Set接口
set接口等同于Collection接口,不过其方法的行为有更严谨的定义。set的add方法不允许增加重复的元素。要适当地定义set的equals方法:只要俩个set包含同样的元素就认为它们是相同的,而不要求这些元素有相同的顺序。hashCode方法的定义要保证包含相同元素的俩个set会得到相同的散列码。
——Java核心技术 卷一
public interface Set<E> extends Collection<E> {
//一些方法
}
set不允许包含相同的元素,如果调用 add 方法来添加俩个相同的元素,那么在添加第二个元素时就会返回 false。这个接口有俩个比较常用的实现类:HashSet,TreeSet。HashSet是一个没有重复元素的一个无序集合,而TreeSet是一个有序集。
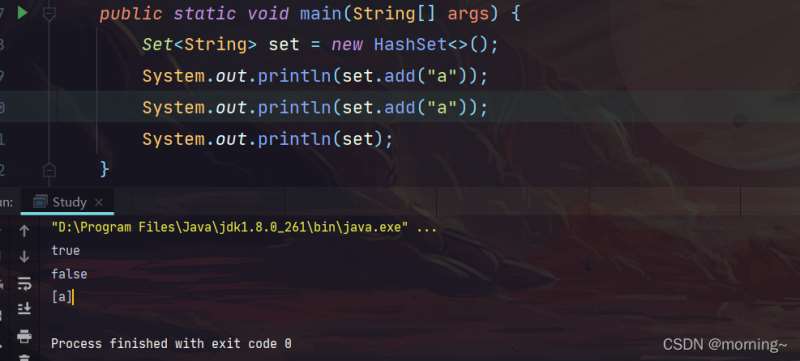
HashSet
HashSet 使用数组和链表来实现散列表,不同 hashcode 的值存放在不同数组下标的位置,相同 hashcode 的值存放在相同数组下标的链表上的不同位置上。
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable{
//一些方法
}
HashSet类中有四个构造方法:
public HashSet() //构造一个空的散列集 public HashSet(Collection<? extends E> c) //构造一个散列集,并将集合中的所有元素添加到这个散列集中 public HashSet(int initialCapacity, float loadFactor) //构造一个有指定容量和装填因子的空散列集 public HashSet(int initialCapacity) //构造一个指定容量的空散列集
现在让我们来看一下add方法的源码:
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
可以看到这里面是调用了 map.put() 方法,map 在HashSet中的声明如下:
private transient HashMap<E,Object> map;
由此可见HashSet和HashMap有很紧密的联系。
HashSet的底层是用一个HashMap来实现的。HashSet再添加时如何扩容问题在下文HashMap中再详细介绍。
散列表
Java中,散列表用链表,数组实现。也就可以这么理解,在数组不同索引位置上放的是一个链表,要想查找表中对象的位置,要先计算它的散列码,然后与数组长度取余,所得到的结果就是保存这个元素的索引。在保存对象时,通过这个计算方式得到了索引位置,如果这个位置没有其他元素,那就将元素直接插入到该位置就好了,如果这个位置已经有其他元素了,那么需要将这个新的对象与已有的对象进行比较,查看这个对象是否已经存在。如果不存在就在链表的末尾存储这个对象。
TreeSet
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable{
//一些方法
}
树集是一个有序集合,可以以任意顺序将元素插入集合中。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LmJuZcAV-1639916281542)(C:UsersDELLAppDataRoamingTyporatypora-user-images1639904244362.png)]](https://www.shuijiaxian.com/files_image/2022051004/2021122108461218.png)
TreeSet排序是用一个红黑树完成的,每次将一个元素添加到树中时,都会将其放置到正确的排序位置上。由于树集时有序的,所以将一个元素添加到树中要比添加到散列表中慢,所以如果不需要数据是有序的,就没必要为了排序而影响性能。
它也有四个构造函数:
public TreeSet() //构造一个空的树集,排序方式是自然排序 public TreeSet(Comparator<? super E> comparator) //构造一个空树集,指定比较器,就是排序方式 public TreeSet(Collection<? extends E> c) //构造一个树集,并将集合中的所有元素添加到这个树集中 public TreeSet(SortedSet<E> s) //构造一个树集,并增加一个集合或者有序集中的所有元素,如果是有序集的话,要使用同样的顺序。
上面提到的自然排序是用元素的 compareTo() 方法来比较元素的大小关系(比如你存入v,b,a,就会输出a,b,v),然后将集合元素按照升序排列。
Map接口
集是一个集合,允许你快速的查找现有的元素。但是要查找一个元素,需要有所要查找的那个元素的准确副本。这不是一种常见的查找方式。通常,我们知道某些关键信息,希望查找与之关联的元素。映射(map)数据结构就是为此设计的。映射用来存放键 / 值对。如果提供了键,就可以查找到值。
——Java核心技术
public interface Map<K,V> {
int size(); //返回映射中的元素数
V get(Object key); //返回指定键对应的值
V remove(Object key); //从映射中删除指定键对应的元素。
}
Java为映射提供了俩个通用的实现:HashMap和TreeMap
HashMap
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
}
实现了Map接口,存储的内容是键值对(key-value)映射,将键进行散列,散列或比较函数只应用于键,与键相关的值不进行散列或比较。
HashMap底层的结构是,散列表(数组和链表)和红黑树
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oi9ZErOs-1639916281543)(C:UsersDELLAppDataRoamingTyporatypora-user-images1639910918514.png)]](https://www.shuijiaxian.com/files_image/2022051004/2021122108461219.png)
我用反射的方式输出了这个map的容量,可以看到如果使用无参的构造方法,那么map的容量默认为16。我们也可以通过传参的方式,来指定它的容量,值的一提的是,你指定的容量,一定要为 2 的幂次方,且要小于 int 范围内最大的 2 的幂次方数(1073741824)。
//指定容量 HashMap<String,String> map = new HashMap<String, String>(8);
这个构造方法还是调用了下面的这个构造方法,只是把默认的负载因子值传进去了:
put方法,直接看源码:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
调用put方法后,会根据键值来计算一个值(位置),然后调用putVal来存放元素。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//hash表为空或者长度为0的话,创建hash表
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;//resize()HashMap扩容的方法
if ((p = tab[i = (n - 1) & hash]) == null)
//如果位置上没有元素,就加进去,成为链表的头结点
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//如果这个值的类型为树结构的话,就直接添加到树中,不会判断是否超过8
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//binCount链表的长度
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
//如果链表不为空,就往下一个节点添加
p.next = newNode(hash, key, value, null);
//如果这个链表的长度大于8,就会转为红黑树存储
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//如果该键已经有映射关系的话,用这次的值覆盖掉之前的值
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//如果里面的元素超过 threshold 的话就扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
通过代码中的注释,相信你已经初步了解了 put 方法,总的来说就是添加时首先是用 k 通过哈希函数计算位置,位置上如果没有元素添加在链表的头结点,如果有插入到链表的下一个节点,当链表的长度为大于等于8时,转为红黑树存储,如果该键已经有映射关系的话,用这次的值覆盖掉之前的值,最后判断要不要扩容。如果要扩容,会扩容为原来容量的2倍。这样效率会高一些,也可以减少哈希冲突。
负载因子
上文中我们提到了负载因子,那么负载因子是什么呢?
负载因子也叫装填因子,是一个0.0~1.0之间的数,确定散列表填充的百分比,当大于这个百分比时,散列表进行再散列。在map中,也就是说,当put的元素数量超过一定值的时候,就会扩容,这个值就是负载因子*容量。
HashMap中的负载因子默认是0.75:
static final float DEFAULT_LOAD_FACTOR = 0.75f;
就是说如果map中的元素超过容量的3/4就要进行扩容。
那么为什么这里要默认为0.75呢?这了也是规定了一个相对合理的值,如果为 1 的话效率太低,满了之后才扩容;如果为0.5的话,浪费空间。所以选了一个居中的值。
TreeMap
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable{
}
它没有实现Map接口是因为AbstractMap实现了Map接口,TreeMap是一个能比较元素大小的Map集合,可以对 key 值进行大小排序。其中,可以使用自然顺序,也可以使用集合中自定义的比较器来进行排序。底层是红黑树结构。
TreeMap中运用到的红黑树结构,是数据结构的一种,相关知识太多,大家感兴趣的话可以在网上查阅资料(博主对树结构的理解不是很透彻
最后
以上就是闪闪红酒最近收集整理的关于Java集合框架之Set和Map详解的全部内容,更多相关Java集合框架之Set和Map详解内容请搜索靠谱客的其他文章。








发表评论 取消回复