首先郑重声明:
nodeJS 是一门单线程!异步!非阻塞语言!
nodeJS 是一门单线程!异步!非阻塞语言!
nodeJS 是一门单线程!异步!非阻塞语言!
重要的事情说3遍。 因为nodeJS天生自带buff, 所以从一出生就受到 万千 粉丝的追捧(俺,也是它的死忠). 但是,傻逼php 竟然嘲笑 我大NodeJS 的性能。 说不稳定,不可靠,只能利用单核CPU。 辣鸡 nodeJS.
艹!艹!艹!
搞mo shi~
但,大哥就是大哥,nodeJS在v0.8 的时候就已经加入了cluster的模块。 完全打脸php. 虽然,现在php 也开始抄袭nodeJS, 退出php7, 但是,渣渣,你就只会抄...
233333
对不起啊,上面是我自已意淫的一段~ 以上内容,纯属调侃,如果雷同,纯属巧合。
Ok~ 我们来正式介绍一下nodeJS的多进程吧~
cluster的前世今生
以前,由于cluster 本身的不完善,可能由于多方面原因吧,实现性能不好。 结果是,pm2 包的 崛起。 轻松使用一个pm2 就可以开启多进程,实现负载均衡的效果。
pm2 start app.js
pm2的内部和cluster内部实现其实是一个道理,都是封装了一层child_process--fork. 而child_process--fork 则是封装了unix 系统的fork 方法。 既然,都到这了,我们来看看官方给出的解释吧。
fork() creates a new process by duplicating the calling process. The new process is referred to as the child process. The calling process is referred to as the parent process. The child process and the parent process run in separate memory spaces. At the time of fork() both memory spaces have the same content. Memory writes, file mappings (mmap(2)), and unmappings (munmap(2)) performed by one of the processes do not affect the other.
俺来翻译一下,fork其实就是创建子进程的方法,新创建的进程被认为是子进程,而调用fork的进程则是父进程。 子进程和父进程本来是在独立的内存空间中的。但当你使用了fork之后,两者就处在同一个作用域内了。 但是,内存的读写,文件的map,都不会影响对方。
上面那段的意思就是,你创建的进程其实可以相互通信,并且被master进程 管理。
看图~~~
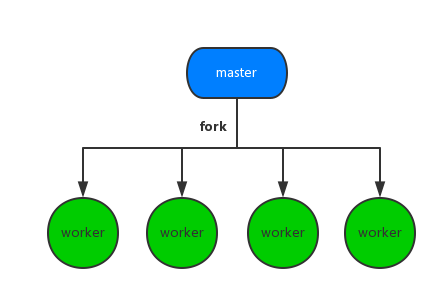
其实就是这个意思。
Ok~ 这只是系统创建子进程的模型。那么在NodeJs中是怎样实现进程之间的交互的呢?
很简单监听端口呗。。。
但是,实现通信不是很难,关键在于如果分配请求,这一点nodeJS 踩的坑确实很大。
nodeJS 实现进程分配的黑历史
long time ago
nodeJS的master 开始并不是上帝, 他只是一个小小的太监,每次请求(妃子)来的时候,他只会默默的看着几个worker小皇帝相互争夺,如果某个worker胜出,则其他的worker也就草草了事,等下一个请求过来。所以说,每来一次请求,都会引起一场腥风血雨。而,我们体会最深的就是惊群现象,即,CPU爆表.
借用TJ大神的一幅图,说明一下。

这里,master只是绑定端口,而不会对来的请求做任何处理。 通过将socket的fd给fork出来的进程。造成的结果就是4个人男人(worker)抢一个妃子(request). 那场面别提有多血腥了。
前面说过,cluster其实就是对child_process的一层封装,那我们继续往底层走一点。实现cluster多进程。 首先,我们需要了解,这几个模块的基本用法。net,child_process.
child_process
这个应该是nodeJS 进程最核心的模块。 基本的方法,有几个,不过我这里,只介绍比较核心的:spawn ,fork ,exec。如果大家有兴趣,可以去child_process参考.
child_process.spawn(command, args)
该方法用来运行指定的程序。比如: node app.js.他是异步的命令,但不支持callback, 不过我们可以使用process.on来监听结果。 他自带3个参数.
command: 执行命令
args[Array]: 命令所带的参数
options[Object]: 环境变量对象
OK~ 我们举个一个简单的demo: 试一试运行 touch apawn.js
const spawn = require('child_process').spawn;
const touch = spawn('touch',['spawn.js']);
touch.stdout.on('data', (data) => {
console.log(`stdout: ${data}`);
});
touch.stderr.on('data', (data) => {
console.log(`stderr: ${data}`);
});
touch.on('close', (code) => {
console.log(`child process exited with code $[code]`);
});
如果,正确的话,应该会输
出child process exited with code 0. 然后运行目录会生成pawn.js文件。 当然,如果你需要运行多参数的命令的话这就有点蛋疼了。
所以,nodeJS 使用了exec对其进行很好的封装,而且他支持回调函数,这比较能够让我们理解。
child_process.exec(order,cb(err[,stdout,stderr]));
order: 就是你执行的命令. 比如: rm spawn.js
cb: 就是命令执行成功后的回调函数。
const childProcess = require('child_process');
const ls = childProcess.exec('rm spawn.js', function (error, stdout, stderr) {
if (error) {
console.log(error.stack);
console.log('Error code: '+error.code);
}
console.log('Child Process STDOUT: '+stdout);
});
正常情况下会删除spawn.js文件。
上面两个只是简单的运行进程的命令。 最后,(Boss总是最后出场的). 我们来瞧瞧fork方法的使用.
fork其实也是用来执行进程,比如,spawn("node",['app.js']),其实和fork('app.js') 是一样的效果的。但是,fork牛逼的地方在于他在开启一个子进程时,同时建立了一个信息通道(双工的哦). 俩个进程之间使用process.on("message",fn)和process.send(...)进行信息的交流.
child_process.fork(order) //创建子进程
worker.on('message',cb) //监听message事件
worker.send(mes) //发送信息
他和spawn类似都是通过返回的通道进行通信。举一个demo, 两个文件master.js和worker.js 来看一下.
//master.js
const childProcess = require('child_process');
const worker = childProcess.fork('worker.js');
worker.on('message',function(mes){
console.log(`from worder, message: ${mes}`);
});
worker.send("this is master");
//worker.js
process.on('message',function(mes){
console.log(`from master, message: ${mes}`);
});
process.send("this is worker");
运行,node app.js, 会输出一下结果:
from master, message: this is master from worker, message: this is worker
现在我们已经学会了,如何使用child_process来创建一个基本的进程了。
关于net 这一模块,大家可以参考一下net模块.
ok . 现在我们正式进入,模拟nodeJS cluster模块通信的procedure了。
out of date 的cluster
这里先介绍一下,曾经的cluster实现的一套机理。同样,再放一次图
我们使用net和child_process来模仿一下。
//master.js
const net = require('net');
const fork = require('child_process').fork;
var handle = net._createServerHandle('0.0.0.0', 3000);
for(var i=0;i<4;i++) {
fork('./worker').send({}, handle);
}
//worker.js
const net = require('net');
//监听master发送过来的信息
process.on('message', function(m, handle) {
start(handle);
});
var buf = 'hello nodejs'; ///返回信息
var res = ['HTTP/1.1 200 OK','content-length:'+buf.length].join('rn')+'rnrn'+buf; //嵌套字
function start(server) {
server.listen();
var num=0;
//监听connection函数
server.onconnection = function(err,handle) {
num++;
console.log(`worker[${process.pid}]:${num}`);
var socket = new net.Socket({
handle: handle
});
socket.readable = socket.writable = true;
socket.end(res);
}
}
ok~ 我们运行一下程序, 首先运行node master.js.
然后使用测试工具,siege.
siege -c 100 -r 2 http://localhost:3000
OK,我们看一下,到底此时的负载是否均衡。
worker[1182]:52 worker[1183]:42 worker[1184]:90 worker[1181]:16
发现,这样任由worker去争夺请求,效率真的很低呀。每一次,触发请求,都有可能导致惊群事件的发生啊喂。所以,后来cluster改变了一种模式,使用master来控制请求的分配,官方给出的算法其实就是round-robin 轮转方法。
高富帅版cluster
现在具体的实现模型就变成这个.

由master来控制请求的给予。通过监听端口,创建一个socket,将获得的请求传递给子进程。
从tj大神那里借鉴的代码demo:
//master
const net = require('net');
const fork = require('child_process').fork;
var workers = [];
for (var i = 0; i < 4; i++) {
workers.push(fork('./worker'));
}
var handle = net._createServerHandle('0.0.0.0', 3000);
handle.listen();
//将监听事件移到master中
handle.onconnection = function (err,handle) {
var worker = workers.pop(); //取出一个pop
worker.send({},handle);
workers.unshift(worker); //再放回取出的pop
}
//worker.js
const net = require('net');
process.on('message', function (m, handle) {
start(handle);
});
var buf = 'hello Node.js';
var res = ['HTTP/1.1 200 OK','content-length:'+buf.length].join('rn')+'rnrn'+buf;
function start(handle) {
console.log('got a connection on worker, pid = %d', process.pid);
var socket = new net.Socket({
handle: handle
});
socket.readable = socket.writable = true;
socket.end(res);
}
这里就经由master来掌控全局了. 当一个皇帝(worker)正在宠幸妃子的时候,master就会安排剩下的几个皇帝排队一个几个的来。 其实中间的handle就会我们具体的业务逻辑. 如同:app.js.
ok~ 我们再来看一下cluster模块实现多进程的具体写法.
cluster模块实现多进程
现在的cluster已经可以说完全做到的负载均衡。在cluster说明我已经做了阐述了。我们来看一下具体的实现吧
var cluster = require('cluster');
var http = require('http');
var numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
console.log('[master] ' + "start master...");
for (var i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('listening', function (worker, address) {
console.log('[master] ' + 'listening: worker' + worker.id + ',pid:' + worker.process.pid + ', Address:' + address.address + ":" + address.port);
});
} else if (cluster.isWorker) {
console.log('[worker] ' + "start worker ..." + cluster.worker.id);
var num = 0;
http.createServer(function (req, res) {
num++;
console.log('worker'+cluster.worker.id+":"+num);
res.end('worker'+cluster.worker.id+',PID:'+process.pid);
}).listen(3000);
}
这里使用的是HTTP模块,当然,完全也可以替换为socket模块. 不过由于这样书写,将集群和单边给混淆了。 所以,推荐写法是将具体业务逻辑独立出来.
var cluster = require('cluster');
var numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
console.log('[master] ' + "start master...");
for (var i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('listening', function (worker, address) {
console.log('[master] ' + 'listening: worker' + worker.id + ',pid:' + worker.process.pid + ', Address:' + address.address + ":" + address.port);
});
} else if (cluster.isWorker) {
require('app.js');
}
//app.js就是开启具体的业务逻辑了
//app.js具体内容
const net = require('net');
//自动创建socket
const server = net.createServer(function(socket) { //'connection' listener
socket.on('end', function() {
console.log('server disconnected');
});
socket.on('data', function() {
socket.end('hellorn');
});
});
//开启端口的监听
server.listen(8124, function() { //'listening' listener
console.log('working')
});
接着我们开启服务,node master.js
然后进行测试
siege -c 100 -r 2 http://localhost:8124
我这里开启的是长连接. 每个worker处理的长连接数是有限的。所以,当有额外的连接到来时,worker会断开当前没有响应的连接,去处理新的连接。
不过,平常我们都是使用HTTP开启 短连接,快速处理大并发的请求。
这是我改成HTTP短连接之后的结果
Transactions: 200 hits Availability: 100.00 % Elapsed time: 2.09 secs Data transferred: 0.00 MB Response time: 0.02 secs Transaction rate: 95.69 trans/sec Throughput: 0.00 MB/sec Concurrency: 1.74 Successful transactions: 200 Failed transactions: 0 Longest transaction: 0.05 Shortest transaction: 0.02
那,怎么模拟大并发嘞?
e e e e e e e e e ...
自己解决啊~
开玩笑的啦~ 不然我写blog是为了什么呢? 就是为了传播知识.
在介绍工具之前,我想先说几个关于性能的基本概念
QPS(TPS),并发数,响应时间,吞吐量,吞吐率
你母鸡的性能测试theories
自从我们和服务器扯上关系后,我们前端的性能测试真的很多。但这也是我们必须掌握的tip. 本来前端宝宝只需要看看控制台,了解一下网页运行是否运行顺畅, 看看TimeLine,Profile 就可以了。 不过,作为一名有追求,有志于改变世界的童鞋来说。。。
md~ 又要学了...
ok~ 好了,在进入正题之前,我再放一次 线上的测试结果.
Transactions: 200 hits Availability: 100.00 % Elapsed time: 13.46 secs Data transferred: 0.15 MB Response time: 3.64 secs Transaction rate: 14.86 trans/sec Throughput: 0.01 MB/sec Concurrency: 54.15 Successful transactions: 200 Failed transactions: 0 Longest transaction: 11.27 Shortest transaction: 0.01
根据上面的数据,就可以得出,你网页的大致性能了。
恩~ let's begin
吞吐率
关于吞吐率有多种解读,一种是:描绘web服务器单位时间处理请求的能力。根据这个描述,其单位就为: req/sec. 另一种是: 单位时间内网络上传输的数据量。 而根据这个描述的话,他的单位就为: MB/sec.
而这个指标就是上面数据中的Throughput. 当然,肯定是越大越好了
吞吐量
这个和上面的吞吐率很有点关系的。 吞吐量是在没有时间的限制下,你一次测试的传输数据总和。 所以,没有时间条件的测试,都是耍流氓。
这个对应于上面数据中的Data transferred.
事务 && TPS
熟悉数据库操作的童鞋,应该知道,在数据库中常常会提到一个叫做事务的概念。 在数据库中,一个事务,常常代表着一个具体的处理流程和结果. 比如,我现在想要的数据是 2013-2015年,数学期末考试成绩排名. 这个就是一个具体的事务,那么我们映射到数据库中就是,取出2013-2015年的排名,然后取平均值,返回最后的排序结果。 可以看出,事务并不单单指单一的操作,他是由一个或一个以上 操作组合而成具有 实际意义的。 那,反映到前端测试,我们应该怎样去定义呢? 首先,我们需要了解,前端的网络交流其实就是 请求-响应模式. 也就是说,每一次请求,我们都可以理解为一次事务(trans).
所以,TPS(transaction per second)就可以理解为1sec内,系统能够处理的请求数目.他的单位也就是: trans/sec . 你当然也可以理解为seq/sec.
所以说,TPS 应该是衡量一个系统承载力最优的一个标识.
TPS的计算公式很容易的出来就是: Transactions / Elapsed time.
不过, 凡事无绝对。 大家以后遇到测试的时候,应该就会知道的.
并发数
就是服务器能够并发处理的连接数,具体我也母鸡他的单位是什么。 官方给出的解释是:
Concurrency is average number of simultaneous connections, a number which rises as server performance decreases.
这里我们就理解为,这就是一个衡量系统的承载力的一个标准吧。 当Concurrency 越高,表示 系统承载的越多,但性能也越低。
ok~ 但是我们如何利用这些数据,来确定我们的并发策略呢? e e e e e e e ...
当然, 一两次测试的结果真的没有什么卵用. 所以实际上,我们需要进行多次测试,然后画图才行。 当然,一些大公司,早就有一套完整的系统来计算你web服务器的瓶颈,以及 给出 最优的并发策略.
废话不多说,我们来看看,如何分析,才能得出 比较好的 并发策略。
探究并发策略
首先,我们这里的并发需要进行区分. 一个是并发的请求数,一个是并发的用户数. 这两个对于服务器是完全不同的需求。
假如100个用户同时向服务器分别进行10次请求,与1个用户向服务器连续进行1000次请求。两个的效果一样么?
一个用户向服务器连续进行1000次请求的过程中,任何时刻服务器的网卡接受缓存区中只有来自该用户的1个请求,而100个用户同时向服务器分别进行10次请求的过程中,服务器网卡接收缓冲区中最多有100个等待处理的请求,显然这时候服务器的压力更大。
所以上面所说的 并发用户数和吞吐率 是完全不一样的.
不过通常来说,我们更看重的是Concurrency(并发用户数). 因为这样更能反映出系统的 能力。 一般,我们都会对并发用户数进行一些限制,比如apache的maxClients参数.
ok~ 我们来实例分析一下吧.
首先,我们拿到一份测试数据.

接着,我们进行数据分析.
根据并发数和吞吐率的关系得出下列的图.
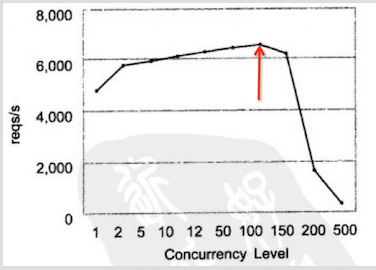
OK~ 我们会发现从大约130并发数的地方开始,吞吐率开始下降,而且越多下降的越厉害。 主要是因为,在前面部分随着用户数的上升,空闲的系统资源得到充分的利用,当然就和正太曲线一样,总会有个顶点。 当到达一定值后,顶点就会出现了. 这就我们的系统的一个瓶颈.
接着,我们细化分析,响应时间和并发用户数的相关性

同样额道理,当并发数到达130左右,正对每个req的响应时间开始增加,越大越抖,这适合吞吐率是相关的。 所以,我们可以得出一个结论,该次连接 并发数 最好设置为100~150之间。 当然,这样的分析很肤浅,不过,对于我们这些前端宝宝来说了解一下就足够了。
接下来,我们使用工具来武装自己的头脑.
这里主要介绍一个测试工具,siege.
并发测试工具
事实上并发测试工具主要有3个siege,ab,还有webbench. 我这里之所以没介绍webbench的原因,因为,我在尝试安装他时,老子,电脑差点就挂了(我的MAC pro)... 不过后面,被聪明的我 巧妙的挽回~ 所以,如果有其他大神在MAC x11 上成功安装,可以私信小弟。让我学习学习。
ok~ 吐槽完了。我们正式说一下siege吧
siege
安装siege利用MAC神器 homebrew, 就是就和js前端世界的npm一样.
安装ing:
brew install siege
安装成功--bingo
接着,我们来看一下语法吧.
-c NUM 设置并发的用户数量.eg: -c 100;
-r NUM 设置发送几轮的请求,即,总的请求数为: -cNum*-rNum但是, -r不能和-t一起使用(为什么呢?你猜).eg: -r 20
-t NUM 测试持续时间,指你运行一次测试需要的时间,在timeout后,结束测试.
-f file. 用来测试file里面的url路径 eg: -f girls.txt.
-b . 就是询问开不开启基准测试(benchmark)。 这个参数不太重要,有兴趣的同学,可以下去学习一下。
关于-c -r我就不介绍了。 大家有兴趣,可以参考一下,我前一篇文章让你升级的网络知识. 这里主要介绍一下 -f 参数.
通常,如果我们想要测试多个页面的话,可以新建一个文件,在文件中创建 你想测试的所有网页地址.
比如:
//文件名为 urls.txt
www.example.com www.example.org 123.45.67.89
然后运行测试
siege -f your/file/path.txt -c 100 -t 10s
OK~ 关于进程和测试的内容就介绍到这了。
最后
以上就是无情春天最近收集整理的关于node.js使用cluster实现多进程的全部内容,更多相关node内容请搜索靠谱客的其他文章。








发表评论 取消回复