本篇文章给大家带来了关于Python的相关知识,其中主要整理了爬取网页图片的相关问题,要想高效的获取数据,爬虫是非常好用的,而用python做爬虫也十分简单方便,下面通过一个简单的小爬虫程序来看一看写爬虫的基本过程,下面一起来看一下,希望对大家有帮助。

【相关推荐:Python3视频教程 】
在现在这个信息爆炸的时代,要想高效的获取数据,爬虫是非常好用的。而用python做爬虫也十分简单方便,下面通过一个简单的小爬虫程序来看一看写爬虫的基本过程:
准备工作
语言:python
IDE:pycharm
首先是要用到的库,因为是刚入门最简单的程序,我们主要就用到下面这两:
import requests //用于请求网页
import re //正则表达式,用于解析筛选网页中的信息
登录后复制其中re是python自带的,requests库需要我们自己安装,在命令行中输入pip install requests即可。
然后随便找一个网站,注意不要尝试爬取隐私敏感信息,这里找了个表情包网站:
注:此处表情包网站中的内容本来就可以免费下载,所以爬虫只是简化了我们一个个点的流程,注意不能去爬取付费资源。

我们要做的就是通过爬虫把这些表情包下载到我们电脑里。
编写爬虫程序
首先肯定要通过python访问这个网站,代码如下:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:98.0) Gecko/20100101 Firefox/98.0'
}
response = requests.get('https://qq.yh31.com/zjbq/',headers=headers) //请求网页登录后复制其中之所以要加headers这一段是因为有些网页会识别到你是通过python请求的然后把你拒绝,所以我们要换个正常的请求头。可以随便找一个或者f12从网络信息里复制一个。

然后我们要找到我们要爬取的图片在网页代码里的位置,f12查看源代码,找到表情包如下:
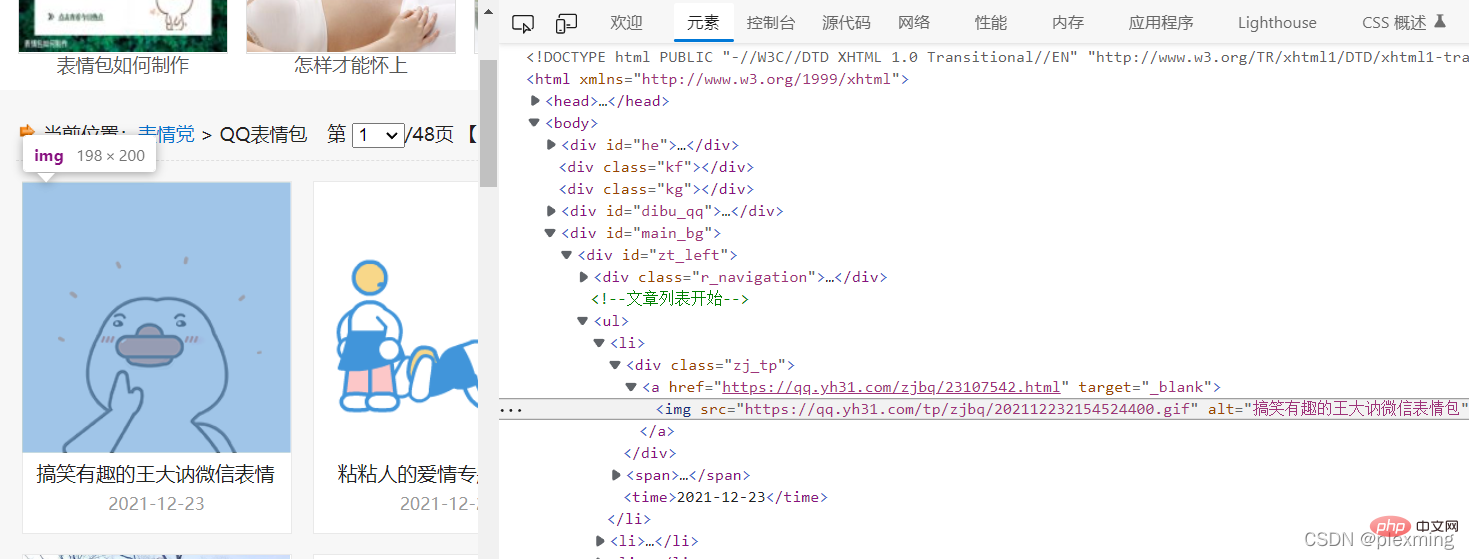
然后建立匹配规则,用正则表达式把中间那串替换掉,最简单的就是.*?
t = '<img src="(.*?)" alt="(.*?)" width="160" height="120">'
登录后复制像这样。
然后就可以调用re库里的findall方法把相关内容爬下来了:
result = re.findall(t, response.text)
登录后复制返回的内容是由字符串组成的列表,最后我们经由爬到的地址通过python语句把图片下下来保存到文件夹里就行了。
程序代码
import requests
import re
import os
image = '表情包'
if not os.path.exists(image):
os.mkdir(image)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:98.0) Gecko/20100101 Firefox/98.0'
}
response = requests.get('https://qq.yh31.com/zjbq/',headers=headers)
response.encoding = 'GBK'
response.encoding = 'utf-8'
print(response.request.headers)
print(response.status_code)
t = '<img src="(.*?)" alt="(.*?)" width="160" height="120">'
result = re.findall(t, response.text)
for img in result:
print(img)
res = requests.get(img[0])
print(res.status_code)
s = img[0].split('.')[-1] #截取图片后缀,得到表情包格式,如jpg ,gif
with open(image + '/' + img[1] + '.' + s, mode='wb') as file:
file.write(res.content)登录后复制最后结果就是这个样子:

【相关推荐:Python3视频教程 】
以上就是python爬虫入门实战之爬取网页图片的详细内容,更多请关注靠谱客其它相关文章!

最后
以上就是美满奇迹最近收集整理的关于python爬虫入门实战之爬取网页图片的全部内容,更多相关python爬虫入门实战之爬取网页图片内容请搜索靠谱客的其他文章。








发表评论 取消回复