欢迎关注我的公众号 [极智视界],获取我的更多笔记分享
大家好,我是极智视界,本文解读一下 体现自适应的目标检测器 Interactron。

多年来,人们提出了各种各样的方法来解决目标检测问题。近年来,由于强大的深度神经网络的出现,咱们在这一领域取得了长足的进步。然而,在这些方法中通常有两个共同的假设。(1) 首先,在一个固定的数据集上训练模型,并在预先记录的测试集上进行评估。(2) 其次,在训练阶段结束后,模型被冻结,因此在训练结束后不再进行任何更新。这两个假设限制了这些方法在现实世界中的适用性。在本文中,作者提出了 Interactron,一种在交互式环境中进行自适应目标检测的方法,其目标是在不同的环境中由一个具体的代理导航在图像中进行目标检测。作者的想法是在推理期间继续训练,并在测试时通过与环境的交互来调整模型,而不需要任何明确的监督。提出的自适应目标检测模型在 AP 上比最近的高性能目标检测器 DETR 高了 7.2 个百分点 (在 AP50 上提高了 12.7 个百分点)。此外,还证明了提出的目标检测模型能够适应具有完全不同特征的环境,并在这些环境中取得良好的效果。
论文地址:https://arxiv.org/abs/2202.00660
代码地址:https://github.com/allenai/interactron
文章目录
1. 简介
自计算机视觉领域产生以来,目标检测一直是计算机视觉领域的核心问题。在过去的几十年里,有大量的文献提出了各种各样的方法,从 constellation、region-based 和 hierarchical 模型,到最近强大的 CNN 和 基于 Transformer 的模型来解决这些问题。典型的,这些工作中有两个主要的假设:(1) 存在一个固定的训练集和测试集;(2) 模型在训练阶段结束后被冻结,并在预定义的测试集上进行评估。这些假设对现实世界应用中的目标检测造成了一定的限制。(1) 首先,在许多应用中 (例如 自动驾驶或家庭助理机器人),模型不断接收来自环境中新的观察,而新的观察结果可能有助于模型修正其信念。例如,在当前帧中可能无法自信地检测到被遮挡的目标,但在以后的观察中可能会有该目标更加好的、未遮挡的视图。模型应该利用这一信号来提高它在未来类似情况下的信心。(2) 其次,训练后冻结权重会抑制模型的进一步改进和适应。作者认为,在推理阶段存在着强的自监督信号,具体代理可以通过与环境的交互来调整模型。
提出的方法的思想是在推理过程中继续训练,同时与环境进行交互。作者的假设是,与环境的交互使具体代理能够在推理过程中捕获更加好的观察结果,从而实现更加好的适应和更加高的性能。与常见的目标检测工作形成鲜明对比的是,训练和推理阶段之间没有明显的界限,并且模型在推理过程中学习采取行动并适应任何明确的监督。更加具体地说,有一个代理可以在室内环境中进行交互,并依赖于经过完全监督训练的目标检测器来识别目标。作者的目标是通过在推理过程中调整模型来提高目标检测性能,同时代理根据学习策略与环境进行交互,如图1。在训练过程中,代理使用监督数据学习损失函数,即使用标注数据来模仿训练期间产生的梯度。在推理过程中,没有可用于目标检测的监督。然而,该模型可以为输入图像生成梯度,因此可以使用生成的梯度在推理时更新模型。基本上在测试的时候,模型是在没有任何显式监督的情况下更新的。
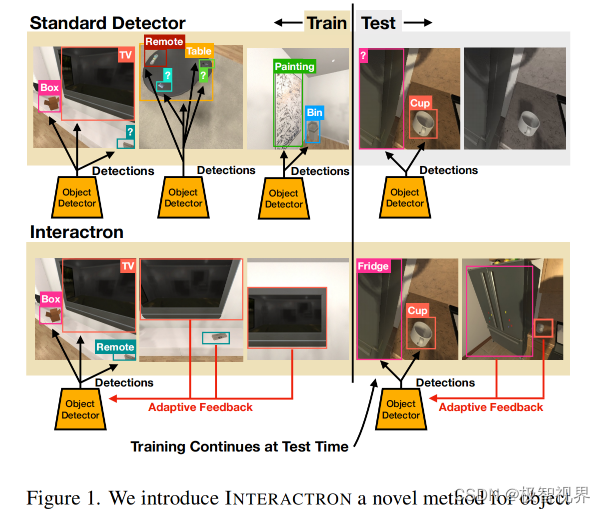
使用 AI2-THOR 框架评估提出的自适应目标检测模型,称为 Interactron,该模型包括出现在 120 个室内场景中的 125 个不同的目标类别。任务是检测代理在场景中导航时观察到的所有帧中的目标。实验表明,通过学习适应,相比与最新的高性能目标检测模型 DETR,mAP 提高了 7.2 个点。除了这个强有力的结果之外,作者还证明了在 AI2-THOR 上训练的自适应模型与在 Habitat 框架的完全监督下训练的模型取得了接近标准的结果,其中包括具有完全不同外观特征的场景。
总之,作者提出了一种包含自适应目标检测的方法,该方法在训练和推理中更新模型。这种方法与传统目标检测不同,传统目标检测中网络在训练后被冻结。该模型在推理过程中通过与环境的交互来学习适应,并且没有任何明确的监督。提出的模型显著地优于非自适应 baselines,并且可以很好地推广到具有不同外观特征分布的环境中。
2. 自适应学习
2.1 任务定义
首先介绍了一种新的目标检测任务,它适用于交互环境 (如 AI2-THOR 或 Habitat)。该任务包括为具体代理的以自我为中心的 RGB 帧中的每个目标检测 bounding box 和类别标签。

2.2 标准方法
解决这个问题的最简单的方法是使用一个现成的目标检测器,在初始帧上简单地执行目标检测,这里的策略是不采取任何行动。可以通过来自与交互环境相同域的数据预训练目标检测器来提高性能。一种更加强大的方法是使用随机策略移动代理,并在起始位置周围收集几个帧,然后可以训练一个多帧模型,以使用所有帧作为输入对初始帧进行目标检测。在这些序列上训练的模型可以学习利用代理在移动时收集的目标的多个视角来改进目标检测。
2.3 自适应学习
直观地说,在环境的一个特定局部区域 (无论是房间、建筑物还是场景) 中训练目标检测器可以提高检测器在该区域其他附近帧上的性能,因为这些环境 (实际上是自然界) 是连续的。通过经验结果证实了这种直觉,因此将此任务表述为一个元学习问题,其中交互式目标检测任务 T 的每个实例都代表一个要适应的新任务。在训练时,这种抽象很有效,因为咱们可以将 F 中的每个帧及其对应的 ground truth 标签作为一个任务示例,并应用 MAML 算法的一个版本。然而在测试时,这种方法是不可行的,因为咱们没有得到任何帧的标签。咱们可以通过添加另外一个损失来克服这个问题,这个损失不是基于标签的,而是基于 F 中的帧。这个损失可以是手工设计的,也可以是学习的。学习损失没有明确的目标,并通过趋向最小化这种损失来提高模型的检测能力。因此,提出的模型的学习目标是 公式(1)。
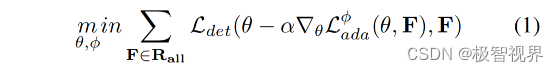
2.4 交互式自适应学习
在标准的自适应和元学习的应用程序中,通常假设每个任务的数据样本分布是固定的,不能被咱们所影响。在交互式环境中,这是不正确的,因为咱们用于适应的样本是由咱们的代理收集的。形式上,在每个时间step里,咱们的代理根据某个策略 P^2 采取行动 α,将它看到的所有先前帧作为输入。根据并非所有样本都提供相同质量和数量的信息的直觉,可以学习一个策略 Pint,它是一个由 ρ 参数化的神经网络,并对其进行优化以引导代理沿着一系列帧 F,这将使 Mmeta 轻松适应新任务。通过这种方式,鼓励代理收集有助于学习损失模拟 ground truth 标签提供的有监督的帧。将此值称为初始帧梯度对齐 IFGA,并为任何序列 F 定义为 公式(2)。
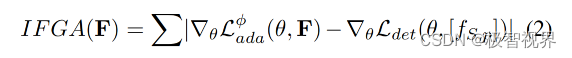
这使模型可以从学习到的损失中提取另一个有用的训练信号。需要注意的是,咱们只计算长度为 n+1 (初始帧加上代理收集的 n 帧) 的完整序列的 IFGA,因为学习的损失函数将 n+1 帧作为输入来计算自适应梯度,损失函数定义为公式(3)。
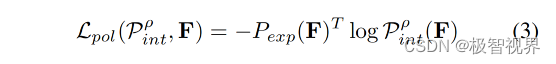
交互式自适应训练算法,如 Algorithm 1 所示。

通过这种方法,不仅利用了模型适应场景局部区域的能力,而且还利用了能够为咱们模型提供良好训练示例的帧也往往包含有用信息这一事实。
3. 方法
以上描述的方法是与基础数据模型无关的,但这些架构自然适合这种方法,这里描述了所研究的模型的具体内容,图2展示了这些模型的整体架构。
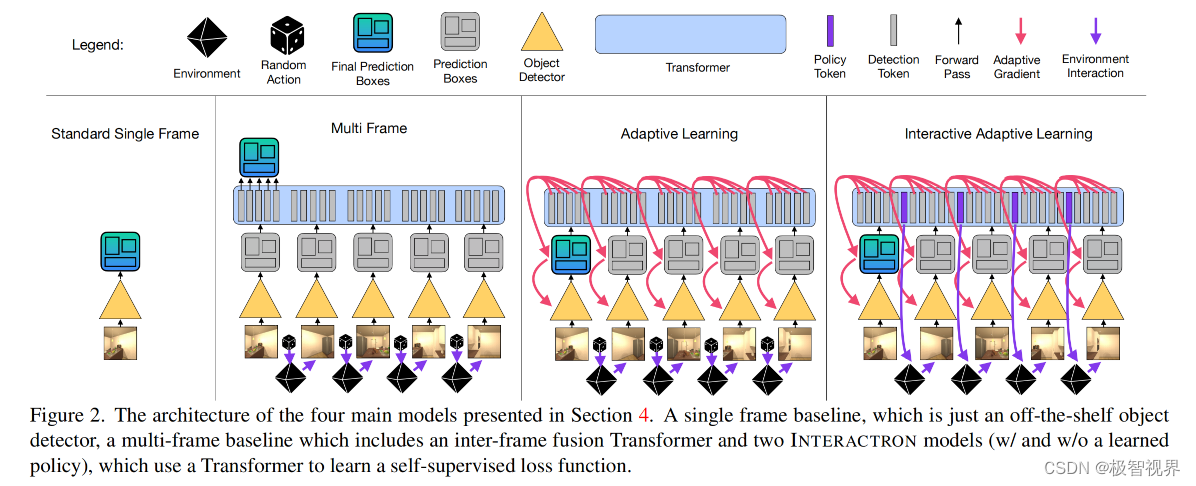
3.1 INTERACTRON 模型
本文的 pipeline 由两个模型组成:(1) Detector 执行目标检测任务并在测试时适应本地环境;(2) Supervisor 由学习损失Lada 和 学习策略Pint 组成,在测试时被冻结。
The Detector 检测器可以是任何现成的目标检测器模型,但作者使用 DEtection TRansformer (DETR) 进行实验,它在架构上很简单,但非常强大。它利用 ResNet backbone 生成图像特征,并利用 Transformer 模型处理所有特征来产生目标检测嵌入。然后将每个目标检测嵌入通过 MLP 来提取 bounding box坐标和预测目标类别。尽管在模型的其他地方使用了 Transformer,但使用基于 Transformer 的目标检测器并不是此架构的要求。
The Supervisor 监督器也是一种 Transformer 模型,既可以作为策略,也可以作为学习损失。由检测器产生的图像特征和目标检测嵌入,称为检测tokens,被传递到 Transformer。这些 tokens 的 transformer 输出通过 MLP,然后还原为一个标量以计算自适应梯度。除此之外,对于代理需要采取的每一个动作,一个可学习的策略 token 被传递到 Transformer 中,其输出用于计算策略。
Learned Loss Training 学习损失策略是通过将检测 token 输出传递给 MLP 并采用所有特征的 l2 范数来获得一个标量,该标量是自适应学习的目标。l2 范数是一种技巧,将监督器 transformer 产生的向量序列组合成单个标量损失。在训练期间,根据目标注释计算 ground truth 损失,并由自适应检测器进行预测。用于调整检测器参数的梯度由监督器生成,可以通过自适应梯度反向传播以更新监督器参数,使其产生更加好的自适应梯度 (元训练)。在测试时没有目标注释,但是监督器现在已经被优化,可以使用序列中的其他帧和检测来产生良好的梯度。
Policy Training 通过将问题视为序列预测任务来执行策略训练。学习 n 种不同的 EM 层来产生 n 种不同的策略tokens。策略tokens的 Transformer 输出通过 MLP 传递以生产动作概率分布。在训练期间探索所有长度为 n 的所有的轨迹,并优化策略以选择导致具有最低 IFGA 的完整退出 F 的动作。当 n 很小时,有可能退出每一个轨迹,但当 n 较大时,随机探索或强化学习方法更加可取。检测Tokens 被一帧一帧地送入 Transformer 中,然后是策略Tokens,其输出用于预测代理应该采取的下一个动作。当判断下一步要采取哪个动作时,该模型可以访问所有以前的帧。自适应梯度仅在所有 n 步完成后才计算。图4 展示了模型的更多细节。
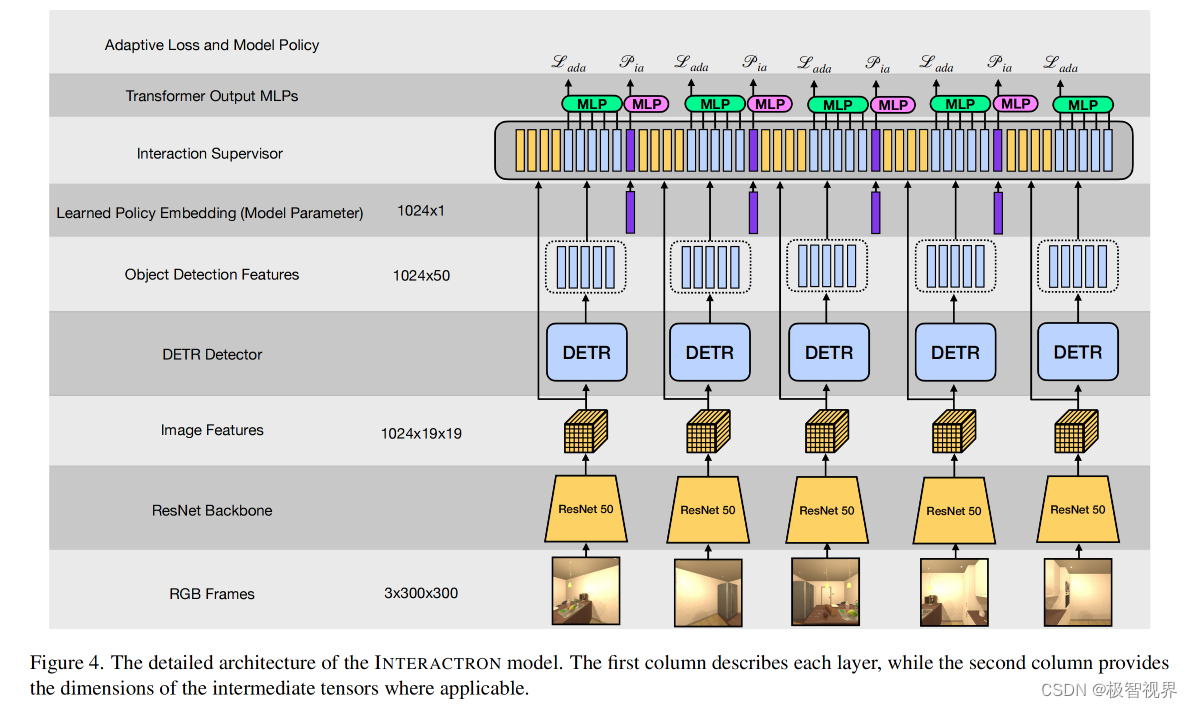
3.2 消融模型
The INTERACTRON-Rand Model 随机交互模型与上述的自适应交互式学习模型基本相同,只是它不向 Transformer 提供策略 tokens,而是采用随机策略 Prand。
The Multi-Frame Baseline 多帧 baseline 在架构上与自适应学习模型相同,但不是将 Transformer 用作学习的损失函数 Lada,而是将其用作融合层,组合序列中所有帧的检测器的输出以产生第一帧的检测结果。
The Single Frame Baseline 单帧 baseline 只是一个非自检测器,它已经在一些数据上进行了预训练,包括来自交互环境的图像,并且对应于 Mexist。
4. 实验
表1展示了本文的方法明显优于 baselines。

表2展示了在 AI2-iTHOR 图像上训练的 INTERACTRON 的性能几乎与在 Habitat 中经过全面监督预训练的检测器相当。
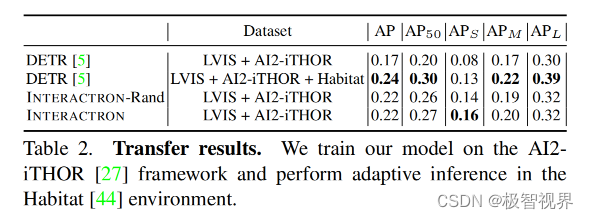
表3展示了元训练模型在没有 train-at-test 梯度更新的情况下,性能明显比作者的完整模型差。

表4展示了不同帧数量对效果的影响。
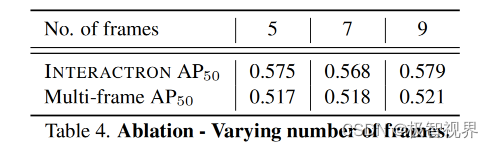
表5展示了使用随机交互模型仅查看第一帧的表现。

图3展示了由 INTERACTRON 生成的一些列图像展示。

5. 总结
本文介绍了一种自适应目标检测模型 INTERACTRON,该模型无需外部监督就能够适应其测试环境。该模型通过部署在环境中导航的具体代理上的学习策略收集有关场景的信息。作者展示了提出的方法显著改进了最先进的目标检测器 (目标检测 AP 提高了 7.2 个点)。此外,展示了提出的方法使模型适应新环境方面的优势,其表现与针对该环境进行完全监督训练的模型相当。
6. 参考
[1] Interactron: Embodied Adaptive Objection Detection.
好了,以上解读了 体现自适应的目标检测器 Interactron。希望我的分享能对你的学习有一点帮助。
【极智视界】

搜索关注我的微信公众号【极智视界】,获取我的更多经验分享,让我们用极致+极客的心态来迎接AI !
最后
以上就是害怕书本最近收集整理的关于Interactron | 体现自适应的目标检测器的全部内容,更多相关Interactron内容请搜索靠谱客的其他文章。








发表评论 取消回复