链接:https://www.zhihu.com/question/517340666
编辑:深度学习与计算机视觉
声明:仅做学术分享,侵删
作者:kinredon
https://www.zhihu.com/question/517340666/answer/2417377951
看了一圈没看到有人总结 2D Detection 方向的论文,我来更新一下
update:
Towards Robust Adaptive Object Detection under Noisy Annotations
update:
R(Det)^2: Randomized Decision Routing for Object Detection
DETR/Mixer
Omni-DETR: Omni-Supervised Object Detection with Transformers
DN-DETR: Accelerate DETR Training by Introducing Query DeNoising
AdaMixer: A Fast-Converging Query-Based Object Detector
Accelerating DETR Convergence via Semantic-Aligned Matching
DETReg: Unsupervised Pretraining with Region Priors for Object Detection
半监督/无监督/弱监督
MUM : Mix Image Tiles and UnMix Feature Tiles for Semi-Supervised Object Detection
SIOD: Single Instance Annotated Per Category Per Image for Object Detection
Scale-Equivalent Distillation for Semi-Supervised Object Detection
Domain adaptation/ Open set / Few shot
Expanding Low-Density Latent Regions for Open-Set Object Detection
Sylph: A Hypernetwork Framework for Incremental Few-shot Object Detection
Semantic-aligned Fusion Transformer for One-shot Object Detection
SIGMA: Semantic-complete Graph Matching for Domain Adaptive Object Detection
Task-specific Inconsistency Alignment for Domain Adaptive Object Detection
Few-Shot Object Detection with Fully Cross-Transformer
Interactron: Embodied Adaptive Object Detection
Label, Verify, Correct: A Simple Few Shot Object Detection Method
Multi-Granularity Alignment Domain Adaptation for Object Detection
Towards Robust Adaptive Object Detection under Noisy Annotations
传统 2D 目标检测
A Dual Weighting Label Assignment Scheme for Object Detection
Confidence Propagation Cluster: Unleash Full Potential of Object Detectors
Optimal Correction Cost for Object Detection Evaluation
Unknown-Aware Object Detection: Learning What You Don't Know from Videos in the Wild
Zoom In and Out: A Mixed-scale Triplet Network for Camouflaged Object Detection
Oriented RepPoints for Aerial Object Detection
Learning to Prompt for Open-Vocabulary Object Detection with Vision-Language Model
Real-time Object Detection for Streaming Perception
Implicit Motion Handling for Video Camouflaged Object Detection
Focal and Global Knowledge Distillation for Detectors
Sequential Voting with Relational Box Fields for Active Object Detection
QueryDet: Cascaded Sparse Query for Accelerating High-Resolution Small Object Detection
R(Det)^2: Randomized Decision Routing for Object Detection
作者:包文韬
https://www.zhihu.com/question/517340666/answer/2414307092
可以关注一下开集识别(open-set recognition, OSR)方面的相关论文。这里简单PR一下我们CVPR 2022刚被接受为Oral的一篇论文,顺便浅谈一下目前OSR领域的发展现状与趋势。
论文地址:https://arxiv.org/pdf/2203.05114.pdf
开源代码:https://github.com/Cogito2012/OpenTAL
开集识别,简单来说就是在多类别分类任务基础上,进一步要求模型准确判别出未知类别的样本。我们此次被接收为CVPR 2022 Oral的这篇文章,首次在视频动作定位(temporal action localization, TAL)这一领域引入开集问题,称之为OSTAL任务。对于这一新的任务,下面一图胜千言:
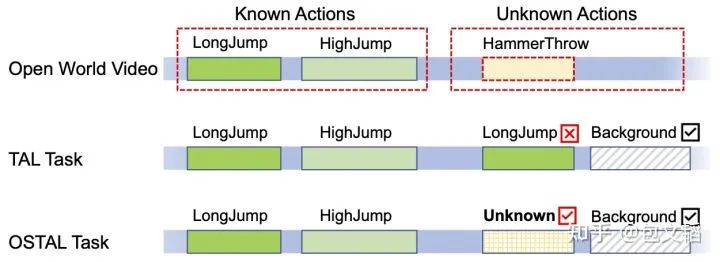
Open-set Temporal Action Localization
在开放世界中,现有训练好的视频TAL模型,不可避免地需要处理包含有任意未知事件/动作(unknown action)的长视频,目前这些模型要么错误地将这些unknown action判定为已知类别,要么直接判定为背景(background)。然而,当新的TAL需求包含有新的、模型从未见过(从未被监督学习过)的事件/动作时,需要重新标注一遍所有的训练视频吗?利用我们的OpenTAL方法,只需一个可定位未知动作的TAL模型,并辅以少量人工,对未知动作进一步标注真实类别即可。
提出的OpenTAL方法,主要受我们组近期的DEAR论文(ICCV 2021 Oral)启发,将基于证据深度学习不确定性理论,与长视频时序动作定位相结合,如图。
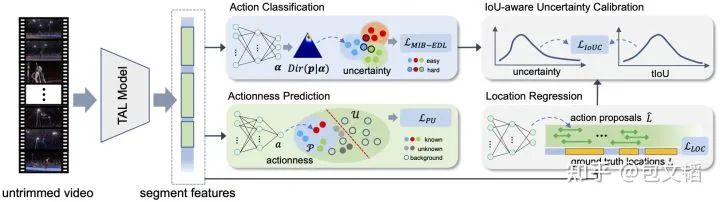
OpenTAL Framework
该方法主要包括:
动作分类(Action Classification): 对视频片段做K-way闭集分类,同时学习分类不确定性;
动作前景分预测(Actionness Prediction): 用于区分前/背景动作,在本文OSTAL设定中属于半监督二分类问题;
时序位置回归(Location Regression): 常规的时序定位模块;
不确定性校准(Uncertainty Calibration): 对于TAL任务来说,时序交并比(IoU)与不确定性之间存在隐含的约束关系。
对具体技术细节感兴趣的,欢迎阅读文章。由于时间精力有限,我们的方法目前只在AFSD这一TAL方法(CVPR 2021)上做了具体实现(参见开源代码)。实验结果表明,在THUMOS14数据集的closed set部分动作数据上训练的模型,不仅能够很好地定位、鉴别出另一部分未知open-set动作,而且还能够定位和鉴别出更大规模的ActivityNet1.3数据集中的未知open-set动作。
开集识别,早已不是新鲜的问题,而且还挺卷(参见https://github.com/iCGY96/awesome_OpenSetRecognition_list),并且和机器学习领域十分热门的Out-of-distribution (OOD) Detection有十分紧密的联系(参见https://github.com/Jingkang50/OODSurvey)。然而,除了做典型的图片分类之外,如何将open-set learning与更多下游的CV任务本身结合起来研究,才能更好地发挥OSR的应用价值,这方面直到近期才开始受到较多关注。下面列出几个不完整统计的近期OSR的CV应用文章,较多文章获得了Oral Accept,某种程度上可以说明这一领域的关注度正在上升。
CVPR 2022中的其它OSR应用文章:
视频目标跟踪:Yang Liu, Idil Esen Zulfikar, Jonathon Luiten, Achal Dave, Deva Ramanan, Bastian Leibe, Aljoša Ošep, Laura Leal-Taixé. Opening up Open-World Tracking. in CVPR, 2022 (Oral).
视频异常检测:Andra Acsintoae, et al. UBnormal: New Benchmark for Supervised Open-Set Video Anomaly Detection. in CVPR, 2022.
6D姿态估计:Yisheng He, Yao Wang, Haoqiang Fan, Jian Sun, Qifeng Chen. FS6D: Few-Shot 6D Pose Estimation of Novel Objects. in CVPR, 2022.
...
近期cv会议中部分OSR应用文章:
视频动作识别:Wentao Bao, Qi Yu, Yu Kong. Evidential Deep Learning for Open Set Action Recognition. in ICCV, 2021 (Oral).
图片分类:Shu Kong, Deva Ramanan. OpenGAN: Open-Set Recognition via Open Data Generation. in ICCV, 2021 (Best Paper Honorable Mention).
2D物体检测: KJ Joseph, Salman Khan, Fahad Shahbaz Khan, and Vineeth N Balasubramanian. Towards open world object detection. In CVPR, 2021 (Oral).
3D物体检测:Jun Cen, Peng Yun, Junhao Cai, Michael Yu Wang, Ming Liu. Open-set 3D object detection. in 3DV, 2021.
语义分割:Weiyao Wang, Matt Feiszli, Heng Wang, and Du Tran. Unidentified video objects: A benchmark for dense, open-world segmentation. In ICCV, 2021.
...
开集识别,一方面在底层的学习理论方面,存在许多的挑战(比如open-space risk management);另一方面,不同的下游CV任务,在开集世界中面临着绝然不同的挑战(比如object detection、OSTAL等定位任务中的隐含的半监督问题)。希望看到更多地相关工作,一起解决这些挑战。
作者:知乎用户
https://www.zhihu.com/question/517340666/answer/2381860732
主要盘点了一下CVPR 2022中与NeRF相关的论文(1、Mip-NeRF 360; 2、Point-NeRF; 3、Human-NeRF; 4、Urban-NeRF; 5、Block-NeRF; 6、Raw-NeRF)。
NeRF 是 2020 年 ECCV 上获得最佳论文荣誉提名的工作,其影响力是十分巨大的。NeRF 将隐式表达推上了一个新的高度,仅用 2D 的 posed images 作为监督,即可表示复杂的三维场景,在新视角合成这一任务上的表现是非常 impressive 的。目前 NeRF 的热度依旧不减,其表达方面的优势在诸多方面都有收益
作者:廖康
https://www.zhihu.com/question/517340666/answer/2422010395
分享一下我们今年在CVPR的Oral工作:Deep Rectangling for Image Stitching: A Learning Baseline
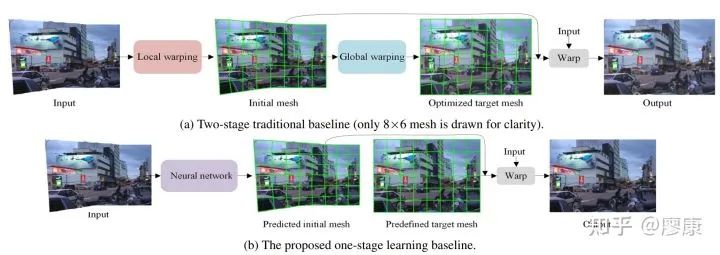
图像拼接技术将不同视角的图像warp至同一平面以此达到增大视场的目的,但是经过投影变换后,部分原始图像的边缘会出现拉伸等形变现象,进而导致最终拼接图像出现结构不规则的问题。为此,我们基于Kaiming早期在计算机图形学领域的工作——全景矩形化,提出更加灵活鲁棒、适应更多场景的Deep Rectangling。两种方法对比如上图所示。代码和数据集均已开源。
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 woshicver」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓

最后
以上就是懵懂狗最近收集整理的关于CVPR2022 有什么值得关注的论文 ?的全部内容,更多相关CVPR2022内容请搜索靠谱客的其他文章。








发表评论 取消回复