
研究了一段时间酷狗音乐的接口,完美破解了其vip音乐下载方式,想着能更好的追求开源,故写下此篇文章,本文仅供学习参考。虽然没什么技术含量,但都是自己一点一点码出来,一点一点抓出来的。
一、综述:
根据酷狗的搜索接口以及无损音乐下载接口,做出爬虫系统。采用flask框架,前端提取搜索关键字,后端调用爬虫系统采集数据,并将数据前端呈现;
运行环境:windows/linux python2.7
二、爬虫开发:
通过抓包的方式对酷狗客户端进行抓包,抓到两个接口:
1、搜索接口:
http://songsearch.kugou.com/song_search_v2?keyword={关键字}page=1
这个接口通过传递关键字,其返回的是一段json数据,数据包含音乐名称、歌手、专辑、总数据量等信息,当然最重要的是数据包含音乐各个品质的hash。
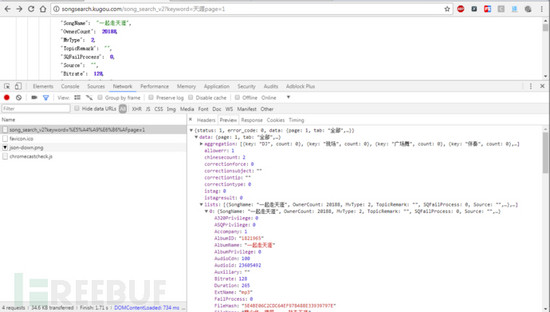
默认接口返回的数据只包含30首音乐,为了能拿到所有的数据,只需要把pagesize更改就可以,所以我提取了总数据数量,然后再次发动一次数据请求,拿到全部的数据。当然,这个总数据量也就是json中的total也是作为搜索结果的依据,如果total == 0 则判断无法搜索到数据。
搜索到数据后,我就要提取无损音乐的hash,这个hash是音乐下载的关键,无损音乐hash键名:SQFileHash,提取到无损hash(如果是32个0就表示None),我把他的名称、歌手、hash以字典形式传递给下一个模块。
代码实现:
a.请求模块(复用率高):
# coding=utf-8
import requests
import json
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/63.0.3239.132 Safari/537.36',
}
def parse(url):
ret = json.loads(requests.get(url, headers=headers, timeout=5).text)
# 返回的是已经转换过后的字典数据
return ret
if __name__ == '__main__':
parse()
b.搜索模块
# coding=utf-8
import copy
import MusicParse
def search(keyword):
search_url = 'http://songsearch.kugou.com/song_search_v2?keyword={}page=1'.format(keyword)
# 这里需要判断一下,ip与搜索字段可能会限制搜索,total进行判断
total = MusicParse.parse(search_url)['data']['total']
if total != 0:
search_total_url = search_url + '&pagesize=%d' % total
music_list = MusicParse.parse(search_total_url)['data']['lists']
item, items = {}, []
for music in music_list:
if music['SQFileHash'] != '0'*32:
item['Song'] = music['SongName'] # 歌名
item['Singer'] = music['SingerName'] # 歌手
item['Hash'] = music['SQFileHash'] # 歌曲无损hash
items.append(copy.deepcopy(item))
return items
else:
return None
if __name__ == '__main__':
search()
到这步,音乐搜索接口以及利用完了,下面就是无损音乐搜索了。
2、音乐下载接口:
# V2版系统,pc版 Music_api_1 = 'http://trackercdnbj.kugou.com/i/v2/?cmd=23&pid=1&behavior=download' # V2版系统,手机版(备用) Music_api_2 = 'http://trackercdn.kugou.com/i/v2/?appid=1005&pid=2&cmd=25&behavior=play' # 老版系统(备用) Music_api_3 = 'http://trackercdn.kugou.com/i/?cmd=4&pid=1&forceDown=0&vip=1'
我这里准备三个接口,根据酷狗系统版本不同,采用不同加密方式,酷狗音乐下载的关键就是音乐接口处提交的key的加密方式,key是由hash加密生成的,不同的酷狗版本,加密方式不同:
酷狗v2版key的生成:md5(hash +”kgcloudv2″)
酷狗老版key的生成:md5(hash +”kgcloud”)
只要将音乐的hash+key添加到api_url ,get提交过去,就能返回一段json数据,数据中就包括了音乐的下载链接,然后在提取其download_url。下面我将采用酷狗的第一个接口完成代码的实现,当然,酷狗存在地区的限制,接口有效性也带检测,如果第一个不行就换一个,你懂得!!!然后我把数据做成字典进行传递。
代码实现:
# coding=utf-8
import copy
import hashlib
import MusicParse
import MusicSearch
# V2版系统,pc版,加密方式为md5(hash +"kgcloudv2")
Music_api_1 = 'http://trackercdnbj.kugou.com/i/v2/?cmd=23&pid=1&behavior=download'
# V2版系统,手机版,加密方式为md5(hash +"kgcloudv2") (备用)
Music_api_2 = 'http://trackercdn.kugou.com/i/v2/?appid=1005&pid=2&cmd=25&behavior=play'
# 老版系统,加密方式为md5(hash +"kgcloud")(备用)
Music_api_3 = 'http://trackercdn.kugou.com/i/?cmd=4&pid=1&forceDown=0&vip=1'
def V2Md5(Hash): # 用于生成key,适用于V2版酷狗系统
return hashlib.md5((Hash + 'kgcloudv2').encode('utf-8')).hexdigest()
def Md5(Hash): # 用于老版酷狗系统
return hashlib.md5((Hash + 'kgcloud').encode('utf-8')).hexdigest()
def HighSearch(keyword):
music_list = MusicSearch.search(keyword)
if music_list is not None:
item, items = {}, []
for music in music_list:
Hash = str.lower(music['Hash'].encode('utf-8'))
key_new = V2Md5(Hash) # 生成v2系统key
try:
DownUrl = MusicParse.parse(Music_api_1 + '&hash=%s&key=%s' % (Hash, key_new))['url']
item['Song'] = music['Song'].encode('utf-8') # 歌名
item['Singer'] = music['Singer'].encode('utf-8') # 歌手
item['url'] = DownUrl
items.append(copy.deepcopy(item))
except KeyError:
pass
return items
if __name__ == '__main__':
HighSearch()
酷狗的爬虫系统就设计完毕了,下面开始使用flask框架搭建前后端了。
三、引擎搭建
这个搜索引擎是基于flask框架的,设计思路比较简单,就是前端传递post数据(keyword)传递到后端,后端拿着这个keyword传递给爬虫,爬虫把数据返回给系统,系统在前端渲染出来。
代码实现:
# coding=utf-8
import sys
from flask import Flask
from flask import request, render_template
from KgSpider import HighMusicSearch
reload(sys)
sys.setdefaultencoding('utf-8')
app = Flask(__name__)
@app.route('/', methods=['GET', 'POST'])
def search():
if request.method == 'GET':
return render_template('index.html')
elif request.method == 'POST':
keyword = request.form.get('keyword')
items = HighMusicSearch.HighSearch(keyword)
if items != None:
return render_template('list.html', list=items)
else:
return '找不到!!!不支持英文'
else:
return render_template('404.html')
if __name__ == '__main__':
app.run(debug=True)
四、调试
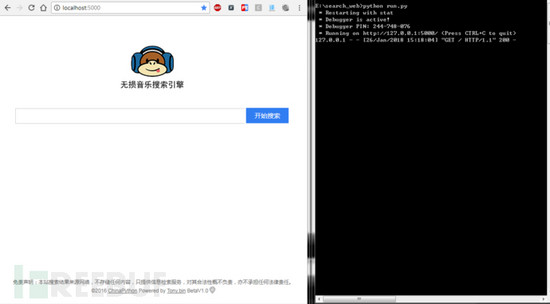
整改引擎系统,也就设计完毕,然我们试试效果:
1.启动脚本:python run.py
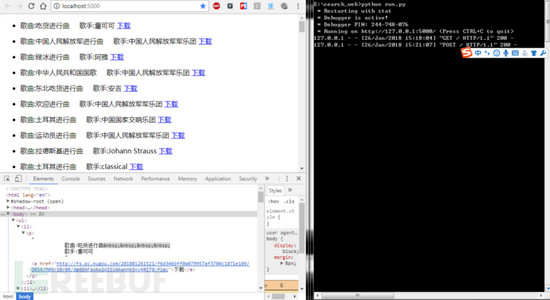
2.输入关键字进行搜索
五、总结
引擎搭建完毕,也能正常的运行了,但是这只是一个模型,完全没有考虑,多用户访问带来的压力,很容易崩溃,当然经过我的测试,发现只能搜索中文,英文完全无效,why?别问我,我也不知道!!!当然在这里我也想说一下,请尊重版权!!!虽然我是口是心非!!!!!
项目地址: 码云项目地址
总结
以上所述是小编给大家介绍的Python无损音乐搜索引擎实现代码,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对脚本之家网站的支持!
最后
以上就是快乐黄蜂最近收集整理的关于Python无损音乐搜索引擎实现代码的全部内容,更多相关Python无损音乐搜索引擎实现代码内容请搜索靠谱客的其他文章。








发表评论 取消回复