C++内存池
前言:
使用new expression为类的多个实例分配动态内存时,cookie导致内存利用率可能不高,此时我们通过实现类的内存池来降低overhead。从不成熟到巧妙优化的内存池,得益于union的分时复用特性,内存利用率得到了提高。
1、C++内存池分析
在实例化某个类的对象时(在heap而不是stack中),若不使用array new,则每次实例化时都要调用一次内存分配函数,类的每个实例在内存中都有上下两个cookie,从而降低了内存的利用率。然而,array new也有先天的缺陷,即只能调用默认无参构造函数,这对于很多没有提供无参构造函数的类来说是不合适的。
因此,我们可以对于一个没有实例化的类第一次实例化时,先分配一大块内存(内存池),这一大块内存记录在类中,只有上下两个cookie,能够容纳多个实例。后续实例化时,若内存池中还有剩余内存,则不必申请内存分配,只在内存池中分配。内存回收时,将实例所占用的内存回收到内存池中。若内存池中无内存,则再申请分配大块内存。
2、多此一举方案
我们以链表的形式组织内存池,内存池中链表的每个结点是一个小桶,这个桶中装我们实例化的对象。
内存池链表的头结点记录在类中,即以class staic变量的形式存储。组织形式如下:

实现代码如下:
#include <iostream>
using namespace std;
class DemoClass{
public:
DemoClass() = default;
DemoClass(int i):data(i){}
static void* operator new(size_t size);
static void operator delete(void *);
virtual ~DemoClass(){}
private:
DemoClass *next;
int data;
static DemoClass *freeMemHeader;
static const size_t POOL_SIZE;
};
DemoClass * DemoClass::freeMemHeader = nullptr;
const size_t DemoClass::POOL_SIZE = 24;//设定内存池能容纳24个DemoClass对象
void* DemoClass::operator new(size_t size){
DemoClass* p;
if(!freeMemHeader){//freeMemHeader为空,内存池中无空间,分配内存
size_t pool_mem_bytes = size * POOL_SIZE;//内存池的字节大小 = 每个实例的大小(字节数)* 内存池中能容纳的最大实例数
freeMemHeader = reinterpret_cast<DemoClass*>(new char[pool_mem_bytes]);//new char[]分配pool_mem_bytes个字节,因为每个char占用1个字节
cout << "Info:向操作系统申请了" << pool_mem_bytes << "字节的内存。" << endl;
for(int i = 0;i < POOL_SIZE - 1; ++i){//将内存池中POOL_SIZE个小块内存,串起来。
freeMemHeader[i].next = &freeMemHeader[i + 1];
}
freeMemHeader[POOL_SIZE - 1].next = nullptr;
}
p = freeMemHeader;//取内存池(链表)的头部,分配给要实例化的对象
cout << "Info:从内存池中取了" << size << "字节的内存。" << endl;
freeMemHeader = freeMemHeader -> next;//从内存池中删去取出的那一小块地址,即更新内存池
p -> next = nullptr;
return p;
}
void DemoClass::operator delete(void* p){
DemoClass* tmp = (DemoClass*) p;
tmp -> next = freeMemHeader;
freeMemHeader = tmp;
}
测试代码如下:
int main(int argc, char* argv[]){
cout << "sizeof(DemoClass):" << sizeof(DemoClass) << endl;
size_t N = 32;
DemoClass* demos[N];
for(int i = 0; i < N; ++i){
demos[i] = new DemoClass(i);
cout << "address of the ith demo:" << demos[i] << endl;
cout << endl;
}
return 0;
}
其结果如下:
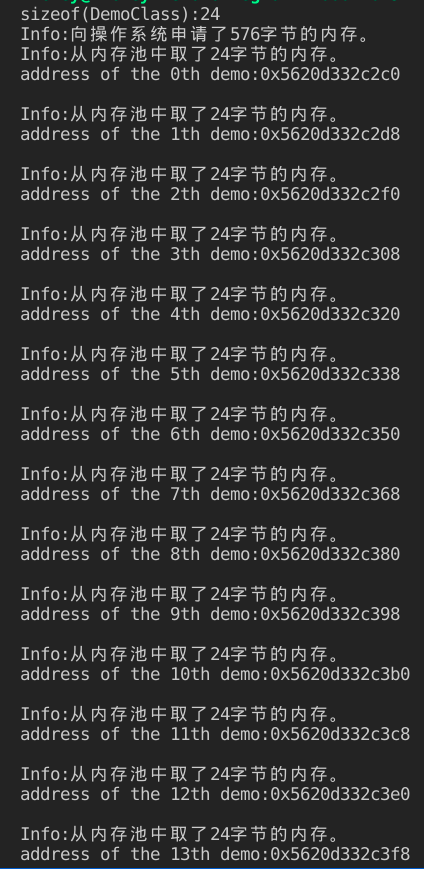

可以看到每个DemoClass的实例大小为24字节,内存池一次从操作系统中申请了576个字节的内存,这些内存可以容纳24个实例。上面显示出了每个实例的内存地址,内存池中相邻实例的内存首地址之差为24,即实例的大小,证明了一个内存池的实例之间确实没有cookie。
当内存池中内存用完后,又向操作系统申请了576个字节的内存。
由此,只有每个内存池两侧有cookie,而内存池中的实例不存在cookie,相比于每次调用new expression实例化对象都有cookie,内存池的组织形式确实在形式上提高了内存利用率。
那么,有什么问题么?
sizeof(DemoClass)等于24:
- int data数据域占4个字节
- 两个构造函数一个析构函数各占4字节,共12字节
- 额外的指针DemoClass*,在64位机器上,占8个字节
这样一个DemoClass的大小确实是24字节。wait,what?
我们为了解决cookie带来的内存浪费,引入了指针next,但却又引入了8个字节的overhead,脱裤子放屁,多此一举?
这样看来确实没有达到要求,但至少为我们提供了一种思路,不是么?
3、分时复用改进方案
首先我们先回忆下c++ 中的Union:
在任意时刻,联合中只能有一个数据成员可以有值。当给联合中某个成员赋值之后,该联合中的其它成员就变成未定义状态了。
结合我们之前不成熟的内存池,我们发现,当内存池中的桶还没有被分配给实例时,只有next域有用,而当桶被分配给实例后,next域就没什么用了;当桶被回收时,数据域变无用而next指针又需要用到。这不正是union的特性么?
看一下代码实现:
#include <iostream>
using namespace std;
class DemoClass{
public:
DemoClass() = default;
DemoClass(int i, double p){
data.num = i;
data.price = p;
}
static void* operator new(size_t size);
static void operator delete(void *);
virtual ~DemoClass(){}
private:
struct DemoData{
int num;
double price;
};
private:
static DemoClass *freeMemHeader;
static const size_t POOL_SIZE;
union {
DemoClass *next;
DemoData data;
};
};
DemoClass * DemoClass::freeMemHeader = nullptr;
const size_t DemoClass::POOL_SIZE = 24;//设定内存池能容纳24个DemoClass对象
void* DemoClass::operator new(size_t size){
DemoClass* p;
if(!freeMemHeader){//freeMemHeader为空,内存池中无空间,分配内存
size_t pool_mem_bytes = size * POOL_SIZE;//内存池的字节大小 = 每个实例的大小(字节数)* 内存池中能容纳的最大实例数
freeMemHeader = reinterpret_cast<DemoClass*>(new char[pool_mem_bytes]);//new char[]分配pool_mem_bytes个字节,因为每个char占用1个字节
cout << "Info:向操作系统申请了" << pool_mem_bytes << "字节的内存。" << endl;
for(int i = 0;i < POOL_SIZE - 1; ++i){//将内存池中POOL_SIZE个小块内存,串起来。
freeMemHeader[i].next = &freeMemHeader[i + 1];
}
freeMemHeader[POOL_SIZE - 1].next = nullptr;
}
p = freeMemHeader;//取内存池(链表)的头部,分配给要实例化的对象
cout << "Info:从内存池中取了" << size << "字节的内存。" << endl;
freeMemHeader = freeMemHeader -> next;//从内存池中删去取出的那一小块地址,即更新内存池
p -> next = nullptr;
return p;
}
void DemoClass::operator delete(void* p){
DemoClass* tmp = (DemoClass*) p;
tmp -> next = freeMemHeader;
freeMemHeader = tmp;
}
对比前一种实现代码,只是构造函数、数据域和指针域的组织形式发生了变化:
- 由于数据域增加了price项,构造函数中也增加了对应的参数
- 数据域被集成定义成一个类自定义struct类型
- 数据域和指针域被组织为union
测试代码依旧:
int main(int argc, char* argv[]){
cout << "sizeof(DemoClass):" << sizeof(DemoClass) << endl;
size_t N = 32;
DemoClass* demos[N];
for(int i = 0; i < N; ++i){
demos[i] = new DemoClass(i, i * i);
cout << "address of the " << i << "th demo:" << demos[i] << endl;
cout << endl;
}
return 0;
}
结果:

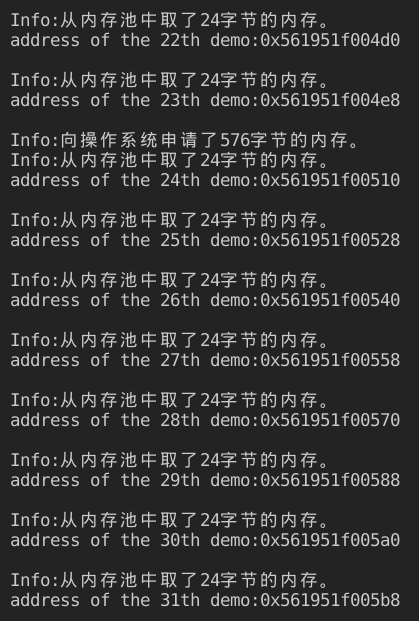
可以看到每个DemoClass的实例大小为24字节,一个内存池的实例之间没有cookie。
分析一下sizeof(DemoClass)等于24的缘由:
data数据域占12个字节(int 4字节、double 8字节)。
两个构造函数一个析构函数各占4字节,共12字节。
指针DemoClass,在64位机器上,占8个字节,但由于和数据域使用了union,data数据域12个字节中的前8个字节在适当的时机被看作DemoClass,而不占用额外空间,消除了overhead。
这样一个DemoClass的大小确实是24字节。利用union的分时复用特性,我们消除了初步方案中指针带来的脱裤子放屁效果。
4、其他的思考
细心的读者可能会发现,前面的那两种方案都有共同的小缺陷,即当程序一直实例化而不析构时,内存池会向操作系统申请多次大块内存,而当这些对象一起回收时,内存池中的剩余桶数会远大于设定的POOL_SIZE的大小,这个峰值多大取决于类实例化和回收的时机。
另外,内存池中的内存暂时不会回收给操作系统,峰值很大可能会对内存分配带来一些影响,不过这却不属于内存泄漏。在以后的文章中,我们可能会讨论一些性能更好的内存分配方案。
以上就是C++内存池两种方案对比的详细内容,更多关于C++内存池的资料请关注靠谱客其它相关文章!望大家以后多多支持靠谱客!
最后
以上就是听话草莓最近收集整理的关于C++内存池两种方案解析的全部内容,更多相关C++内存池两种方案解析内容请搜索靠谱客的其他文章。








发表评论 取消回复