“Talk is cheap, show me the code.” 废话少说,上代码!
In probability theory and statistics, the Gumbel distribution (Generalized Extreme Value distribution Type-I) is used to model the distribution of the maximum (or the minimum) of a number of samples of various distributions.
Gumbel:MATLAB程序:(放入主程序.m文件同路径下即可调用)
function [Recurrence_period_value] = Gumble_func_by_zlf(data,N,len)
% data应为一列数据
% N为多少年一遇
% len为所用数据年数(从大到小排序后希望获得前几个数据)
% Recurrence_period_value为N年一遇值
datasort = sort(data,'descend');
datasort(isnan(datasort))=[];%剔除缺测值
data_select_sort = datasort(1:len);
mu = mean(data_select_sort);
sum = 0;
for i = 1:length(data_select_sort)
sum = sum + (data_select_sort(i) - mu)^2;
end
sigma = sqrt(sum/(length(data_select_sort)-1)); %标准差
alpha = pi/(sqrt(6)*sigma);
u = mu - 0.57721/alpha;
for i = 1 : 0.1 : 999999 %降水量设置为1~999999mm
if 1/N >= 1 - exp(-exp(-alpha*(i - u))) % N年一遇
Recurrence_period_value = i; % Recurrence_period_value即为N年一遇降水值
break;
end
end
end
Gumbel:Python程序:
def Gumble_func(data,N,length):
# data应为一列数据
# N为多少年一遇
# length为所用数据年数(从大到小排序后希望获得前几个数据)
# Recurrence_period_value为N年一遇值
# data = pd.read_excel(file_path)
# data = np.array(data)
# N = 100
# length = 100
datasort = np.sort(data, axis=0)[::-1] # 从大到小排列
data_select_sorts = datasort[0:length - 1]
mu = np.mean(data_select_sorts)
sum_mm = 0
for data_select_sort in data_select_sorts:
sum_mm = sum_mm + (data_select_sort - mu) ** 2
sigma = np.sqrt(sum_mm / (len(data_select_sorts) - 1)) # 标准差
alpha = np.pi / (np.sqrt(6) * sigma)
u = mu - 0.57721 / alpha
for i in np.arange(1, 999999, 0.1): # 降水量设置为1~999999mm
if 1 / N >= 1 - np.exp(-np.exp(-alpha * (i - u))): # N年一遇
Recurrence_period_value = i # Recurrence_period_value即为N年一遇降水值
print(str(N)+'年一遇降水值:',Recurrence_period_value,'毫米')
break
return Recurrence_period_value
以上两程序所得的Recurrence_period_value即为N年一遇的降水值,如果N设置为100,那么Recurrence_period_value就是100年一遇的降水量。
广义极值分布:Python程序:
# -*- coding: utf-8 -*-
"""
@Features of this code:重现期
@Author: zlf
@Date:
"""
import numpy as np
import pandas as pd
from scipy.stats import genextreme
def return_periods(data, years=[5, 10, 20, 50, 100]):
data = np.array(data) # data为ndarray格式
# Fit the generalized extreme value distribution to the data.
shape, loc, scale = genextreme.fit(data)
print("Fit parameters:")
print(f" shape: {shape:.4f}")
print(f" loc: {loc:.4f}")
print(f" scale: {scale:.4f}")
# Compute the return levels for several return periods.
return_periods = np.array(years)
return_levels = genextreme.isf(1 / return_periods, shape, loc, scale)
print("Return levels:")
print("Period Level")
for period, level in zip(return_periods, return_levels):
print(f'{period:4.0f} {level:9.2f}')
if __name__ == '__main__':
data = pd.read_excel(r'D:降水量.xlsx')
return_periods(data)
输出结果:
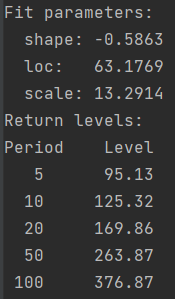
最后
以上就是腼腆冷风最近收集整理的关于重现期Matlab\Python程序(Gumbel和广义极值分布)的全部内容,更多相关重现期Matlab\Python程序(Gumbel和广义极值分布)内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复