引言
树形结构不论在生活中或者是开发中都是一种非常常见的结构,一个容器对象(如文件夹)下可以存放多种不同的叶子对象或者容器对象,容器对象与叶子对象之间属性差别可能非常大。
由于容器对象和叶子对象在功能上的区别,在使用这些对象的代码中必须有区别地对待容器对象和叶子对象,而实际上大多数情况下我们希望一致地处理它们,因为对于这些对象的区别对待将会使得程序非常复杂。
组合模式为解决此类问题而诞生,它可以让叶子对象和容器对象的使用具有一致性。
组合模式介绍
组合多个对象形成树形结构以表示具有 “整体—部分” 关系的层次结构。组合模式对单个对象(即叶子对象)和组合对象(即容器对象)的使用具有一致性,组合模式又可以称为 “整体—部分”(Part-Whole) 模式,它是一种对象结构型模式。
由于在软件开发中存在大量的树形结构,因此组合模式是一种使用频率较高的结构型设计模式,
在XML解析、组织结构树处理、文件系统设计等领域,组合模式都得到了广泛应用。
角色
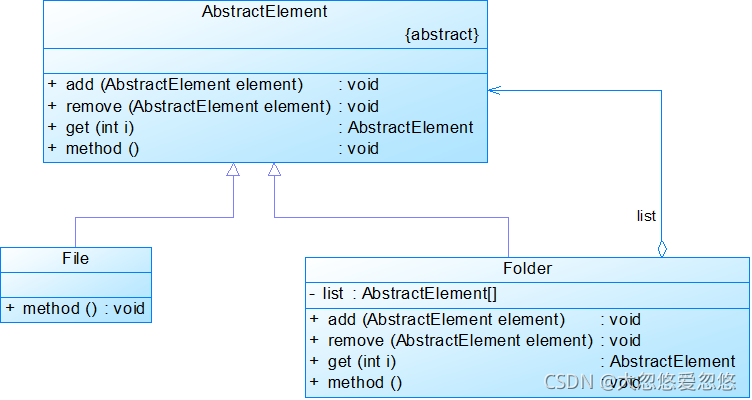
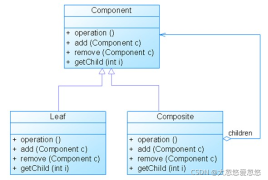
- Component(抽象构件):它可以是接口或抽象类,为叶子构件和容器构件对象声明接口,在该角色中可以包含所有子类共有行为的声明和实现。在抽象构件中定义了访问及管理它的子构件的方法,如增加子构件、删除子构件、获取子构件等。
- Leaf(叶子构件):它在组合结构中表示叶子节点对象,叶子节点没有子节点,它实现了在抽象构件中定义的行为。对于那些访问及管理子构件的方法,可以通过异常等方式进行处理。
- Composite(容器构件):它在组合结构中表示容器节点对象,容器节点包含子节点,其子节点可以是叶子节点,也可以是容器节点,它提供一个集合用于存储子节点,实现了在抽象构件中定义的行为,包括那些访问及管理子构件的方法,在其业务方法中可以递归调用其子节点的业务方法。
组合模式的关键是定义了一个抽象构件类,它既可以代表叶子,又可以代表容器,而客户端针对该抽象构件类进行编程,无须知道它到底表示的是叶子还是容器,可以对其进行统一处理。同时容器对象与抽象构件类之间还建立一个聚合关联关系,在容器对象中既可以包含叶子,也可以包含容器,以此实现递归组合,形成一个树形结构。
模式结构

示例代码
典型的抽象构件角色代码:
public abstract class Component
{
public abstract void add(Component c);
public abstract void remove(Component c);
public abstract Component getChild(int i);
public abstract void operation();
}
典型的容器构件角色代码:
public class Leaf extends Component
{
public void add(Component c)
{ //异常处理或错误提示 }
public void remove(Component c)
{ //异常处理或错误提示 }
public Component getChild(int i)
{ //异常处理或错误提示 }
public void operation()
{
//实现代码
}
}
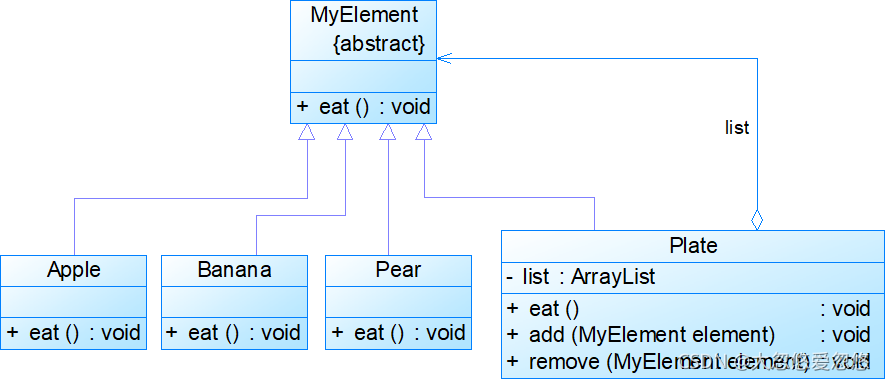
水果盘
在水果盘(Plate)中有一些水果,如苹果(Apple)、香蕉(Banana)、梨子(Pear),当然大水果盘中还可以有小水果盘,现需要对盘中的水果进行遍历(吃),当然如果对一个水果盘执行“吃”方法,实际上就是吃其中的水果。使用组合模式模拟该场景 。

//抽象构建
public abstract class MyElement
{
public abstract void eat();
}
//容器构建
import java.util.*;
public class Plate extends MyElement
{
private ArrayList list=new ArrayList();
public void add(MyElement element)
{
list.add(element);
}
public void delete(MyElement element)
{
list.remove(element);
}
public void eat()
{
for(Object object:list)
{
((MyElement)object).eat(); //递归
}
}
}
//叶子构建
public class Apple extends MyElement
{
public void eat()
{
System.out.println("吃苹果!");
}
}
//叶子构建
public class Banana extends MyElement
{
public void eat()
{
System.out.println("吃香蕉!");
}
}
//叶子构建
public class Pear extends MyElement
{
public void eat()
{
System.out.println("吃梨子!");
}
}
//客户端
public class Client
{
public static void main(String a[])
{
MyElement obj1,obj2,obj3,obj4,obj5;
Plate plate1,plate2,plate3;
obj1=new Apple();
obj2=new Pear();
plate1=new Plate();
plate1.add(obj1);
plate1.add(obj2);
obj3=new Banana();
obj4=new Banana();
plate2=new Plate();
plate2.add(obj3);
plate2.add(obj4);
obj5=new Apple();
plate3=new Plate();
plate3.add(plate1);
plate3.add(plate2);
plate3.add(obj5);
plate3.eat();
}
}

文件浏览
我们来实现一个简单的目录树,有文件夹和文件两种类型,首先需要一个抽象构件类,声明了文件夹类和文件类需要的方法
public abstract class Component {
public String getName() {
throw new UnsupportedOperationException("不支持获取名称操作");
}
public void add(Component component) {
throw new UnsupportedOperationException("不支持添加操作");
}
public void remove(Component component) {
throw new UnsupportedOperationException("不支持删除操作");
}
public void print() {
throw new UnsupportedOperationException("不支持打印操作");
}
public String getContent() {
throw new UnsupportedOperationException("不支持获取内容操作");
}
}
实现一个文件夹类 Folder,继承 Component,定义一个 List<Component> 类型的componentList属性,用来存储该文件夹下的文件和子文件夹,并实现 getName、add、remove、print等方法
public class Folder extends Component {
private String name;
private List<Component> componentList = new ArrayList<Component>();
public Integer level;
public Folder(String name) {
this.name = name;
}
@Override
public String getName() {
return this.name;
}
@Override
public void add(Component component) {
this.componentList.add(component);
}
@Override
public void remove(Component component) {
this.componentList.remove(component);
}
@Override
public void print() {
System.out.println(this.getName());
if (this.level == null) {
this.level = 1;
}
String prefix = "";
for (int i = 0; i < this.level; i++) {
prefix += "t- ";
}
for (Component component : this.componentList) {
if (component instanceof Folder){
((Folder)component).level = this.level + 1;
}
System.out.print(prefix);
component.print();
}
this.level = null;
}
}
文件类 File,继承Component父类,实现 getName、print、getContent等方法
public class File extends Component {
private String name;
private String content;
public File(String name, String content) {
this.name = name;
this.content = content;
}
@Override
public String getName() {
return this.name;
}
@Override
public void print() {
System.out.println(this.getName());
}
@Override
public String getContent() {
return this.content;
}
}
我们来测试一下
public class Test {
public static void main(String[] args) {
Folder DSFolder = new Folder("设计模式资料");
File note1 = new File("组合模式笔记.md", "组合模式组合多个对象形成树形结构以表示具有 "整体—部分" 关系的层次结构");
File note2 = new File("工厂方法模式.md", "工厂方法模式定义一个用于创建对象的接口,让子类决定将哪一个类实例化。");
DSFolder.add(note1);
DSFolder.add(note2);
Folder codeFolder = new Folder("样例代码");
File readme = new File("README.md", "# 设计模式示例代码项目");
Folder srcFolder = new Folder("src");
File code1 = new File("组合模式示例.java", "这是组合模式的示例代码");
srcFolder.add(code1);
codeFolder.add(readme);
codeFolder.add(srcFolder);
DSFolder.add(codeFolder);
DSFolder.print();
}
}
输出结果
设计模式资料
- 组合模式笔记.md
- 工厂方法模式.md
- 样例代码
- - README.md
- - src
- - - 组合模式示例.java
在这里父类 Component 是一个抽象构件类,Folder 类是一个容器构件类,File 是一个叶子构件类,Folder 和 File 继承了 Component,Folder 与 Component 又是聚合关系
更复杂的组合模式

透明与安全
在使用组合模式时,根据抽象构件类的定义形式,我们可将组合模式分为透明组合模式和安全组合模式两种形式。
透明组合模式
透明组合模式中,抽象构件角色中声明了所有用于管理成员对象的方法,譬如在示例中 Component 声明了 add、remove 方法,这样做的好处是确保所有的构件类都有相同的接口。透明组合模式也是组合模式的标准形式。
透明组合模式的缺点是不够安全,因为叶子对象和容器对象在本质上是有区别的,叶子对象不可能有下一个层次的对象,即不可能包含成员对象,因此为其提供 add()、remove() 等方法是没有意义的,这在编译阶段不会出错,但在运行阶段如果调用这些方法可能会出错(如果没有提供相应的错误处理代码)
安全组合模式
在安全组合模式中,在抽象构件角色中没有声明任何用于管理成员对象的方法,而是在容器构件 Composite 类中声明并实现这些方法
安全组合模式的缺点是不够透明,因为叶子构件和容器构件具有不同的方法,且容器构件中那些用于管理成员对象的方法没有在抽象构件类中定义,因此客户端不能完全针对抽象编程,必须有区别地对待叶子构件和容器构件。
在实际应用中 java.awt 和 swing 中的组合模式即为安全组合模式。

组合模式总结
优点
- 组合模式可以清楚地定义分层次的复杂对象,表示对象的全部或部分层次,它让客户端忽略了层次的差异,方便对整个层次结构进行控制。
- 客户端可以一致地使用一个组合结构或其中单个对象,不必关心处理的是单个对象还是整个组合结构,简化了客户端代码。
- 在组合模式中增加新的容器构件和叶子构件都很方便,无须对现有类库进行任何修改,符合“开闭原则”。
- 组合模式为树形结构的面向对象实现提供了一种灵活的解决方案,通过叶子对象和容器对象的递归组合,可以形成复杂的树形结构,但对树形结构的控制却非常简单。
缺点
- 使得设计更加复杂,客户端需要花更多时间理清类之间的层次关系。
- 在增加新构件时很难对容器中的构件类型进行限制。
适用场景
- 在具有整体和部分的层次结构中,希望通过一种方式忽略整体与部分的差异,客户端可以一致地对待它们。
- 在一个使用面向对象语言开发的系统中需要处理一个树形结构。
- 在一个系统中能够分离出叶子对象和容器对象,而且它们的类型不固定,需要增加一些新的类型。
应用
XML文档解析

1 <?xml version="1.0"?> 2 <books> 3 <book> 4 <author>Carson</author> 5 <price format="dollar">31.95</price> 6 <pubdate>05/01/2001</pubdate> 7 </book> 8 <pubinfo> 9 <publisher>MSPress</publisher> 10 <state>WA</state> 11 </pubinfo> 12 </books>
文件
操作系统中的目录结构是一个树形结构,因此在对文件和文件夹进行操作时可以应用组合模式,例如杀毒软件在查毒或杀毒时,既可以针对一个具体文件,也可以针对一个目录。如果是对目录查毒或杀毒,将递归处理目录中的每一个子目录和文件。
HashMap
HashMap 提供 putAll 的方法,可以将另一个 Map 对象放入自己的存储空间中,如果有相同的 key 值则会覆盖之前的 key 值所对应的 value 值
public class Test {
public static void main(String[] args) {
Map<String, Integer> map1 = new HashMap<String, Integer>();
map1.put("aa", 1);
map1.put("bb", 2);
map1.put("cc", 3);
System.out.println("map1: " + map1);
Map<String, Integer> map2 = new LinkedMap();
map2.put("cc", 4);
map2.put("dd", 5);
System.out.println("map2: " + map2);
map1.putAll(map2);
System.out.println("map1.putAll(map2): " + map1);
}
}
输出结果
map1: {aa=1, bb=2, cc=3}
map2: {cc=4, dd=5}
map1.putAll(map2): {aa=1, bb=2, cc=4, dd=5}
查看 putAll 源码
public void putAll(Map<? extends K, ? extends V> m) {
putMapEntries(m, true);
}
putAll 接收的参数为父类 Map 类型,所以 HashMap 是一个容器类,Map 的子类为叶子类,当然如果 Map 的其他子类也实现了 putAll 方法,那么它们都既是容器类,又都是叶子类
Mybatis SqlNode中的组合模式
MyBatis 的强大特性之一便是它的动态SQL,其通过 if, choose, when, otherwise, trim, where, set, foreach 标签,可组合成非常灵活的SQL语句,从而提高开发人员的效率。
<select id="findActiveBlogLike" resultType="Blog">
SELECT * FROM BLOG WHERE state = ‘ACTIVE'
<if test="title != null">
AND title like #{title}
</if>
<if test="author != null and author.name != null">
AND author_name like #{author.name}
</if>
</select>
Mybatis在处理动态SQL节点时,应用到了组合设计模式,Mybatis会将映射配置文件中定义的动态SQL节点、文本节点等解析成对应的 SqlNode 实现,并形成树形结构。
SQLNode 的类图如下所示:

需要先了解 DynamicContext 类的作用:主要用于记录解析动态SQL语句之后产生的SQL语句片段,可以认为它是一个用于记录动态SQL语句解析结果的容器
抽象构件为 SqlNode 接口,源码如下:
public interface SqlNode {
boolean apply(DynamicContext context);
}
apply 是 SQLNode 接口中定义的唯一方法,该方法会根据用户传入的实参,参数解析该SQLNode所记录的动态SQL节点,并调用 DynamicContext.appendSql() 方法将解析后的SQL片段追加到 DynamicContext.sqlBuilder 中保存,当SQL节点下所有的 SqlNode 完成解析后,我们就可以从 DynamicContext 中获取一条动态生产的、完整的SQL语句
然后来看 MixedSqlNode 类的源码:
public class MixedSqlNode implements SqlNode {
private List<SqlNode> contents;
public MixedSqlNode(List<SqlNode> contents) {
this.contents = contents;
}
@Override
public boolean apply(DynamicContext context) {
for (SqlNode sqlNode : contents) {
sqlNode.apply(context);
}
return true;
}
}
MixedSqlNode 维护了一个 List< SqlNode > 类型的列表,用于存储 SqlNode 对象,apply 方法通过 for循环 遍历 contents 并调用其中对象的 apply 方法,这里跟我们的示例中的 Folder 类中的 print 方法非常类似,很明显 MixedSqlNode 扮演了容器构件角色
对于其他SqlNode子类的功能,稍微概括如下:
- TextSqlNode:表示包含 ${} 占位符的动态SQL节点,其 apply 方法会使用 GenericTokenParser解析 ${} 占位符,并直接替换成用户给定的实际参数值
- IfSqlNode:对应的是动态SQL节点 < If > 节点,其 apply 方法首先通过ExpressionEvaluator.evaluateBoolean() 方法检测其 test 表达式是否为 true,然后根据test 表达式的结果,决定是否执行其子节点的 apply() 方法
- TrimSqlNode :会根据子节点的解析结果,添加或删除相应的前缀或后缀。
- WhereSqlNode 和 SetSqlNode 都继承了 TrimSqlNode
- ForeachSqlNode:对应 < for each > 标签,对集合进行迭代
- 动态SQL中的 < choose >、< when >、< otherwise > 分别解析成ChooseSqlNode、IfSqlNode、MixedSqlNode
综上,SqlNode 接口有多个实现类,每个实现类对应一个动态SQL节点,其中 SqlNode 扮演抽象构件角色,MixedSqlNode 扮演容器构件角色,其它一般是叶子构件角色
参考文章
组合模式
设计模式 | 组合模式及典型应用
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注靠谱客的更多内容!
最后
以上就是独特香水最近收集整理的关于Java设计模式之java组合模式详解的全部内容,更多相关Java设计模式之java组合模式详解内容请搜索靠谱客的其他文章。








发表评论 取消回复