作者 | 东田应子
【导读】本文是深度学习之视频人脸识别系列的第一篇文章,介绍了人脸识别领域的一些基本概念,分析了深度学习在人脸识别的基本流程,并总结了近年来科研领域的研究进展,最后分析了静态数据与视频动态数据在人脸识别技术上的差异。
一、基本概念
- 人脸识别(face identification)
人脸识别是1对n的比对,给定一张人脸图片,如何在n张人脸图片中找到同一张人脸图片,相对于一个分类问题,将一张人脸划分到n张人脸中的一张。类似于管理人员进行的人脸识别门禁系统。
2.人脸验证(face verification)
人脸验证的1对1的比对,给定两张人脸图片,判断这两张人脸是否为同一人,类似于手机的人脸解锁系统,事先在手机在录入自己的脸部信息,然后在开锁时比对摄像头捕捉到的人脸是否与手机上录入的人脸为同一个人。
3.人脸检测(face detection)
人脸检测是在一张图片中把人脸检测出来,即在图片上把人脸用矩形框出来,并得到矩形的坐标,如下图所示。

、
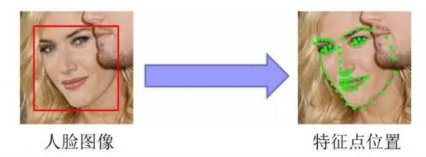
4.人脸关键点检测
根据输入的人脸图像,识别出面部关键特征点,如眼睛、鼻尖、嘴角点、眉毛以及人脸各部件轮廓点的坐标,如下图所示。
5.人脸矫正(人脸对齐)
通过人脸关键点检测得到人脸的关键点坐标,然后根据人脸的关键点坐标调整人脸的角度,使人脸对齐,由于输入图像的尺寸是大小不一的,人脸区域大小也不相同,角度不一样,所以要通过坐标变换,对人脸图像进行归一化操作,如下图所示。

二、基于深度学习的人脸识别算法基本流程
随着神经网络的迅速发展和其对图像数据的强大的特征提取,深度学习运用于人脸识别也成为热点研究方向;2014年的开山之作DeepFace,第一个真正将大数据和深度学习结合应用于人脸识别与验证,确立人脸识别的常规流程:图片->人脸与关键点检测->人脸对齐->人脸表征(representation)->分类。首先将图片中的人脸检测处理并通过关键点进行对齐,如何输入到神经网络,得到特征向量,通过分类训练过程,该向量即为人脸的特征向量。要求出两张人脸的相似度即计算两个特征的向量度量之差,方法包括:SVM、SiameseNetwork、JointBayesian、L1距离、L2距离、cos距离等。
三、科研领域近期进展
科研领域近期进展主要集中于loss函数的研究,包括DeepId2(Contrastive Loss)、FaceNet(Triplet loss)、L-Softmax、SphereFace(A-Softmax)、Center Loss、L2-Softmax、NormFace、CosFace(AM-Softmax)、ArcFace(AA-Softmax)等。
四、基于视频人脸识别和图片人脸识别的区别(该小结部分参考于博客园 - 米罗西)
相对于图片数据,目前视频人脸识别有很多挑战,包括:(1)视频数据一般为户外,视频图像质量比较差;(2)人脸图像比较小且模糊;(3)视频人脸识别对实时性要求更高。
但是视频数据也有一些优越性,视频数据同时具有空间信息和时间信息,在时间和空间的联合空间中描述人脸和识别人脸会具有一定提升空间。在视频数据中人脸跟踪是一个提高识别的方法,首先检测出人脸,然后跟踪人脸特征随时间的变化。当捕捉到一帧比较好的图像时,再使用图片人脸识别算法进行识别。这类方法中跟踪和识别是单独进行的,时间信息只在跟踪阶段用到。
【总结】:本期文章主要介绍了基于深度学习的人脸识别算法的一些基本入门知识,下一期我给大家介绍人脸识别中获取神经网络输入的算法,即关于人脸检测、人脸关键点检测与人脸对齐的一些重要算法和相关论文解析。
人脸矫正(人脸对齐)
通过人脸关键点检测得到人脸的关键点坐标,然后根据人脸的关键点坐标调整人脸的角度,使人脸对齐,由于输入图像的尺寸是大小不一的,人脸区域大小也不相同,角度不一样,所以要通过坐标变换,对人脸图像进行归一化操作,如下图所示。
最后
以上就是无限帆布鞋最近收集整理的关于深度学习之视频人脸识别系列一:介绍的全部内容,更多相关深度学习之视频人脸识别系列一内容请搜索靠谱客的其他文章。








发表评论 取消回复