小白第一次写系统文,技术不佳,主要是为了自己后期查找方便,望各路大神不喜轻喷~~
文末有7个主要文件的完整版本,喜欢请查阅~
0 重要文件结构梳理
主要文件结构如下图所示。为了方便后续文件位置对照,先把总图摆在这了。纯原创哈~~
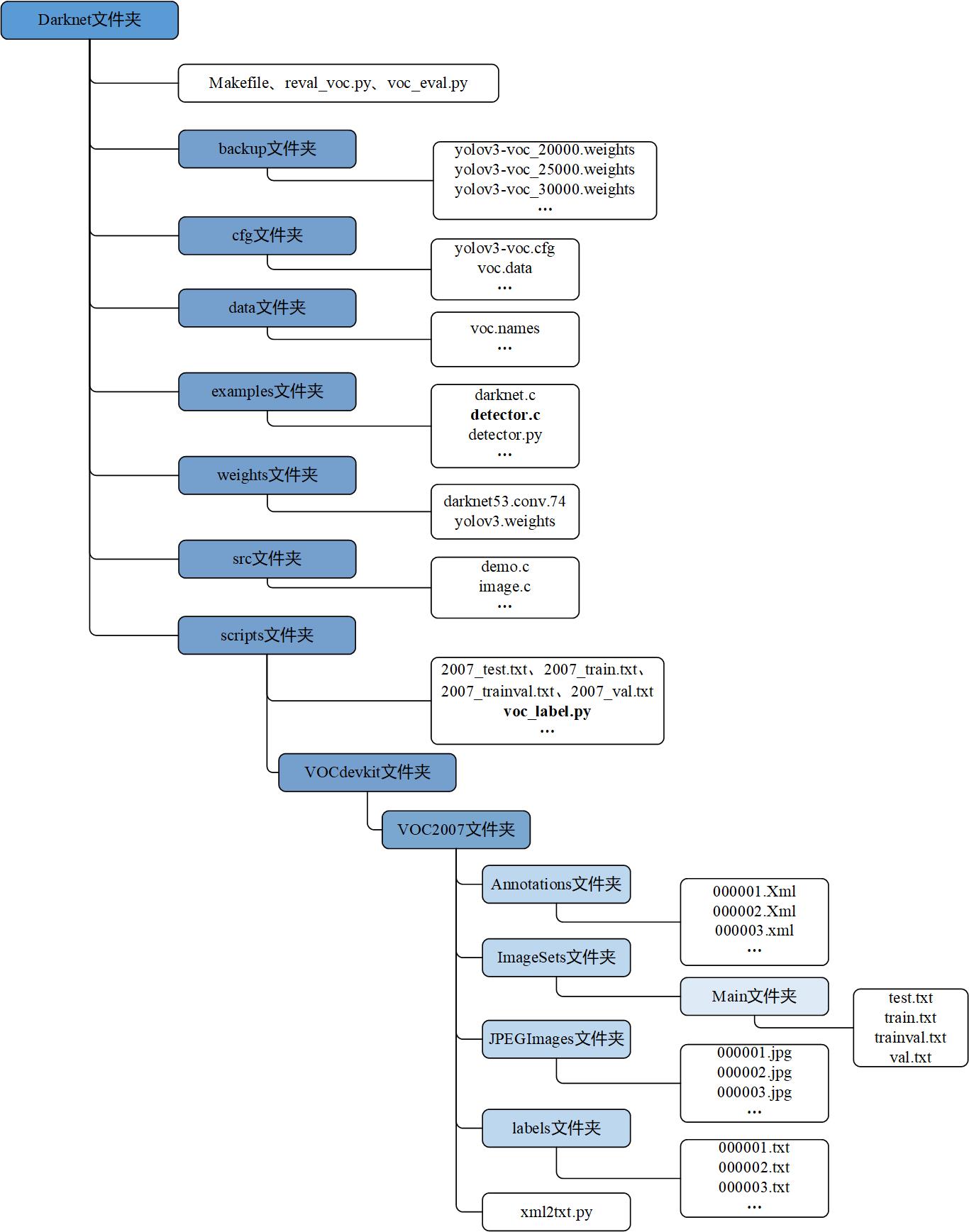
1 前期安装和环境配置
1.1 下载安装
参考:https://pjreddie.com/darknet/yolo/
git clone https://github.com/pjreddie/darknet
cd darknet
make
下载预训练模型darknet53.conv.74,放置路径建议:darknet/weights/darknet53.conv.74。
1.2 修改Makefile
修改darknet文件夹中的Makefile文件的指定内容:
修改前:
GPU=0
CUDNN=0
OPENCV=0
NVCC=nvcc //根据自己的版本修改
COMMON+=-DGPU -I/usr/local/cuda/include/
LDFLAGS+=-L/usr/local/cuda/lib64 -lcuda -lcudart -lcublas -lcurand
修改后:
GPU=1
CUDNN=1
OPENCV=1
NVCC=/usr/local/cuda-10.1/bin/nvcc //根据自己的版本修改
COMMON+=-DGPU -I/usr/local/cuda-10.1/include/
LDFLAGS+=-L/usr/local/cuda-10.1/lib64 -L/usr/lib/nvidia -lcuda -lcudart -lcublas -lcurand
完整的Makefile文件见附录①。修改Makefile后,需要重新编译:
make clean
make
1.3 准备数据集VOC2007
1.3.1 初步形成VOC2007文件夹
使用LabelImg软件进行图片标注,将原始图片和相应xml标注文件放入VOC2007文件夹。
VOC2007文件夹中包含3个子文件夹,分别是:Annotations、ImageSets、JPEGImages。为了避免不必要的麻烦,这三个名字一个字母都不要错哦。
其中,Annotations文件夹用于存放所有的xml文件,把你的xml文件都放这里;JPEGImages用于存放所有的图片,把你的jpg文件都放这里;而ImageSets文件夹类似一个管理员的感觉,其中只有一个Main文件夹,Main文件夹里面暂时是空的,但是要有这个文件夹。
1.3.2 划分数据集:xml2txt.py
#_*_coding:utf-8
import os
import random
# 0.9,0.9能够保证此时的train:val:test = 8:1:1
xmlfilepath="./Annotations" # xml文件路径
txtsavepath="./ImageSets/Main" # txt文件保存路径
trainval_percent=0.9 # trainval集占整个数据集的百分比,剩下的就是test集所占的百分比
train_percent=0.9 # train集占trainval集的百分比,剩下的就是val集所占的百分比
def xml_to_txt():
xmllist=os.listdir(xmlfilepath) # 导入xml文件列表
xml_num=len(xmllist) # xml文件数量
num_list=range(xml_num) # 将xml文件分别用数字表示,从0到xml_num(不包含xml_num)
trainval_num=int(xml_num*trainval_percent) # trainval集样本数量
trainval=random.sample(num_list,trainval_num) #从num_list个xml文件中随机选取trainval_num个当作trainval数据集
train_num=int(trainval_num*train_percent) # train集样本数量
train=random.sample(trainval,train_num) # 从trainval集中随机选取train_num个当作train数据集
ftrainval=open(txtsavepath+'/trainval.txt','w')
ftest=open(txtsavepath+'/test.txt','w')
ftrain=open(txtsavepath+'/train.txt','w')
fval=open(txtsavepath+'/val.txt','w')
for i in num_list:
name=xmllist[i][:-4]+'n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
xml_to_txt() # 调用转换函数
将xml2txt.py文件放到VOC2007文件夹中,在VOC2007文件夹下运行:
python xml2txt.py //用的是python3
运行后,VOC2007/Main文件夹中多出4个文本文件:test.txt、train.txt、trainval.txt、val.txt。4个txt文件里面存放的都是一行行干净整齐的文件名(不含路径和后缀),表示哪些样本用于train,而哪些用于test等。这个是通过scripts下的voc_label.py文件生成的。
000001
以上提到的文件夹,缺啥补啥,至此,一个独立的数据集已经建立完成,但还不是能使用的,要想使用,还得做两件事:
①把VOC2007数据集纳入darknet体系;
②修改并运行voc_label.py脚本。
1.3.3 把VOC2007数据集纳入darknet体系
在darknet/scripts文件夹下新建VOCdevkit文件夹(一个字母都不能错),把VOC2007文件夹直接放入,最后层级关系是:darknet/scripts/VOCdevkit/VOC2007
1.3.4 修改并运行voc_label.py脚本
修改scripts下的voc_label.py文件:
修改前:
sets=[('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
os.system("cat 2007_train.txt 2007_val.txt > train.txt")
os.system("cat 2007_train.txt 2007_val.txt 2007_test.txt 2007_trainval.txt> train.all.txt")
修改后:
sets = [('2007', 'train'), ('2007', 'trainval'), ('2007', 'test'), ('2007', 'val')]
classes = ["excreting","notexcreting","likeboarurination","0","1","2","3","4","5","6","7","8","f","h","x","sickfeces"] //换成自己的类别
#os.system("cat 2007_train.txt 2007_val.txt > train.txt")
#os.system("cat 2007_train.txt 2007_val.txt 2007_test.txt 2007_trainval.txt> train.all.txt")
在scripts下运行:
python voc_label.py //用的python3
运行后,视觉上有两个变化:
① darkent/scripts文件夹中出现4个文本文件:2007_test.txt、2007_train.txt、2007_trainval.txt、2007_val.txt。里面存放的是图片的完整路径和带后缀的文件名:
/home/dj/dingjing/darknet/scripts/VOCdevkit/VOC2007/JPEGImages/000001.jpg
② VOC2007文件夹中出现labels文件夹,里面放的是所有xml转换成的txt,每个txt文件中内容类似下面:
| 类别编号 | xmin | xmax | ymin | ymax |
|---|---|---|---|---|
| 1 | 0.5037109375000001 | 0.290625 | 0.20039062500000002 | 0.13125 |
| 1 | 0.3853515625 | 0.43506944444444445 | 0.103515625 | 0.38263888 |
| 11 | 0.5326171875 | 0.2611111111111111 | 0.053515625 | 0.051388888 |
| 3 | 0.3615234375 | 0.38159722222222225 | 0.033984375 | 0.054861 |
第1列数字是类别编号,第2列至第5列是标注框的相对坐标。相对坐标 = 绝对坐标/图片长宽。
1.4 修改配置文件
共3部分:修改cfg中两个文件voc.data和yolov3-voc.cfg,修改data下的类别名称文件xxx.names。
1.4.1 修改cfg中voc.data
修改前:
classes= 20
train = /home/pjreddie/data/voc/train.txt
valid = /home/pjreddie/data/voc/2007_test.txt
names = data/voc.names
backup = backup
修改后:
classes= 16
train = /home/dj/dingjing/darknet/scripts/2007_train.txt
valid = /home/dj/dingjing/darknet/scripts/2007_test.txt
names = data/dingall.names
backup = backup
1.4.2 修改cfg中yolov3-voc.cfg
修改前:
[net]
# Testing
batch=1
subdivisions=1
# Training
# batch=64
# subdivisions=16
width=416
height=416
...
max_batches = 50200
...
steps=40000,45000
...
//每一个[yolo]层前的最后一个卷积层 共3处
[convolutional]
size=1
stride=1
pad=1
filters=75
activation=linear
[yolo]
mask = 6,7,8
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=20
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=1
修改后:
[net]
# Testing
# batch=1
# subdivisions=1
# Training
batch=64
subdivisions=16 //如果报错,改成64
width=608 //改或不改都行
height=608//改或不改都行
...
max_batches = 30000
...
steps=24000,27000
...
//每一个[yolo]层前的最后一个卷积层 共3处
[convolutional]
size=1
stride=1
pad=1
filters=63 //需要修改,filters=num(yolo层个数)*(classes+5)
activation=linear
[yolo]
mask = 6,7,8
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=16 //需要修改,改为自己的实际种类数
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=1
修改后完整版的yolov3-voc.cfg见附录⑦。
1.4.3 修改data下的类别名称文件xxx.names
可以新建文件:dingall.names
excreting
notexcreting
likeboarurination
0
1
2
3
4
5
6
7
8
f
h
x
sickfeces
2 训练
2.1 单GPU训练
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg weights/darknet53.conv.74 | tee dingall.txt
tee是为了生成训练过程记录文本,便于后续模型分析。
2.2 多GPU训练
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg weights/darknet53.conv.74 -gpus 0,1,2,3
2.3 从checkpoint断点开始训练
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg backup/yolov3-voc.backup -gpus 0,1,2,3
3 模型测试
3.1 修改yolov3-voc.cfg
cfg中yolov3-voc.cfg中,关闭训练开关,打开测试开关:
修改前:
[net]
# Testing
# batch=1
# subdivisions=1
# Training
batch=64
subdivisions=16
修改后:
[net]
# Testing
batch=1
subdivisions=1
# Training
# batch=64
# subdivisions=16
3.2 测试单张图片
./darknet detector test cfg/voc.data cfg/yolov3-voc.cfg backup/yolov3-voc_final.weights data/xxx.jpg
3.3 批量测试(test数据集)
① 在detector.c中修改生成文件的名称为comp4_det_test
首先修改examples/detector.c:validate_detector函数中,约为424行,将comp4_det_val改成comp4_det_test,如果已经是就不需修改啦,然后在darknet文件夹下重新编译:
make clean
make
② 批量测试——输出文本检测结果(first)(输出在results文件夹中comp4_det_test_类名.txt)
./darknet detector valid cfg/voc.data cfg/yolov3-voc.cfg backup/yolov3-voc_final.weights
③ 批量测试——输出图片检测结果(second)(输出在data/out-img文件夹中)
./darknet detector test cfg/voc.data cfg/yolov3-voc.cfg backup/yolov3-voc_final.weights
Enter Image Path: scripts/2007_test.txt
④ 计算recall(执行这个命令需要修改detector.c文件,修改信息请参考“detector.c修改”)
./darknet detector recall cfg/voc.data cfg/yolov3-voc.cfg backup/yolov3-voc_final.weights
⑤(切换成python3)计算各类别的AP和mAP:生成plk文件用于画PR曲线
执行下列命令前一定要注意把darknet/scripts/VOCdevkit/annotations_cache这个文件夹屏蔽掉,否则影响新的文件输出(参考https://blog.csdn.net/weixin_41143397/article/details/83831839
)
python reval_voc.py --voc_dir /home/dj/dingjing/darknet/scripts/VOCdevkit --year 2007 --image_set test --classes /home/dj/dingjing/darknet/data/dingall.names x(x是自己新建的文件夹名称,用来保存最后生成的.txt文件)
3.5 测试视频
./darknet detector demo cfg/voc.data cfg/yolov3-voc.cfg backup/yolov3-voc_25000.weights data/1.mp4
4 训练过程分析
4.1 绘制loss-iter曲线
新建文件夹keshihua,将tee生成的dingall.txt放进来,将iouLoss.py文件放进来。
其中,iouLoss.py内容如下,需要修改的地方:g_log_path = "dingall.txt"。
# -*- coding: utf-8 -*-
# @Time : 2018/12/30 16:26
# @Author : lazerliu
# @File : vis_yolov3_log.py
# @Func :yolov3 训练日志可视化,把该脚本和日志文件放在同一目录下运行。
import pandas as pd
import matplotlib.pyplot as plt
import os
# ==================可能需要修改的地方=====================================#
g_log_path = "dingall.txt" # 此处修改为你的训练日志文件名
# ==========================================================================#
def extract_log(log_file, new_log_file, key_word):
'''
:param log_file:日志文件
:param new_log_file:挑选出可用信息的日志文件
:param key_word:根据关键词提取日志信息
:return:
'''
with open(log_file, "r") as f:
with open(new_log_file, "w") as train_log:
for line in f:
# 去除多gpu的同步log
if "Syncing" in line:
continue
# 去除nan log
if "nan" in line:
continue
if key_word in line:
train_log.write(line)
f.close()
train_log.close()
def drawAvgLoss(loss_log_path):
'''
:param loss_log_path: 提取到的loss日志信息文件
:return: 画loss曲线图
'''
line_cnt = 0
for count, line in enumerate(open(loss_log_path, "rU")):
line_cnt += 1
result = pd.read_csv(loss_log_path, skiprows=[iter_num for iter_num in range(line_cnt) if ((iter_num < 500))],
error_bad_lines=False,
names=["loss", "avg", "rate", "seconds", "images"])
result["avg"] = result["avg"].str.split(" ").str.get(1)
result["avg"] = pd.to_numeric(result["avg"])
fig = plt.figure(1, figsize=(6, 4))
ax = fig.add_subplot(1, 1, 1)
ax.plot(result["avg"].values, label="Avg Loss", color="#ff7043")
ax.legend(loc="best")
ax.set_title("Avg Loss Curve")
ax.set_xlabel("Batches")
ax.set_ylabel("Avg Loss")
def drawIOU(iou_log_path):
'''
:param iou_log_path: 提取到的iou日志信息文件
:return: 画iou曲线图
'''
line_cnt = 0
for count, line in enumerate(open(iou_log_path, "rU")):
line_cnt += 1
result = pd.read_csv(iou_log_path, skiprows=[x for x in range(line_cnt) if (x % 39 != 0 | (x < 5000))],
error_bad_lines=False,
names=["Region Avg IOU", "Class", "Obj", "No Obj", "Avg Recall", "count"])
result["Region Avg IOU"] = result["Region Avg IOU"].str.split(": ").str.get(1)
result["Region Avg IOU"] = pd.to_numeric(result["Region Avg IOU"])
result_iou = result["Region Avg IOU"].values
# 平滑iou曲线
for i in range(len(result_iou) - 1):
iou = result_iou[i]
iou_next = result_iou[i + 1]
if abs(iou - iou_next) > 0.2:
result_iou[i] = (iou + iou_next) / 2
fig = plt.figure(2, figsize=(6, 4))
ax = fig.add_subplot(1, 1, 1)
ax.plot(result_iou, label="Region Avg IOU", color="#ff7043")
ax.legend(loc="best")
ax.set_title("Avg IOU Curve")
ax.set_xlabel("Batches")
ax.set_ylabel("Avg IOU")
if __name__ == "__main__":
loss_log_path = "train_log_loss.txt"
iou_log_path = "train_log_iou.txt"
if os.path.exists(g_log_path) is False:
exit(-1)
if os.path.exists(loss_log_path) is False:
extract_log(g_log_path, loss_log_path, "images")
if os.path.exists(iou_log_path) is False:
extract_log(g_log_path, iou_log_path, "IOU")
drawAvgLoss(loss_log_path)
drawIOU(iou_log_path)
plt.show()
4.2 训练的日志格式分析
//第一轮:
Loaded: 4.533954 seconds
Region Avg IOU: 0.262313, Class: 1.000000, Obj: 0.542580, No Obj: 0.514735, Avg Recall: 0.162162, count: 37
Region Avg IOU: 0.175988, Class: 1.000000, Obj: 0.499655, No Obj: 0.517558, Avg Recall: 0.070423, count: 71
Region Avg IOU: 0.200012, Class: 1.000000, Obj: 0.483404, No Obj: 0.514622, Avg Recall: 0.075758, count: 66
Region Avg IOU: 0.279284, Class: 1.000000, Obj: 0.447059, No Obj: 0.515849, Avg Recall: 0.134615, count: 52
1: 629.763611, 629.763611 avg, 0.001000 rate, 6.098687 seconds, 64 images
//第二轮:
Loaded: 2.957771 seconds
Region Avg IOU: 0.145857, Class: 1.000000, Obj: 0.051285, No Obj: 0.031538, Avg Recall: 0.069767, count: 43
Region Avg IOU: 0.257284, Class: 1.000000, Obj: 0.048616, No Obj: 0.027511, Avg Recall: 0.078947, count: 38
Region Avg IOU: 0.174994, Class: 1.000000, Obj: 0.030197, No Obj: 0.029943, Avg Recall: 0.088889, count: 45
Region Avg IOU: 0.196278, Class: 1.000000, Obj: 0.076030, No Obj: 0.030472, Avg Recall: 0.087719, count: 57
2: 84.804230, 575.267700 avg, 0.001000 rate, 5.959159 seconds, 128 images
| 关键字 | 含义 |
|---|---|
| Region | cfg文件中yolo-layer的索引 |
| Avg IOU | 当前迭代中,预测的box与标注的box的平均交并比,越大越好,期望数值为1 |
| Class | 标注物体的分类准确率,越大越好,期望数值为1 |
| obj | 越大越好,期望数值为1 |
| No obj | 越小越好,但不为零 |
| .5R | 以IOU=0.5为阈值时候的recall; recall = 检出的正样本/实际的正样本 |
| .75R | 以IOU=0.75为阈值时候的recall |
| count | 正样本数目 |
Region 82 Avg IOU: 0.798032, Class: 0.559781, Obj: 0.515851, No Obj: 0.006533, .5R: 1.000000, .75R: 1.000000, count: 2
Region 94 Avg IOU: 0.725307, Class: 0.830518, Obj: 0.506567, No Obj: 0.000680, .5R: 1.000000, .75R: 0.750000, count: 4
Region 106 Avg IOU: 0.579333, Class: 0.322556, Obj: 0.020537, No Obj: 0.000070, .5R: 1.000000, .75R: 0.000000, count: 2
以上输出显示了所有训练图片的一个批次(batch),批次大小的划分根据我们在 .cfg 文件中设置的subdivisions参数。
在我使用的 .cfg 文件中 batch = 64 ,subdivision = 16,所以在训练输出中,训练迭代包含了16组,每组又包含了4张图片,跟设定的batch和subdivision的值一致。
但是此处有16*3条信息,每组包含三条信息,分别是:Region 82、Region 94、Region 106。
三个尺度上预测不同大小的框:
- 82卷积层 为最大的预测尺度,使用较大的mask,但是可以预测出较小的物体;
- 94卷积层 为中间的预测尺度,使用中等的mask;
- 106卷积层为最小的预测尺度,使用较小的mask,可以预测出较大的物体
每个batch都会有这样一个输出:
2706: 1.350835, 1.386559 avg, 0.001000 rate, 3.323842 seconds, 173184 images
batch 总损失 平均损失 学习率 花费时间 参与训练的图片总数
5 附录
附录共包括7个文件的完整内容:
①Makefile
②detector.c
③reval_voc.py
④voc_eval.py
⑤xml2txt.py
⑥voc_label.py
⑦yolov3-voc.cfg
①Makefile
GPU=1
CUDNN=1
OPENCV=1
OPENMP=0
DEBUG=1
ARCH= -gencode arch=compute_30,code=sm_30
-gencode arch=compute_35,code=sm_35
-gencode arch=compute_50,code=[sm_50,compute_50]
-gencode arch=compute_52,code=[sm_52,compute_52]
#-gencode arch=compute_20,code=[sm_20,sm_21] This one is deprecated?
# This is what I use, uncomment if you know your arch and want to specify
# ARCH= -gencode arch=compute_52,code=compute_52
VPATH=./src/:./examples
SLIB=libdarknet.so
ALIB=libdarknet.a
EXEC=darknet
OBJDIR=./obj/
CC=gcc
CPP=g++
NVCC=/usr/local/cuda-9.0/bin/nvcc
AR=ar
ARFLAGS=rcs
OPTS=-Ofast
LDFLAGS= -lm -pthread
COMMON= -Iinclude/ -Isrc/
CFLAGS=-Wall -Wno-unused-result -Wno-unknown-pragmas -Wfatal-errors -fPIC
ifeq ($(OPENMP), 1)
CFLAGS+= -fopenmp
endif
ifeq ($(DEBUG), 1)
OPTS=-O0 -g
endif
CFLAGS+=$(OPTS)
ifeq ($(OPENCV), 1)
COMMON+= -DOPENCV
CFLAGS+= -DOPENCV
LDFLAGS+= `pkg-config --libs opencv` -lstdc++
COMMON+= `pkg-config --cflags opencv`
endif
ifeq ($(GPU), 1)
COMMON+= -DGPU -I/usr/local/cuda-9.0/include/
CFLAGS+= -DGPU
LDFLAGS+= -L/usr/local/cuda-9.0/lib64 -lcuda -lcudart -lcublas -lcurand
endif
ifeq ($(CUDNN), 1)
COMMON+= -DCUDNN -I/usr/local/cuda-9.0/include
CFLAGS+= -DCUDNN
LDFLAGS+= -L/usr/local/cuda-9.0/lib64 -lcudnn
endif
OBJ=gemm.o utils.o cuda.o deconvolutional_layer.o convolutional_layer.o list.o image.o activations.o im2col.o col2im.o blas.o crop_layer.o dropout_layer.o maxpool_layer.o softmax_layer.o data.o matrix.o network.o connected_layer.o cost_layer.o parser.o option_list.o detection_layer.o route_layer.o upsample_layer.o box.o normalization_layer.o avgpool_layer.o layer.o local_layer.o shortcut_layer.o logistic_layer.o activation_layer.o rnn_layer.o gru_layer.o crnn_layer.o demo.o batchnorm_layer.o region_layer.o reorg_layer.o tree.o lstm_layer.o l2norm_layer.o yolo_layer.o iseg_layer.o image_opencv.o
EXECOBJA=captcha.o lsd.o super.o art.o tag.o cifar.o go.o rnn.o segmenter.o regressor.o classifier.o coco.o yolo.o detector.o nightmare.o instance-segmenter.o darknet.o
ifeq ($(GPU), 1)
LDFLAGS+= -lstdc++
OBJ+=convolutional_kernels.o deconvolutional_kernels.o activation_kernels.o im2col_kernels.o col2im_kernels.o blas_kernels.o crop_layer_kernels.o dropout_layer_kernels.o maxpool_layer_kernels.o avgpool_layer_kernels.o
endif
EXECOBJ = $(addprefix $(OBJDIR), $(EXECOBJA))
OBJS = $(addprefix $(OBJDIR), $(OBJ))
DEPS = $(wildcard src/*.h) Makefile include/darknet.h
all: obj backup results $(SLIB) $(ALIB) $(EXEC)
#all: obj results $(SLIB) $(ALIB) $(EXEC)
$(EXEC): $(EXECOBJ) $(ALIB)
$(CC) $(COMMON) $(CFLAGS) $^ -o $@ $(LDFLAGS) $(ALIB)
$(ALIB): $(OBJS)
$(AR) $(ARFLAGS) $@ $^
$(SLIB): $(OBJS)
$(CC) $(CFLAGS) -shared $^ -o $@ $(LDFLAGS)
$(OBJDIR)%.o: %.cpp $(DEPS)
$(CPP) $(COMMON) $(CFLAGS) -c $< -o $@
$(OBJDIR)%.o: %.c $(DEPS)
$(CC) $(COMMON) $(CFLAGS) -c $< -o $@
$(OBJDIR)%.o: %.cu $(DEPS)
$(NVCC) $(ARCH) $(COMMON) --compiler-options "$(CFLAGS)" -c $< -o $@
obj:
mkdir -p obj
backup:
mkdir -p backup
results:
mkdir -p results
.PHONY: clean
clean:
rm -rf $(OBJS) $(SLIB) $(ALIB) $(EXEC) $(EXECOBJ) $(OBJDIR)/*
②detector.c(较长哦)
#include "darknet.h"
#include "math.h"
int cvRound(double value) {return(ceil(value));}
#include <opencv2/highgui/highgui_c.h>
#include <sys/stat.h>
#include <stdio.h>
#include <time.h>
#include <sys/types.h>
#include <unistd.h>/* Many POSIX functions (but not all, by a large margin) */
#include <fcntl.h>/* open(), creat() - and fcntl() */
static int coco_ids[] = {1,2,3,4,5,6,7,8,9,10,11,13,14,15,16,17,18,19,20,21,22,23,24,25,27,28,31,32,33,34,35,36,37,38,39,40,41,42,43,44,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,67,70,72,73,74,75,76,77,78,79,80,81,82,84,85,86,87,88,89,90};
//产生的文件名与原文件名相同(去除路径和格式)
char *GetFilename(char *p)
{
static char name[20]={""};
char *q = strrchr(p,'/') + 1;
strncpy(name,q,6);//注意后面的6,如果你的测试集的图片的名字字符(不包括后缀)是其他长度,请改为你需要的长度
return name;
}
void train_detector(char *datacfg, char *cfgfile, char *weightfile, int *gpus, int ngpus, int clear)
{
list *options = read_data_cfg(datacfg);
char *train_images = option_find_str(options, "train", "data/train.list");
char *backup_directory = option_find_str(options, "backup", "/backup/");
srand(time(0));
char *base = basecfg(cfgfile);
printf("%sn", base);
float avg_loss = -1;
network **nets = calloc(ngpus, sizeof(network));
srand(time(0));
int seed = rand();
int i;
for(i = 0; i < ngpus; ++i){
srand(seed);
#ifdef GPU
cuda_set_device(gpus[i]);
#endif
nets[i] = load_network(cfgfile, weightfile, clear);
nets[i]->learning_rate *= ngpus;
}
srand(time(0));
network *net = nets[0];
int imgs = net->batch * net->subdivisions * ngpus;
printf("Learning Rate: %g, Momentum: %g, Decay: %gn", net->learning_rate, net->momentum, net->decay);
data train, buffer;
layer l = net->layers[net->n - 1];
int classes = l.classes;
float jitter = l.jitter;
list *plist = get_paths(train_images);
//int N = plist->size;
char **paths = (char **)list_to_array(plist);
load_args args = get_base_args(net);
args.coords = l.coords;
args.paths = paths;
args.n = imgs;
args.m = plist->size;
args.classes = classes;
args.jitter = jitter;
args.num_boxes = l.max_boxes;
args.d = &buffer;
args.type = DETECTION_DATA;
//args.type = INSTANCE_DATA;
args.threads = 64;
pthread_t load_thread = load_data(args);
double time;
int count = 0;
//while(i*imgs < N*120){
while(get_current_batch(net) < net->max_batches){
if(l.random && count++%10 == 0){
printf("Resizingn");
int dim = (rand() % 10 + 10) * 32;
if (get_current_batch(net)+200 > net->max_batches) dim = 608;
//int dim = (rand() % 4 + 16) * 32;
printf("%dn", dim);
args.w = dim;
args.h = dim;
pthread_join(load_thread, 0);
train = buffer;
free_data(train);
load_thread = load_data(args);
#pragma omp parallel for
for(i = 0; i < ngpus; ++i){
resize_network(nets[i], dim, dim);
}
net = nets[0];
}
time=what_time_is_it_now();
pthread_join(load_thread, 0);
train = buffer;
load_thread = load_data(args);
/*
int k;
for(k = 0; k < l.max_boxes; ++k){
box b = float_to_box(train.y.vals[10] + 1 + k*5);
if(!b.x) break;
printf("loaded: %f %f %f %fn", b.x, b.y, b.w, b.h);
}
*/
/*
int zz;
for(zz = 0; zz < train.X.cols; ++zz){
image im = float_to_image(net->w, net->h, 3, train.X.vals[zz]);
int k;
for(k = 0; k < l.max_boxes; ++k){
box b = float_to_box(train.y.vals[zz] + k*5, 1);
printf("%f %f %f %fn", b.x, b.y, b.w, b.h);
draw_bbox(im, b, 1, 1,0,0);
}
show_image(im, "truth11");
cvWaitKey(0);
save_image(im, "truth11");
}
*/
printf("Loaded: %lf secondsn", what_time_is_it_now()-time);
time=what_time_is_it_now();
float loss = 0;
#ifdef GPU
if(ngpus == 1){
loss = train_network(net, train);
} else {
loss = train_networks(nets, ngpus, train, 4);
}
#else
loss = train_network(net, train);
#endif
if (avg_loss < 0) avg_loss = loss;
avg_loss = avg_loss*.9 + loss*.1;
i = get_current_batch(net);
printf("%ld: %f, %f avg, %f rate, %lf seconds, %d imagesn", get_current_batch(net), loss, avg_loss, get_current_rate(net), what_time_is_it_now()-time, i*imgs);
if(i%100==0){
#ifdef GPU
if(ngpus != 1) sync_nets(nets, ngpus, 0);
#endif
char buff[256];
sprintf(buff, "%s/%s.backup", backup_directory, base);
save_weights(net, buff);
}
//if(i%10000==0 || (i < 1000 && i%100 == 0)){ //changed by dingjing
if(i%1000==0){//every 1000 output one model每训练1000次保存一次模型
#ifdef GPU
if(ngpus != 1) sync_nets(nets, ngpus, 0);
#endif
char buff[256];
sprintf(buff, "%s/%s_%d.weights", backup_directory, base, i);
save_weights(net, buff);
}
free_data(train);
}
#ifdef GPU
if(ngpus != 1) sync_nets(nets, ngpus, 0);
#endif
char buff[256];
sprintf(buff, "%s/%s_final.weights", backup_directory, base);
save_weights(net, buff);
}
static int get_coco_image_id(char *filename)
{
char *p = strrchr(filename, '/');
char *c = strrchr(filename, '_');
if(c) p = c;
return atoi(p+1);
}
static void print_cocos(FILE *fp, char *image_path, detection *dets, int num_boxes, int classes, int w, int h)
{
int i, j;
int image_id = get_coco_image_id(image_path);
for(i = 0; i < num_boxes; ++i){
float xmin = dets[i].bbox.x - dets[i].bbox.w/2.;
float xmax = dets[i].bbox.x + dets[i].bbox.w/2.;
float ymin = dets[i].bbox.y - dets[i].bbox.h/2.;
float ymax = dets[i].bbox.y + dets[i].bbox.h/2.;
if (xmin < 0) xmin = 0;
if (ymin < 0) ymin = 0;
if (xmax > w) xmax = w;
if (ymax > h) ymax = h;
float bx = xmin;
float by = ymin;
float bw = xmax - xmin;
float bh = ymax - ymin;
for(j = 0; j < classes; ++j){
if (dets[i].prob[j]) fprintf(fp, "{"image_id":%d, "category_id":%d, "bbox":[%f, %f, %f, %f], "score":%f},n", image_id, coco_ids[j], bx, by, bw, bh, dets[i].prob[j]);
}
}
}
void print_detector_detections(FILE **fps, char *id, detection *dets, int total, int classes, int w, int h)
{
int i, j;
for(i = 0; i < total; ++i){
float xmin = dets[i].bbox.x - dets[i].bbox.w/2. + 1;
float xmax = dets[i].bbox.x + dets[i].bbox.w/2. + 1;
float ymin = dets[i].bbox.y - dets[i].bbox.h/2. + 1;
float ymax = dets[i].bbox.y + dets[i].bbox.h/2. + 1;
if (xmin < 1) xmin = 1;
if (ymin < 1) ymin = 1;
if (xmax > w) xmax = w;
if (ymax > h) ymax = h;
for(j = 0; j < classes; ++j){
if (dets[i].prob[j]) fprintf(fps[j], "%s %f %f %f %f %fn", id, dets[i].prob[j],
xmin, ymin, xmax, ymax);
}
}
}
void print_imagenet_detections(FILE *fp, int id, detection *dets, int total, int classes, int w, int h)
{
int i, j;
for(i = 0; i < total; ++i){
float xmin = dets[i].bbox.x - dets[i].bbox.w/2.;
float xmax = dets[i].bbox.x + dets[i].bbox.w/2.;
float ymin = dets[i].bbox.y - dets[i].bbox.h/2.;
float ymax = dets[i].bbox.y + dets[i].bbox.h/2.;
if (xmin < 0) xmin = 0;
if (ymin < 0) ymin = 0;
if (xmax > w) xmax = w;
if (ymax > h) ymax = h;
for(j = 0; j < classes; ++j){
int class = j;
if (dets[i].prob[class]) fprintf(fp, "%d %d %f %f %f %f %fn", id, j+1, dets[i].prob[class],
xmin, ymin, xmax, ymax);
}
}
}
void validate_detector_flip(char *datacfg, char *cfgfile, char *weightfile, char *outfile)
{
int j;
list *options = read_data_cfg(datacfg);
char *valid_images = option_find_str(options, "valid", "data/val.list");
char *name_list = option_find_str(options, "names", "data/names.list");
char *prefix = option_find_str(options, "results", "results");
char **names = get_labels(name_list);
char *mapf = option_find_str(options, "map", 0);
int *map = 0;
if (mapf) map = read_map(mapf);
network *net = load_network(cfgfile, weightfile, 0);
set_batch_network(net, 2);
fprintf(stderr, "Learning Rate: %g, Momentum: %g, Decay: %gn", net->learning_rate, net->momentum, net->decay);
srand(time(0));
list *plist = get_paths(valid_images);
char **paths = (char **)list_to_array(plist);
layer l = net->layers[net->n-1];
int classes = l.classes;
char buff[1024];
char *type = option_find_str(options, "eval", "voc");
FILE *fp = 0;
FILE **fps = 0;
int coco = 0;
int imagenet = 0;
if(0==strcmp(type, "coco")){
if(!outfile) outfile = "coco_results";
snprintf(buff, 1024, "%s/%s.json", prefix, outfile);
fp = fopen(buff, "w");
fprintf(fp, "[n");
coco = 1;
} else if(0==strcmp(type, "imagenet")){
if(!outfile) outfile = "imagenet-detection";
snprintf(buff, 1024, "%s/%s.txt", prefix, outfile);
fp = fopen(buff, "w");
imagenet = 1;
classes = 200;
} else {
if(!outfile) outfile = "comp4_det_test_";
fps = calloc(classes, sizeof(FILE *));
for(j = 0; j < classes; ++j){
snprintf(buff, 1024, "%s/%s%s.txt", prefix, outfile, names[j]);
fps[j] = fopen(buff, "w");
}
}
int m = plist->size;
int i=0;
int t;
float thresh = .005;
float nms = .45;
int nthreads = 4;
image *val = calloc(nthreads, sizeof(image));
image *val_resized = calloc(nthreads, sizeof(image));
image *buf = calloc(nthreads, sizeof(image));
image *buf_resized = calloc(nthreads, sizeof(image));
pthread_t *thr = calloc(nthreads, sizeof(pthread_t));
image input = make_image(net->w, net->h, net->c*2);
load_args args = {0};
args.w = net->w;
args.h = net->h;
//args.type = IMAGE_DATA;
args.type = LETTERBOX_DATA;
for(t = 0; t < nthreads; ++t){
args.path = paths[i+t];
args.im = &buf[t];
args.resized = &buf_resized[t];
thr[t] = load_data_in_thread(args);
}
double start = what_time_is_it_now();
for(i = nthreads; i < m+nthreads; i += nthreads){
fprintf(stderr, "%dn", i);
for(t = 0; t < nthreads && i+t-nthreads < m; ++t){
pthread_join(thr[t], 0);
val[t] = buf[t];
val_resized[t] = buf_resized[t];
}
for(t = 0; t < nthreads && i+t < m; ++t){
args.path = paths[i+t];
args.im = &buf[t];
args.resized = &buf_resized[t];
thr[t] = load_data_in_thread(args);
}
for(t = 0; t < nthreads && i+t-nthreads < m; ++t){
char *path = paths[i+t-nthreads];
char *id = basecfg(path);
copy_cpu(net->w*net->h*net->c, val_resized[t].data, 1, input.data, 1);
flip_image(val_resized[t]);
copy_cpu(net->w*net->h*net->c, val_resized[t].data, 1, input.data + net->w*net->h*net->c, 1);
network_predict(net, input.data);
int w = val[t].w;
int h = val[t].h;
int num = 0;
detection *dets = get_network_boxes(net, w, h, thresh, .5, map, 0, &num);
if (nms) do_nms_sort(dets, num, classes, nms);
if (coco){
print_cocos(fp, path, dets, num, classes, w, h);
} else if (imagenet){
print_imagenet_detections(fp, i+t-nthreads+1, dets, num, classes, w, h);
} else {
print_detector_detections(fps, id, dets, num, classes, w, h);
}
free_detections(dets, num);
free(id);
free_image(val[t]);
free_image(val_resized[t]);
}
}
for(j = 0; j < classes; ++j){
if(fps) fclose(fps[j]);
}
if(coco){
fseek(fp, -2, SEEK_CUR);
fprintf(fp, "n]n");
fclose(fp);
}
fprintf(stderr, "Total Detection Time: %f Secondsn", what_time_is_it_now() - start);
}
void validate_detector(char *datacfg, char *cfgfile, char *weightfile, char *outfile)
{
int j;
list *options = read_data_cfg(datacfg);
char *valid_images = option_find_str(options, "valid", "data/test.list");
char *name_list = option_find_str(options, "names", "data/names.list");
char *prefix = option_find_str(options, "results", "results");
char **names = get_labels(name_list);
char *mapf = option_find_str(options, "map", 0);
int *map = 0;
if (mapf) map = read_map(mapf);
network *net = load_network(cfgfile, weightfile, 0);
set_batch_network(net, 1);
fprintf(stderr, "Learning Rate: %g, Momentum: %g, Decay: %gn", net->learning_rate, net->momentum, net->decay);
srand(time(0));
list *plist = get_paths(valid_images);
char **paths = (char **)list_to_array(plist);
layer l = net->layers[net->n-1];
int classes = l.classes;
char buff[1024];
char *type = option_find_str(options, "eval", "voc");
FILE *fp = 0;
FILE **fps = 0;
int coco = 0;
int imagenet = 0;
if(0==strcmp(type, "coco")){
if(!outfile) outfile = "coco_results";
snprintf(buff, 1024, "%s/%s.json", prefix, outfile);
fp = fopen(buff, "w");
fprintf(fp, "[n");
coco = 1;
} else if(0==strcmp(type, "imagenet")){
if(!outfile) outfile = "imagenet-detection";
snprintf(buff, 1024, "%s/%s.txt", prefix, outfile);
fp = fopen(buff, "w");
imagenet = 1;
classes = 200;
} else {
if(!outfile) outfile = "comp4_det_test_";
fps = calloc(classes, sizeof(FILE *));
for(j = 0; j < classes; ++j){
snprintf(buff, 1024, "%s/%s%s.txt", prefix, outfile, names[j]);
fps[j] = fopen(buff, "w");
}
}
int m = plist->size;
int i=0;
int t;
float thresh = .005;
float nms = .45;
int nthreads = 4;
image *val = calloc(nthreads, sizeof(image));
image *val_resized = calloc(nthreads, sizeof(image));
image *buf = calloc(nthreads, sizeof(image));
image *buf_resized = calloc(nthreads, sizeof(image));
pthread_t *thr = calloc(nthreads, sizeof(pthread_t));
load_args args = {0};
args.w = net->w;
args.h = net->h;
//args.type = IMAGE_DATA;
args.type = LETTERBOX_DATA;
for(t = 0; t < nthreads; ++t){
args.path = paths[i+t];
args.im = &buf[t];
args.resized = &buf_resized[t];
thr[t] = load_data_in_thread(args);
}
double start = what_time_is_it_now();
for(i = nthreads; i < m+nthreads; i += nthreads){
fprintf(stderr, "%dn", i);
for(t = 0; t < nthreads && i+t-nthreads < m; ++t){
pthread_join(thr[t], 0);
val[t] = buf[t];
val_resized[t] = buf_resized[t];
}
for(t = 0; t < nthreads && i+t < m; ++t){
args.path = paths[i+t];
args.im = &buf[t];
args.resized = &buf_resized[t];
thr[t] = load_data_in_thread(args);
}
for(t = 0; t < nthreads && i+t-nthreads < m; ++t){
char *path = paths[i+t-nthreads];
char *id = basecfg(path);
float *X = val_resized[t].data;
network_predict(net, X);
int w = val[t].w;
int h = val[t].h;
int nboxes = 0;
detection *dets = get_network_boxes(net, w, h, thresh, .5, map, 0, &nboxes);
if (nms) do_nms_sort(dets, nboxes, classes, nms);
if (coco){
print_cocos(fp, path, dets, nboxes, classes, w, h);
} else if (imagenet){
print_imagenet_detections(fp, i+t-nthreads+1, dets, nboxes, classes, w, h);
} else {
print_detector_detections(fps, id, dets, nboxes, classes, w, h);
}
free_detections(dets, nboxes);
free(id);
free_image(val[t]);
free_image(val_resized[t]);
}
}
for(j = 0; j < classes; ++j){
if(fps) fclose(fps[j]);
}
if(coco){
fseek(fp, -2, SEEK_CUR);
fprintf(fp, "n]n");
fclose(fp);
}
fprintf(stderr, "Total Detection Time: %f Secondsn", what_time_is_it_now() - start);
}
void validate_detector_recall(char *datacfg, char *cfgfile, char *weightfile)
{
network *net = load_network(cfgfile, weightfile, 0);
set_batch_network(net, 1);
fprintf(stderr, "Learning Rate: %g, Momentum: %g, Decay: %gn", net->learning_rate, net->momentum, net->decay);
srand(time(0));
//list *plist = get_paths("data/coco_val_5k.list");
//char **paths = (char **)list_to_array(plist);
list *options = read_data_cfg(datacfg);
char *valid_images = option_find_str(options, "valid", "data/train.list");
list *plist = get_paths(valid_images);
char **paths = (char **)list_to_array(plist);
//layer l = net->layers[net->n-1];//为了解决IOU:inf% —— 交并比 数值爆炸的问题1/2
int j, k;
int m = plist->size;
int i=0;
float thresh = .001;
float iou_thresh = .5;
float nms = .4;
int total = 0;
int correct = 0;
int proposals = 0;
float avg_iou = 0;
for(i = 0; i < m; ++i){
char *path = paths[i];
image orig = load_image_color(path, 0, 0);
image sized = resize_image(orig, net->w, net->h);
char *id = basecfg(path);
network_predict(net, sized.data);
int nboxes = 0;
detection *dets = get_network_boxes(net, sized.w, sized.h, thresh, .5, 0, 1, &nboxes);
if (nms) do_nms_obj(dets, nboxes, 1, nms);
char labelpath[4096];
find_replace(path, "images", "labels", labelpath);
find_replace(labelpath, "JPEGImages", "labels", labelpath);
find_replace(labelpath, ".jpg", ".txt", labelpath);
find_replace(labelpath, ".JPEG", ".txt", labelpath);
int num_labels = 0;
box_label *truth = read_boxes(labelpath, &num_labels);
for(k = 0; k < nboxes; ++k){
if(dets[k].objectness > thresh){
++proposals;
}
}
for (j = 0; j < num_labels; ++j) {
++total;
box t = {truth[j].x, truth[j].y, truth[j].w, truth[j].h};
float best_iou = 0;
// for(k = 0; k < l.w*l.h*l.n; ++k){// 为了解决IOU:inf% —— 交并比 数值爆炸的问题2/2
for(k = 0; k < nboxes; ++k){
float iou = box_iou(dets[k].bbox, t);
if(dets[k].objectness > thresh && iou > best_iou){
best_iou = iou;
}
}
avg_iou += best_iou;
if(best_iou > iou_thresh){
++correct;
}
}
fprintf(stderr, "%5d %5d %5dtRPs/Img: %.2ftIOU: %.2f%%tRecall:%.2f%%n", i, correct, total, (float)proposals/(i+1), avg_iou*100/total, 100.*correct/total);
free(id);
free_image(orig);
free_image(sized);
}
}
void test_detector(char *datacfg, char *cfgfile, char *weightfile, char *filename, float thresh, float hier_thresh, char *outfile, int fullscreen)
{
list *options = read_data_cfg(datacfg);
char *name_list = option_find_str(options, "names", "data/names.list");
char **names = get_labels(name_list);
image **alphabet = load_alphabet();
network *net = load_network(cfgfile, weightfile, 0);
set_batch_network(net, 1);
srand(2222222);
double time;
char buff[256];
char *input = buff;
float nms=.45;
int i=0;
while(1){
if(filename){
strncpy(input, filename, 256);
image im = load_image_color(input,0,0);
image sized = letterbox_image(im, net->w, net->h);
//image sized = resize_image(im, net->w, net->h);
//image sized2 = resize_max(im, net->w);
//image sized = crop_image(sized2, -((net->w - sized2.w)/2), -((net->h - sized2.h)/2), net->w, net->h);
//resize_network(net, sized.w, sized.h);
layer l = net->layers[net->n-1];
float *X = sized.data;
time=what_time_is_it_now();
network_predict(net, X);
printf("%s: Predicted in %f seconds.n", input, what_time_is_it_now()-time);
int nboxes = 0;
detection *dets = get_network_boxes(net, im.w, im.h, thresh, hier_thresh, 0, 1, &nboxes);
//printf("%dn", nboxes);
//if (nms) do_nms_obj(boxes, probs, l.w*l.h*l.n, l.classes, nms);
if (nms) do_nms_sort(dets, nboxes, l.classes, nms);
draw_detections(im, dets, nboxes, thresh, names, alphabet, l.classes);
free_detections(dets, nboxes);
if(outfile)
{
save_image(im, outfile);
}
else{
save_image(im, "predictions");
#ifdef OPENCV
cvNamedWindow("predictions", CV_WINDOW_NORMAL);
if(fullscreen){
cvSetWindowProperty("predictions", CV_WND_PROP_FULLSCREEN, CV_WINDOW_FULLSCREEN);
}
//show_image(im, "predictions",0);//这三行注释掉,否则每次都要手动关闭当前图片,才能进行下一张图片的测试1/2
//cvWaitKey(0);
//cvDestroyAllWindows();
#endif
}
free_image(im);
free_image(sized);
if (filename) break;
}
else {
printf("Enter Image Path: ");
fflush(stdout);
input = fgets(input, 256, stdin);
if(!input) return;
strtok(input, "n");
list *plist = get_paths(input);
char **paths = (char **)list_to_array(plist);
printf("Start Testing!n");
int m = plist->size;
if(access("/home/dj/dingjing/darknet/data/out-img",0)==-1)//"/home/FENGsl/darknet/data"修改成自己的路径1/3
{
if (mkdir("/home/dj/dingjing/darknet/data/out-img",0777))//"/home/FENGsl/darknet/data"修改成自己的路径2/3
{
printf("creat file bag failed!!!");
}
}
for(i = 0; i < m; ++i){
char *path = paths[i];
image im = load_image_color(path,0,0);
image sized = letterbox_image(im, net->w, net->h);
//image sized = resize_image(im, net->w, net->h);
//image sized2 = resize_max(im, net->w);
//image sized = crop_image(sized2, -((net->w - sized2.w)/2), -((net->h - sized2.h)/2), net->w, net->h);
//resize_network(net, sized.w, sized.h);
layer l = net->layers[net->n-1];
float *X = sized.data;
time=what_time_is_it_now();
network_predict(net, X);
printf("Try Very Hard:");
printf("%s: Predicted in %f seconds.n", path, what_time_is_it_now()-time);
int nboxes = 0;
detection *dets = get_network_boxes(net, im.w, im.h, thresh, hier_thresh, 0, 1, &nboxes);
//printf("%dn", nboxes);
//if (nms) do_nms_obj(boxes, probs, l.w*l.h*l.n, l.classes, nms);
if (nms) do_nms_sort(dets, nboxes, l.classes, nms);
draw_detections(im, dets, nboxes, thresh, names, alphabet, l.classes);
free_detections(dets, nboxes);
if(outfile){
save_image(im, outfile);
}
else{
char b[2048];
sprintf(b,"/home/dj/dingjing/darknet/data/out-img/%s",GetFilename(path));//"/home/FENGsl/darknet/data"修改成自己的路径3/3
save_image(im, b);
printf("save %s successfully!n",GetFilename(path));
#ifdef OPENCV
cvNamedWindow("predictions", CV_WINDOW_NORMAL);
if(fullscreen){
cvSetWindowProperty("predictions", CV_WND_PROP_FULLSCREEN, CV_WINDOW_FULLSCREEN);
}
//show_image(im, "predictions",0); //这三行注释掉,否则每次都要手动关闭当前图片,才能进行下一张图片的测试2/2
//cvWaitKey(0);
//cvDestroyAllWindows();
#endif
}
free_image(im);
free_image(sized);
if (filename) break;
}
}
}
}
/*
void censor_detector(char *datacfg, char *cfgfile, char *weightfile, int cam_index, const char *filename, int class, float thresh, int skip)
{
#ifdef OPENCV
char *base = basecfg(cfgfile);
network *net = load_network(cfgfile, weightfile, 0);
set_batch_network(net, 1);
srand(2222222);
CvCapture * cap;
int w = 1280;
int h = 720;
if(filename){
cap = cvCaptureFromFile(filename);
}else{
cap = cvCaptureFromCAM(cam_index);
}
if(w){
cvSetCaptureProperty(cap, CV_CAP_PROP_FRAME_WIDTH, w);
}
if(h){
cvSetCaptureProperty(cap, CV_CAP_PROP_FRAME_HEIGHT, h);
}
if(!cap) error("Couldn't connect to webcam.n");
cvNamedWindow(base, CV_WINDOW_NORMAL);
cvResizeWindow(base, 512, 512);
float fps = 0;
int i;
float nms = .45;
while(1){
image in = get_image_from_stream(cap);
//image in_s = resize_image(in, net->w, net->h);
image in_s = letterbox_image(in, net->w, net->h);
layer l = net->layers[net->n-1];
float *X = in_s.data;
network_predict(net, X);
int nboxes = 0;
detection *dets = get_network_boxes(net, in.w, in.h, thresh, 0, 0, 0, &nboxes);
//if (nms) do_nms_obj(boxes, probs, l.w*l.h*l.n, l.classes, nms);
if (nms) do_nms_sort(dets, nboxes, l.classes, nms);
for(i = 0; i < nboxes; ++i){
if(dets[i].prob[class] > thresh){
box b = dets[i].bbox;
int left = b.x-b.w/2.;
int top = b.y-b.h/2.;
censor_image(in, left, top, b.w, b.h);
}
}
show_image(in, base);
cvWaitKey(10);
free_detections(dets, nboxes);
free_image(in_s);
free_image(in);
float curr = 0;
fps = .9*fps + .1*curr;
for(i = 0; i < skip; ++i){
image in = get_image_from_stream(cap);
free_image(in);
}
}
#endif
}
void extract_detector(char *datacfg, char *cfgfile, char *weightfile, int cam_index, const char *filename, int class, float thresh, int skip)
{
#ifdef OPENCV
char *base = basecfg(cfgfile);
network *net = load_network(cfgfile, weightfile, 0);
set_batch_network(net, 1);
srand(2222222);
CvCapture * cap;
int w = 1280;
int h = 720;
if(filename){
cap = cvCaptureFromFile(filename);
}else{
cap = cvCaptureFromCAM(cam_index);
}
if(w){
cvSetCaptureProperty(cap, CV_CAP_PROP_FRAME_WIDTH, w);
}
if(h){
cvSetCaptureProperty(cap, CV_CAP_PROP_FRAME_HEIGHT, h);
}
if(!cap) error("Couldn't connect to webcam.n");
cvNamedWindow(base, CV_WINDOW_NORMAL);
cvResizeWindow(base, 512, 512);
float fps = 0;
int i;
int count = 0;
float nms = .45;
while(1){
image in = get_image_from_stream(cap);
//image in_s = resize_image(in, net->w, net->h);
image in_s = letterbox_image(in, net->w, net->h);
layer l = net->layers[net->n-1];
show_image(in, base);
int nboxes = 0;
float *X = in_s.data;
network_predict(net, X);
detection *dets = get_network_boxes(net, in.w, in.h, thresh, 0, 0, 1, &nboxes);
//if (nms) do_nms_obj(boxes, probs, l.w*l.h*l.n, l.classes, nms);
if (nms) do_nms_sort(dets, nboxes, l.classes, nms);
for(i = 0; i < nboxes; ++i){
if(dets[i].prob[class] > thresh){
box b = dets[i].bbox;
int size = b.w*in.w > b.h*in.h ? b.w*in.w : b.h*in.h;
int dx = b.x*in.w-size/2.;
int dy = b.y*in.h-size/2.;
image bim = crop_image(in, dx, dy, size, size);
char buff[2048];
sprintf(buff, "results/extract/%07d", count);
++count;
save_image(bim, buff);
free_image(bim);
}
}
free_detections(dets, nboxes);
free_image(in_s);
free_image(in);
float curr = 0;
fps = .9*fps + .1*curr;
for(i = 0; i < skip; ++i){
image in = get_image_from_stream(cap);
free_image(in);
}
}
#endif
}
*/
/*
void network_detect(network *net, image im, float thresh, float hier_thresh, float nms, detection *dets)
{
network_predict_image(net, im);
layer l = net->layers[net->n-1];
int nboxes = num_boxes(net);
fill_network_boxes(net, im.w, im.h, thresh, hier_thresh, 0, 0, dets);
if (nms) do_nms_sort(dets, nboxes, l.classes, nms);
}
*/
void run_detector(int argc, char **argv)
{
char *prefix = find_char_arg(argc, argv, "-prefix", 0);
float thresh = find_float_arg(argc, argv, "-thresh", .5);
float hier_thresh = find_float_arg(argc, argv, "-hier", .5);
int cam_index = find_int_arg(argc, argv, "-c", 0);
int frame_skip = find_int_arg(argc, argv, "-s", 0);
int avg = find_int_arg(argc, argv, "-avg", 3);
if(argc < 4){
fprintf(stderr, "usage: %s %s [train/test/valid] [cfg] [weights (optional)]n", argv[0], argv[1]);
return;
}
char *gpu_list = find_char_arg(argc, argv, "-gpus", 0);
char *outfile = find_char_arg(argc, argv, "-out", 0);
int *gpus = 0;
int gpu = 0;
int ngpus = 0;
if(gpu_list){
printf("%sn", gpu_list);
int len = strlen(gpu_list);
ngpus = 1;
int i;
for(i = 0; i < len; ++i){
if (gpu_list[i] == ',') ++ngpus;
}
gpus = calloc(ngpus, sizeof(int));
for(i = 0; i < ngpus; ++i){
gpus[i] = atoi(gpu_list);
gpu_list = strchr(gpu_list, ',')+1;
}
} else {
gpu = gpu_index;
gpus = &gpu;
ngpus = 1;
}
int clear = find_arg(argc, argv, "-clear");
int fullscreen = find_arg(argc, argv, "-fullscreen");
int width = find_int_arg(argc, argv, "-w", 0);
int height = find_int_arg(argc, argv, "-h", 0);
int fps = find_int_arg(argc, argv, "-fps", 0);
//int class = find_int_arg(argc, argv, "-class", 0);
char *datacfg = argv[3];
char *cfg = argv[4];
char *weights = (argc > 5) ? argv[5] : 0;
char *filename = (argc > 6) ? argv[6]: 0;
if(0==strcmp(argv[2], "test")) test_detector(datacfg, cfg, weights, filename, thresh, hier_thresh, outfile, fullscreen);
else if(0==strcmp(argv[2], "train")) train_detector(datacfg, cfg, weights, gpus, ngpus, clear);
else if(0==strcmp(argv[2], "valid")) validate_detector(datacfg, cfg, weights, outfile);
else if(0==strcmp(argv[2], "valid2")) validate_detector_flip(datacfg, cfg, weights, outfile);
else if(0==strcmp(argv[2], "recall")) validate_detector_recall(datacfg, cfg, weights);
else if(0==strcmp(argv[2], "demo")) {
list *options = read_data_cfg(datacfg);
int classes = option_find_int(options, "classes", 20);
char *name_list = option_find_str(options, "names", "data/names.list");
char **names = get_labels(name_list);
demo(cfg, weights, thresh, cam_index, filename, names, classes, frame_skip, prefix, avg, hier_thresh, width, height, fps, fullscreen);
}
//else if(0==strcmp(argv[2], "extract")) extract_detector(datacfg, cfg, weights, cam_index, filename, class, thresh, frame_skip);
//else if(0==strcmp(argv[2], "censor")) censor_detector(datacfg, cfg, weights, cam_index, filename, class, thresh, frame_skip);
}
③reval_voc.py
#!/usr/bin/env python
# Adapt from ->
# --------------------------------------------------------
# Fast R-CNN
# Copyright (c) 2015 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Written by Ross Girshick
# --------------------------------------------------------
# <- Written by Yaping Sun
"""Reval = re-eval. Re-evaluate saved detections."""
import os, sys, argparse
import numpy as np
import _pickle as cPickle
#import cPickle
from voc_eval import voc_eval
def parse_args():
"""
Parse input arguments
"""
parser = argparse.ArgumentParser(description='Re-evaluate results')
parser.add_argument('output_dir', nargs=1, help='results directory',
type=str)
parser.add_argument('--voc_dir', dest='voc_dir', default='data/VOCdevkit', type=str)
parser.add_argument('--year', dest='year', default='2017', type=str)
parser.add_argument('--image_set', dest='image_set', default='test', type=str)
parser.add_argument('--classes', dest='class_file', default='data/voc.names', type=str)
if len(sys.argv) == 1:
parser.print_help()
sys.exit(1)
args = parser.parse_args()
return args
def get_voc_results_file_template(image_set, out_dir = 'results'):
filename = 'comp4_det_' + image_set + '_{:s}.txt'
path = os.path.join(out_dir, filename)
return path
def do_python_eval(devkit_path, year, image_set, classes, output_dir = 'results'):
annopath = os.path.join(
devkit_path,
'VOC' + year,
'Annotations',
'{}.xml')
imagesetfile = os.path.join(
devkit_path,
'VOC' + year,
'ImageSets',
'Main',
image_set + '.txt')
cachedir = os.path.join(devkit_path, 'annotations_cache')
aps = []
# The PASCAL VOC metric changed in 2010
use_07_metric = True if int(year) < 2010 else False
print('VOC07 metric? ' + ('Yes' if use_07_metric else 'No'))
print('devkit_path=',devkit_path,', year = ',year)
if not os.path.isdir(output_dir):
os.mkdir(output_dir)
for i, cls in enumerate(classes):
if cls == '__background__':
continue
filename = get_voc_results_file_template(image_set).format(cls)
rec, prec, ap = voc_eval(
filename, annopath, imagesetfile, cls, cachedir, ovthresh=0.5,
use_07_metric=use_07_metric)
aps += [ap]
print('AP for {} = {:.4f}'.format(cls, ap))
with open(os.path.join(output_dir, cls + '_pr.pkl'), 'wb') as f:
cPickle.dump({'rec': rec, 'prec': prec, 'ap': ap}, f)
print('Mean AP = {:.4f}'.format(np.mean(aps)))
print('~~~~~~~~')
print('Results:')
for ap in aps:
print('{:.3f}'.format(ap))
print('{:.3f}'.format(np.mean(aps)))
print('~~~~~~~~')
print('')
print('--------------------------------------------------------------')
print('Results computed with the **unofficial** Python eval code.')
print('Results should be very close to the official MATLAB eval code.')
print('-- Thanks, The Management')
print('--------------------------------------------------------------')
if __name__ == '__main__':
args = parse_args()
output_dir = os.path.abspath(args.output_dir[0])
with open(args.class_file, 'r') as f:
lines = f.readlines()
classes = [t.strip('n') for t in lines]
print('Evaluating detections')
do_python_eval(args.voc_dir, args.year, args.image_set, classes, output_dir)
④voc_eval.py
# --------------------------------------------------------
# Fast/er R-CNN
# Licensed under The MIT License [see LICENSE for details]
# Written by Bharath Hariharan
# --------------------------------------------------------
import xml.etree.ElementTree as ET
import os
#import cPickle
import _pickle as cPickle
import numpy as np
def parse_rec(filename):
""" Parse a PASCAL VOC xml file """
tree = ET.parse(filename)
objects = []
for obj in tree.findall('object'):
obj_struct = {}
obj_struct['name'] = obj.find('name').text
#obj_struct['pose'] = obj.find('pose').text
#obj_struct['truncated'] = int(obj.find('truncated').text)
obj_struct['difficult'] = int(obj.find('difficult').text)
bbox = obj.find('bndbox')
obj_struct['bbox'] = [int(bbox.find('xmin').text),
int(bbox.find('ymin').text),
int(bbox.find('xmax').text),
int(bbox.find('ymax').text)]
objects.append(obj_struct)
return objects
def voc_ap(rec, prec, use_07_metric=False):
""" ap = voc_ap(rec, prec, [use_07_metric])
Compute VOC AP given precision and recall.
If use_07_metric is true, uses the
VOC 07 11 point method (default:False).
"""
if use_07_metric:
# 11 point metric
ap = 0.
for t in np.arange(0., 1.1, 0.1):
if np.sum(rec >= t) == 0:
p = 0
else:
p = np.max(prec[rec >= t])
ap = ap + p / 11.
else:
# correct AP calculation
# first append sentinel values at the end
mrec = np.concatenate(([0.], rec, [1.]))
mpre = np.concatenate(([0.], prec, [0.]))
# compute the precision envelope
for i in range(mpre.size - 1, 0, -1):
mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i])
# to calculate area under PR curve, look for points
# where X axis (recall) changes value
i = np.where(mrec[1:] != mrec[:-1])[0]
# and sum (Delta recall) * prec
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1])
return ap
def voc_eval(detpath,
annopath,
imagesetfile,
classname,
cachedir,
ovthresh=0.5,
use_07_metric=False):
"""rec, prec, ap = voc_eval(detpath,
annopath,
imagesetfile,
classname,
[ovthresh],
[use_07_metric])
Top level function that does the PASCAL VOC evaluation.
detpath: Path to detections
detpath.format(classname) should produce the detection results file.
annopath: Path to annotations
annopath.format(imagename) should be the xml annotations file.
imagesetfile: Text file containing the list of images, one image per line.
classname: Category name (duh)
cachedir: Directory for caching the annotations
[ovthresh]: Overlap threshold (default = 0.5)
[use_07_metric]: Whether to use VOC07's 11 point AP computation
(default False)
"""
# assumes detections are in detpath.format(classname)
# assumes annotations are in annopath.format(imagename)
# assumes imagesetfile is a text file with each line an image name
# cachedir caches the annotations in a pickle file
# first load gt
if not os.path.isdir(cachedir):
os.mkdir(cachedir)
cachefile = os.path.join(cachedir, 'annots.pkl')
# read list of images
with open(imagesetfile, 'r') as f:
lines = f.readlines()
imagenames = [x.strip() for x in lines]
if not os.path.isfile(cachefile):
# load annots
recs = {}
for i, imagename in enumerate(imagenames):
recs[imagename] = parse_rec(annopath.format(imagename))
#if i % 100 == 0:
#print('Reading annotation for {:d}/{:d}').format(i + 1, len(imagenames))
# save
#print('Saving cached annotations to {:s}').format(cachefile)
with open(cachefile, 'wb') as f:
cPickle.dump(recs, f)
else:
# load
print('!!! cachefile = ',cachefile)
with open(cachefile, 'rb') as f:
recs = cPickle.load(f)
# extract gt objects for this class
class_recs = {}
npos = 0
for imagename in imagenames:
R = [obj for obj in recs[imagename] if obj['name'] == classname]
bbox = np.array([x['bbox'] for x in R])
difficult = np.array([x['difficult'] for x in R]).astype(np.bool)
det = [False] * len(R)
npos = npos + sum(~difficult)
class_recs[imagename] = {'bbox': bbox,
'difficult': difficult,
'det': det}
# read dets
detfile = detpath.format(classname)
with open(detfile, 'r') as f:
lines = f.readlines()
splitlines = [x.strip().split(' ') for x in lines]
image_ids = [x[0] for x in splitlines]
confidence = np.array([float(x[1]) for x in splitlines])
BB = np.array([[float(z) for z in x[2:]] for x in splitlines])
# sort by confidence
sorted_ind = np.argsort(-confidence)
sorted_scores = np.sort(-confidence)
BB = BB[sorted_ind, :]
image_ids = [image_ids[x] for x in sorted_ind]
# go down dets and mark TPs and FPs
nd = len(image_ids)
tp = np.zeros(nd)
fp = np.zeros(nd)
for d in range(nd):
R = class_recs[image_ids[d]]
bb = BB[d, :].astype(float)
ovmax = -np.inf
BBGT = R['bbox'].astype(float)
if BBGT.size > 0:
# compute overlaps
# intersection
ixmin = np.maximum(BBGT[:, 0], bb[0])
iymin = np.maximum(BBGT[:, 1], bb[1])
ixmax = np.minimum(BBGT[:, 2], bb[2])
iymax = np.minimum(BBGT[:, 3], bb[3])
iw = np.maximum(ixmax - ixmin + 1., 0.)
ih = np.maximum(iymax - iymin + 1., 0.)
inters = iw * ih
# union
uni = ((bb[2] - bb[0] + 1.) * (bb[3] - bb[1] + 1.) +
(BBGT[:, 2] - BBGT[:, 0] + 1.) *
(BBGT[:, 3] - BBGT[:, 1] + 1.) - inters)
overlaps = inters / uni
ovmax = np.max(overlaps)
jmax = np.argmax(overlaps)
if ovmax > ovthresh:
if not R['difficult'][jmax]:
if not R['det'][jmax]:
tp[d] = 1.
R['det'][jmax] = 1
else:
fp[d] = 1.
else:
fp[d] = 1.
# compute precision recall
fp = np.cumsum(fp)
tp = np.cumsum(tp)
rec = tp / float(npos)
# avoid divide by zero in case the first detection matches a difficult
# ground truth
prec = tp / np.maximum(tp + fp, np.finfo(np.float64).eps)
ap = voc_ap(rec, prec, use_07_metric)
return rec, prec, ap
⑤xml2txt.py
#_*_coding:utf-8
import os
import random
# 0.9,0.9能够保证此时的train:val:test = 8:1:1
xmlfilepath="./Annotations" # xml文件路径
txtsavepath="./ImageSets/Main" # txt文件保存路径
trainval_percent=0.9 # trainval集占整个数据集的百分比,剩下的就是test集所占的百分比
train_percent=0.9 # train集占trainval集的百分比,剩下的就是val集所占的百分比
def xml_to_txt():
xmllist=os.listdir(xmlfilepath) # 导入xml文件列表
xml_num=len(xmllist) # xml文件数量
num_list=range(xml_num) # 将xml文件分别用数字表示,从0到xml_num(不包含xml_num)
trainval_num=int(xml_num*trainval_percent) # trainval集样本数量
trainval=random.sample(num_list,trainval_num) #从num_list个xml文件中随机选取trainval_num个当作trainval数据集
train_num=int(trainval_num*train_percent) # train集样本数量
train=random.sample(trainval,train_num) # 从trainval集中随机选取train_num个当作train数据集
ftrainval=open(txtsavepath+'/trainval.txt','w')
ftest=open(txtsavepath+'/test.txt','w')
ftrain=open(txtsavepath+'/train.txt','w')
fval=open(txtsavepath+'/val.txt','w')
for i in num_list:
name=xmllist[i][:-4]+'n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
xml_to_txt() # 调用转换函数
⑥voc_label.py
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2007', 'train'), ('2007', 'trainval'), ('2007', 'test'), ('2007', 'val')]
#classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
#classes = ["excreting","notexcreting","likeboarurination"]
#classes = ["0","1","2","3","4","5","6","7","8","F","H","X"]
#classes = ["sickfeces"]
classes = ["excreting","notexcreting","likeboarurination","0","1","2","3","4","5","6","7","8","f","h","x","sickfeces"]
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + 'n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpgn'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
#os.system("cat 2007_train.txt 2007_val.txt > train.txt")
#os.system("cat 2007_train.txt 2007_val.txt 2007_test.txt 2007_trainval.txt> train.all.txt")
⑦yolov3-voc.cfg
[net]
# Testing
# batch=1
# subdivisions=1
# Training
batch=64
subdivisions=16
width=608
height=608
channels=3
momentum=0.9
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
learning_rate=0.001
burn_in=1000
max_batches = 30000
policy=steps
steps=24000,27000
scales=.1,.1
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
# Downsample
[convolutional]
batch_normalize=1
filters=64
size=3
stride=2
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
# Downsample
[convolutional]
batch_normalize=1
filters=128
size=3
stride=2
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
# Downsample
[convolutional]
batch_normalize=1
filters=256
size=3
stride=2
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
# Downsample
[convolutional]
batch_normalize=1
filters=512
size=3
stride=2
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
# Downsample
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=2
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
######################
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=63
activation=linear
[yolo]
mask = 6,7,8
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=16
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=1
[route]
layers = -4
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[upsample]
stride=2
[route]
layers = -1, 61
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=63
activation=linear
[yolo]
mask = 3,4,5
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=16
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=1
[route]
layers = -4
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[upsample]
stride=2
[route]
layers = -1, 36
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=63
activation=linear
[yolo]
mask = 0,1,2
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=16
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=1
最后
以上就是感性火龙果最近收集整理的关于【全套完整版本】YOLOv3使用方法记录0 重要文件结构梳理1 前期安装和环境配置2 训练3 模型测试4 训练过程分析5 附录的全部内容,更多相关【全套完整版本】YOLOv3使用方法记录0内容请搜索靠谱客的其他文章。


![[总结]FFMPEG命令行工具之ffprobe详解0 前言1 语法 Synopsis2 描述 Description3 选项 Options](https://www.shuijiaxian.com/files_image/reation/bcimg14.png)





发表评论 取消回复