jitter buffer中取出包并解码得到PCM数据,做后处理后送给播放器播放出来。
二、NetEQ
1、简介
netEQ是webRTC中音频技术方面的两大核心技术之一,webRTC是Google收购GIPS重新包装后开源出来的,netEQ有两大模块,MCU(micro control unit, 微控制单元)和DSP(digital signal processing, 信号处理单元,
netEQ有两大核心技术点,一、解决时延、抖动,二、信号处理(加速(accelerate)、减速(preemptive expand)、丢包补偿(PLC)、融合(merge)和背景噪声生成(BNG))
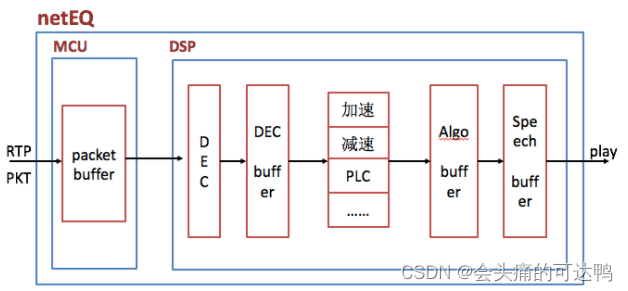
MCU负责控制从网络收到的语音包在jitter buffer里的插入和提取,同时控制DSP模块用哪种算法处理解码后的PCM数据,
DSP负责解码以及解码后的PCM信号处理,主要PCM信号处理算法有加速、减速、丢包补偿、融合等),MCU模块在CP (communication processor, 通讯处理器)上做,两个模块之间通过消息交互。
2、架构
把jitter buffer和decoder综合起来并加入解码后的PCM信号处理形成
即netEQ = jitter buffer + decoder + PCM信号处理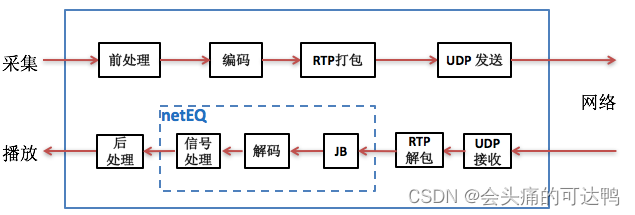
3、处理流程
(1)、RTP语音包插入packet packet
A、在收到第一个RTP语音包后初始化netEQ
B、解析RTP语音包,将其插入到packet buffer中。在插入时根据收到包的顺序依次插入,到尾部后再从头上继续插入。这是一种简单的插入方法。
C、计算网络延时optBufLevel
(2)、packet buffer中提取语音包解码和PCM信号处理
A、将DSP模块的endTimeStamp赋给playedOutTS,和sampleLeft(语音缓冲区中未播放的样本数)一同传给MCU,告诉MCU当前DSP模块的播放状况。
B、看是否要从packet buffer里取出语音包,以及是否能取出语音包。取出包时用的是遍历整个packet buffer的方法,根据playedOutTS找到最小的大于等于playedOutTS的时间戳,记为availableTS,将其取出来。如果包丢了就取不到包。
C、算抖动缓冲延时buffLevelFilt。
D、根据网络延时抖动缓冲延时以及上一帧的处理方式等决定本次的MCU控制命令。
E、如果有从packet buffer里提取到包就解码,否则不解码。
F、根据MCU给的控制命令对解码后的以及语音缓冲区里的数据做信号处理。
4、MCU、DSP
(1)、MCU
MCU单元主要负责把从网络侧收到的语音包经过RTP解析后往packet buffer里插入(insert),以及从packet buffer 里提取(extract)语音包给DSP单元做解码、信号处理等,同时也算网络延时(optBufLevel)和抖动缓冲延时(buffLevelFilt),根据网络延时和抖动缓冲延时以及其他因素(上一帧的处理方式等)决定给DSP单元发什么信号处理命令
jitter buffer(也就是packet buffer,后面就跟netEQ一致,表述成packet buffer,用于去除网络抖动)模块在MCU单元内,decoder和PCM信号处理模块在DSP单元内。
(2)、DSP单元
负责解码和PCM信号处理。从packet buffer提取出来的码流解码成PCM数据放进decoded_buffer中,然后根据MCU给出的命令做信号处理,处理结果放在algorithm_buffer中,最后将algorithm_buffer中的数据放进speech_buffer待取走播放。
Speech_buffer中数据分两块,一块是已播放过的数据(playedOut),另一块是未播放的数据(sampleLeft), curPosition就是这两种数据的分割点。另外还有一个变量endTimestamps用于记录最后一个样本的时间戳,并报告给MCU,让MCU根据endTimestamps和packet buffer里包的timestamp决定是否要能取出包以及是否要取出包。
(3)、信号处理命令
A、正常播放,即不需要做信号处理
B、加速播放,用于通话延时较大的情况,通过加速算法使语音信息不丢而减少语音时长,从而减少延时
C、减速播放,用于语音断续情况,通过减速算法使语音信息不丢而增加语音时长,从而减少语音断续
D、丢包补偿,通过丢包补偿算法把丢掉的语音补偿回来
E、融合(merge),用于前一帧丢包而当前包正常收到的情况,由于前一包丢失用丢包补偿算法补回了语音,与当前包之间需要做融合处理来平滑上一补偿的包和当前正常收到的语音包
(4)、源码导读
class NetEq {
public:
struct Config {
Config();
Config(const Config&);
Config(Config&&);
~Config();
Config& operator=(const Config&);
Config& operator=(Config&&);
std::string ToString() const;
int sample_rate_hz = 16000; // 初始值。 会随着输入数据而改变
bool enable_post_decode_vad = false;
size_t max_packets_in_buffer = 200; // 最大包数
int max_delay_ms = 0; // 最大延迟
int min_delay_ms = 0; // 最小延迟
bool enable_fast_accelerate = false; // 启用快速加速
bool enable_muted_state = false; // 启用静音状态
bool enable_rtx_handling = false; // 启用 rtx 处理
absl::optional<AudioCodecPairId> codec_pair_id; // 音频编解码器ID
bool for_test_no_time_stretching = false; // 用于测试没有时间拉伸
// 为 NetEq 的输出增加额外的延迟,而不会影响抖动或丢失行为。 这主要是为了测试。 值必须是 10 毫秒的非负倍数
int extra_output_delay_ms = 0;
};
// 返回值
enum ReturnCodes { kOK = 0, kFail = -1 };
// 操作
enum class Operation {
kNormal, //
kMerge, // 合并
kExpand, // 展开
kAccelerate, // 加速
kFastAccelerate, // 快速加速
kPreemptiveExpand, // 抢占式展开
kRfc3389Cng,
kRfc3389CngNoPacket,
kCodecInternalCng, //编解码器内部Cng
kDtmf,
kUndefined,
};
// 模式
enum class Mode {
kNormal,
kExpand,
kMerge,
kAccelerateSuccess, // 加速成功
kAccelerateLowEnergy, // 加度低能耗
kAccelerateFail, // 加速失败
kPreemptiveExpandSuccess, // 抢先扩张成功
kPreemptiveExpandLowEnergy, // 抢先扩张低能耗
kPreemptiveExpandFail, // 抢先扩张失败
kRfc3389Cng,
kCodecInternalCng,
kCodecPlc,
kDtmf,
kError,
kUndefined,
};
// GetDecoderFormat返回类型
struct DecoderFormat {
int sample_rate_hz; // 采样率
int num_channels; // 声道数
SdpAudioFormat sdp_format; // 格式
};
// 创建一个新的 NetEq对象,参数设置在|config|中。|config|对象只需在调用此方法的持续时间内有效
static NetEq* Create(
const NetEq::Config& config,
Clock* clock,
const rtc::scoped_refptr<AudioDecoderFactory>& decoder_factory);
virtual ~NetEq() {}
// 在Neteq中插入新的包
// 成功返回0,失败返回-1
virtual int InsertPacket(const RTPHeader& rtp_header,
rtc::ArrayView<const uint8_t> payload) = 0;
// 让NetEq知道数据包到达时带有空负载。
// 通常发生在使用空数据包探测网络通道时
// 这些数据包使用与实际音频数据包相同系列的RTP序列号
virtual void InsertEmptyPacket(const RTPHeader& rtp_header) = 0;
// 指示NetEq传送10毫秒的音频数据。数据写入|audio_frame|---数据将被初始化
// |data_|、|speech_type_|、|num_channels_|、|sample_rate_hz_|、
// |samples_per_channel_| 和 |vad_activity_| 成功后更新
// 如果返回错误,则某些字段可能尚未更新,或者可能包含不一致的值。
// 如果启用静音状态(通过 Config::enable_muted_state),|muted|可能会在延长扩展期后设置为true
// 当这种情况发生时,|data_|在|audio_frame|未写入,但应解释为全为零。
// 出于测试目的,可以在 |action_override| 中提供覆盖。 参数,这将导致 NetEq 下一步执行此操作,而不是它通常选择的操作
// 成功时返回 kOK,错误时返回 kFail
virtual int GetAudio(
AudioFrame* audio_frame,
bool* muted,
absl::optional<Operation> action_override = absl::nullopt) = 0;
// 设置解码器
virtual void SetCodecs(const std::map<int, SdpAudioFormat>& codecs) = 0;
// 注册有效载荷类型
// |rtp_payload_type| 使用给定的编解码器
// NetEq将在需要时实例化。如果成功则返回 true
virtual bool RegisterPayloadType(int rtp_payload_type,
const SdpAudioFormat& audio_format) = 0;
// 删除|rtp_payload_type|来自编解码器数据库。 成功返回 0,
// 失败返回-1,删除未注册的有效负载类型是可以的,不会导致错误。
virtual int RemovePayloadType(uint8_t rtp_payload_type) = 0;
// 从编解码器数据库中删除所有负载类型
virtual void RemoveAllPayloadTypes() = 0;
// 设置最小延迟
// 设置数据包缓冲区的最小延迟(以毫秒为单位)。 除非通道条件要求更高的延迟,否则将保持最小值。
// 如果成功应用最小值,则返回 true,否则返回 false。
virtual bool SetMinimumDelay(int delay_ms) = 0;
// 设置最小延迟
// 设置数据包缓冲区的最大延迟(以毫秒为单位)
// 延迟不会超过给定值,即使需要的延迟(给定信道条件)更高
// 调用该方法与设置|max_delay_ms|效果相同。NetEq::Config 结构中的值。
virtual bool SetMaximumDelay(int delay_ms) = 0;
// 设置数据包缓冲区的基本最小延迟(以毫秒为单位)
// 通过|SetMinimumDelay|设置的最小延迟不能低于基本最小延迟
// 调用该方法类似于设置|min_delay_ms| NetEq::Config 结构中的值。 如果成功应用了基本最小值,则返回 true,否则返回 false。
virtual bool SetBaseMinimumDelayMs(int delay_ms) = 0;
// 以毫秒为单位返回基本最小延迟的当前值
virtual int GetBaseMinimumDelayMs() const = 0;
// 以毫秒为单位返回当前目标延迟。 这包括通过 SetMinimumDelay 请求的任何额外延迟
virtual int TargetDelayMs() const = 0;
// 以毫秒为单位返回当前的总延迟(数据包缓冲区和同步缓冲区)
// 并应用平滑以消除由于抖动造成的短时间波动。在 DTX/CNG 期间不会更新延迟的数据包缓冲区部分
virtual int FilteredCurrentDelayMs() const = 0;
// 将当前网络统计信息写入 |stats|。 通话结束后,统计数据被重置
virtual int NetworkStatistics(NetEqNetworkStatistics* stats) = 0;
// 仅当前值,不重置任何状态
virtual NetEqNetworkStatistics CurrentNetworkStatistics() const = 0;
// 返回此类的生命周期统计信息的副本。 这些统计信息永远不会重置。
virtual NetEqLifetimeStatistics GetLifetimeStatistics() const = 0;
// 返回有关已执行操作和内部状态的统计信息。 这些统计信息永远不会重置。
virtual NetEqOperationsAndState GetOperationsAndState() const = 0;
// 启用解码后VAD。启用后,当信号不包含语音时,GetAudio()将返回 kOutputVADPassive。
virtual void EnableVad() = 0;
// 禁用解码后VAD
virtual void DisableVad() = 0;
// 返回 GetAudio()提供的最后一个样本的RTP时间戳。
// 如果没有可用的有效时间戳,则返回值将为空
virtual absl::optional<uint32_t> GetPlayoutTimestamp() const = 0;
// 返回上次 GetAudio 调用中产生的音频的采样率(以Hz为单位)
// 如果尚未调用 GetAudio,则返回配置的采样率 (Config::sample_rate_hz)。
virtual int last_output_sample_rate_hz() const = 0;
// 返回给定负载类型的解码器信息。 如果未注册此类有效负载类型,则返回空。
virtual absl::optional<DecoderFormat> GetDecoderFormat(
int payload_type) const = 0;
// 刷新数据包缓冲区和同步缓冲区
virtual void FlushBuffers() = 0;
// 启用 NACK 并设置 NACK 列表的最大大小,该大小应为正且不大于 Nack::kNackListSizeLimit。
// 如果 NACK 已启用,则相应地修改最大 NACK 列表大小
virtual void EnableNack(size_t max_nack_list_size) = 0;
// 关闭NACK
virtual void DisableNack() = 0;
// 返回与要重新传输的数据包相对应的RTP序列号列表,给出以毫秒为单位的往返时间的估计
virtual std::vector<uint16_t> GetNackList(
int64_t round_trip_time_ms) const = 0;
// 返回一个向量,其中包含在上次 GetAudio 调用中解码的数据包的时间戳
// 如果在上次调用中没有解码包,则向量为空。 主要用于测试。
virtual std::vector<uint32_t> LastDecodedTimestamps() const = 0;
// 返回同步缓冲区中尚未播放的音频长度。主要用于测试
virtual int SyncBufferSizeMs() const = 0;
};三、音频后处理(3A算法)
1、AEC
2、ANS
3、AGC
最后
以上就是激昂小蝴蝶最近收集整理的关于Webrtc音频技术(未完)的全部内容,更多相关Webrtc音频技术(未完)内容请搜索靠谱客的其他文章。








发表评论 取消回复