前向逐步回归原理
前向逐步回归的过程是:遍历属性的一列子集,选择使模型效果最好的那一列属性。接着寻找与其组合效果最好的第二列属性,而不是遍历所有的两列子集。以此类推,每次遍历时,子集都包含上一次遍历得到的最优子集。这样,每次遍历都会选择一个新的属性添加到特征集合中,直至特征集合中特征个数不能再增加。
数据导入并分组
导入数据,将数据集抽取70%作为训练集,剩下30%作为测试集。特征与标签分开存放。
导入数据
R语言的实现如下图:

train和test中存储的数据情况如下:

特征与标签分开存放
R语言的实现如下图:
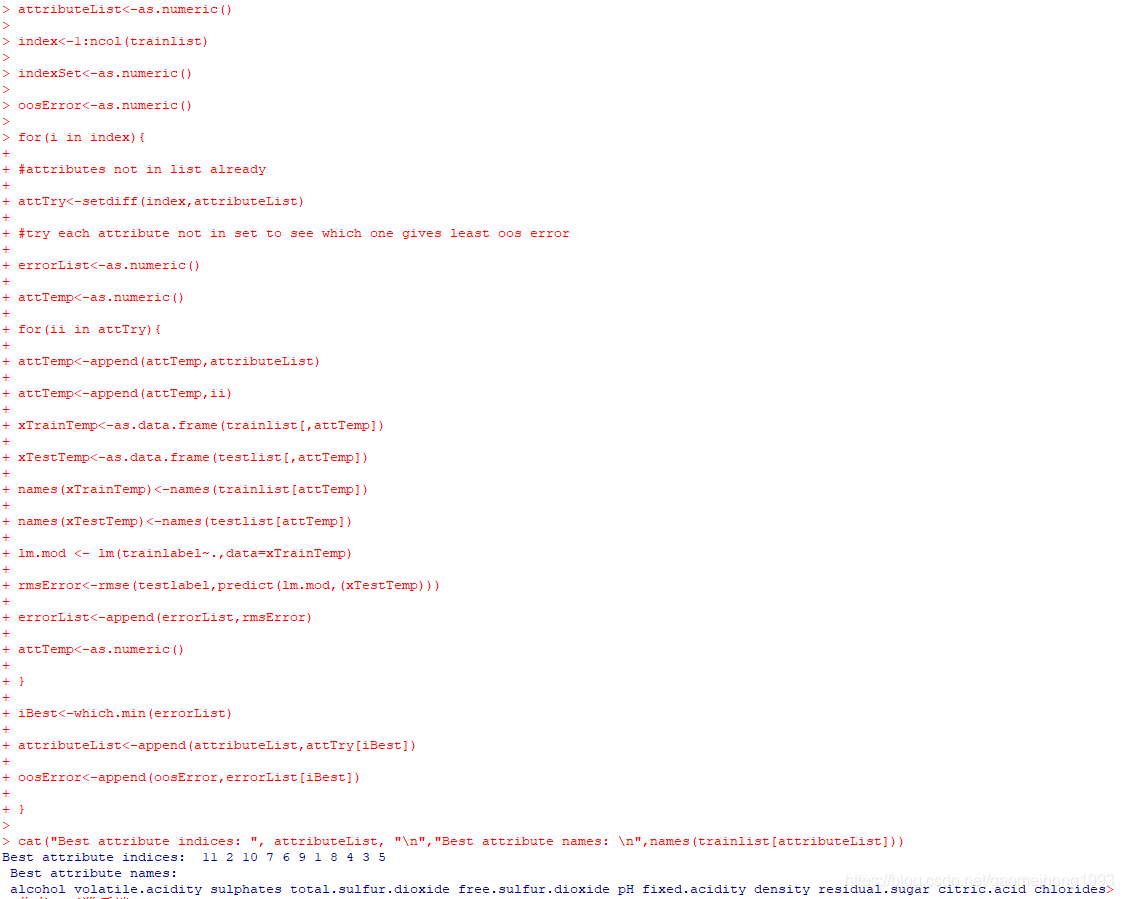
前向逐步回归构建输出特征集合
通过for循环,从属性的一个子集开始进行遍历。第一次遍历时,该子集为空。每一个属性被加入子集后,通过线性回归来拟合模型,并计算在测试集上的误差,每次遍历选择得到误差最小的一列加入输出特征集合中。最终得到输出特征集合的关联索引和属性名称。
从空开始一次创建属性列表
R语言的实现如下图:
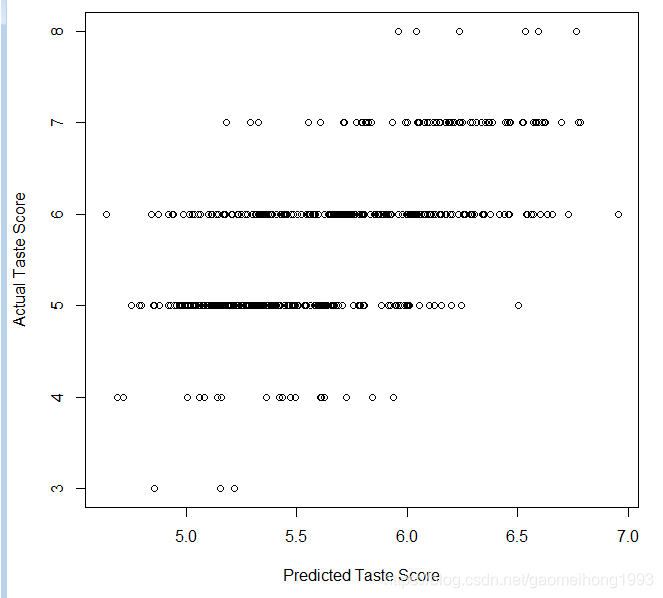
模型效果评估
分别画出RMSE与属性个数之间的关系,前向逐步预测算法对数据预测对错误直方图,和真实标签与预测标签散点图。R实现如下:





到此这篇关于详解R语言实现前向逐步回归(前向选择模型)的文章就介绍到这了,更多相关R语言 前向逐步回归内容请搜索靠谱客以前的文章或继续浏览下面的相关文章希望大家以后多多支持靠谱客!
最后
以上就是忧郁美女最近收集整理的关于详解R语言实现前向逐步回归(前向选择模型)的全部内容,更多相关详解R语言实现前向逐步回归(前向选择模型)内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复