文章目录
- 功耗:CPU的人体极限
- 并行优化,阿姆达尔定律
- 总结
CPU性能中,程序的CPU执行时间公式如下
程序的 CPU 执行时间 = 指令数 × CPI × Clock Cycle Time
提升计算机的性能,从指令数、CPI以及CPU主频入手。
功耗:CPU的人体极限
奔腾 4 的 CPU 主频从来没有达到过 10GHz,最终它的主频上限定格在 3.8GHz,是因为它的功耗问题
一个 3.8GHz 的奔腾 4 处理器,满载功率是 130 瓦,CPU 安在手机里面,不考虑屏幕内存之类的耗电,这个 CPU 满载运行 45 分钟,充电宝里面就没电了。
iPhone X 使用 ARM 架构的 CPU,功率则只有 4.5 瓦左右。
CPU(被叫作超大规模集成电路(Very-Large-Scale Integration,VLSI))。这些电路都是一个个晶体管组合成的。
CPU 在计算,其实就是让晶体管里面的“开关”不断地去“打开”和“关闭”,来组合完成各种运算和功能。想要计算得快,
- 增加密度。在 CPU 里,同样的面积里面,多放一些晶体管
- 提升主频。让晶体管“打开”和“关闭”得更快一点
这两者,都会增加功耗,带来耗电和散热的问题。
CPU里能够放下的晶体管数量和晶体管的开关频率都是有限的,CPU的功率公式如下:
功耗 ~= 1/2 ×负载电容×电压的平方×开关频率×晶体管数量
提升性能的时候,需要不断增加晶体管的数量,同样面积下要多放一些晶体管,也即是把晶体管造的小一点,这个就是平时所说的制程,比如28nm。
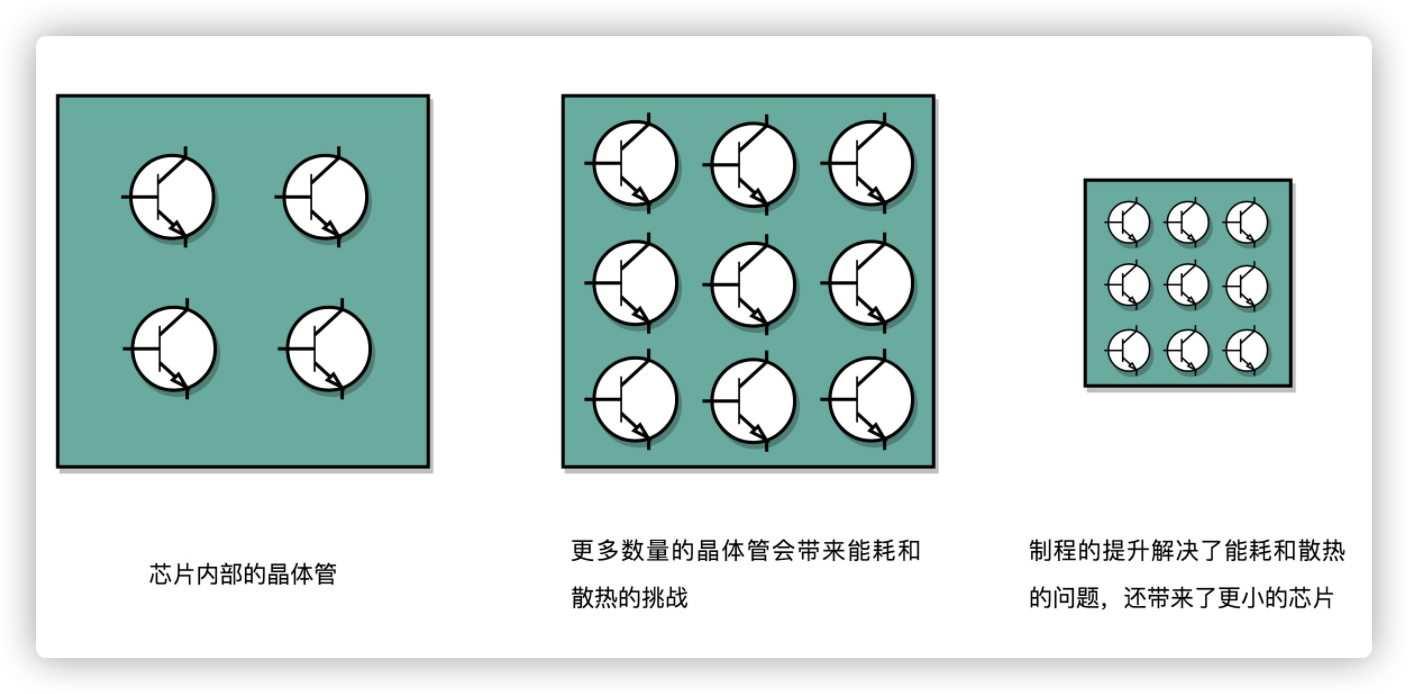
功耗太多,会导致CPU散热跟不上,这个时候需要减低电压,功耗是和电压的平方成正比,电压下降1/5,功耗变为原来1/25。
并行优化,阿姆达尔定律
不是所有问题,都可以通过并行提高性能来解决,需要满足以下几个条件
- 需要进行的计算,本身可以分解成为几个可以并行的任务。
- 分解好的问题解决完之后,能够将结果汇总在一起
- 汇总阶段,没有办法并行执行,需要顺序执行。
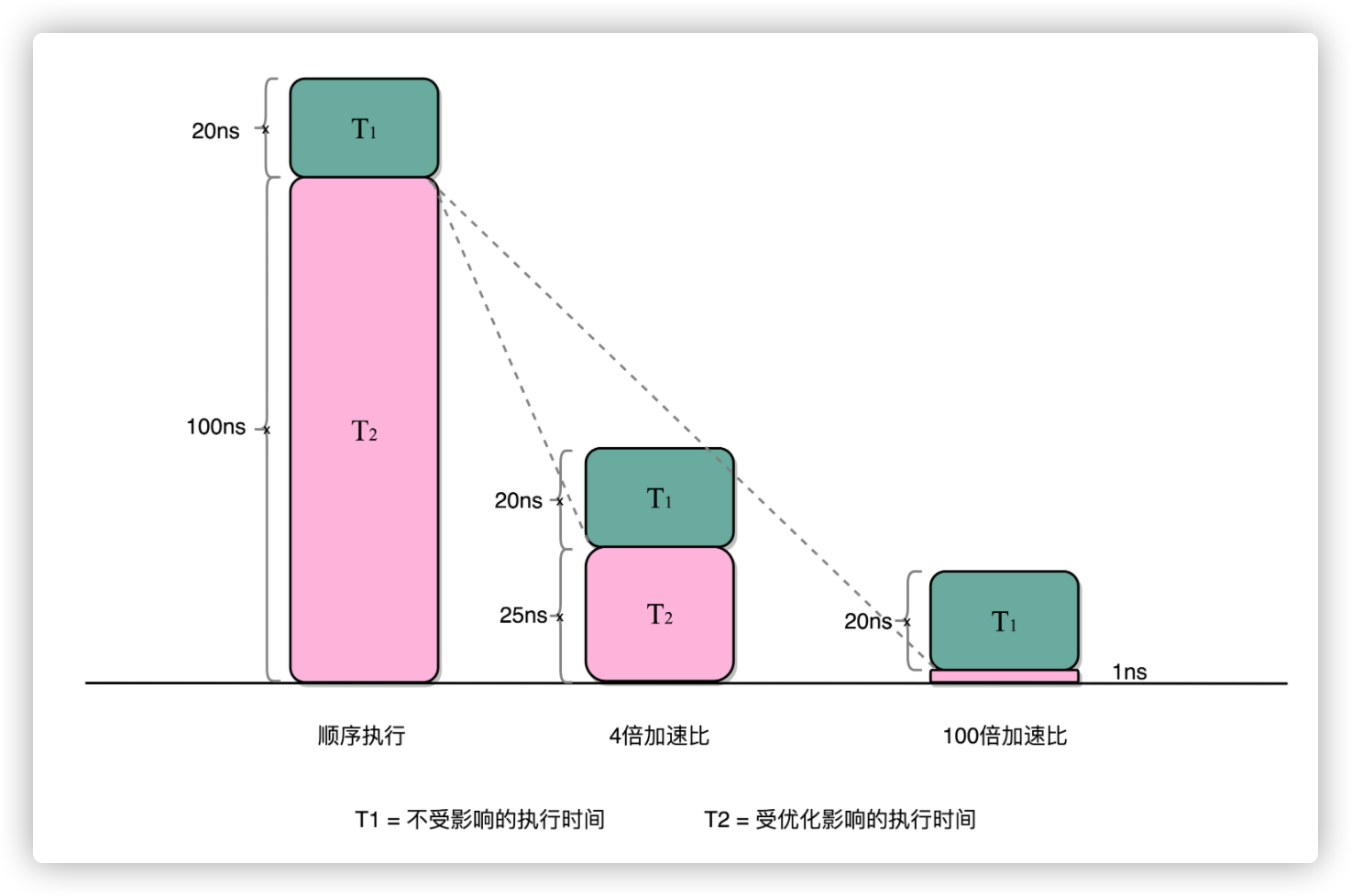
对于一个程序优化之后,处理器并行运算之后效率提升的情况,就是阿姆达尔定律,可以用公式
优化后的执行时间 = 受优化影响的执行时间 / 加速倍数 + 不受影响的执行时间
总结
- 加速大概率事件。深度学习整个计算过程中,99% 都是向量和矩阵计算,所以通过用GPU代替CPU,大幅提升深度学习模型训练的过程。
- 通过流水线提高性能。现代 CPU 里是如何通过流水线来提升性能的,以及过长的流水线会带来什么新的功耗和效率上的负面影响。
- 通过预测提高性能。预先猜测下一步该干什么,而不是等上一步运行的结果,提前进行运算,也是让程序跑得更快一点的办法。
最后
以上就是温婉枫叶最近收集整理的关于穿越功耗墙,从哪些方面提升性能?的全部内容,更多相关穿越功耗墙内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复