Spark
- 简介
- 什么是Spark
- Spark和MR比较
- Spark运行方式
- RDD
- RDD的五大特性
- 哪里体现RDD的弹性(容错)?
- 哪里体现RDD的分布式?
- Spark代码流程
- 算子
- 转换算子Transformations
- 行动算子Action触发执行
- 控制算子(做持久化)
- 资源调度和任务调度
- 推测机制
- 集群搭建以及测试
- 搭建
- Standalone
- yarn
- 测试
- 相关术语
- Standalone模式两种提交任务方式
- Standalone-client提交任务方式
- Standalone-cluster提交任务方式
- 总结Standalone两种方式提交任务,Driver与集群的通信包括:
- Yarn模式两种提交任务方式
- yarn-client提交任务方式
- yarn-cluster提交任务方式
- 窄依赖和宽依赖
- 窄依赖
- 宽依赖
- Stage
- Stage切割规则
- Stage计算模式
- PV&UV
- Spark-Submit提交参数
- 二次排序
- 分组取topN和topN
- SparkShell的使用
- SparkUI
- Master HA
- Master的高可用原理
- Master高可用搭建
- 注意点
- 测试验证
- 广播变量和累加器
- 广播变量
- 累加器
- 资源调度源码分析
- 任务调度源码分析
- SparkShuffle
- SparkShuffle概念
- HashShuffle
- SortShuffle
- Shuffle文件寻址
- Spark内存管理
- Shuffle调优
- SparkSql
- Shark
- SparkSQL
- 创建Dataset的几种方式
- 读取json格式的文件创建Dataset
- 通过json格式的RDD创建Dataset
- 非json格式的RDD创建Dataset
- 读取parquet文件创建Dataset
- 读取JDBC中的数据创建Dataset(MySql为例)
- 读取Hive中的数据加载成Dataset
- Spark On Hive的配置
- 序列化问题。
- 储存DataSet
- 自定义函数UDF和UDAF
- 开窗函数
- Spark Streaming
- SparkStreaming简介
- SparkStreaming与Storm的区别
- SparkStreaming初始
- SparkStreaming算子操作
- Driver HA(Standalone或者Mesos)
- SparkStreaming+Kafka
简介
什么是Spark
- Spark 是专为大规模数据处理而设计的快速通用的计算引擎。
Spark和MR比较
- Spark 一般速度比MR快10倍,在迭代计算的场景下可以快100倍
- Spark快的原因是:Spark基于内存,MR基于HDFS,Spark还有DAG有向无环图来切分任务的执行先后顺序
Spark运行方式
- Local:多用于本地测试,如在eclipse,idea中写程序测试等。
- Standalone:是Spark自带的一个资源调度框架,它支持完全分布式
- Yarn:Hadoop生态圈里面的一个资源调度框架,Spark也是可以基于Yarn来计算的。要基于Yarn来进行资源调度,必须实现AppalicationMaster接口,Spark实现了这个接口,所以可以基于Yarn。
- Mesos:资源调度框架。
RDD
RDD(Resilient Distributed Dateset),弹性分布式数据集
RDD的五大特性
- RDD是由一系列的partition组成的。
- 函数是作用在每一个partition(split)上的。
- RDD之间有一系列的依赖关系。
- 分区器是作用在K,V格式的RDD上。
- RDD提供一系列最佳的计算位置。体现了大数据计算的“计算移动,数据不移动”的理念
哪里体现RDD的弹性(容错)?
- partition数量,大小没有限制,体现了RDD的弹性。
- RDD之间依赖关系,可以基于上一个RDD重新计算出RDD。
哪里体现RDD的分布式?
-RDD是由Partition组成,partition是分布在不同节点上的。
Spark代码流程
- 创建SparkConf对象
- 可以设置Application name。
- 可以设置运行模式及资源需求。
- 创建SparkContext对象
- 基于Spark的上下文创建一个RDD,对RDD进行处理。
- 应用程序中要有Action类算子来触发Transformation类算子执行。
- 关闭Spark上下文对象SparkContext。
算子
转换算子Transformations
- map:将一个RDD中的每个数据项,通过map中的函数映射变为一个新的元素。特点:输入一条,输出一条数据。
- mapToPair
- flatmap:先map后flat。与map类似,每个输入项可以映射为0到多个输出项。
- flatMapToPair
- reduceBykey:将相同的Key根据相应的逻辑进行处理
- filter:过滤符合条件的记录数,true保留,false过滤掉
- sortBy/sortBykey:作用在K,V格式的RDD上,对key进行升序或者降序排序。
- sample:随机抽样算子,根据传进去的小数按比例进行又放回或者无放回的抽样
- union:合并两个数据集。两个数据集的类型要一致。返回新的RDD的分区数是合并RDD分区数的总和。
- join,leftOuterJoin,rightOuterJoin,fullOuterJoin:作用在K,V格式的RDD上。根据K进行连接,对(K,V)join(K,W)返回(K,(V,W))。join后的分区数与父RDD分区数多的那一个相同。
- cogroup:当调用类型(K,V)和(K,W)的数据上时,返回一个数据集(K,(Iterable,Iterable))
- crossProduct
- mapValues
- sort
- partitionBy
- intersection:取两个数据集的交集
- subtract:取两个数据集的差集
- mapPartition:与map类似,遍历的单位是每个partition上的数据。
- distinct(map+reduceByKey+map):去重
- mapPartitionWithIndex:类似于mapPartitions,除此之外还会携带分区的索引值。
- repartition:增加或减少分区。会产生shuffle
- coalesce:coalesce常用来减少分区。例子:coalesce(numPartitions,true),true为产生shuffle,false不产生shuffle。默认是false。如果coalesce设置的分区数比原来的RDD的分区数还多的话,第二个参数设置为false不会起作用,如果设置成true,效果和repartition一样。即repartition(numPartitions) = coalesce(numPartitions,true)
- groupByKey:作用在K,V格式的RDD上。根据Key进行分组。作用在(K,V),返回(K,Iterable )。
- zip:将两个RDD中的元素(KV格式/非KV格式)变成一个KV格式的RDD,两个RDD的个数必须相同。
- zipWithIndex:该函数将RDD中的元素和这个元素在RDD中的索引号(从0开始)组合成(K,V)对。
行动算子Action触发执行
一个application应用程序中有几个Action类算子执行,就有几个job运行。
- foreach:循环遍历数据集中的每个元素,运行相应的逻辑。
- take:返回一个包含数据集前n个元素的集合。
- count:返回数据集中的元素数。
- countByKey:作用到K,V格式的RDD上,根据Key计数相同Key的数据集元素。
- countByValue:根据数据集每个元素相同的内容来计数。返回相同内容的元素对应的条数。
- reduce:根据聚合逻辑聚合数据集中的每个元素。
- first:first=take(1),返回数据集中的第一个元素。
- collect:将计算结果回收到Driver端。
- lookup
- save
- foreachPartition:遍历的数据是每个partition的数据。
控制算子(做持久化)
- cache:默认将RDD的数据持久化到内存中
PS:chche () = persist()=persist(StorageLevel.Memory_Only)
SparkConf conf = new SparkConf(); conf.setMaster("local").setAppName("CacheTest"); JavaSparkContext jsc = new JavaSparkContext(conf); JavaRDD<String> lines = jsc.textFile("./NASA_access_log_Aug95"); lines = lines.cache(); long startTime = System.currentTimeMillis(); long count = lines.count(); long endTime = System.currentTimeMillis(); System.out.println("共"+count+ "条数据,"+"初始化时间+cache时间+计算时间="+ (endTime-startTime)); long countStartTime = System.currentTimeMillis(); long countrResult = lines.count(); long countEndTime = System.currentTimeMillis(); System.out.println("共"+countrResult+ "条数据,"+"计算时间="+ (countEndTime- countStartTime)); jsc.stop();
- persist:可以指定持久化的级别。常用的是MEMORY_ONLY和MEMORY_AND_DISK。”_2”表示有副本数。持久化级别如下:
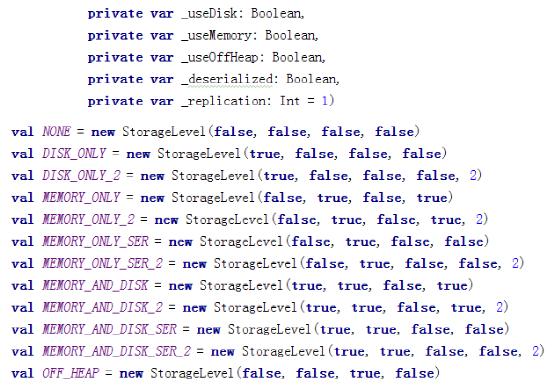
注意:cache和persist的注意事项:
- cache和persist都是懒执行,必须有一个action类算子触发执行。
- cache和persist算子的返回值可以赋值给一个变量,在其他job中直接使用这个变量就是使用持久化的数据了。持久化的单位是partition。
- cache和persist算子后不能立即紧跟action算子。
- checkpoint:checkpoint将RDD持久化到磁盘,还可以切断RDD之间的依赖关系。
- checkpoint 的执行原理:
a. 当RDD的job执行完毕后,会从finalRDD从后往前回溯。
b. 当回溯到某一个RDD调用了checkpoint方法,会对当前的RDD做一个标记。
c. Spark框架会自动启动一个新的job,重新计算这个RDD的数据,将数据持久化到HDFS上。 - 优化:对RDD执行checkpoint之前,最好对这个RDD先执行cache,这样新启动的job只需要将内存中的数据拷贝到HDFS上就可以,省去了重新计算这一步。
SparkConf conf = new SparkConf(); conf.setMaster("local").setAppName("checkpoint"); JavaSparkContext sc = new JavaSparkContext(conf); sc.setCheckpointDir("./checkpoint"); JavaRDD<Integer> parallelize = sc.parallelize(Arrays.asList(1,2,3)); parallelize.checkpoint(); parallelize.count(); sc.stop();
资源调度和任务调度
当Spark提交一个Application后,根据RDD之间的依赖关系将Application形成一个DAG有向无环图。任务提交后,Spark会在Driver端创建两个对象:DAGScheduler和TaskScheduler
- DAGScheduler将DAG根据RDD之间的宽窄依赖关系划分为一个个的Stage
- 然后将这些Stage以TaskSet的形式提交给TaskScheduler
- TaskScheduler会遍历TaskSet集合,拿到每个task后会将task发送到计算节点Executor中去执行.
- 当task执行失败时,则由TaskScheduler负责重试,将task重新发送给Executor去执行,默认重试3次。如果重试3次依然失败,那么这个task所在的stage就失败了。
- stage失败了则由DAGScheduler来负责重试,重新发送TaskSet到TaskSchdeuler,Stage默认重试4次。如果重试4次以后依然失败,那么这个job就失败了,Application就失败了。
推测机制
如果有运行缓慢的task那么TaskScheduler会启动一个新的task来与这个运行缓慢的task执行相同的处理逻辑。两个task哪个先执行完,就以哪个task的执行结果为准。
集群搭建以及测试
搭建
Standalone
-
下载安装包(略),解压

-
改名

-
进入安装包的conf目录下,修改slaves.template文件,
先把slaves.template文件名改成 slaves

然后添加从节点。保存。

-
修改spark-env.sh.template 文件名为 spark-env.sh

然后编辑spark-env.sh文件,进行配置:
JAVA_HOME:配置java_home路径
SPARK_MASTER_IP:master的ip
SPARK_MASTER_PORT:提交任务的端口,默认是7077
SPARK_WORKER_CORES:每个worker从节点能够支配的core的个数
SPARK_WORKER_MEMORY:每个worker从节点能够支配的内存数
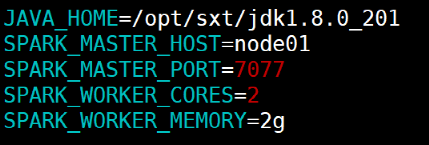
-
同步到其他节点上


-
启动集群
进入sbin目录下,执行当前目录下的./start-all.sh

-
访问master:8080端口:
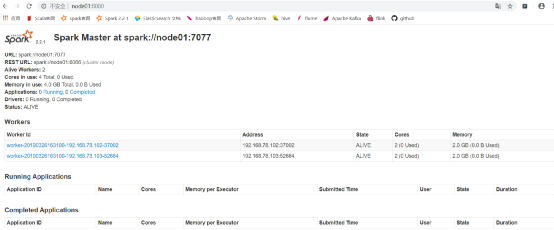
-
搭建客户端
将spark安装包原封不动的拷贝到一个新的节点上,然后,在新的节点上提交任务可。
注意:
- 8080是Spark WEBUI界面的端口,7077是Spark任务提交的端口。
- 修改master的WEBUI端口:
- 修改start-master.sh即可。
yarn
- 1,2,3,4,5,7步同standalone。
- 在客户端中配置:
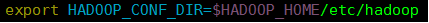
测试
- PI案例:
- Standalone提交命令:
./spark-submit --master spark://node01:7077 --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.11-2.2.1.jar 100
- YARN提交命令:
./spark-submit --master yarn --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.11-2.2.1.jar 100
注意:yarn运行方式的时候,若运行失败,在yarn的web界面上面看到如下日志:
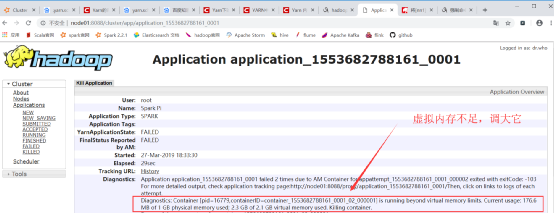
即: Current usage: 176.6 MB of 1 GB physical memory used; 2.3 GB of 2.1 GB virtual memory used. Killing container. 这种错误,代表虚拟内存不足,可通过以下两种方式解决:
- 调大虚拟内存比:yarn.nodemanager.vmem-pmem-ratio 默认2.1倍
- 或者关闭虚拟内存检查:yarn.nodemanager.vmem-check-enabled 默认true
以上两种配置,都在yarn-site.xml里配置,配置完后,重启yarn。stop-yarn.sh -> start-yarn.sh
相关术语

Standalone模式两种提交任务方式
Standalone-client提交任务方式
- 提交命令
./spark-submit --master spark://node1:7077 --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.11-2.2.1.jar 1000
或者
./spark-submit --master spark://node1:7077 --deploy-mode client --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.11-2.2.1.jar 100
- 执行原理图解
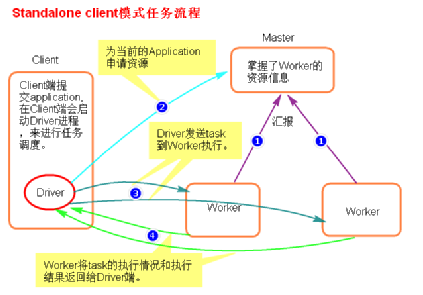
- 执行流程
a. client模式提交任务后,会在客户端启动Driver进程。
b. Driver会向Master申请启动Application启动的资源。
c. 资源申请成功,Driver端将task发送到worker端执行。
d. Worker端将task执行结果返回到Driver端。 - 总结
client模式适用于测试调试程序。Driver进程是在客户端启动的,这里的客户端就是指提交应用程序的当前节点。在Driver端可以看到task执行的情况。生产环境下不能使用client模式,是因为:假设要提交100个application到集群运行,Driver每次都会在client端启动,那么就会导致客户端100次网卡流量暴增的问题。
Standalone-cluster提交任务方式
- 提交命令
./spark-submit --master spark://node1:7077 --deploy-mode cluster --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.11-2.2.1.jar 100
注意:Standalone-cluster提交方式,应用程序使用的所有jar包和文件,必须保证所有的worker节点都要有,因为此种方式,spark不会自动上传包。
解决方式:
a. 将所有的依赖包和文件打到同一个包中,然后放在hdfs上。
b. 将所有的依赖包和文件各放一份在worker节点上。
- 执行原理图解
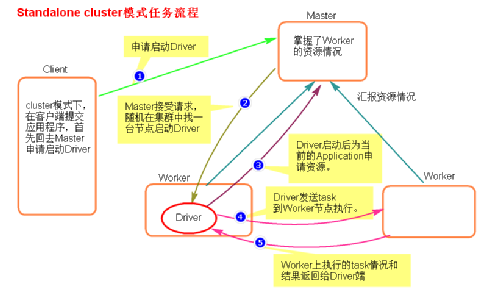
- 执行流程
a. cluster模式提交应用程序后,会向Master请求启动Driver.
b. Master接受请求,随机在集群一台节点启动Driver进程。
c. Driver启动后为当前的应用程序申请资源。
d. Driver端发送task到worker节点上执行。
e. worker将执行情况和执行结果返回给Driver端。
总结
Driver进程是在集群某一台Worker上启动的,在客户端是无法查看task的执行情况的。假设要提交100个application到集群运行,每次Driver会随机在集群中某一台Worker上启动,那么这100次网卡流量暴增的问题就散布在集群上。
总结Standalone两种方式提交任务,Driver与集群的通信包括:
- Driver负责应用程序资源的申请
- 任务的分发。
- 结果的回收。
- 监控task执行情况。
Yarn模式两种提交任务方式
yarn-client提交任务方式
- 提交命令
./spark-submit --master yarn --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.11-2.2.1.jar 100
或者
./spark-submit --master yarn–client --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.11-2.2.1.jar 100
或者
./spark-submit --master yarn --deploy-mode client --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.11-2.2.1.jar 100
- 执行原理图解
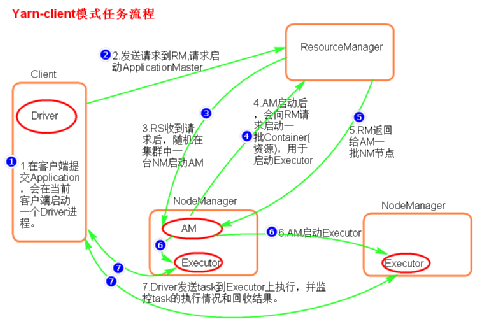
- 执行流程
a. 客户端提交一个Application,在客户端启动一个Driver进程。
b. 应用程序启动后会向RS(ResourceManager)发送请求,启动AM(ApplicationMaster)的资源。
c. RS收到请求,随机选择一台NM(NodeManager)启动AM。这里的NM相当于Standalone中的Worker节点。
d. AM启动后,会向RS请求一批container资源,用于启动Executor.
e. RS会找到一批NM返回给AM,用于启动Executor。
f. AM会向NM发送命令启动Executor。
g. Executor启动后,会反向注册给Driver,Driver发送task到Executor,执行情况和结果返回给Driver端。 - 总结
Yarn-client模式同样是适用于测试,因为Driver运行在本地,Driver会与yarn集群中的Executor进行大量的通信,会造成客户机网卡流量的大量增加.
ApplicationMaster的作用:
a. 为当前的Application申请资源
b. 给NodeManager发送消息启动Executor。
注意:ApplicationMaster有launchExecutor和申请资源的功能,并没有作业调度的功能。
yarn-cluster提交任务方式
-
提交命令
./spark-submit
–master yarn
–deploy-mode cluster
–class org.apache.spark.examples.SparkPi
…/examples/jars/spark-examples_2.11-2.2.1.jar
100
或者
./spark-submit
–master yarn-cluster
–class org.apache.spark.examples.SparkPi
…/examples/jars/spark-examples_2.11-2.2.1.jar
100 -
执行原理图解
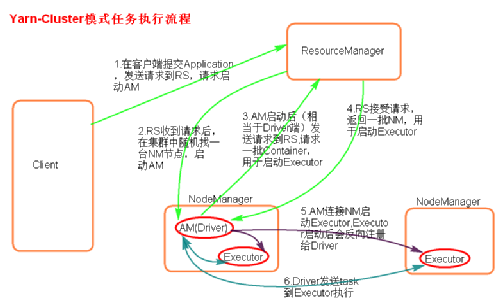
-
执行流程
a. 客户机提交Application应用程序,发送请求到RS(ResourceManager),请求启动AM(ApplicationMaster)。
b. RS收到请求后随机在一台NM(NodeManager)上启动AM(相当于Driver端)。
c. AM启动,AM发送请求到RS,请求一批container用于启动Excutor。
d. RS返回一批NM节点给AM。
e. AM连接到NM,发送请求到NM启动Excutor。
f. Excutor反向注册到AM所在的节点的Driver。Driver发送task到Excutor。 -
总结
Yarn-Cluster主要用于生产环境中,因为Driver运行在Yarn集群中某一台nodeManager中,每次提交任务的Driver所在的机器都是随机的,不会产生某一台机器网卡流量激增的现象,缺点是任务提交后不能看到日志。只能通过yarn查看日志。
ApplicationMaster的作用:
a. 为当前的Application申请资源
b. 给NodeManger发送消息启动Excutor。
c. 任务调度。
停止集群任务命令:yarn application -kill applicationID
窄依赖和宽依赖
- RDD之间有一系列的依赖关系,依赖关系又分为窄依赖和宽依赖。
窄依赖
- 父RDD和子RDD partition之间的关系是一对一的。不会有shuffle的产生。
- 父RDD和子RDD partition之间的关系是多对一的。不会有shuffle的产生。
宽依赖
父RDD与子RDD partition之间的关系是一对多。会有shuffle的产生。
Stage
Stage切割规则
- Spark任务会根据RDD之间的依赖关系,形成一个DAG有向无环图
- DAG会提交给DAGScheduler,DAGScheduler会把DAG划分相互依赖的多个stage,划分stage的依据就是RDD之间的宽窄依赖。
- 遇到宽依赖就划分stage,每个stage包含一个或多个task任务。然后将这些task以taskSet的形式提交给TaskScheduler运行。
- stage是由一组并行的task组成
Stage计算模式
pipeline管道计算模式,pipeline只是一种计算思想,模式。
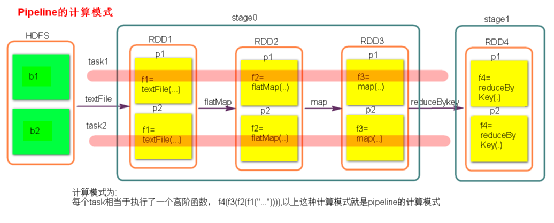
- 数据一直在管道里面什么时候数据会落地?
- 对RDD进行持久化。
- shuffle write的时候。
- Stage的task并行度是由stage的最后一个RDD的分区数来决定的 。
- 如何改变RDD的分区数?
- 例如:reduceByKey(XXX,3),GroupByKey(4)
- 相关代码
val conf = new SparkConf() conf.setMaster("local").setAppName("pipeline"); val sc = new SparkContext(conf) val rdd = sc.parallelize(Array(1,2,3,4)) val rdd1 = rdd.map { x => { println("map--------"+x) x }} val rdd2 = rdd1.filter { x => { println("fliter********"+x) true } } rdd2.collect() sc.stop()
PV&UV
- 什么是PV值
PV(page view)即页面浏览量或点击量,是衡量一个网站或网页用户访问量。 - 什么是UV值
UV(unique visitor)即独立访客数,指访问某个站点或点击某个网页的不同IP地址的人数。在同一天内,UV只记录第一次进入网站的具有独立IP的访问者,在同一天内再次访问该网站则不计数。
Spark-Submit提交参数
- Options:
- master
MASTER_URL, 可以是spark://host:port, mesos://host:port, yarn, yarn-cluster,yarn-client, local - deploy-mode
DEPLOY_MODE, Driver程序运行的地方,client或者cluster,默认是client。 - class
CLASS_NAME, 主类名称,含包名 - jars
逗号分隔的本地JARS, Driver和executor依赖的第三方jar包 - files
用逗号隔开的文件列表,会放置在每个executor工作目录中 - conf
spark的配置属性 - driver-memory
Driver程序使用内存大小(例如:1000M,5G),默认1024M - executor-memory
每个executor内存大小(如:1000M,2G),默认1G
- Spark standalone with cluster deploy mode only:
- driver-cores
Driver程序的使用core个数(默认为1),仅限于Spark standalone模式
- Spark standalone or Mesos with cluster deploy mode only:
- supervise
失败后是否重启Driver,仅限于Spark alone或者Mesos模式
- Spark standalone and Mesos only:
- total-executor-cores
executor使用的总核数,仅限于SparkStandalone、Spark on Mesos模式
- Spark standalone and YARN only:
- executor-cores
每个executor使用的core数,Spark on Yarn默认为1,standalone默认为worker上所有可用的core。
- YARN-only:
- driver-cores
driver使用的core,仅在cluster模式下,默认为1。 - queue
QUEUE_NAME 指定资源队列的名称,默认:default - num-executors
一共启动的executor数量,默认是2个。
二次排序
SparkConf sparkConf = new SparkConf() .setMaster("local") .setAppName("SecondarySortTest"); final JavaSparkContext sc = new JavaSparkContext(sparkConf); JavaRDD<String> secondRDD = sc.textFile("secondSort.txt"); JavaPairRDD<SecondSortKey, String> pairSecondRDD = secondRDD.mapToPair(new PairFunction<String, SecondSortKey, String>(){
/** * */ private static final long serialVersionUID = 1L; @Override public Tuple2<SecondSortKey, String> call(String line) throws Exception { String[] splited = line.split(" "); int first = Integer.valueOf(splited[0]); int second = Integer.valueOf(splited[1]); SecondSortKey secondSortKey = new SecondSortKey(first,second); return new Tuple2<SecondSortKey, String>(secondSortKey,line); } }); pairSecondRDD.sortByKey(false).foreach(new VoidFunction<Tuple2<SecondSortKey,String>>() { /** * */ private static final long serialVersionUID = 1L; @Override public void call(Tuple2<SecondSortKey, String> tuple) throws Exception { System.out.println(tuple._2); } }); public class SecondSortKey implements Serializable,Comparable<SecondSortKey>{ /** * */ private static final long serialVersionUID = 1L; private int first; private int second; public int getFirst() { return first; } public void setFirst(int first) { this.first = first; } public int getSecond() { return second; } public void setSecond(int second) { this.second = second; } public SecondSortKey(int first, int second) { super(); this.first = first; this.second = second; } @Override public int compareTo(SecondSortKey o1) { if(getFirst() - o1.getFirst() ==0 ){ return getSecond() - o1.getSecond(); }else{ return getFirst() - o1.getFirst(); } } }
分组取topN和topN
SparkConf conf = new SparkConf() .setMaster("local") .setAppName("TopOps"); JavaSparkContext sc = new JavaSparkContext(conf); JavaRDD<String> linesRDD = sc.textFile("scores.txt"); JavaPairRDD<String, Integer> pairRDD = linesRDD.mapToPair(new PairFunction<String, String, Integer>() { /** * */ private static final long serialVersionUID = 1L; @Override public Tuple2<String, Integer> call(String str) throws Exception { String[] splited = str.split("t"); String clazzName = splited[0]; Integer score = Integer.valueOf(splited[1]); return new Tuple2<String, Integer> (clazzName,score); } }); pairRDD.groupByKey().foreach(new VoidFunction<Tuple2<String,Iterable<Integer>>>() { /** * */ private static final long serialVersionUID = 1L; @Override public void call(Tuple2<String, Iterable<Integer>> tuple) throws Exception { String clazzName = tuple._1; Iterator<Integer> iterator = tuple._2.iterator(); Integer[] top3 = new Integer[3]; while (iterator.hasNext()) { Integer score = iterator.next(); for (int i = 0; i < top3.length; i++) { if(top3[i] == null){ top3[i] = score; break; }else if(score > top3[i]){ for (int j = 2; j > i; j--) { top3[j] = top3[j-1]; } top3[i] = score; break; } } } System.out.println("class Name:"+clazzName); for(Integer sscore : top3){ System.out.println(sscore); } } });
SparkShell的使用
- 概念:
SparkShell是Spark自带的一个快速原型开发工具,也可以说是Spark的scala REPL(Read-Eval-Print-Loop),即交互式shell。支持使用scala语言来进行Spark的交互式编程。 - 使用:
启动Standalone集群
./start-all.sh
在客户端上启动spark-shell:
./spark-shell --master spark://node1:7077
启动hdfs,创建目录spark/test,上传文件wc.txt
启动hdfs集群:
start-all.sh
创建目录:
hdfs dfs -mkdir -p /spark/test
上传wc.txt
hdfs dfs -put /root/test/wc.txt /spark/test/
运行wordcount
sc.textFile(“hdfs://node1:9000/spark/test/wc.txt”)
.flatMap(.split(" ")).map((,1)).reduceByKey(+).foreach(println)
SparkUI
- SparkUI界面介绍
可以指定提交Application的名称
./spark-shell --master spark://node1:7077 --name myapp - 配置historyServer
- 临时配置,对本次提交的应用程序起作用
./spark-shell --master spark://node1:7077 --name myapp1 --conf spark.eventLog.enabled=true --conf spark.eventLog.dir=hdfs://node1:8020/spark/test
停止程序,在Web Ui中Completed Applications对应的ApplicationID中能查看history。
- spark-default.conf配置文件中配置HistoryServer,对所有提交的Application都起作用
在客户端节点,进入…/spark-2.2.1/conf/ spark-defaults.conf最后加入:
//开启记录事件日志的功能 spark.eventLog.enabled true //设置事件日志存储的目录 spark.eventLog.dir hdfs://node1:8020/spark/test //日志优化选项,压缩日志 spark.eventLog.compress true
启动HistoryServer:
./start-history-server.sh
访问HistoryServer:node4:18080,之后所有提交的应用程序运行状况都会被记录。
Master HA
Master的高可用原理
Standalone集群只有一个Master,如果Master挂了就无法提交应用程序,需要给Master进行高可用配置,Master的高可用可以使用fileSystem(文件系统)和zookeeper(分布式协调服务)。
fileSystem只有存储功能,可以存储Master的元数据信息,用fileSystem搭建的Master高可用,在Master失败时,需要我们手动启动另外的备用Master,这种方式不推荐使用。
zookeeper有选举和存储功能,可以存储Master的元素据信息,使用zookeeper搭建的Master高可用,当Master挂掉时,备用的Master会自动切换,推荐使用这种方式搭建Master的HA。
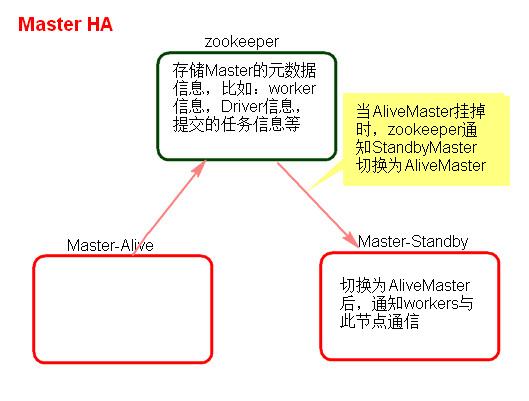
Master高可用搭建
- 在Spark Master节点上配置主Master,配置spark-env.sh
export SPARK_DAEMON_JAVA_OPTS=" -Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node3:2181,node4:2181,node5:2181 -Dspark.deploy.zookeeper.dir=/sparkmaster0821"
- 发送到其他worker节点上


- 找一台节点(非主Master节点),比如node2
配置备用 Master,修改spark-env.sh配置节点上的MasterIP, - 启动集群之前启动zookeeper集群:
…/zkServer.sh start - 在node1上启动spark Standalone集群 ./start-all.sh
在node2上启动备用Master ./ start-master.sh - 打开主Master和备用Master WebUI页面,观察状态。
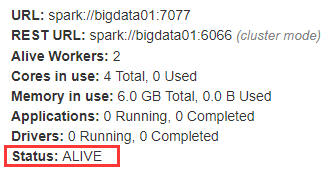
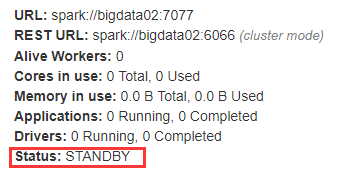
注意点
- 主备切换过程中不能提交Application。
- 主备切换过程中不影响已经在集群中运行的Application。因为Spark是粗粒度资源调度。
测试验证
提交SparkPi程序,kill主Master观察现象。
./spark-submit --master spark://node1:7077,node2:7077 --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.11-2.2.1.jar 10000
广播变量和累加器
广播变量
- 广播变量理解图
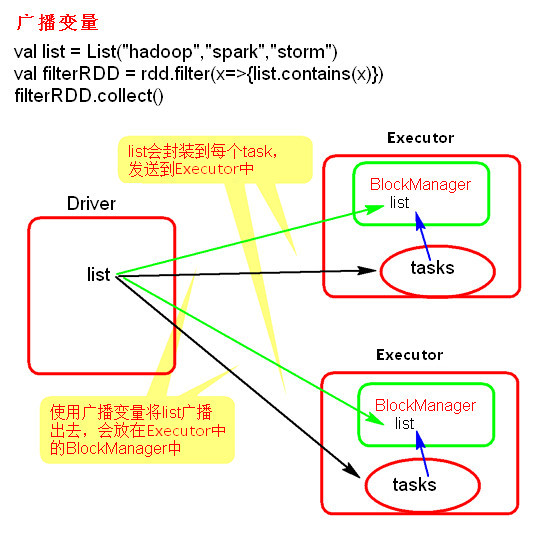
- 广播变量使用
val conf = new SparkConf() conf.setMaster("local").setAppName("brocast") val sc = new SparkContext(conf) val list = List("hello xasxt") val broadCast = sc.broadcast(list) val lineRDD = sc.textFile("./words.txt") lineRDD.filter { x => broadCast.value.contains(x) }.foreach { println} sc.stop()
- 注意事项
- 能不能将一个RDD使用广播变量广播出去?
不能,因为RDD是不存储数据的。可以将RDD的结果广播出去。 - 广播变量只能在Driver端定义,不能在Executor端定义。
- 在Driver端可以修改广播变量的值,在Executor端无法修改广播变量的值。
累加器
- 累加器理解图
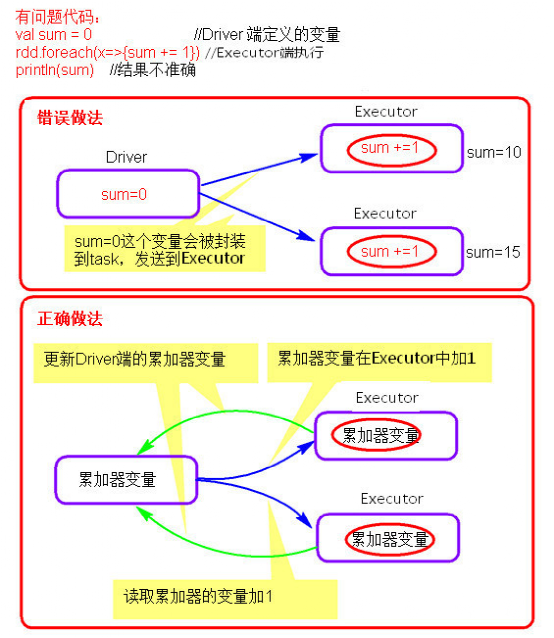
- 累加器的使用
val conf = new SparkConf() conf.setMaster("local").setAppName("accumulator") val sc = new SparkContext(conf) val accumulator = sc.longAccumulator sc.textFile("./words.txt").foreach { x =>{accumulator.add(1)}} println(accumulator.value) sc.stop()
- 注意事项
- 累加器在Driver端定义赋初始值,累加器只能在Driver端读取,在Excutor端更新。
资源调度源码分析
- 资源请求简单图
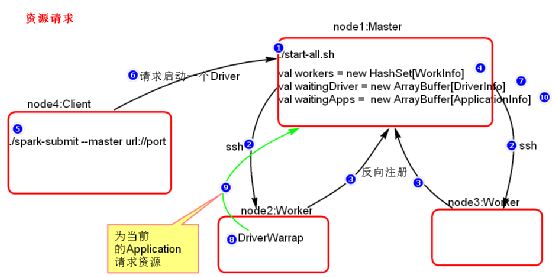
- 资源调度Master路径:

路径:spark-2.2.1/core/src/main/scala/org.apache.spark/deploy/master/Master.scala - 提交应用程序,submit的路径:

路径:spark-2.2.1/core/src/main/scala/org.apache.spark/deploy/SparkSubmit.scala - 总结:
a. Executor在集群中分散启动,有利于task计算的数据本地化。
b. 默认情况下(提交任务的时候没有设置–executor-cores选项),每一个Worker为当前的Application启动一个Executor,这个Executor会使用这个Worker的所有的cores和1G内存。
c. 如果想在Worker上启动多个Executor,提交Application的时候要加–executor-cores这个选项。
d. 默认情况下没有设置–total-executor-cores,一个Application会使用Spark集群中所有的cores。 - 结论演示
使用Spark-submit提交任务演示。也可以使用spark-shell
a. 默认情况每个worker为当前的Application启动一个Executor,这个Executor使用集群中所有的cores和1G内存。
./spark-submit --master spark://node1:7077 --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.11-2.2.1.jar 10000
b. 在workr上启动多个Executor,设置–executor-cores参数指定每个executor使用的core数量。
./spark-submit --master spark://node1:7077 --executor-cores 1 --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.11-2.2.1.jar 10000
c. 内存不足的情况下启动core的情况。Spark启动是不仅看core配置参数,也要看配置的core的内存是否够用。
./spark-submit --master spark://node1:7077 --executor-cores 1 --executor-memory 3g --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.11-2.2.1.jar 10000
d. --total-executor-cores集群中共使用多少cores
注意:一个进程不能让集群多个节点共同启动。
./spark-submit --master spark://node1:7077 --executor-cores 1 --executor-memory 2g --total-executor-cores 3 --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.11-2.2.1.jar 10000
任务调度源码分析
- Action算子开始分析
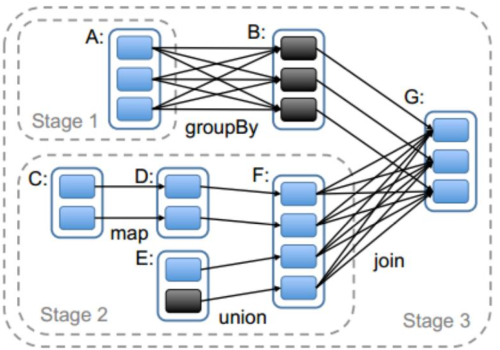
任务调度可以从一个Action类算子开始。因为Action类算子会触发一个job的执行。 - 划分stage,以taskSet形式提交任务
DAGScheduler 类中getMessingParentStages()方法是切割job划分stage。可以结合以下这张图来分析:
SparkShuffle
SparkShuffle概念
reduceByKey会将上一个RDD中的每一个key对应的所有value聚合成一个value,然后生成一个新的RDD,元素类型是<key,value>对的形式,这样每一个key对应一个聚合起来的value。
问题:聚合之前,每一个key对应的value不一定都是在一个partition中,也不太可能在同一个节点上,因为RDD是分布式的弹性的数据集,RDD的partition极有可能分布在各个节点上。
如何聚合?
- Shuffle Write:上一个stage的每个map task就必须保证将自己处理的当前分区的数据相同的key写入一个分区文件中,可能会写入多个不同的分区文件中。
- Shuffle Read:reduce task就会从上一个stage的所有task所在的机器上寻找属于己的那些分区文件,这样就可以保证每一个key所对应的value都会汇聚到同一个节点上去处理和聚合。
Spark中有两种Shuffle类型,HashShuffle和SortShuffle,Spark1.2之前是HashShuffle,Spark1.2引入SortShuffle 。
HashShuffle
- 普通机制
- 普通机制示意图
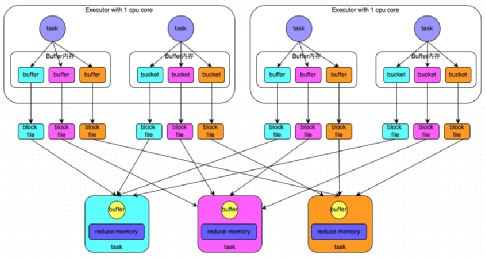
- 执行流程
a. 每一个map task将不同结果写到不同的buffer中,每个buffer的大小为32K。buffer起到数据缓存的作用。
b. 每个buffer文件最后对应一个磁盘小文件。
c. reduce task来拉取对应的磁盘小文件。 - 总结
a. .map task的计算结果会根据分区器(默认是hashPartitioner)来决定写入到哪一个磁盘小文件中去。ReduceTask会去Map端拉取相应的磁盘小文件。
b. .产生的磁盘小文件的个数:
M(map task的个数)*R(reduce task的个数) - 存在的问题
产生的磁盘小文件过多,会导致以下问题:
a. 在Shuffle Write过程中会产生很多写磁盘小文件的对象。
b. 在Shuffle Read过程中会产生很多读取磁盘小文件的对象。
c. 在JVM堆内存中对象过多会造成频繁的gc,gc还无法解决运行所需要的内存 的话,就会OOM。
d. 在数据传输过程中会有频繁的网络通信,频繁的网络通信出现通信故障的可能性大大增加,一旦网络通信出现了故障会导致shuffle file cannot find 由于这个错误导致的task失败,TaskScheduler不负责重试,由DAGScheduler负责重试Stage。
- 合并机制
- 合并机制示意图
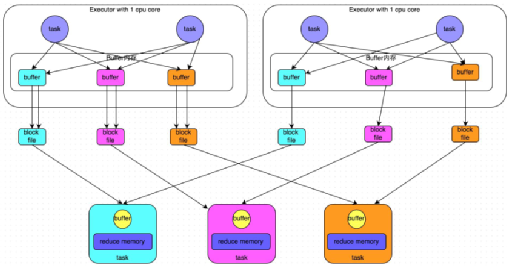
- 总结
产生磁盘小文件的个数:C(core的个数)*R(reduce的个数)
SortShuffle
- 普通机制
- 普通机制示意图
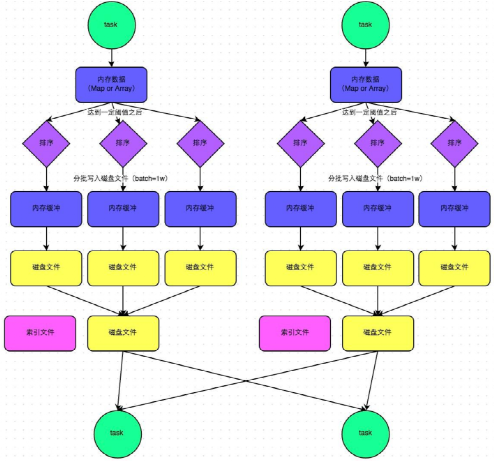
- 执行流程
a. map task 的计算结果会写入到一个内存数据结构里面,内存数据结构默认是5M
b. 在shuffle的时候会有一个定时器,不定期的去估算这个内存结构的大小,当内存结构中的数据超过5M时,比如现在内存结构中的数据为5.01M,那么他会申请5.01*2-5=5.02M内存给内存数据结构。
c. 如果申请成功不会进行溢写,如果申请不成功,这时候会发生溢写磁盘。
d. 在溢写之前内存结构中的数据会进行排序分区
e. 然后开始溢写磁盘,写磁盘是以batch的形式去写,一个batch是1万条数据,
f. map task执行完成后,会将这些磁盘小文件合并成一个大的磁盘文件,同时生成一个索引文件。
g. reduce task去map端拉取数据的时候,首先解析索引文件,根据索引文件再去拉取对应的数据。 - 总结
产生磁盘小文件的个数: 2*M(map task的个数)
- bypass机制
- bypass机制示意图
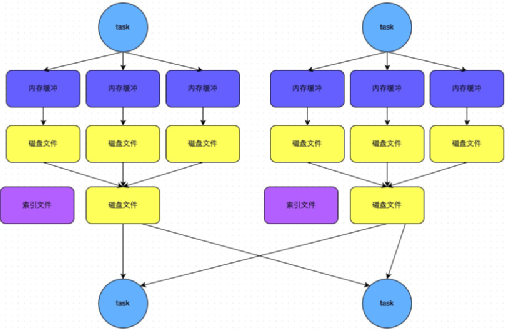
- 总结
a. .bypass运行机制的触发条件如下:
shuffle reduce task的数量小于spark.shuffle.sort.bypassMergeThreshold的参数值。这个值默认是200。
不需要进行map端的预聚合,比如groupBykey,join.
b. .产生的磁盘小文件为:2*M(map task的个数)
Shuffle文件寻址
- MapOutputTracker
MapOutputTracker是Spark架构中的一个模块,是一个主从架构。管理磁盘小文件的地址。
- MapOutputTrackerMaster是主对象,存在于Driver中。
- MapOutputTrackerWorker是从对象,存在于Excutor中。
- BlockManager
BlockManager块管理者,是Spark架构中的一个模块,也是一个主从架构。
- BlockManagerMaster,主对象,存在于Driver中。
BlockManagerMaster会在集群中有用到广播变量和缓存数据或者删除缓存数据的时候,通知BlockManagerSlave传输或者删除数据。 - BlockManagerWorker,从对象,存在于Excutor中。
BlockManagerWorker会与BlockManagerWorker之间通信。 - 无论在Driver端的BlockManager还是在Excutor端的BlockManager都含有四个对象:
a. DiskStore:负责磁盘的管理。
b. MemoryStore:负责内存的管理。
c. ConnectionManager:负责连接其他的BlockManagerWorker。
d. BlockTransferService:负责数据的传输。
- Shuffle文件寻址图
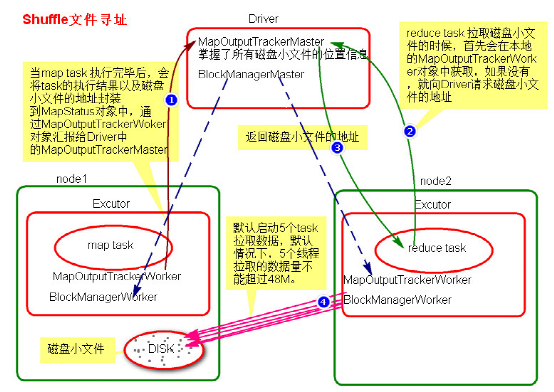
- Shuffle文件寻址流程
a. 当map task执行完成后,会将task的执行情况和磁盘小文件的地址封装到MpStatus对象中,通过MapOutputTrackerWorker对象向Driver中的MapOutputTrackerMaster汇报。
b. 在所有的map task执行完毕后,Driver中就掌握了所有的磁盘小文件的地址。
c. 在reduce task执行之前,会通过Excutor中MapOutPutTrackerWorker向Driver端的MapOutputTrackerMaster获取磁盘小文件的地址。
d. 获取到磁盘小文件的地址后,会通过BlockManager中的ConnectionManager连接数据所在节点上的ConnectionManager,然后通过BlockTransferService进行数据的传输。
e. BlockTransferService默认启动5个task去节点拉取数据。默认情况下,5个task拉取数据量不能超过48M。
注意:spark1.2之前没有SortShuffle
spark1.2-spark1.6之间是有HashShuffle和SortShuffle的
spark2.0之后就只有SortShuffle了,HashShuffle被移除了
Spark内存管理
Spark执行应用程序时,Spark集群会启动Driver和Executor两种JVM进程,Driver负责创建SparkContext上下文,提交任务,task的分发等。Executor负责task的计算任务,并将结果返回给Driver。同时需要为需要持久化的RDD提供储存。Driver端的内存管理比较简单,这里所说的Spark内存管理针对Executor端的内存管理。
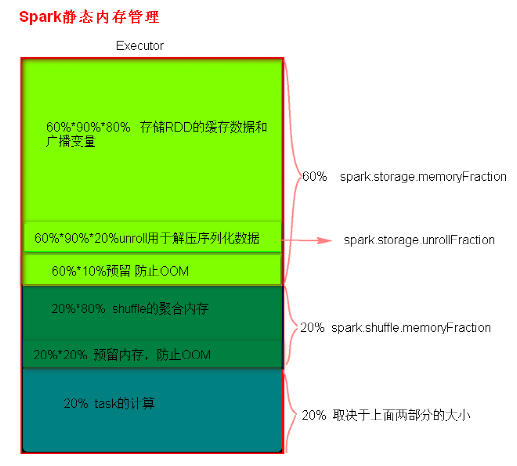
Spark内存管理分为静态内存管理和统一内存管理,Spark1.6之前使用的是静态内存管理,Spark1.6之后引入了统一内存管理。
静态内存管理中存储内存、执行内存和其他内存的大小在 Spark 应用程序运行期间均为固定的,但用户可以应用程序启动前进行配置。
统一内存管理与静态内存管理的区别在于储存内存和执行内存共享同一块空间,可以互相借用对方的空间。
Spar1.6及1.6版本之后的版本默认使用的是统一内存管理
要想使用静态内存可以通过参数spark.memory.useLegacyMode
设置为true(默认为false)使用静态内存管理。
- 静态内存管理分布图
- 统一内存管理分布图
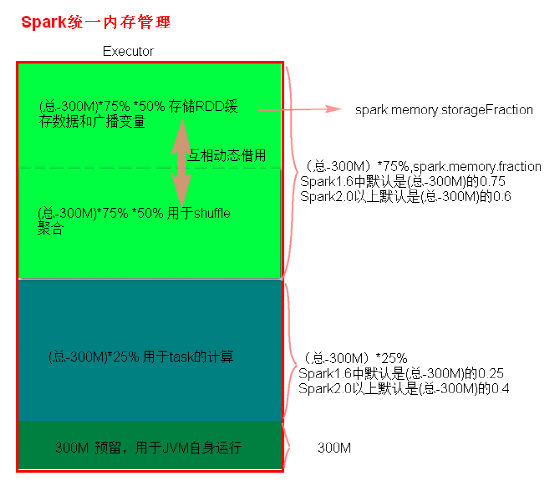
- reduce 中OOM如何处理?
- 减少每次拉取的数据量
- 提高shuffle聚合的内存比例
- 提高Excutor的总内存
Shuffle调优
- SparkShuffle调优配置项如何使用?
- 在代码中,不推荐使用,硬编码。
new SparkConf().set(“spark.shuffle.file.buffer”,”64”) - 在提交spark任务的时候,推荐使用。
spark-submit --conf spark.shuffle.file.buffer=64 –conf …. - 在conf下的spark-default.conf配置文件中,不推荐,因为是写死后所有应用程序都要用。
SparkSql
Shark
Shark是基于Spark计算框架之上且兼容Hive语法的SQL执行引擎,由于底层的计算采用了Spark,性能比MapReduce的Hive普遍快2倍以上,当数据全部load在内存的话,将快10倍以上,因此Shark可以作为交互式查询应用服务来使用。除了基于Spark的特性外,Shark是完全兼容Hive的语法,表结构以及UDF函数等,已有的HiveSql可以直接进行迁移至Shark上Shark底层依赖于Hive的解析器,查询优化器,但正是由于SHark的整体设计架构对Hive的依赖性太强,难以支持其长远发展,比如不能和Spark的其他组件进行很好的集成,无法满足Spark的一栈式解决大数据处理的需求。
SparkSQL
- SparkSQL介绍
Hive是Shark的前身,Shark是SparkSQL的前身,SparkSQL产生的根本原因是其完全脱离了Hive的限制。
- SparkSQL支持查询原生的RDD。 RDD是Spark平台的核心概念,是Spark能够高效的处理大数据的各种场景的基础。
- 能够在scala中写SQL语句。支持简单的SQL语法检查,能够在Scala中写Hive语句访问Hive数据,并将结果取回作为RDD使用。
- Spark on Hive和Hive on Spark
- Spark on Hive: Hive只作为储存角色,Spark负责sql解析优化,执行。
- Hive on Spark:Hive即作为存储又负责sql的解析优化,Spark负责执行。
-
Dataset与DataFrame
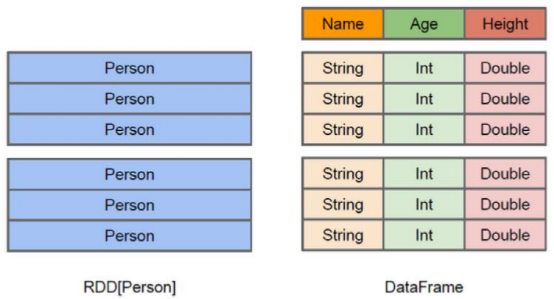
Dataset也是一个分布式数据容器。与RDD类似,然而Dataset更像传统数据库的二维表格,除了数据以外,还掌握数据的结构信息,即schema。同时,与Hive类似,Dataset也支持嵌套数据类型(struct、array和map)。从API易用性的角度上 看, Dataset API提供的是一套高层的关系操作,比函数式的RDD API要更加友好,门槛更低。
Dataset的底层封装的是RDD,当RDD的泛型是Row类型的时候,我们也可以称它为DataFrame。即Dataset = DataFrame -
SparkSQL的数据源
SparkSQL的数据源可以是JSON类型的字符串,JDBC,Parquent,Hive,HDFS等。 -
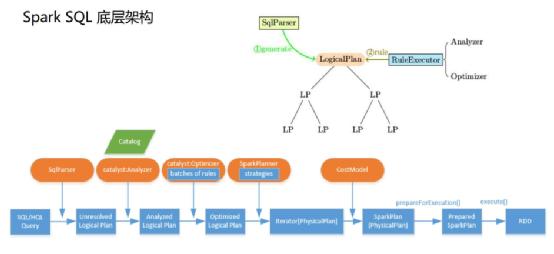
SparkSQL底层架构
首先拿到sql后解析一批未被解决的逻辑计划,再经过分析得到分析后的逻辑计划,再经过一批优化规则转换成一批最佳优化的逻辑计划,再经过SparkPlanner的策略转化成一批物理计划,随后经过消费模型转换成一个个的Spark任务执行。
-
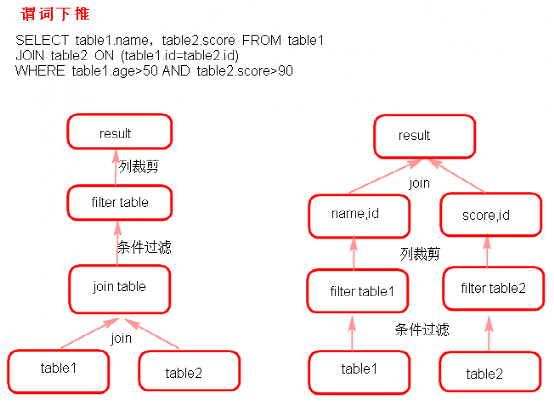
谓词下推(predicate Pushdown)
创建Dataset的几种方式
读取json格式的文件创建Dataset
注意:
- json文件中的json数据不能嵌套json格式数据。
- Dataset是一个一个Row类型的RDD,ds.rdd()/ds.javaRdd()。
- 可以两种方式读取json格式的文件。
- df.show()默认显示前20行数据。
- Dataset原生API可以操作Dataset(不方便)。
- 注册成临时表时,表中的列默认按ascii顺序显示列。
java:
SparkSession sparkSession = SparkSession .builder() .appName("jsonfile") .master("local") .getOrCreate(); /** * Dataset的底层是一个一个的RDD RDD的泛型是Row类型。 * 以下两种方式都可以读取json格式的文件 */ Dataset<Row> ds = sparkSession.read().format("json").load("data/json"); // Dataset<Row> ds = sparkSession.read().json("data/json"); // ds.show(); /** * Dataset转换成RDD */ JavaRDD<Row> javaRDD = ds.javaRDD(); /** * 显示 Dataset中的内容,默认显示前20行。如果现实多行要指定多少行show(行数) * 注意:当有多个列时,显示的列先后顺序是按列的ascii码先后显示。 */ // ds.show(); /** * 树形的形式显示schema信息 */ ds.printSchema(); /** * Dataset自带的API 操作Dataset */ //select name from table // ds.select("name").show(); //select name age+10 as addage from table ds.select(ds.col("name"),ds.col("age").plus(10).alias("addage")).show(); //select name ,age from table where age>19 ds.select(ds.col("name"),ds.col("age")).where(ds.col("age").gt(19)).show(); //select count(*) from table group by age ds.groupBy(ds.col("age")).count().show(); /** * 将Dataset注册成临时的一张表,这张表临时注册到内存中,是逻辑上的表,不会雾化到磁盘 */ ds.createOrReplaceTempView("jtable"); Dataset<Row> result= sparkSession.sql("select age,count(*) as gg from jtable group by age"); result.show(); sparkSession.stop();
通过json格式的RDD创建Dataset
java:
SparkSession sparkSession = SparkSession .builder() .appName("jsonrdd") .master("local") .getOrCreate(); SparkContext sc = sparkSession.sparkContext(); JavaSparkContext jsc = new JavaSparkContext(sc); JavaRDD<String> nameRDD = sc.parallelize(Arrays.asList( "{"name":"zhangsan","age":"18"}", "{"name":"lisi","age":"19"}", "{"name":"wangwu","age":"20"}" )); JavaRDD<String> scoreRDD = sc.parallelize(Arrays.asList( "{"name":"zhangsan","score":"100"}", "{"name":"lisi","score":"200"}", "{"name":"wangwu","score":"300"}" )); Dataset<Row> nameds = sparkSession.read().json(nameRDD); Dataset<Row> scoreds = sparkSession.read().json(scoreRDD); nameds.createOrReplaceTempView("nameTable"); scoreds.createOrReplaceTempView("scoreTable"); Dataset<Row> result = sparkSession.sql("select nameTable.name,nameTable.age,scoreTable.score " + "from nameTable join scoreTable " + "on nameTable.name = scoreTable.name"); result.show(); sparkSession.stop();
非json格式的RDD创建Dataset
a. 通过反射的方式将非json格式的RDD转换成Dataset
- 自定义类要可序列化
- 自定义类的访问级别是Public
- RDD转成Dataset后会根据映射将字段按Assci码排序
- 将Dataset转换成RDD时获取字段两种方式,一种是ds.getInt(0)下标获取(不推荐使用),另一种是ds.getAs(“列名”)获取(推荐使用)
/** * 注意: * 1.自定义类必须是可序列化的 * 2.自定义类访问级别必须是Public * 3.RDD转成Dataset会把自定义类中字段的名称按assci码排序 */ SparkSession sparkSession = SparkSession .builder() .appName("reflect") .master("local") .getOrCreate(); SparkContext sc = sparkSession.sparkContext(); JavaSparkContext jsc = new JavaSparkContext(sc); JavaRDD<String> lineRDD = jsc.textFile("data/person.txt"); JavaRDD<Person> personRDD = lineRDD.map( new Function<String, Person>() { private static final long serialVersionUID = 1L; @Override public Person call(String line) throws Exception { Person p = new Person(); p.setId(line.split(",")[0]); p.setName(line.split(",")[1]); p.setAge(Integer.valueOf(line.split(",")[2])); return p; } }); /** * 传入进去Person.class的时候,sqlContext是通过反射的方式创建DataFrame * 在底层通过反射的方式获得Person的所有field,结合RDD本身,就生成了DataFrame */ Dataset<Row> dataFrame = sparkSession.createDataFrame(personRDD, Person.class); dataFrame.show(); dataFrame.printSchema(); dataFrame.registerTempTable("person"); Dataset sql = sparkSession.sql("select name,id,age from person where id = 2"); sql.show(); /** * 将Dataset转成JavaRDD * 注意: * 1.可以使用row.getInt(0),row.getString(1)...通过下标获取返回Row类型的数据,但是要注意列顺序问题---不常用 * 2.可以使用row.getAs("列名")来获取对应的列值。 * */ JavaRDD<Row> javaRDD = df.javaRDD(); JavaRDD<Person> map = javaRDD.map(new Function<Row, Person>() { /** * */ private static final long serialVersionUID = 1L; @Override public Person call(Row row) throws Exception { Person p = new Person(); //p.setId(row.getString(1)); //p.setName(row.getString(2)); //p.setAge(row.getInt(0)); p.setId((String)row.getAs("id")); p.setName((String)row.getAs("name")); p.setAge((Integer)row.getAs("age")); return p; } }); map.foreach(x-> System.out.println(x)); sc.stop();
b. 动态创建Schema将非json格式的RDD转换成Dataset
java:
SparkSession sparkSession = SparkSession .builder() .appName("schema") .master("local") .getOrCreate(); SparkContext sc = sparkSession.sparkContext(); JavaSparkContext jsc = new JavaSparkContext(sc); JavaRDD<String> lineRDD = jsc.textFile("data/person.txt"); JavaRDD<String> lineRDD = sc.textFile("./sparksql/person.txt"); /** * 转换成Row类型的RDD */ JavaRDD<Row> rowRDD = lineRDD.map(new Function<String, Row>() { /** * */ private static final long serialVersionUID = 1L; @Override public Row call(String s) throws Exception { return RowFactory.create( String.valueOf(s.split(",")[0]), String.valueOf(s.split(",")[1]), Integer.valueOf(s.split(",")[2]) ); } }); /** * 动态构建DataFrame中的元数据,一般来说这里的字段可以来源自字符串,也可以来源于外部数据库 */ List<StructField> asList =Arrays.asList( DataTypes.createStructField("id", DataTypes.StringType, true), DataTypes.createStructField("name", DataTypes.StringType, true), DataTypes.createStructField("age", DataTypes.IntegerType, true) ); StructType schema = DataTypes.createStructType(asList); Dataset<Row> df = sparkSession.createDataFrame(rowRDD, schema); df.show(); sc.stop();
读取parquet文件创建Dataset
注意:
- 可以将Dataset存储成parquet文件。保存成parquet文件的方式有两种
df.write().mode(SaveMode.Overwrite)format(“parquet”).save("./sparksql/parquet");
df.write().mode(SaveMode.Overwrite).parquet("./sparksql/parquet"); - SaveMode指定文件保存时的模式。
Overwrite:覆盖
Append:追加
ErrorIfExists:如果存在就报错
Ignore:如果存在就忽略
java:
SparkSession sparkSession = SparkSession .builder() .appName("parquet") .master("local") .getOrCreate(); Dataset<Row> df = sparkSession.read().json("data/json"); /** * 将Dataset保存成parquet文件,SaveMode指定存储文件时的保存模式 * 保存成parquet文件有以下两种方式: */ df.write().mode(SaveMode.Overwrite).format("parquet").save("./data/parquet"); df.write().mode(SaveMode.Overwrite).parquet("./data/parquet"); df.show(); /** * 加载parquet文件成DataFrame * 加载parquet文件有以下两种方式: */ Dataset load = sparksession.read().format("parquet").load("./data /parquet"); load = sparksession.read().parquet("./data /parquet"); load.show(); sc.stop();
读取JDBC中的数据创建Dataset(MySql为例)
两种方式创建Dataset
java:
SparkSession sparkSession = SparkSession .builder() .appName("mysql") .master("local") .getOrCreate();/** * 第一种方式读取MySql数据库表,加载为DataFrame */ Map<String, String> options = new HashMap<String,String>(); options.put("url", "jdbc:mysql://192.168.179.4:3306/spark"); options.put("driver", "com.mysql.jdbc.Driver"); options.put("user", "root"); options.put("password", "123456"); options.put("dbtable", "person"); Dataset<Row> person = sparkSession.read().format("jdbc").options(options).load(); person.show(); person.createOrReplaceTempView("person"); /** * 第二种方式读取MySql数据表加载为Dataset */ DataFrameReader reader = sparkSession.read().format("jdbc"); reader.option("url", "jdbc:mysql://192.168.179.4:3306/spark"); reader.option("driver", "com.mysql.jdbc.Driver"); reader.option("user", "root"); reader.option("password", "123456"); reader.option("dbtable", "score"); Dataset<Row> score = reader.load(); score.show(); score.createOrReplaceTempView("score"); Dataset result = sparksession.sql("select person.id,person.name,score.score from person,score where person.name = score.name"); result.show(); /** * 将Dataset结果保存到Mysql中 */ Properties properties = new Properties(); properties.setProperty("user", "root"); properties.setProperty("password", "root"); result.write().mode(SaveMode.Overwrite).jdbc("jdbc:mysql://192.168.179.4:3306/spark","result",properties); sc.stop();
读取Hive中的数据加载成Dataset
java:
SparkSession sparkSession = SparkSession .builder() .master("local") .appName("hvie") //开启hive的支持,接下来就可以操作hive表了 // 前提需要是需要开启hive metastore 服务 .enableHiveSupport() .getOrCreate(); sparkSession.sql("USE spark"); sparkSession.sql("DROP TABLE IF EXISTS student_infos"); //在hive中创建student_infos表 sparkSession.sql("CREATE TABLE IF NOT EXISTS student_infos (name STRING,age INT) row format delimited fields terminated by't'"); sparkSession.sql("load data local inpath '/root/student_infos' into table student_infos"); //注意:此种方式,程序需要能读取到数据(如/root/student_infos),同时也要能读取到 metastore服务的配置信息。 sparkSession.sql("DROP TABLE IF EXISTS student_scores"); sparkSession.sql("CREATE TABLE IF NOT EXISTS student_scores (name STRING, score INT) row format delimited fields terminated by 't'"); sparkSession.sql("LOAD DATA " + "LOCAL INPATH '/root/student_scores'" + "INTO TABLE student_scores"); // Dataset<Row> df = hiveContext.table("student_infos");//读取Hive表加载Dataset方式 /** * 查询表生成Dataset */ Dataset<Row> goodStudentsDF = sparkSession.sql("SELECT si.name, si.age, ss.score " + "FROM student_infos si " + "JOIN student_scores ss " + "ON si.name=ss.name " + "WHERE ss.score>=80"); goodStudentsDF.registerTempTable("goodstudent"); Dataset<Row> result = sparkSession.sql("select * from goodstudent"); result.show(); /** * 将结果保存到hive表 good_student_infos */ sparkSession.sql("DROP TABLE IF EXISTS good_student_infos"); goodStudentsDF.write().mode(SaveMode.Overwrite).saveAsTable("good_student_infos"); sparkSession.stop();
Spark On Hive的配置
- 在Spark客户端配置spark On hive
在Spark客户端安装包下spark-2.2.1/conf中创建文件hive-site.xml:
配置hive的metastore路径
<configuration> <property> <name>hive.metastore.uris</name> <value>thrift://node1:9083</value> </property> </configuration>
- 启动Hive的metastore服务
hive --service metastore &
- 启动zookeeper集群,启动HDFS集群。
- 启动SparkShell 读取Hive中的表总数,对比hive中查询同一表查询总数测试时间。
./spark-shell --master spark://node1:7077 spark.sql("select * from day_table").show;
注意:
如果使用Spark on Hive 查询数据时,出现错误:

找不到HDFS集群路径,要在客户端机器conf/spark-env.sh中设置HDFS的路径:
序列化问题。
储存DataSet
- 将DataSet存储为parquet文件。
- 将DataSet存储到JDBC数据库。
- 将DataSet存储到Hive表。
自定义函数UDF和UDAF
- UDF:用户自定义函数。
java:
SparkSession sparkSession = SparkSession .builder() .appName("udf") .master("local") .getOrCreate(); JavaSparkContext sc = new JavaSparkContext(sparkSession.sparkContext()); JavaRDD<String> parallelize = sc.parallelize(Arrays.asList("zhangsan","lisi","wangwu")); JavaRDD<Row> rowRDD = parallelize.map(new Function<String, Row>() { /** * */ private static final long serialVersionUID = 1L; @Override public Row call(String s) throws Exception { return RowFactory.create(s); } }); /** * 动态创建Schema方式加载DF */ List<StructField> fields = new ArrayList<StructField>(); fields.add(DataTypes.createStructField("name", DataTypes.StringType,true)); StructType schema = DataTypes.createStructType(fields); Dataset<Row> df = sparkSession.createDataFrame(rowRDD,schema); df.registerTempTable("user"); /** * 根据UDF函数参数的个数来决定是实现哪一个UDF UDF1,UDF2。。。。UDF1xxx */ sparkSession.udf().register("StrLen",new UDF2<String, Integer, Integer>() { /** * */ private static final long serialVersionUID = 1L; @Override public Integer call(String t1, Integer t2) throws Exception { return t1.length() + t2; } } ,DataTypes.IntegerType ); sparkSession.sql("select name ,StrLen(name,100) as length from user").show(); // sparkSession.stop();
- UDAF:用户自定义聚合函数。
实现UDAF函数如果要自定义类要实现UserDefinedAggregateFunction类
java:
SparkSession sparkSession = SparkSession .builder() .appName("udaf") .master("local") .getOrCreate(); JavaSparkContext sc = new JavaSparkContext(sparkSession.sparkContext()); JavaRDD<String> parallelize = sc.parallelize(Arrays.asList("zhansan","lisi","wangwu","zhangsan","zhangsan","lisi")); JavaRDD<Row> rowRDD = parallelize.map(new Function<String, Row>() { /** * */ private static final long serialVersionUID = 1L; @Override public Row call(String s) throws Exception { return RowFactory.create(s); } }); List<StructField> fields = new ArrayList<StructField>(); fields.add(DataTypes.createStructField("name", DataTypes.StringType, true)); StructType schema = DataTypes.createStructType(fields); Dataset df = sparkSession.createDataFrame(rowRDD, schema); df.registerTempTable("user"); /** * 注册一个UDAF函数,实现统计相同值得个数 * 注意:这里可以自定义一个类继承UserDefinedAggregateFunction类也是可以的 */ sparkSession.udf().register("StringCount", new UserDefinedAggregateFunction() { /** * */ private static final long serialVersionUID = 1L; /** * 更新 可以认为一个一个地将组内的字段值传递进来 实现拼接的逻辑 * buffer.getInt(0)获取的是上一次聚合后的值 * 相当于map端的combiner,combiner就是对每一个map task的处理结果进行一次小聚合 * 大聚和发生在reduce端. * 这里即是:在进行聚合的时候,每当有新的值进来,对分组后的聚合如何进行计算 */ @Override public void update(MutableAggregationBuffer buffer, Row arg1) { buffer.update(0, buffer.getInt(0)+1); } /** * 合并 update操作,可能是针对一个分组内的部分数据,在某个节点上发生的 但是可能一个分组内的数据,会分布在多个节点上处理 * 此时就要用merge操作,将各个节点上分布式拼接好的串,合并起来 * buffer1.getInt(0) : 大聚和的时候 上一次聚合后的值 * buffer2.getInt(0) : 这次计算传入进来的update的结果 * 这里即是:最后在分布式节点完成后需要进行全局级别的Merge操作 */ @Override public void merge(MutableAggregationBuffer buffer1, Row buffer2) { buffer1.update(0, buffer1.getInt(0) + buffer2.getInt(0)); } /** * 指定输入字段的字段及类型 */ @Override public StructType inputSchema() { return DataTypes.createStructType( Arrays.asList(DataTypes.createStructField("name", DataTypes.StringType, true))); } /** * 初始化一个内部的自己定义的值,在Aggregate之前每组数据的初始化结果 */ @Override public void initialize(MutableAggregationBuffer buffer) { buffer.update(0, 0); } /** * 最后返回一个和DataType的类型要一致的类型,返回UDAF最后的计算结果 */ @Override public Object evaluate(Row row) { return row.getInt(0); } @Override public boolean deterministic() { //设置为true return true; } /** * 指定UDAF函数计算后返回的结果类型 */ @Override public DataType dataType() { return DataTypes.IntegerType; } /** * 在进行聚合操作的时候所要处理的数据的结果的类型 */ @Override public StructType bufferSchema() { return DataTypes.createStructType( Arrays.asList(DataTypes.createStructField("bf", DataTypes.IntegerType, true))); } }); sparkSession.sql("select name ,StringCount(name) from user group by name").show(); sparkSession.stop();
开窗函数
注意:
row_number() 开窗函数是按照某个字段分组,然后取另一字段的前几个的值,相当于 分组取topN
开窗函数格式:
row_number() over (partitin by XXX order by XXX)
java:
SparkSession sparkSession = SparkSession .builder() .appName("window") .master("local") //开启hive的支持,接下来就可以操作hive表了 // 前提需要是需要开启hive metastore 服务 .enableHiveSupport() .getOrCreate(); sparkSession.sql("use spark"); sparkSession.sql("drop table if exists sales"); sparkSession.sql("create table if not exists sales (riqi string,leibie string,jine Int) " + "row format delimited fields terminated by 't'"); sparkSession.sql("load data local inpath '/root/test/sales' into table sales"); /** * 开窗函数格式: * 【 rou_number() over (partitin by XXX order by XXX) 】 */ Dataset<Row> result = sparkSession.sql("select riqi,leibie,jine " + "from (" + "select riqi,leibie,jine," + "row_number() over (partition by leibie order by jine desc) rank " + "from sales) t " + "where t.rank<=3"); result.show(); sparkSession.stop();
Spark Streaming
SparkStreaming简介
SparkStreaming是流式处理框架,是Spark API的扩展,支持可扩展、高吞吐量、容错的准实时数据流处理,实时数据的来源可以是:Kafka, Flume, Twitter, ZeroMQ或者TCP sockets,并且可以使用高级功能的复杂算子来处理流数据。例如:map,reduce,join,window 。最终,处理后的数据可以存放在文件系统,数据库等,方便实时展现。
SparkStreaming与Storm的区别
- Storm是纯实时的流式处理框架,SparkStreaming是准实时的处理框架(微批处理)。因为微批处理,SparkStreaming的吞吐量比Storm要高。
- Storm 的事务机制要比SparkStreaming的要完善。
- Storm支持动态资源调度。(spark1.2开始和之后也支持)
- SparkStreaming擅长复杂的业务处理,Storm不擅长复杂的业务处理,擅长简单的汇总型计算。
SparkStreaming初始
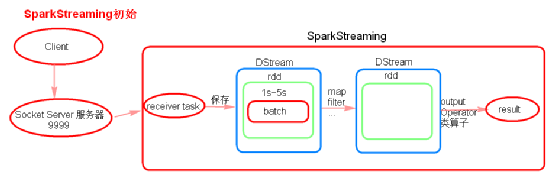
- SparkStreaming初始理解
注意:
- receiver task是7*24小时一直在执行,一直接受数据,将一段时间内接收来的数据保存到batch中。假设batchInterval为5s,那么会将接收来的数据每隔5秒封装到一个batch中,batch没有分布式计算特性,这一个batch的数据又被封装到一个RDD中最终封装到一个DStream中。
例如:假设batchInterval为5秒,每隔5秒通过SparkStreamin将得到一个DStream,在第6秒的时候计算这5秒的数据,假设执行任务的时间是3秒,那么第6----9秒一边在接收数据,一边在计算任务,9----10秒只是在接收数据。然后在第11秒的时候重复上面的操作。 - 如果job执行的时间大于batchInterval会有什么样的问题?
如果接受过来的数据设置的级别是仅内存,接收来的数据会越堆积越多,最后可能会导致OOM(如果设置StorageLevel包含disk, 则内存存放不下的数据会溢写至disk, 加大延迟 )。
- SparkStreaming代码
代码注意事项:
- 启动socket server 服务器:nc –lk 9999
- receiver模式下接受数据,local的模拟线程必须大于等于2,一个线程用来receiver用来接受数据,另一个线程用来执行job。
- Durations时间设置就是我们能接收的延迟度。这个需要根据集群的资源情况以及任务的执行情况来调节。
- 创建JavaStreamingContext有两种方式(SparkConf,SparkContext)
- 所有的代码逻辑完成后要有一个output operation类算子。
- JavaStreamingContext.start() Streaming框架启动后不能再次添加业务逻辑。
- JavaStreamingContext.stop() 无参的stop方法将SparkContext一同关闭,stop(false),不会关闭SparkContext。
- JavaStreamingContext.stop()停止之后不能再调用start。
SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("WordCountOnline"); /** * 在创建streaminContext的时候 设置batch Interval */ JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(5)); JavaReceiverInputDStream<String> lines = jsc.socketTextStream("node5", 9999); JavaDStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() { /** * */ private static final long serialVersionUID = 1L; @Override public Iterable<String> call(String s) { return Arrays.asList(s.split(" ")); } }); JavaPairDStream<String, Integer> ones = words.mapToPair(new PairFunction<String, String, Integer>() { /** * */ private static final long serialVersionUID = 1L; @Override public Tuple2<String, Integer> call(String s) { return new Tuple2<String, Integer>(s, 1); } }); JavaPairDStream<String, Integer> counts = ones.reduceByKey(new Function2<Integer, Integer, Integer>() { /** * */ private static final long serialVersionUID = 1L; @Override public Integer call(Integer i1, Integer i2) { return i1 + i2; } }); //outputoperator类的算子 counts.print(); jsc.start(); //等待spark程序被终止 jsc.awaitTermination(); jsc.stop(false);
SparkStreaming算子操作
- foreachRDD
- output operation算子,必须对抽取出来的RDD执行action类算子,代码才能执行。
- transform
- transformation类算子
- 可以通过transform算子,对Dstream做RDD到RDD的任意操作。
- updateStateByKey
- transformation算子
- updateStateByKey作用:
a. 为SparkStreaming中每一个Key维护一份state状态,state类型可以是任意类型的,可以是一个自定义的对象,更新函数也可以是自定义的。
b. 通过更新函数对该key的状态不断更新,对于每个新的batch而言,SparkStreaming会在使用updateStateByKey的时候为已经存在的key进行state的状态更新。 - 使用到updateStateByKey要开启checkpoint机制和功能。
- 多久会将内存中的数据写入到磁盘一份?
如果batchInterval设置的时间小于10秒,那么10秒写入磁盘一份。如果batchInterval设置的时间大于10秒,那么就会batchInterval时间间隔写入磁盘一份。
- 窗口操作
- 窗口操作理解图:
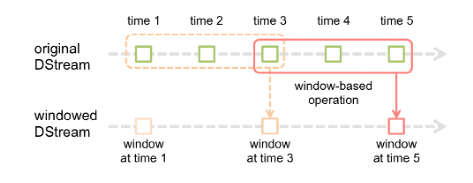
假设每隔5s 1个batch,上图中窗口长度为15s,窗口滑动间隔10s。 - 窗口长度和滑动间隔必须是batchInterval的整数倍。如果不是整数倍会检测报错。
- 优化后的window窗口操作示意图:
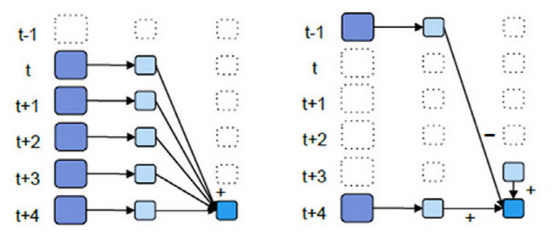
- 优化后的window操作要保存状态所以要设置checkpoint路径,没有优化的window操作可以不设置checkpoint路径。
Driver HA(Standalone或者Mesos)
因为SparkStreaming是7*24小时运行,Driver只是一个简单的进程,有可能挂掉,所以实现Driver的HA就有必要(如果使用的Client模式就无法实现Driver HA ,这里针对的是cluster模式)。Yarn平台cluster模式提交任务,AM(AplicationMaster)相当于Driver,如果挂掉会自动启动AM。这里所说的DriverHA针对的是Spark standalone和Mesos资源调度的情况下。实现Driver的高可用有两个步骤:
第一:提交任务层面,在提交任务的时候加上选项 --supervise,当Driver挂掉的时候会自动重启Driver。
第二:代码层面,使用JavaStreamingContext.getOrCreate(checkpoint路径,JavaStreamingContextFactory)
- Driver中元数据包括:
- 创建应用程序的配置信息。
- DStream的操作逻辑。
- job中没有完成的批次数据,也就是job的执行进度。
SparkStreaming+Kafka
- receiver模式
- receiver模式原理图
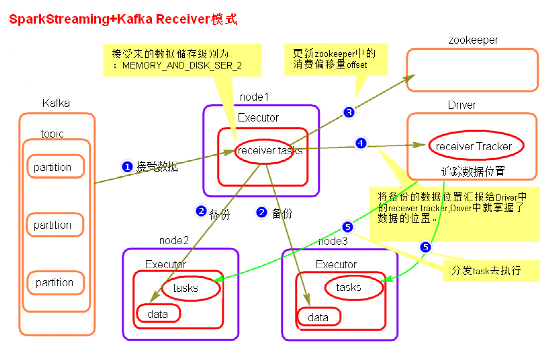
- receiver模式理解:
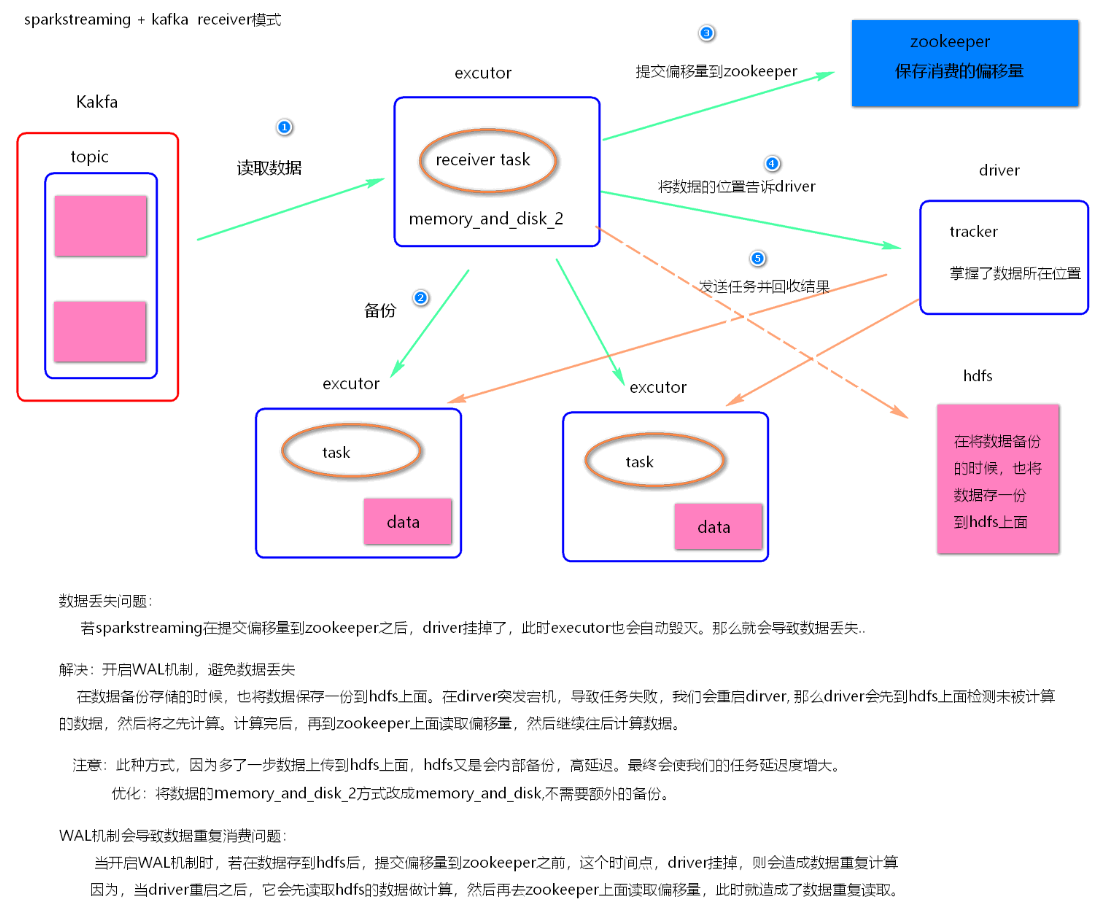
在SparkStreaming程序运行起来后,Executor中会有receiver tasks接收kafka推送过来的数据。数据会被持久化,默认级别为MEMORY_AND_DISK_SER_2,这个级别也可以修改。receiver task对接收过来的数据进行存储和备份,这个过程会有节点之间的数据传输。备份完成后去zookeeper中更新消费偏移量,然后向Driver中的receiver tracker汇报数据的位置。最后Driver根据数据本地化将task分发到不同节点上执行。 - receiver模式中存在的问题
当Driver进程挂掉后,Driver下的Executor都会被杀掉,当更新完zookeeper消费偏移量的时候,Driver如果挂掉了,就会存在找不到数据的问题,相当于丢失数据。
如何解决这个问题?
开启WAL(write ahead log)预写日志机制,在接受过来数据备份到其他节点的时候,同时备份到HDFS上一份(我们需要将接收来的数据的持久化级别降级到MEMORY_AND_DISK),这样就能保证数据的安全性。不过,因为写HDFS比较消耗性能,要在备份完数据之后才能进行更新zookeeper以及汇报位置等,这样会增加job的执行时间,这样对于任务的执行提高了延迟度。 - receiver模式代码(见代码)
- receiver的并行度设置
receiver的并行度是由spark.streaming.blockInterval来决定的,默认为200ms,假设batchInterval为5s,那么每隔blockInterval就会产生一个block,这里就对应每批次产生RDD的partition,这样5秒产生的这个Dstream中的这个RDD的partition为25个,并行度就是25。如果想提高并行度可以减少blockInterval的数值,但是最好不要低于50ms。 - 补充图:
- Driect模式
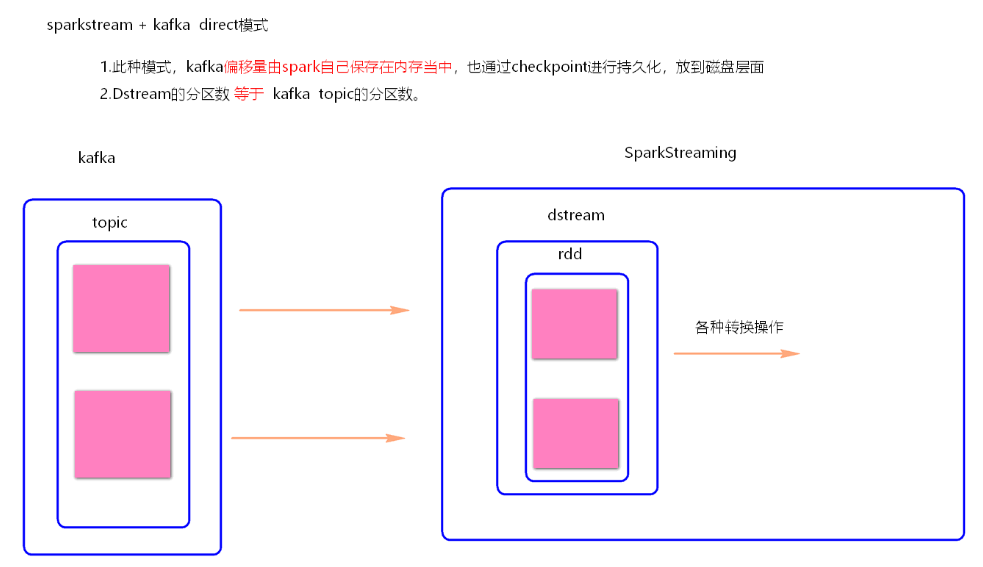
- Direct模式理解
SparkStreaming+kafka 的Driect模式就是将kafka看成存数据的一方,不是被动接收数据,而是主动去取数据。消费者偏移量也不是用zookeeper来管理,而是SparkStreaming内部对消费者偏移量自动来维护,默认消费偏移量是在内存中,当然如果设置了checkpoint目录,那么消费偏移量也会保存在checkpoint中。当然也可以实现用zookeeper来管理。 - Direct模式并行度设置
Direct模式的并行度是由读取的kafka中topic的partition数决定的。 - Direct模式代码(见代码)
- 补充图
- 相关配置
- 预写日志:
spark.streaming.receiver.writeAheadLog.enable 默认false没有开启 - blockInterval:
spark.streaming.blockInterval 默认200ms - 反压机制:
spark.streaming.backpressure.enabled 默认false - 接收数据速率:
- Receiver模式:
spark.streaming.receiver.maxRate 默认没有设置 - Direct模式:
spark.streaming.kafka.maxRatePerPartition - 优雅的停止sparkstream :
spark.streaming.stopGracefullyOnShutdown 设置成true
kill -15/sigterm driverpid
最后
以上就是甜美睫毛最近收集整理的关于Spark简介RDD算子资源调度和任务调度集群搭建以及测试相关术语Standalone模式两种提交任务方式Yarn模式两种提交任务方式窄依赖和宽依赖StagePV&UVSpark-Submit提交参数二次排序分组取topN和topNSparkShell的使用SparkUIMaster HA广播变量和累加器资源调度源码分析任务调度源码分析SparkShuffleSpark内存管理Shuffle调优SparkSqlSpark Streaming的全部内容,更多相关Spark简介RDD算子资源调度和任务调度集群搭建以及测试相关术语Standalone模式两种提交任务方式Yarn模式两种提交任务方式窄依赖和宽依赖StagePV&UVSpark-Submit提交参数二次排序分组取topN和topNSparkShell的使用SparkUIMaster内容请搜索靠谱客的其他文章。








发表评论 取消回复