介绍
解释器模式(Interpreter Pattern):定义一个语言的文法,并且建立一个解释器来解释该语言中的句子,这里的 “语言” 是指使用规定格式和语法的代码。解释器模式是一种类行为型模式。
角色
AbstractExpression(抽象解释器):在抽象表达式中声明了抽象的解释操作,具体的解释任务由各个实现类完成,它是所有终结符表达式和非终结符表达式的公共父类。
TerminalExpression(终结符表达式):实现与文法中的元素相关联的解释操作,通常一个解释器模式中只有一个终结表达式,但有多个实例,对应不同的终结符。
NonterminalExpression(非终结符表达式):文法中的每条规则对应于一个非终结表达式,非终结符表达式根据逻辑的复杂程度而增加,原则上每个文法规则都对应一个非终结符表达式
Context(环境类):环境类又称为上下文类,它用于存储解释器之外的一些全局信息,通常它临时存储了需要解释的语句。
客户类(Test): 客户端,解析表达式,构建抽象语法树,执行具体的解释操作等.

计算器案例
环境类,存储解释器之外的一些全局信息,通常它临时存储了需要解释的语句
public class Context
{
private Map<Expression, Integer> map = new HashMap<>();
//定义变量
public void add(Expression s, Integer value)
{
map.put(s, value);
}
//将变量转换成数字
public int lookup(Expression s){
return map.get(s);
}
}
解释器接口
public interface Expression
{
int interpreter(Context context);//一定会有解释方法
}
抽象非终结符表达式
public abstract class NonTerminalExpression implements Expression{
Expression e1,e2;
public NonTerminalExpression(Expression e1, Expression e2){
this.e1 = e1;
this.e2 = e2;
}
}
减法表达式实现类
public class MinusOperation extends NonTerminalExpression {
public MinusOperation(Expression e1, Expression e2) {
super(e1, e2);
}
//将两个表达式相减
@Override
public int interpreter(Context context) {
return this.e1.interpreter(context) - this.e2.interpreter(context);
}
}
加法表达式实现类
public class PlusOperation extends NonTerminalExpression {
public PlusOperation(Expression e1, Expression e2) {
super(e1, e2);
}
//将两个表达式相加
@Override
public int interpreter(Context context) {
return this.e1.interpreter(context) + this.e2.interpreter(context);
}
}
终结符表达式(在这个例子,用来存放数字,或者代表数字的字符)
public class TerminalExpression implements Expression{
String variable;
public TerminalExpression(String variable){
this.variable = variable;
}
//获得该变量的值
@Override
public int interpreter(Context context) {
return context.lookup(this);
}
}
测试:
public class Test {
public static void main(String[] args) {
Context context = new Context();
TerminalExpression a = new TerminalExpression("a");
TerminalExpression b = new TerminalExpression("b");
TerminalExpression c = new TerminalExpression("c");
context.add(a, 4);
context.add(b, 8);
context.add(c, 2);
//new PlusOperation(a,b).interpreter(context)--->返回12
// c.interpreter(context)--->2
//MinusOperation(12,2)..interpreter(context)--->10
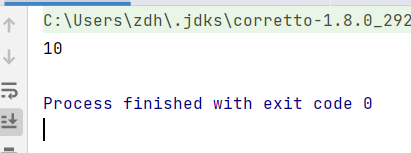
System.out.println(new MinusOperation(new PlusOperation(a,b), c).interpreter(context));
}
}
UML图

深入挖掘
非终结符表达式(相当于树的树杈):在这个例子中就是相加,相减的表达式,称为非终结符,这是非常形象的,因为当运算遇到这类的表达式的时候,必须先把非终结符的结果计算出来,犹如剥茧一般,一层一层的调用,就比如上面的
new MinusOperation(new PlusOperation(a,b), c).interpreter(context)
这个MinusOperation左边参数是new PlusOperation(a,b),是非终结符表达式,所以要调用PlusOperation,因为PlusOperation的左右两边都是TerminalExpression,是终结符表达式,所以计算然后返回,到最外面的MinusOperation函数,发现右边c是终结符表达式,所以可以计算。
终结符表达式(相当于树的叶子):遇到这个表达式interpreter执行能直接返回结果,不会向下继续调用。
构建的语法树

叶子节点即为终结符,树杈即为非终结符,遇到非终结符要继续往下解析,遇到终结符则返回。a+b-c(4+8-2)
上面的语法树是手动建的(new MinusOperation(new PlusOperation(a,b), c).interpreter(context)),实际情况,客户输入的都是(4+8-2)这样的式子,所以,接下来写的就是解析的输入式子然后自动构建语法树,然后计算结果.
public class Context {
private Map<Expression, Integer> map = new HashMap<>();
public void add(Expression s, Integer value){
map.put(s, value);
}
public Integer lookup(Expression s){
return map.get(s);
}
//构建语法树的主要方法
public static Expression build(String str) {
//主要利用栈来实现
Stack<Expression> objects = new Stack<>();
for (int i = 0; i < str.length(); i++){
char c = str.charAt(i);
//遇到运算符号+号时候
if (c == '+'){
//先出栈
Expression pop = objects.pop();
//将运算结果入栈
objects.push(new PlusOperation(pop, new TerminalExpression(String.valueOf(str.charAt(++i)))));
} else if (c == '-'){
//遇到减号类似加号
Expression pop = objects.pop();
objects.push(new MinusOperation(pop, new TerminalExpression(String.valueOf(str.charAt(++i)))));
} else {
//遇到非终结符直接入栈(基本就是第一个数字的情况)
objects.push(new TerminalExpression(String.valueOf(str.charAt(i))));
}
}
//把最后的栈顶元素返回
return objects.pop();
}
}
public class TerminalExpression implements Expression {
String variable;
public TerminalExpression(String variable){
this.variable = variable;
}
@Override
public int interpreter(Context context) {
//因为要兼容之前的版本
Integer lookup = context.lookup(this);
if (lookup == null)
//若在map中能找到对应的数则返回
return Integer.valueOf(variable);
//找不到则直接返回(认为输入的就是数字)
return lookup;
}
}
public class Test {
public static void main(String[] args) {
Context context = new Context();
TerminalExpression a = new TerminalExpression("a");
TerminalExpression b = new TerminalExpression("b");
TerminalExpression c = new TerminalExpression("c");
String str = "4+8-2+9+9-8";
Expression build = Context.build(str);
System.out.println("4+8-2+9+9-8=" + build.interpreter(context));
context.add(a, 4);
context.add(b, 8);
context.add(c, 2);
System.out.println(new MinusOperation(new PlusOperation(a,b), c).interpreter(context));
}
}
解释器模式总结
解释器模式为自定义语言的设计和实现提供了一种解决方案,它用于定义一组文法规则并通过这组文法规则来解释语言中的句子。虽然解释器模式的使用频率不是特别高,但是它在正则表达式、XML文档解释等领域还是得到了广泛使用。
主要优点
- 易于改变和扩展文法。由于在解释器模式中使用类来表示语言的文法规则,因此可以通过继承等机制来改变或扩展文法。
- 每一条文法规则都可以表示为一个类,因此可以方便地实现一个简单的语言。
- 实现文法较为容易。在抽象语法树中每一个表达式节点类的实现方式都是相似的,这些类的代码编写都不会特别复杂,还可以通过一些工具自动生成节点类代码。
- 增加新的解释表达式较为方便。如果用户需要增加新的解释表达式只需要对应增加一个新的终结符表达式或非终结符表达式类,原有表达式类代码无须修改,符合"开闭原则"。
主要缺点
- 对于复杂文法难以维护。在解释器模式中,每一条规则至少需要定义一个类,因此如果一个语言包含太多文法规则,类的个数将会急剧增加,导致系统难以管理和维护,此时可以考虑使用语法分析程序等方式来取代解释器模式。
- 执行效率较低。由于在解释器模式中使用了大量的循环和递归调用,因此在解释较为复杂的句子时其速度很慢,而且代码的调试过程也比较麻烦。
适用场景
- 可以将一个需要解释执行的语言中的句子表示为一个抽象语法树。
- 一些重复出现的问题可以用一种简单的语言来进行表达。
- 一个语言的文法较为简单。
- 对执行效率要求不高。
解释器模式的典型应用
Spring EL表达式中的解释器模式
在下面的类图中,Expression是一个接口,相当于我们解释器模式中的非终结符表达式,而ExpressionParser相当于终结符表达式。根据不同的Parser对象,返回不同的Expression对象

Expression接口:
//抽象的非终结符表达式
public interface Expression {
Object getValue() throws EvaluationException;
Object getValue(Object rootObject) throws EvaluationException;
}
SpelExpression类:
//具体的非终结符表达式
public class SpelExpression implements Expression {
@Override
public Object getValue() throws EvaluationException {
Object result;
if (this.compiledAst != null) {
try {
TypedValue contextRoot = evaluationContext == null ? null : evaluationContext.getRootObject();
return this.compiledAst.getValue(contextRoot == null ? null : contextRoot.getValue(), evaluationContext);
}
catch (Throwable ex) {
// If running in mixed mode, revert to interpreted
if (this.configuration.getCompilerMode() == SpelCompilerMode.MIXED) {
this.interpretedCount = 0;
this.compiledAst = null;
}
else {
// Running in SpelCompilerMode.immediate mode - propagate exception to caller
throw new SpelEvaluationException(ex, SpelMessage.EXCEPTION_RUNNING_COMPILED_EXPRESSION);
}
}
}
ExpressionState expressionState = new ExpressionState(getEvaluationContext(), this.configuration);
result = this.ast.getValue(expressionState);
checkCompile(expressionState);
return result;
}
}
CompositeStringExpression:
//具体的非终结符表达式
public class CompositeStringExpression implements Expression {
@Override
public String getValue() throws EvaluationException {
StringBuilder sb = new StringBuilder();
for (Expression expression : this.expressions) {
String value = expression.getValue(String.class);
if (value != null) {
sb.append(value);
}
}
return sb.toString();
}
}
ExpressionParser接口:
public interface ExpressionParser {
//解析表达式
Expression parseExpression(String expressionString) throws ParseException;
Expression parseExpression(String expressionString, ParserContext context) throws ParseException;
}
TemplateAwareExpressionParser类:
public abstract class TemplateAwareExpressionParser implements ExpressionParser {
@Override
public Expression parseExpression(String expressionString) throws ParseException {
return parseExpression(expressionString, NON_TEMPLATE_PARSER_CONTEXT);
}
//根据不同的parser返回不同的Expression对象
@Override
public Expression parseExpression(String expressionString, ParserContext context)
throws ParseException {
if (context == null) {
context = NON_TEMPLATE_PARSER_CONTEXT;
}
if (context.isTemplate()) {
return parseTemplate(expressionString, context);
}
else {
return doParseExpression(expressionString, context);
}
}
private Expression parseTemplate(String expressionString, ParserContext context)
throws ParseException {
if (expressionString.length() == 0) {
return new LiteralExpression("");
}
Expression[] expressions = parseExpressions(expressionString, context);
if (expressions.length == 1) {
return expressions[0];
}
else {
return new CompositeStringExpression(expressionString, expressions);
}
}
//抽象的,由子类去实现
protected abstract Expression doParseExpression(String expressionString,
ParserContext context) throws ParseException;
}
SpelExpressionParser类:
public class SpelExpressionParser extends TemplateAwareExpressionParser {
@Override
protected SpelExpression doParseExpression(String expressionString, ParserContext context) throws ParseException {
//这里返回了一个InternalSpelExpressionParser,
return new InternalSpelExpressionParser(this.configuration).doParseExpression(expressionString, context);
}
}
InternalSpelExpressionParser类:
class InternalSpelExpressionParser extends TemplateAwareExpressionParser {
@Override
protected SpelExpression doParseExpression(String expressionString, ParserContext context) throws ParseException {
try {
this.expressionString = expressionString;
Tokenizer tokenizer = new Tokenizer(expressionString);
tokenizer.process();
this.tokenStream = tokenizer.getTokens();
this.tokenStreamLength = this.tokenStream.size();
this.tokenStreamPointer = 0;
this.constructedNodes.clear();
SpelNodeImpl ast = eatExpression();
if (moreTokens()) {
throw new SpelParseException(peekToken().startPos, SpelMessage.MORE_INPUT, toString(nextToken()));
}
Assert.isTrue(this.constructedNodes.isEmpty());
return new SpelExpression(expressionString, ast, this.configuration);
}
catch (InternalParseException ex) {
throw ex.getCause();
}
}
}
参考文章
解释器模式
设计模式(二十)解释器模式
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注靠谱客的更多内容!
最后
以上就是轻松煎饼最近收集整理的关于Java设计模式之java解释器模式详解的全部内容,更多相关Java设计模式之java解释器模式详解内容请搜索靠谱客的其他文章。








发表评论 取消回复