
文章目录
- 0、前言
- 1、正则表达式模式
- 2、正则表达式修饰符 - 可选标志
- 2.1、`re.IGNORECASE`(`re.I`)
- 2.2、`re.ASCII`(`re.A`)
- 2.3、`re.DOTALL`(`re.S`)
- 2.4、`re.MULTILINE`(`re.M`)
- 2.5、`re.VERBOSE`(re.X)
- 2.6、修饰符的叠加
- 3、正则表达式函数
- 3.1、查找单个匹配项的函数
- Example 3.1.1
- Example 3.1.2
- Example 3.1.3
- 3.2、查找多个匹配项的函数
- Example 3.2.1
- 3.3、分割
- Example 3.3.1
import re
登录后复制0、前言
本篇笔记基于菜鸟教程以及该知乎教程,融入了自己的一些学习心得。
1、正则表达式模式
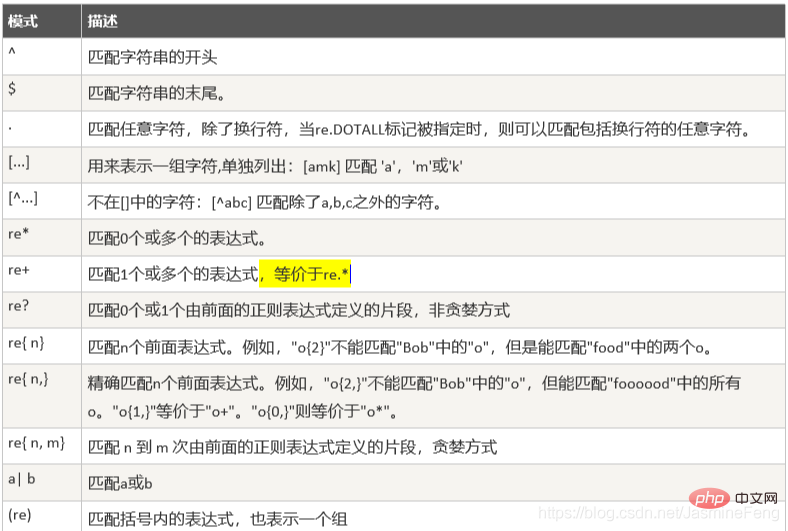
高亮处是我的补充,因为根据实际情况确实是能匹配到的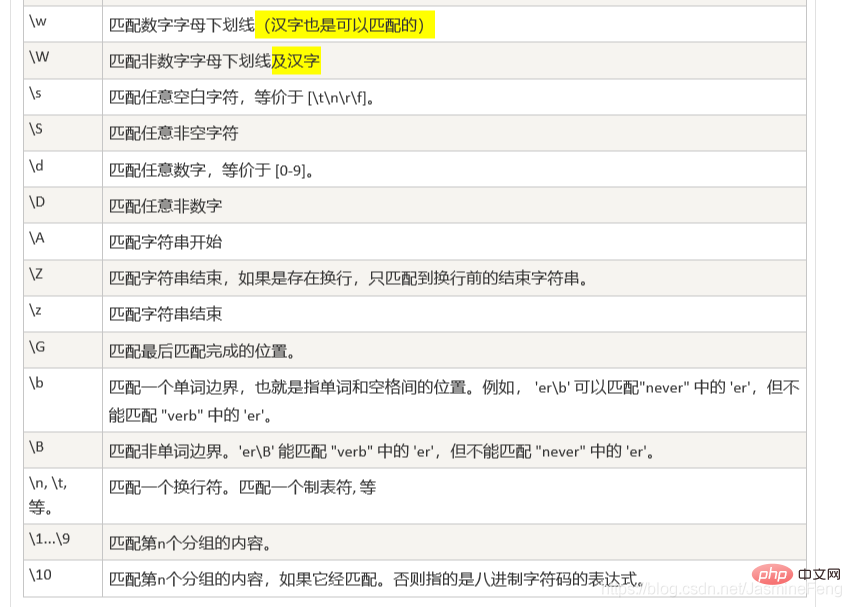
这边我就偷点懒了哈,直接截的是菜鸟教程的图。
2、正则表达式修饰符 - 可选标志
2.1、re.IGNORECASE(re.I)
虽然第1节是常量,但我们必须先简要提一下re.findall这个函数,因为它是贯穿这一节的函数。re.findall(pattern, string, flag=0): 从字符串任意位置查找,返回一个列表。pattern是欲匹配的字符(串),string是查找源,flag是修饰符,默认是0
re.I的作用是忽略字符大小写
text = "I'm Jasmine-Feng. My student number is No. 321432"pattern = r"Jasmine-FENG"print('Default: ', re.findall(pattern,text))print('Ignore upper/lower case: ', re.findall(pattern,text,flags=re.I))登录后复制N.B. pattern被赋了一个r字符串,这个r字符串的作用是避免转义,r是raw的缩写,也就是保持原样的意思。可看这篇博文。一般来说,使用正则表达式都会用到这个r字符串。
Default: []Ignore upper/lower case: ['Jasmine-Feng']Process finished with exit code 0
登录后复制在默认情况下,区分大小写,找不到ENG;若不区分,则可以找到eng。
2.2、re.ASCII(re.A)
re.A的作用是只匹配ASCII码支持的字符,那么具体指哪些字符呢?下图来自百度百科。
汉字是不在这个里面的,所以如果修饰符是re.A的话就匹配不了汉字了哈~
text = "我是Jasmine-Feng. 我的学号是No. 321432"pattern = r"w+"print('Default: ', re.findall(pattern,text))print('ASCII: ', re.findall(pattern,text,flags=re.A))登录后复制w+的作用是匹配一个或多个字母数字下划线汉字
Default: ['我是Jasmine', 'Feng', '我的学号是No', '321432']ASCII: ['Jasmine', 'Feng', 'No', '321432']Process finished with exit code 0
登录后复制2.3、re.DOTALL(re.S)
在正则表达式模式中,.是用来
text = "我t是Jasmine-Fneng. 我%的◉学号是No. 321432"pattern = r'.*'print('Default: ', re.findall(pattern,text))print('DOTALL: ', re.findall(pattern,text,re.S))登录后复制.*的作用是匹配长度至少为0的字符(串),emmm,好像是句废话?事实上,只要整段话不被换行符截断,就可以得到整个字符串(外加一个空字符串)。
Default: ['我t是Jasmine-F', '', 'eng. 我%的◉学号是No. 321432', '']DOTALL: ['我t是Jasmine-Fneng. 我%的◉学号是No. 321432', '']Process finished with exit code 0
登录后复制2.4、re.MULTILINE(re.M)
$匹配定位到字符串末尾,^定位到字符串开头,默认情况下,如果换行,是不能定位到新一行的行头/尾的,而用re.M修饰则可以,也就是多行模式。
text = "我t是Jasmine-Fneng. 我%的◉n学号是No. 321432"pattern = r'.$'pattern2 = r'^.'print('Default, end: ', re.findall(pattern, text))print('MULTILINE, end: ', re.findall(pattern, text, re.M))print('Default, start: ', re.findall(pattern2, text))print('MULTILINE, start: ', re.findall(pattern2, text, re.M))登录后复制Default, end: ['2']MULTILINE, end: ['F', '◉', '2']Default, start: ['我']MULTILINE, start: ['我', 'e', '学']Process finished with exit code 0
登录后复制2.5、re.VERBOSE(re.X)
verbose是“详实的、冗长的”意思,通过该修饰符可以在正则表达式中加入注释。注意,是往pattern里面加,不是往text加!我一开始以为是可以往text加注释,然后调试半天都得不到结果。。。
text = '朋友们好啊!我是xxxxxx拳掌门人xxx~'pattern = r'''朋友们 # 主语
好啊! # 谓语
'''print(re.findall(pattern, text,re.VERBOSE))登录后复制['朋友们好啊!']Process finished with exit code 0
登录后复制2.6、修饰符的叠加
使用|可以叠加修饰。
text = 'Hello everybody!n我是xxxxxx拳掌门人xxx~'pattern = r'BODY.*$'print(re.findall(pattern, text, re.I))print(re.findall(pattern, text, re.M))print(re.findall(pattern, text, re.M | re.I))
登录后复制[][]['body!']Process finished with exit code 0
登录后复制3、正则表达式函数
3.1、查找单个匹配项的函数
| 函数 | 功能 |
|---|---|
search | 从任意位置开始搜索 |
match | 从开头搜索,不用完全匹配 |
fullmatch | 从开头搜索,必须完全匹配 |
其实我本来是写了自己的例子的,但是浏览器给我误关了,又没保存(心态直接炸裂
以上就是笔记之 Python正则表达式的详细内容,更多请关注靠谱客其它相关文章!

最后
以上就是故意微笑最近收集整理的关于笔记之 Python正则表达式的全部内容,更多相关笔记之内容请搜索靠谱客的其他文章。








发表评论 取消回复