C#如何安全、高效地玩转任何种类的内存之Span的本质
一、what - 痛点是什么?
回答这个问题前,先总结一下如何用C#操作任何类型的内存:
1、托管内存(managed memory )
var mangedMemory = new Student();
很熟悉吧,只需使用new操作符就分配了一块托管堆内存,而且还不用手工释放它,因为它是由垃圾收集器(GC)管理的,GC会智能地决定何时释放它,这就是所谓的托管内存。默认情况下,GC通过复制内存的方式分代管理小对象(size < 85000 bytes),而专门为大对象(size >= 85000 bytes)开辟大对象堆(LOH),管理大对象时,并不会复制它,而是将其放入一个列表,提供较慢的分配和释放,而且很容易产生内存碎片。
2、栈内存(stack memory )
unsafe{
var stackMemory = stackalloc byte[100];
}
很简单,使用stackalloc关键字非常快速地就分配好了一块栈内存,也不用手工释放,它会随着当前作用域而释放,比如方法执行结束时,就自动释放了。栈内存的容量非常小( ARM、x86 和 x64 计算机,默认堆栈大小为 1 MB),当你使用栈内存的容量大于1M时,就会报StackOverflowException 异常 ,这通常是致命的,不能被处理,而且会立即干掉整个应用程序,所以栈内存一般用于需要小内存,但是又不得不快速执行的大量短操作,比如微软使用栈内存来快速地记录ETW事件日志。
3、本机内存(native memory )
IntPtr nativeMemory0 = default(IntPtr), nativeMemory1 = default(IntPtr);
try
{
unsafe
{
nativeMemory0 = Marshal.AllocHGlobal(256);
nativeMemory1 = Marshal.AllocCoTaskMem(256);
}
}
finally
{
Marshal.FreeHGlobal(nativeMemory0);
Marshal.FreeCoTaskMem(nativeMemory1);
}
通过调用方法Marshal.AllocHGlobal 或Marshal.AllocCoTaskMem 来分配非托管堆内存,非托管就是垃圾回收器(GC)不可见的意思,并且还需要手工调用方法Marshal.FreeHGlobal or Marshal.FreeCoTaskMem 释放它,千万不能忘记,不然就内存泄漏了。
二、抛砖引玉 - 痛点
首先我们设计一个解析完整或部分字符串为整数的API,如下:
public interface IntParser
{
// allows us to parse the whole string.
int Parse(string managedMemory);
// allows us to parse part of the string.
int Parse(string managedMemory, int startIndex, int length);
// allows us to parse characters stored on the unmanaged heap / stack.
unsafe int Parse(char* pointerToUnmanagedMemory, int length);
// allows us to parse part of the characters stored on the unmanaged heap / stack.
unsafe int Parse(char* pointerToUnmanagedMemory, int startIndex, int length);
}
从上面可以看到,为了支持解析来自任何内存区域的字符串,一共写了4个重载方法。
接下来在来设计一个支持复制任何内存块的API,如下:
public interface MemoryblockCopier
{
void Copy<T>(T[] source, T[] destination);
void Copy<T>(T[] source, int sourceStartIndex, T[] destination, int destinationStartIndex, int elementsCount);
unsafe void Copy<T>(void* source, void* destination, int elementsCount);
unsafe void Copy<T>(void* source, int sourceStartIndex, void* destination, int destinationStartIndex, int elementsCount);
unsafe void Copy<T>(void* source, int sourceLength, T[] destination);
unsafe void Copy<T>(void* source, int sourceStartIndex, T[] destination, int destinationStartIndex, int elementsCount);
}
脑袋蒙圈没,以前C#操纵各种内存就是这么复杂、麻烦。通过上面的总结如何用C#操作任何类型的内存,相信大多数同学都能够很好地理解这两个类的设计,但我心里是没底的,因为使用了不安全代码和指针,这些操作是危险的、不可控的,根本无法获得.net至关重要的安全保障,并且可能还会有难以预估的问题,比如堆栈溢出、内存碎片、栈撕裂等等,微软的工程师们早就意识到了这个痛点,所以span诞生了,它就是这个痛点的解决方案。
三、how - span如何解决这个痛点?
先来看看,如何使用span操作各种类型的内存(伪代码):
1、托管内存(managed memory )
var managedMemory = new byte[100]; Span<byte> span = managedMemory;
2、栈内存(stack memory )
var stackedMemory = stackalloc byte[100]; var span = new Span<byte>(stackedMemory, 100);
3、本机内存(native memory )
var nativeMemory = Marshal.AllocHGlobal(100); var nativeSpan = new Span<byte>(nativeMemory.ToPointer(), 100);
span就像黑洞一样,能够吸收来自于内存任意区域的数据,实际上,现在,在.Net的世界里,Span就是所有类型内存的抽象化身,表示一段连续的内存,它的API设计和性能就像数组一样,所以我们完全可以像使用数组一样地操作各种内存,真的是太方便了。
现在重构上面的两个设计,如下:
public interface IntParser
{
int Parse(Span<char> managedMemory);
int Parse(Span<char>, int startIndex, int length);
}
public interface MemoryblockCopier
{
void Copy<T>(Span<T> source, Span<T> destination);
void Copy<T>(Span<T> source, int sourceStartIndex, Span<T> destination, int destinationStartIndex, int elementsCount);
}
上面的方法根本不关心它操作的是哪种类型的内存,我们可以自由地从托管内存切换到本机代码,再切换到堆栈上,真正的享受玩转内存的乐趣。
四、why - 为什么span能解决这个痛点?
1、浅析span的工作机制
先来窥视一下源码:
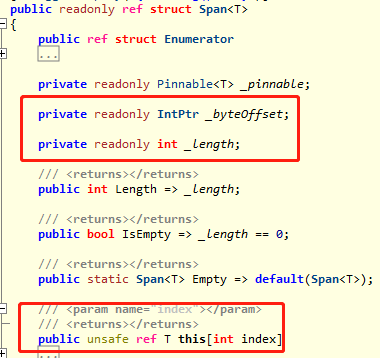
我已经圈出的三个字段:偏移量、索引、长度(使用过ArraySegment<byte> 的同学可能已经大致理解到设计的精髓了),这就是它的主要设计,当我们访问span表示的整体或部分内存时,内部的索引器会按照下面的算法运算指针(伪代码):
ref T this[int index]
{
get => ref ((ref reference + byteOffset) + index * sizeOf(T));
}
整个变化的过程,如图所示:

上面的动画非常清楚了吧,旧span整合它的引用和偏移成新的span的引用,整个过程并没有复制内存,也没有返回相对位置上存在的副本,而是直接返回实际存储位置的引用,因此性能非常高,因为新span获得并更新了引用,所以垃圾回收器(GC)知道如何处理新的span,从而获得了.Net至关重要的安全保障,并且内部还会自动执行边界检查确保内存安全,而这些都是span内部默默完成的,开发人员根本不用担心,非托管世界依然美好。
正是由于span的高性能,目前很多基础设施都开始支持span,甚至使用span进行重构,比如:System.String.Substring方法,我们都知道此方法是非常消耗性能的,首先会创建一个新的字符串,然后再从原始字符串中复制字符集给它,而使用span可以实现Non-Allocating、Zero-coping,下面是我做的一个基准测试:
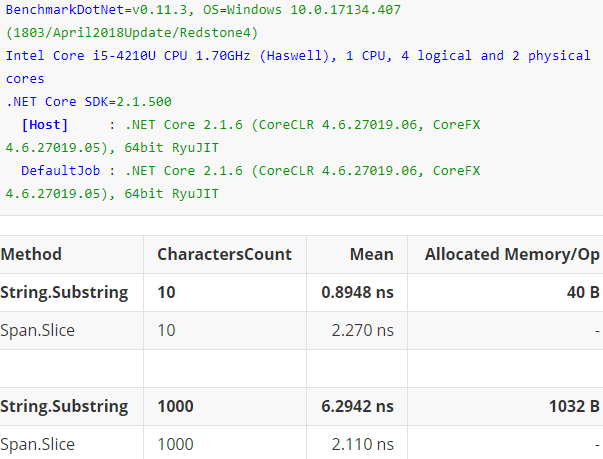
使用String.SubString和Span.Slice分别截取长度为10和1000的字符串的前一半,从指标Mean可以看出方法SubString的耗时随着字符串长度呈线性增长,而Slice几乎保持不变;从指标Allocated Memory/Op可以看出,方法Slice并没有被分配新的内存,实践出真知,可以预见Span未来将会成为.Net下编写高性能应用程序的重要积木,应用前景也会非常地广,微服务、物联网、云原生都是它发光发热的好地方。
从技术的本质上看,Span<T>是一种ref-like type类似引用的结构体;从应用的场景上看,它是高性能的sliceable type可切片类型;综上所诉,Span是一种类似于数组的结构体,但具有创建数组一部分视图,而无需在堆上分配新对象或复制数据的超能力。
补充:
可能会有的同学误解了span,表面上认为只是对指针的封装,从而绕过unsafe带来的限制,避免开发人员直接面对指针而已,其实不是,下面我们来看一个示例:
var nativeMemory = Marshal.AllocHGlobal(100);
Span<byte> nativeSpan;
unsafe {
nativeSpan = new Span<byte>(nativeMemory.ToPointer(), 100);
}
SafeSum(nativeSpan);
Marshal.FreeHGlobal(nativeMemory);
// 这里不关心操作的内存类型,即不用为一种类型写一个重载方法,就好比上面的设计一样。
static ulong SafeSum(Span<byte> bytes) {
ulong sum = 0;
for(int i=0; i < bytes.Length; i++) {
sum += bytes[i];
}
return sum;
}
并没有绕过unsafe,以前该如何用,现在还是一样的,span解决的是下面几点:
- 高性能,避免不必要的内存分配和复制。
- 高效率,它可以为任何具有无复制语义的连续内存块提供安全和可编辑的视图,极大地简化了内存操作,即不用为每一种内存类型操作写一个重载方法。
- 内存安全,span内部会自动执行边界检查来确保安全地读写内存,但它并不管理如何释放内存,而且也管理不了,因为所有权不属于它,希望大家要明白这一点。
以上就是C#如何安全、高效地玩转任何种类的内存之Span的本质的详细内容,更多关于C#语言的资料请关注靠谱客其它相关文章!,希望大家以后多多支持靠谱客!
最后
以上就是俊逸方盒最近收集整理的关于C#如何安全、高效地玩转任何种类的内存之Span的本质的全部内容,更多相关C#如何安全、高效地玩转任何种类内容请搜索靠谱客的其他文章。








发表评论 取消回复