如何xie一个健壮强的mapreduce程序?
相信每个程序员在编程时都会问自己两个问题“我如何完成这个任务”,以及“怎么能让程序运行得更快”。同样,MapReduce计算模型的多次优化也是为了更好地解答这两个问题。
MapReduce计算模型的优化主要集中在两个方面:一是计算性能方面的优化;二是I/O操作方面的优化。这其中,又包含七个方面的内容。
hadoop参数调优:http://blog.csdn.net/qq_39532946/article/details/76463966
MapReducer优化
1.自定义分区 extends Partitioner 可以使用map输出的key或者value
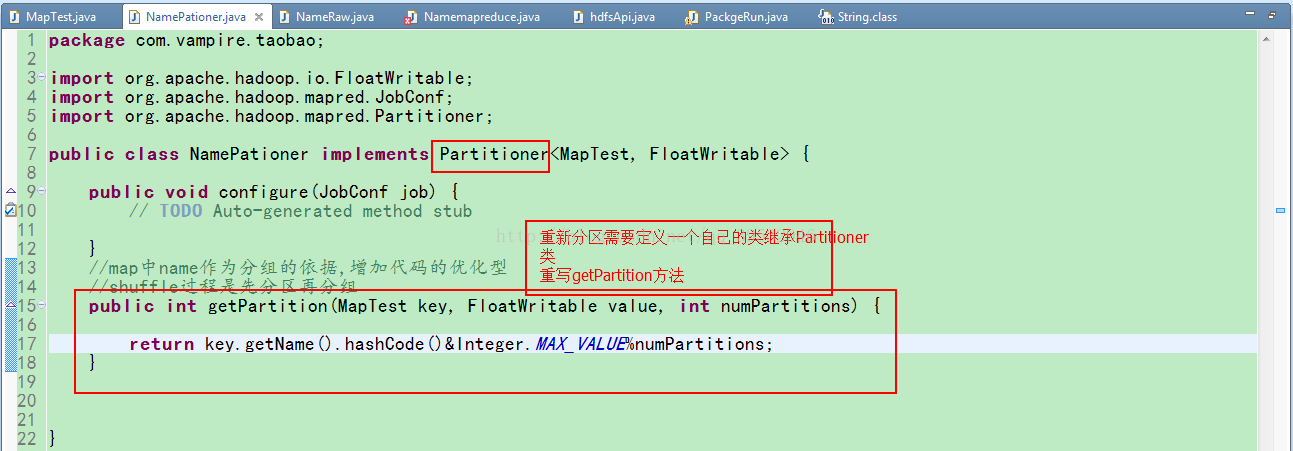
2.自定义分组 implements RawComparator 重点
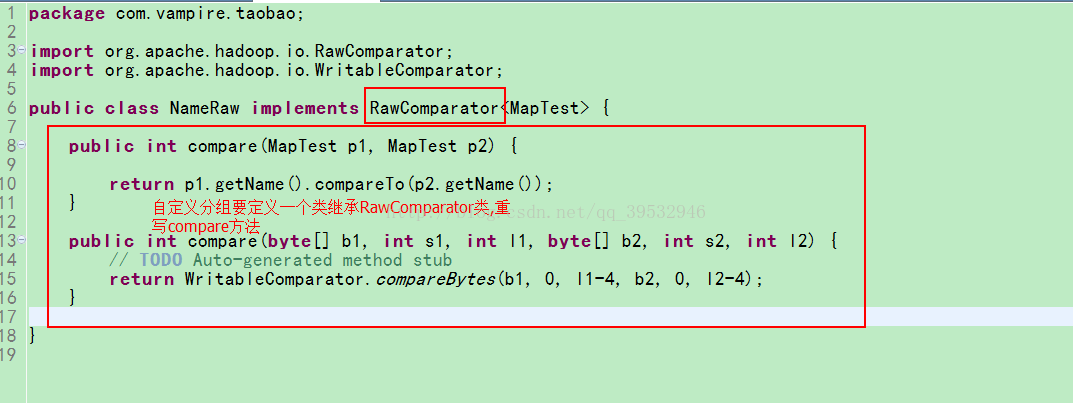
WritableComparator.compareBytes,可以实现在字节数据层面上的比较,更加高效,分组的作用就是为了减少key value对
3.启用Combiner 减少reduce端拉去的文件(key value对)数量
Combine函数是用于本地合并数据的函数。在有些情况下,Map函数产生的中间数据会有很多是重复的,比如在一个简单的WordCount程序中,因为词频是接近与一个zipf分布的,每个Map任务可能会产生成千上万个<the, 1>记录,若将这些记录一一传送给Reduce任务是很耗时的。所以,MapReduce框架运行用户写的combine函数用于本地合并,这会大大减少网络I/O操作的消耗。此时就可以利用combine函数先计算出在这个Block中单词the的个数。合理地设计combine函数会有效地减少网络传输的数据量,提高MapReduce的效率。
在MapReduce程序中使用combine很简单,只需在程序中添加如下内容:
job.setCombinerClass(combine.class);
在WordCount程序中,可以指定Reduce类为combine函数,具体如下:
job.setCombinerClass(Reduce.class);
4.shuffle启用压缩 map端压缩 reduce端解压缩 平衡集群的资源(CPU 内存)和网络IO
编写MapReduce程序时,可以选择对Map的输出和最终的输出结果进行压缩(同时可以选择压缩方式)。在一 些情况下,Map的中间输出可能会 很大,对其进行压缩可以有效地减少网络上的数据传输量。对最终结果的压缩 虽然会减少数据写HDFS的时间,但是也会对读取产生一定的影响,因此 要根据实际情况来选择(第7章中提供 了 一个小实验来验证压缩的效果)。
mapreduce.task.io.sort.factor一次性合并小文件的数量 默认10个
mapreduce.map.output.compress 启用压缩,默认是false
org.apache.hadoop.io.compress.DefaultCodec默认使用的压缩算法
5.CombinerFileInputFormat来合并小文件
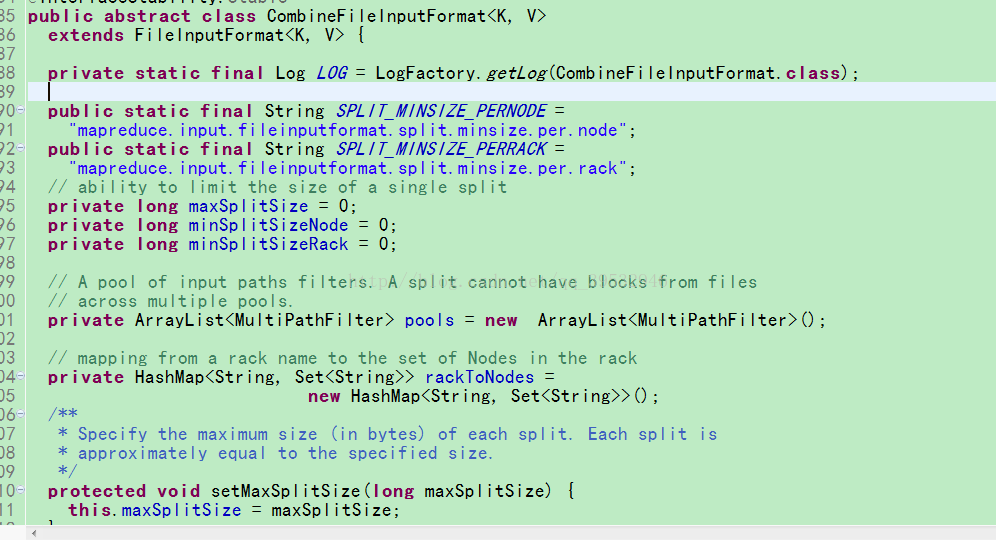
maxSize:由配置参数mapred.max.spilt.size确定,已经不考虑用户设定的maptask个数;
minSize:inputSplit的最小值,由配置参数mapred.min.spilt.size确定,默认值为1;
BlockSize:HDFS中块的大小
splitSize=max(minsplitSzie,min(maxsplitSize,blockSize=128M))
fileSzie/splitSzie=split个数
conf.setLong("mapred.max.split.size",splitSize)
conf.setLong("mapred.min.split.size",splitSize)
按照正常方式,当最后两个切片小于blockSize大小的110%,会合并成一个block.
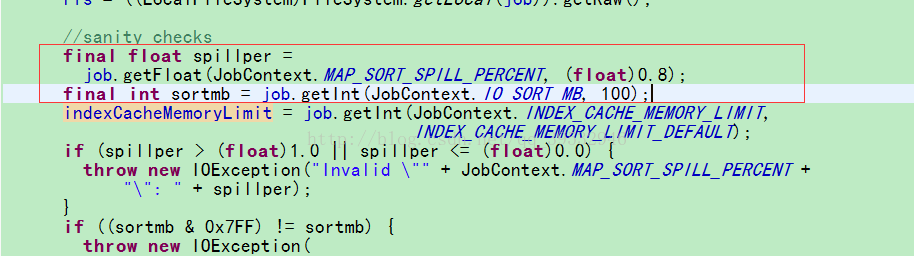
6.调整shffle环形缓冲区大小以及spill溢写的阈值(MapOutputBuffer)
调整Mapper环形缓冲区的大小
conf.set("io.sort.mb", "100");
conf.set("io.sort.record.percent", "0.05");
7.自定义key和value,根据业务需求.
当很多时候map阶段的key或者value接收已经不是简单的数据类型时,这时可能就要想到定义一个javabean或者是collect集合来封装一些数据.
当需要利用value去封装一些数据的话,只需要定义一个实现Writable类,重写方法即可;
example:
publicclass PackgeFlowimplements Writable{
private Long uppackge;
private Long downpackge;
private Long entriepackgeLong;
publicvoid write(DataOutput out)throws IOException {
out.writeLong(uppackge);
out.writeLong(downpackge);
out.writeLong(entriepackgeLong);
}
publicvoid readFields(DataInput in)throws IOException {
uppackge=in.readLong();
downpackge=in.readLong();
entriepackgeLong=in.readLong();
}
当需要利用key去封装一些数据的话,只需要定义一个实现WritableComparable类,重写方法即可;mapreduce中的partition默认分区方法由key和reduce个数算来,重新定义了map中的key的类型,会影响后面分区和分组(记得重写hashcode和equals方法);
example:
public class MapTest implements WritableComparable<MapTest>{
private String name;
private Float money;
public void write(DataOutput out)throws IOException{
out.writeUTF(name);
out.writeFloat(money);
}
public void readFields(DataInput in)throws IOException{
name=in.readUTF();
money=in.readFloat();
}
//shuffle 过程中的排序就是此处的比较得来
public int compareTo(MapTest o){
//先比较二者的那么
int comp=this.name.compareTo(o.name);
if(0!=comp){
return comp;
}
//map中的name值相同时比较map的value
return this.money.compareTo(o.money);
}
@Override
public int hashCode() {
final int prime = 31;
int result =1;
result = prime* result+ Float.floatToIntBits(money);
result = prime* result+((name==null)? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj){
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
MapTest other= (MapTest) obj;
if (Float.floatToIntBits(money)!= Float.floatToIntBits(other.money))
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
}
最后
以上就是矮小未来最近收集整理的关于MapReducer优化的全部内容,更多相关MapReducer优化内容请搜索靠谱客的其他文章。



![MapReduce: 提高MapReduce性能的七点建议[译]](https://www.shuijiaxian.com/files_image/reation/bcimg14.png)




发表评论 取消回复