背景
最近好几个项目在运行过程中客户都提出文件上传大小的限制能否设置的大一些,用户经常需要上传好几个G的资料文件,如图纸,视频等,并且需要在上传大文件过程中进行优化实时展现进度条,进行技术评估后针对框架文件上传进行扩展升级,扩展接口支持大文件分片上传处理,减少服务器瞬时的内存压力,同一个文件上传失败后可以从成功上传分片位置进行断点续传,文件上传成功后再次上传无需等待达到秒传的效果,优化用户交互体验,具体的实现流程如下图所示
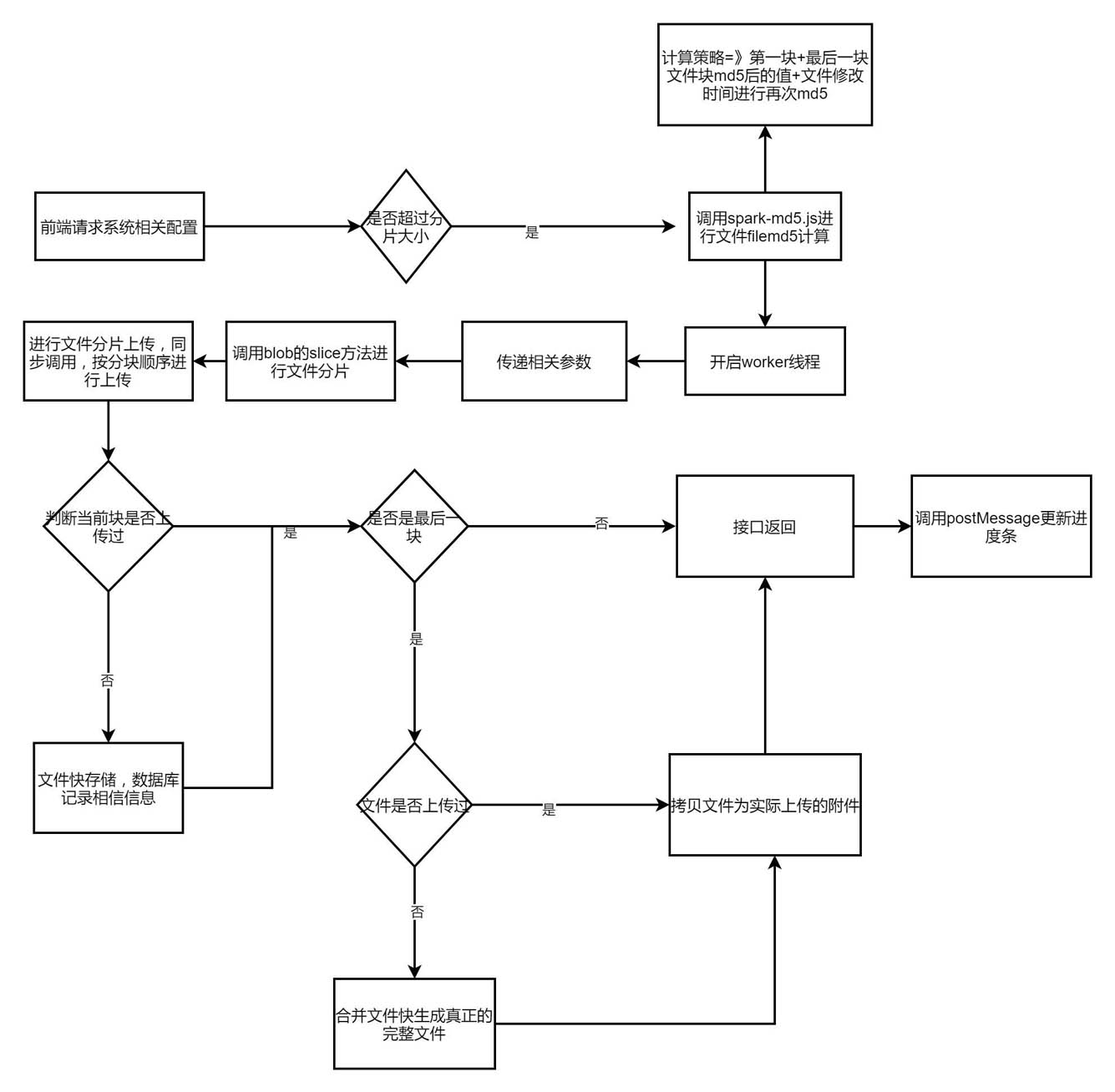
文件MD5计算
对于文件md5的计算我们使用spark-md5第三方库,大文件我们可以分片分别计算再合并节省时间,但是经测试1G文件计算MD5需要20s左右的时间,所以经过优化我们抽取文件部分特征信息(文件第一片+文件最后一片+文件修改时间),来保证文件的相对唯一性,只需要2s左右,大大提高前端计算效率,对于前端文件内容块的读取我们需要使用html5的api中fileReader.readAsArrayBuffer方法,因为是异步触发,封装的方法提供一个回调函数进行使用
createSimpleFileMD5(file, chunkSize, finishCaculate) {
var fileReader = new FileReader();
var blobSlice = File.prototype.mozSlice || File.prototype.webkitSlice || File.prototype.slice;
var chunks = Math.ceil(file.size / chunkSize);
var currentChunk = 0;
var spark = new SparkMD5.ArrayBuffer();
var startTime = new Date().getTime();
loadNext();
fileReader.onload = function() {
spark.append(this.result);
if (currentChunk == 0) {
currentChunk = chunks - 1;
loadNext();
} else {
var fileMD5 = hpMD5(spark.end() + file.lastModifiedDate);
finishCaculate(fileMD5)
}
};
function loadNext() {
var start = currentChunk * chunkSize;
var end = start + chunkSize >= file.size ? file.size : start + chunkSize;
fileReader.readAsArrayBuffer(blobSlice.call(file, start, end));
}
}
文件分片切割
我们通过定义好文件分片大小,使用blob对象支持的file.slice方法切割文件,分片上传请求需要同步按顺序请求,因为使用了同步请求,前端ui会阻塞无法点击,需要开启worker线程进行操作,完成后通过postMessage方法传递消息给主页面通知ui进度条的更新,需要注意的是,worker线程方法不支持window对象,所以尽量不要使用第三方库,使用原生的XMLHttpRequest对象发起请求,需要的参数通过onmessage方法传递获取
页面upload请求方法如下
upload() {
var file = document.getElementById("file").files[0];
if (!file) {
alert("请选择需要上传的文件");
return;
}
if (file.size < pageData.chunkSize) {
alert("选择的文件请大于" + pageData.chunkSize / 1024 / 1024 + "M")
}
var filesize = file.size;
var filename = file.name;
pageData.chunkCount = Math.ceil(filesize / pageData.chunkSize);
this.createSimpleFileMD5(file, pageData.chunkSize, function(fileMD5) {
console.log("计算文件MD:" + fileMD5);
pageData.showProgress = true;
var worker = new Worker('worker.js');
var param = {
token: GetTokenID(),
uploadUrl: uploadUrl,
filename: filename,
filesize: filesize,
fileMD5: fileMD5,
groupguid: pageData.groupguid1,
grouptype: pageData.grouptype1,
chunkCount: pageData.chunkCount,
chunkSize: pageData.chunkSize,
file: file
}
worker.onmessage = function(event) {
var workresult = event.data;
if (workresult.code == 0) {
pageData.percent = workresult.percent;
if (workresult.percent == 100) {
pageData.showProgress = false;
worker.terminate();
}
} else {
pageData.showProgress = false;
worker.terminate();
}
}
worker.postMessage(param);
})
}
worker.js执行方法如下
function FormAjax_Sync(token, data, url, success) {
var xmlHttp = new XMLHttpRequest();
xmlHttp.open("post", url, false);
xmlHttp.setRequestHeader("token", token);
xmlHttp.onreadystatechange = function() {
if (xmlHttp.status == 200) {
var result = JSON.parse(this.responseText);
var status = this.status
success(result, status);
}
};
xmlHttp.send(data);
}
onmessage = function(evt) {
var data = evt.data;
console.log(data)
//传递的参数
var token = data.token
var uploadUrl = data.uploadUrl
var filename = data.filename
var fileMD5 = data.fileMD5
var groupguid = data.groupguid
var grouptype = data.grouptype
var chunkCount = data.chunkCount
var chunkSize = data.chunkSize
var filesize = data.filesize
var filename = data.filename
var file = data.file
var start = 0;
var end;
var index = 0;
var startTime = new Date().getTime();
while (start < filesize) {
end = start + chunkSize;
if (end > filesize) {
end = filesize;
}
var chunk = file.slice(start, end); //切割文件
var formData = new FormData();
formData.append("file", chunk, filename);
formData.append("fileMD5", fileMD5);
formData.append("chunkCount", chunkCount)
formData.append("chunkIndex", index);
formData.append("chunkSize", end - start);
formData.append("groupguid", groupguid);
formData.append("grouptype", grouptype);
//上传文件
FormAjax_Sync(token, formData, uploadUrl, function(result, status) {
var code = 0;
var percent = 0;
if (result.code == 0) {
console.log("分片共" + chunkCount + "个" + ",已成功上传第" + index + "个")
percent = parseInt((parseInt(formData.get("chunkIndex")) + 1) * 100 / chunkCount);
} else {
filesize = -1;
code = -1
console.log("分片第" + index + "个上传失败")
}
self.postMessage({ code: code, percent: percent });
})
start = end;
index++;
}
console.log("上传分片总时间:" + (new Date().getTime() - startTime));
console.log("分片完成");
}
文件分片接收
前端文件分片处理完毕后,接下来我们详细介绍下后端文件接受处理的方案,分片处理需要支持用户随时中断上传与文件重复上传,我们新建表f_attachchunk来记录文件分片的详细信息,表结构设计如下
CREATE TABLE `f_attachchunk` ( `ID` int(11) NOT NULL AUTO_INCREMENT, `ChunkGuid` varchar(50) NOT NULL, `FileMD5` varchar(100) DEFAULT NULL, `FileName` varchar(200) DEFAULT NULL, `ChunkSize` int(11) DEFAULT NULL, `ChunkCount` int(11) DEFAULT NULL, `ChunkIndex` int(11) DEFAULT NULL, `ChunkFilePath` varchar(500) DEFAULT NULL, `UploadUserGuid` varchar(50) DEFAULT NULL, `UploadUserName` varchar(100) DEFAULT NULL, `UploadDate` datetime DEFAULT NULL, `UploadOSSID` varchar(200) DEFAULT NULL, `UploadOSSChunkInfo` varchar(1000) DEFAULT NULL, `ChunkType` varchar(50) DEFAULT NULL, `MergeStatus` int(11) DEFAULT NULL, PRIMARY KEY (`ID`) ) ENGINE=InnoDB AUTO_INCREMENT=237 DEFAULT CHARSET=utf8mb4;
- FileMD5:文件MD5唯一标识文件
- FileName:文件名称
- ChunkSize:分片大小
- ChunkCount:分片总数量
- ChunkIndex:分片对应序号
- ChunkFilePath:分片存储路径(本地存储文件方案使用)
- UploadUserGuid:上传人主键
- UploadUserName:上传人姓名
- UploadDate:上传人日期
- UploadOSSID:分片上传批次ID(云存储方案使用)
- UploadOSSChunkInfo:分片上传单片信息(云存储方案使用)
- ChunkType:分片存储方式(本地存储,阿里云,华为云,Minio标识)
- MergeStatus:分片合并状态(未合并,已合并)
文件分片存储后端一共分为三步,检查分片=》保存分片=》合并分片,我们这里先以本地文件存储为例讲解,云存储思路一致,后续会提供对应使用的api方法
检查分片
检查分片以数据库文件分片记录的FIleMD5与ChunkIndex组合来确定分片的唯一性,因为本地分片temp文件是作为临时文件存储,可能会出现手动清除施放磁盘空间的问题,所以数据库存在记录我们还需要对应的检查实际文件情况
boolean existChunk = false;
AttachChunkDO dbChunk = attachChunkService.checkExistChunk(fileMD5, chunkIndex, "Local");
if (dbChunk != null) {
File chunkFile = new File(dbChunk.getChunkFilePath());
if (chunkFile.exists()) {
if (chunkFile.length() == chunkSize) {
existChunk = true;
} else {
//删除数据库记录
attachChunkService.delete(dbChunk.getChunkGuid());
}
} else {
//删除数据库记录
attachChunkService.delete(dbChunk.getChunkGuid());
}
}
保存分片
保存分片分为两块,文件存储到本地,成功后数据库插入对应分片信息
//获取配置中附件上传文件夹
String filePath = frameConfig.getAttachChunkPath() + "/" + fileMD5 + "/";
//根据附件guid创建文件夹
File targetFile = new File(filePath);
if (!targetFile.exists()) {
targetFile.mkdirs();
}
if (!existChunk) {
//保存文件到文件夹
String chunkFileName = fileMD5 + "-" + chunkIndex + ".temp";
FileUtil.uploadFile(FileUtil.convertStreamToByte(fileContent), filePath, chunkFileName);
//插入chunk表
AttachChunkDO attachChunkDO = new AttachChunkDO(fileMD5, fileName, chunkSize, chunkCount, chunkIndex, filePath + chunkFileName, "Local");
attachChunkService.insert(attachChunkDO);
}
合并分片
在上传分片方法中,如果当前分片是最后一片,上传完毕后进行文件合并工作,同时进行数据库合并状态的更新,下一次同一个文件上传时我们可以直接拷贝之前合并过的文件作为新附件,减少合并这一步骤的I/O操作,合并文件我们采用BufferedOutputStream与BufferedInputStream两个对象,固定缓冲区大小
if (chunkIndex == chunkCount - 1) {
//合并文件
String merageFileFolder = frameConfig.getAttachPath() + groupType + "/" + attachGuid;
File attachFolder = new File(merageFileFolder);
if (!attachFolder.exists()) {
attachFolder.mkdirs();
}
String merageFilePath = merageFileFolder + "/" + fileName;
merageFile(fileMD5, merageFilePath);
attachChunkService.updateMergeStatusToFinish(fileMD5);
//插入到附件库
//设置附件唯一guid
attachGuid = CommonUtil.getNewGuid();
attachmentDO.setAttguid(attachGuid);
attachmentService.insert(attachmentDO);
}
public void merageFile(String fileMD5, String targetFilePath) throws Exception {
String merageFilePath = frameConfig.getAttachChunkPath()+"/"+fileMD5+"/"+fileMD5+".temp";
File merageFile = new File(merageFilePath);
if(!merageFile.exists()){
BufferedOutputStream destOutputStream = new BufferedOutputStream(new FileOutputStream(merageFilePath));
List<AttachChunkDO> attachChunkDOList = attachChunkService.selectListByFileMD5(fileMD5, "Local");
for (AttachChunkDO attachChunkDO : attachChunkDOList) {
File file = new File(attachChunkDO.getChunkFilePath());
byte[] fileBuffer = new byte[1024 * 1024 * 5];//文件读写缓存
int readBytesLength = 0; //每次读取字节数
BufferedInputStream sourceInputStream = new BufferedInputStream(new FileInputStream(file));
while ((readBytesLength = sourceInputStream.read(fileBuffer)) != -1) {
destOutputStream.write(fileBuffer, 0, readBytesLength);
}
sourceInputStream.close();
}
destOutputStream.flush();
destOutputStream.close();
}
FileUtil.copyFile(merageFilePath,targetFilePath);
}
云文件分片上传
云文件上传与本地文件上传的区别就是,分片文件直接上传到云端,再调用云存储api进行文件合并与文件拷贝,数据库相关记录与检查差异不大
阿里云OSS
上传分片前需要生成该文件的分片上传组标识uploadid
public String getUplaodOSSID(String key){
key = "chunk/" + key + "/" + key;
TenantParams.attach appConfig = getAttach();
OSSClient ossClient = InitOSS(appConfig);
String bucketName = appConfig.getBucketname_auth();
InitiateMultipartUploadRequest request = new InitiateMultipartUploadRequest(bucketName, key);
InitiateMultipartUploadResult upresult = ossClient.initiateMultipartUpload(request);
String uploadId = upresult.getUploadId();
ossClient.shutdown();
return uploadId;
}
上传分片时需要指定uploadid,同时我们要将返回的分片信息PartETag序列化保存数据库,用于后续的文件合并
public String uploadChunk(InputStream stream,String key, int chunkIndex, int chunkSize, String uploadId){
key = "chunk/" + key + "/" + key;
String result = "";
try{
TenantParams.attach appConfig = getAttach();
OSSClient ossClient = InitOSS(appConfig);
String bucketName = appConfig.getBucketname_auth();
UploadPartRequest uploadPartRequest = new UploadPartRequest();
uploadPartRequest.setBucketName(bucketName);
uploadPartRequest.setKey(key);
uploadPartRequest.setUploadId(uploadId);
uploadPartRequest.setInputStream(stream);
// 设置分片大小。除了最后一个分片没有大小限制,其他的分片最小为100 KB。
uploadPartRequest.setPartSize(chunkSize);
// 设置分片号。每一个上传的分片都有一个分片号,取值范围是1~10000,如果超出此范围,OSS将返回InvalidArgument错误码。
uploadPartRequest.setPartNumber(chunkIndex+1);
// 每个分片不需要按顺序上传,甚至可以在不同客户端上传,OSS会按照分片号排序组成完整的文件。
UploadPartResult uploadPartResult = ossClient.uploadPart(uploadPartRequest);
PartETag partETag = uploadPartResult.getPartETag();
result = JSON.toJSONString(partETag);
ossClient.shutdown();
}catch (Exception e){
logger.error("OSS上传文件Chunk失败:" + e.getMessage());
}
return result;
}
合并分片时通过传递保存分片的PartETag对象数组进行操作,为了附件独立唯一性我们不直接使用合并后的文件,通过api进行文件拷贝副本使用
public boolean merageFile(String uploadId, List<PartETag> chunkInfoList,String key,AttachmentDO attachmentDO,boolean checkMerge){
key = "chunk/" + key + "/" + key;
boolean result = true;
try{
TenantParams.attach appConfig = getAttach();
OSSClient ossClient = InitOSS(appConfig);
String bucketName = appConfig.getBucketname_auth();
if(!checkMerge){
CompleteMultipartUploadRequest completeMultipartUploadRequest = new CompleteMultipartUploadRequest(bucketName, key, uploadId, chunkInfoList);
CompleteMultipartUploadResult completeMultipartUploadResult = ossClient.completeMultipartUpload(completeMultipartUploadRequest);
}
String attachKey = getKey(attachmentDO);
ossClient.copyObject(bucketName,key,bucketName,attachKey);
ossClient.shutdown();
}catch (Exception e){
e.printStackTrace();
logger.error("OSS合并文件失败:" + e.getMessage());
result = false;
}
return result;
}
华为云OBS
华为云api与阿里云api大致相同,只有个别参数名称不同,直接上代码
public String getUplaodOSSID(String key) throws Exception {
key = "chunk/" + key + "/" + key;
TenantParams.attach appConfig = getAttach();
ObsClient obsClient = InitOBS(appConfig);
String bucketName = appConfig.getBucketname_auth();
InitiateMultipartUploadRequest request = new InitiateMultipartUploadRequest(bucketName, key);
InitiateMultipartUploadResult result = obsClient.initiateMultipartUpload(request);
String uploadId = result.getUploadId();
obsClient.close();
return uploadId;
}
public String uploadChunk(InputStream stream, String key, int chunkIndex, int chunkSize, String uploadId) {
key = "chunk/" + key + "/" + key;
String result = "";
try {
TenantParams.attach appConfig = getAttach();
ObsClient obsClient = InitOBS(appConfig);
String bucketName = appConfig.getBucketname_auth();
UploadPartRequest uploadPartRequest = new UploadPartRequest();
uploadPartRequest.setBucketName(bucketName);
uploadPartRequest.setUploadId(uploadId);
uploadPartRequest.setObjectKey(key);
uploadPartRequest.setInput(stream);
uploadPartRequest.setOffset(chunkIndex * chunkSize);
// 设置分片大小。除了最后一个分片没有大小限制,其他的分片最小为100 KB。
uploadPartRequest.setPartSize((long) chunkSize);
// 设置分片号。每一个上传的分片都有一个分片号,取值范围是1~10000,如果超出此范围,OSS将返回InvalidArgument错误码。
uploadPartRequest.setPartNumber(chunkIndex + 1);
// 每个分片不需要按顺序上传,甚至可以在不同客户端上传,OSS会按照分片号排序组成完整的文件。
UploadPartResult uploadPartResult = obsClient.uploadPart(uploadPartRequest);
PartEtag partETag = new PartEtag(uploadPartResult.getEtag(), uploadPartResult.getPartNumber());
result = JSON.toJSONString(partETag);
obsClient.close();
} catch (Exception e) {
e.printStackTrace();
logger.error("OBS上传文件Chunk:" + e.getMessage());
}
return result;
}
public boolean merageFile(String uploadId, List<PartEtag> chunkInfoList, String key, AttachmentDO attachmentDO, boolean checkMerge) {
key = "chunk/" + key + "/" + key;
boolean result = true;
try {
TenantParams.attach appConfig = getAttach();
ObsClient obsClient = InitOBS(appConfig);
String bucketName = appConfig.getBucketname_auth();
if (!checkMerge) {
CompleteMultipartUploadRequest request = new CompleteMultipartUploadRequest(bucketName, key, uploadId, chunkInfoList);
obsClient.completeMultipartUpload(request);
}
String attachKey = getKey(attachmentDO);
obsClient.copyObject(bucketName, key, bucketName, attachKey);
obsClient.close();
} catch (Exception e) {
e.printStackTrace();
logger.error("OBS合并文件失败:" + e.getMessage());
result = false;
}
return result;
}
Minio
文件存储Minio应用比较广泛,框架也同时支持了自己独立部署的Minio文件存储系统,Minio没有对应的分片上传api支持,我们可以在上传完分片文件后,使用composeObject方法进行文件的合并
public boolean uploadChunk(InputStream stream, String key, int chunkIndex) {
boolean result = true;
try {
MinioClient minioClient = InitMinio();
String bucketName = frameConfig.getMinio_bucknetname();
PutObjectOptions option = new PutObjectOptions(stream.available(), -1);
key = "chunk/" + key + "/" + key;
minioClient.putObject(bucketName, key + "-" + chunkIndex, stream, option);
} catch (Exception e) {
logger.error("Minio上传Chunk文件失败:" + e.getMessage());
result = false;
}
return result;
}
public boolean merageFile(String key, int chunkCount, AttachmentDO attachmentDO, boolean checkMerge) {
boolean result = true;
try {
MinioClient minioClient = InitMinio();
String bucketName = frameConfig.getMinio_bucknetname();
key = "chunk/" + key + "/" + key;
if (!checkMerge) {
List<ComposeSource> sourceObjectList = new ArrayList<ComposeSource>();
for (int i = 0; i < chunkCount; i++) {
ComposeSource composeSource = ComposeSource.builder().bucket(bucketName).object(key + "-" + i).build();
sourceObjectList.add(composeSource);
}
minioClient.composeObject(ComposeObjectArgs.builder().bucket(bucketName).object(key).sources(sourceObjectList).build());
}
String attachKey = getKey(attachmentDO);
minioClient.copyObject(
CopyObjectArgs.builder()
.bucket(bucketName)
.object(attachKey)
.source(
CopySource.builder()
.bucket(bucketName)
.object(key)
.build())
.build());
} catch (Exception e) {
logger.error("Minio合并文件失败:" + e.getMessage());
result = false;
}
return result;
}
到此这篇关于SpringBoot文件分片上传的示例代码的文章就介绍到这了,更多相关SpringBoot文件分片上传内容请搜索靠谱客以前的文章或继续浏览下面的相关文章希望大家以后多多支持靠谱客!
最后
以上就是文艺大神最近收集整理的关于SpringBoot文件分片上传的示例代码的全部内容,更多相关SpringBoot文件分片上传内容请搜索靠谱客的其他文章。








发表评论 取消回复