n 个 generic blendshape A
m 个特定人脸的scan
目标是:结合A(模板的blendshape)和S(特定人的scan)生成B(特定人的blendshape),使得scan(S)可以通过特定人的blendshape(B)生成
-
If only very few training poses are given
scan的数量少 -
And secondly, how can we achieve the right controller semantics, i.e., ensure that similar weight settings lead to semantically similar expressions for both the template and the target blendshape models?
即A和B在相似的权值结合下有相似的语意 -
As we show in Sec- tion 4, this leads to significant improvements compared to a direct optimization of blendshape vertex positions.
去匹配点的local frame(坐标系), 而不是点的位置 -
E f i t E_{fit} Efit匹配scan中第j种pose中的frame
-
E r e g E_{reg} Ereg : blendshape i, 在A中deformation gradients中位移以及在B中deformation gradients中的位移应该similar
-
Our experiments showed that evaluating the regularization weights as
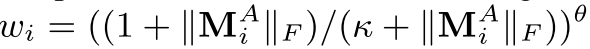 )
)
位移越小,权值越大, 位移越大, 权值越小
最后
以上就是光亮大白最近收集整理的关于Example-Based Facial Rigging的全部内容,更多相关Example-Based内容请搜索靠谱客的其他文章。








发表评论 取消回复