一. 假设需求场景
在我们开发的过程中,经常出现两个对象存在一对多或多对一的关系。如何在程序在表明这两个对象的关系,以及如何利用这种关系优雅地使用它们。
其实,在javax.persistence包下有这样两个注解——@OneTomany和@ManyToOne,可以为我们所用。
现在,我们假设需要开发一个校园管理系统,管理各大高校的学生。这是一种典型的一对多场景,学校和学生的关系。这里,我们涉及简单的级联保存,查询,删除。
二. 代码实现
2.1 级联存储操作
Student类和School类
@Data
@Table
@Entity
@Accessors(chain = true)
public class Student {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
private String name;
@ManyToOne
@JoinColumn(name = "school_fk")
private School school;
}
Student类上面的四个注解不做解释,id主键使用自增策略。Student中有个School的实例变量school,表明学生所属的学校。@ManyToOne(多对一注解)代表在学生和学校关系中“多”的那方,学生是“多”的那方,所以在Student类里面使用@ManyToOne。
那么,@ManyToOne中One当然是指学校了,也就是School类。
@JoinColumn(name = “school_fk”)指明School类的主键id在student表中的字段名,如果此注解不存在,生成的student表如下:

@Data
@Table
@Entity
@Accessors(chain = true)
public class School {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
private String name;
@OneToMany(mappedBy="school",cascade = CascadeType.PERSIST)
private List<Student> students;
}
在School类中,维护一个类型为List的students实例变量。@OneToMany(一对多注解)代表在学生和学校关系中“一”的那方,学校是“一”的那方,所以在School类里面使用@OneToMany。
那么,@OneToMany中many当然是指学生了,也就是Student类。注意@OneToMany中有个mappedBy参数设置为school,这个值是我们在Student类中的School类型的变量名;cascade参数表示级联操作的类型,它只能是CascadeType的6种枚举类型。
有的博客经常写成cascade = CascadeType.ALL,这其实会误导大家,因为里面的级联删除会让你怀疑人生。
我们先使用CascadeType.PERSIST,表示在持久化的级联操作,也就是保存学校的时候可以一起保存学生。
StudentRepository和SchoolRepository
public interface StudentRepository extends JpaRepository<Student, Integer> {
}
public interface SchoolRepository extends JpaRepository<School, Integer> {
}
测试类
@RunWith(SpringRunner.class)
@SpringBootTest
public class MultiDateSourceApplicationTests {
@Autowired
SchoolRepository schoolRepository;
@Test
public void contextLoads() {
Student jackMa = new Student().setName("Jack Ma");
Student jackChen = new Student().setName("Jack Chen");
School school = new School().setName("湖畔大学");
List<Student> students = new ArrayList<>();
students.add(jackMa);
students.add(jackChen);
jackMa.setSchool(school);
jackChen.setSchool(school);
school.setStudents(students);
schoolRepository.save(school);
}
}
运行测试类后,数据库的表数据如下:

在程序中,我们并没有调用StudentRepository的save方法,但是我们在@OneToMany中添加了级联保存参数CascadeType.PERSIST,所以在保存学校的时候能自动保存学生, jackMa.setSchool(school);jackChen.setSchool(school);这两句肯定不能少的。
2.2 查询操作和toSting问题
上面的添加操作成功了,让我们来试试查询操作。

控制台:打印出的错误是org.hibernate.LazyInitializationException: failed to lazily initialize a collection of role: com.cauchy6317.multidatesource.cascadestudy.entity.School.students, could not initialize proxy - no Session
这是因为@OneToMany的fetch参数默认设置为FetchType.Lazy模式,即懒加载模式。
也就是说,我们查询mySchool的时候,并没有把在该学校的学生查出来。而且,School类的toString方法需要知道students,所以debug模式下mySchool变量报错。
我们把@OneToMany的fetch参数改为Fetch.EAGER,即热加载。
@OneToMany(mappedBy="school", cascade = CascadeType.PERSIST, fetch = FetchType.EAGER)
private List<Student> students;
再运行一次…

这次的错误是StackOverflowError,为什么会这样呢?堆栈溢出,也就是我们写的程序出现了死循环。可是我们都没写循环语句啊,不急,我们先看看这个mySchool数据。
我们发现mySchool里面有students,而且students里面又有school变量,变量school里面自然又有students了。由此看来,是这个死循环的导致。也就是Student和School的toString方法,循环调用彼此。
所以只需要修改其中一个的toString方法,使它的toString方法不涉及另一个类型的变量,也就是排除另一个类型的变量。lombok考虑到这点了,可以使用ToString.exclude。
在官网的ToString介绍页面中,我看到了这个有意思的小字部分。
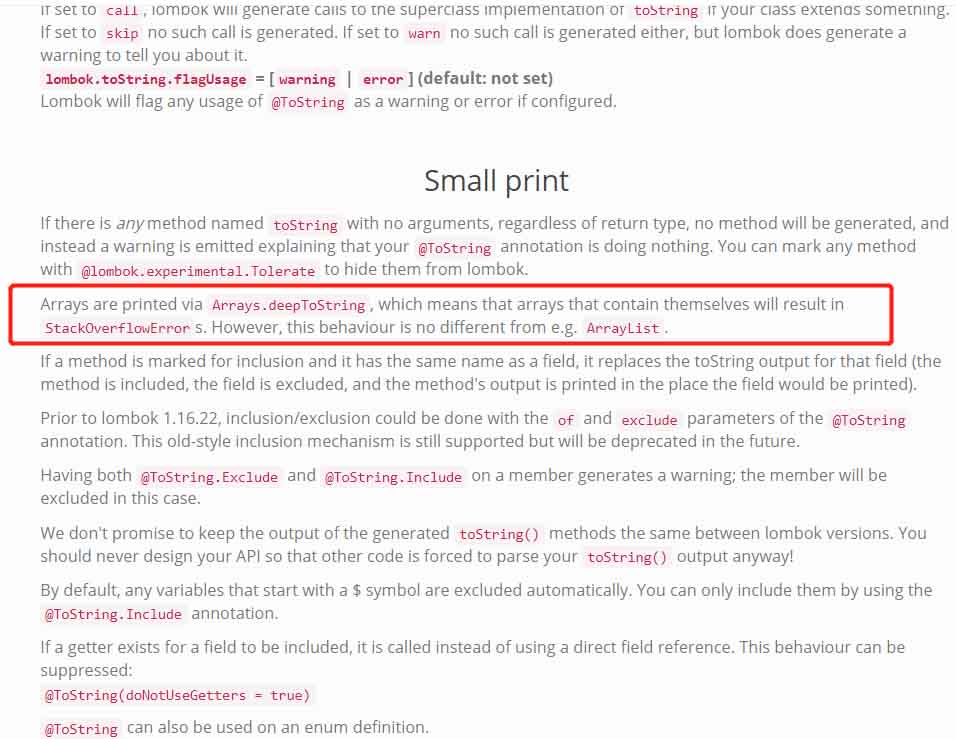
哈哈哈,这个地方已经说明了如果使用数组中包含自身,ToString方法会报StackOverflowError。
那么,我们在Student类中使用ToString.exclude,还是在School类中使用ToString.exclude呢?我们先在School类中试试。
@ToString.Exclude
@OneToMany(mappedBy="school", cascade = CascadeType.PERSIST, fetch = FetchType.EAGER)
private List<Student> students;
这次我们把学生也打印出来一个。

可以看到,mySchool的ToString方法没有将students打印出来;student的toSting方法将School打印出来了。如果在Student类的school变量上使用@ToString.EXCLUDE的话,那么mySchool就会打印出很多student来。
所以,我觉得还是在private List students;上使用@ToString.EXCLUDE较好。
2.3 级联删除
前面我们说过级联删除会让人怀疑人生,让我们用代码来感受一下。
@ToString.Exclude
@OneToMany(mappedBy="school", cascade = {CascadeType.PERSIST, CascadeType.REMOVE}, fetch = FetchType.EAGER)
private List<Student> students;
我们在School类中,使用级联删除。也就是说,当我们删除某个学校的时候,把这个学校下的所有学生删除掉!

现在查看数据库的表,可以清楚的看到。school中id为1的学校没有了,而且student中学校外键为1的学生也全部被删了。或许你会觉得这也没什么大不了的,因为学校不存在了,学校里的学生自然不存在了。好,那就让我们来见识一下级联删除的真正威力。我们如果也在Student类中使用了级联删除会怎么样?
@ManyToOne(cascade = CascadeType.REMOVE)
@JoinColumn(name = "school_fk")
private School school;
也就是说,当我们删除某个学生时,会级联删除学生所在的学校。我们用代码测试一下是不是这样。
public interface StudentRepository extends JpaRepository<Student, Integer> {
/**
* 根据姓名删除学生对象
* @param name
* @return
*/
@Transactional
Integer deleteByName(String name);
}

可以看到数据插入成功了,当我们放掉断点后。

可以看到出现了三条删除语句,我再看看数据库的学生表,发现Jack Chen也被删除了。这是因为我们在Student类和School类中都使用了级联删除,当我们删除Jack Ma的时候,级联删除了湖畔大学,当删除湖畔大学后又级联删除了所有湖畔大学的student。这就好比,你打算开除一个学生,结果把学校和学生的数据全删没了。是不是很刺激?
2.4 pom.xml
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.10</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.28</version>
</dependency>
</dependencies>
环境:springboot2.1.7+jdk1.8+mysql8.0+druid1.1.10+Springdata JPA+Lombok
以上为个人经验,希望能给大家一个参考,也希望大家多多支持靠谱客。
最后
以上就是玩命机器猫最近收集整理的关于SpringData JPA中@OneToMany和@ManyToOne的用法详解的全部内容,更多相关SpringData内容请搜索靠谱客的其他文章。








发表评论 取消回复