在了解Diff前,先看下React的虚拟DOM的结构
这是html结构
<div id="father"> <p class="child">I am child p</p> <div class="child">I am child div</div> </div>
这是React渲染html时的js代码 自己可以在babel上试试
React.createElement("div", {id: "father"},
React.createElement("p", {class: "child"}, "I am child p"),
React.createElement("div", {class: "child"}, "I am child div")
);
由此可以看出这是一个树结构
React在调用render方法时会创建一颗树(简称pre),在下一次调用render方法时会返回一颗不同的树(简称cur)。React就会比较pre和cur这两棵树之间的差别来判断如何高效的更新UI,保证当前UI与最新的树cur保持同步。
为了高效更新UI,React在以下两个假设的基础上提出了一套O(n)的启发算法:
1.两个不同类型的元素会产生出不同的树;
2.开发者可以通过设置 key 属性,来告知渲染哪些子元素在不同的渲染下可以保存不变;
Diffing 算法
逐层比较
在对比两棵树时,React是逐层进行比较的,只会对相同颜色框内的DOM节点进行比较。

首先比较两棵树的根节点,不同类型的根节点会有不同的形态。当根节点为不同类型的元素时,React 会拆卸原有的树并且建立起新的树。举个例子,当一个元素从 <a> 变成 <img>,从 <Article> 变成 <Comment>,或从 <Button> 变成 <div> 都会触发一个完整的重建流程。
//before
<div>
<App/>
</div>
//after
<p>
<App/>
</p>
React会销毁App组件(该组件的子组件也全都销毁),并且重新创建一个新的App组件(也包括App的子组件)。
如下的DOM结构转换:
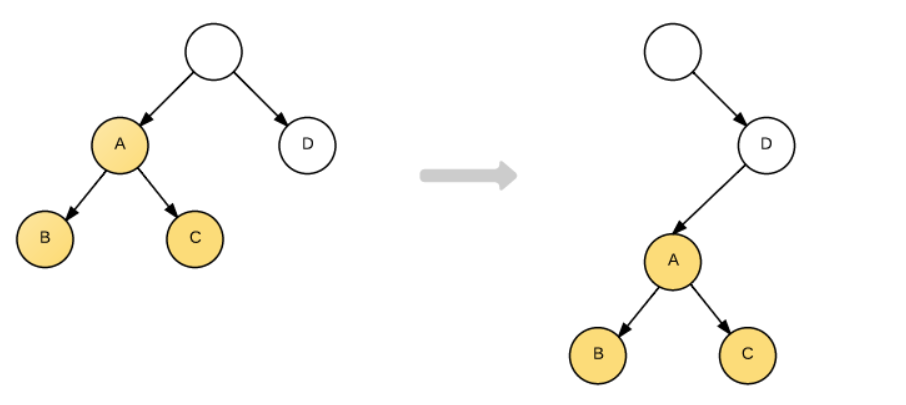
React只会简单的考虑同层节点的位置变换,对于不同层的节点,只有简单的创建和删除。当根节点发现子节点中A不见了,就会直接销毁A;而当D发现自己多了一个子节点A,则会创建一个新的A作为子节点。因此对于这种结构的转变的实际操作是:
A.destroy(); A = new A(); A.append(new B()); A.append(new C()); D.append(A);
虽然看上去这样的算法有些“简陋”,但是其基于的是第一个假设:两个不同类型的元素会产生出不同的树。根据React官方文档,这一假设至今为止没有导致严重的性能问题。这当然也给我们一个提示,在实现自己的组件时,保持稳定的DOM结构会有助于性能的提升。例如,我们有时可以通过CSS隐藏或显示某些节点,而不是真的移除或添加DOM节点。
对比同类型的组件元素
当一个组件更新时,组件实例会保持不变,但是state或props中数据的变化会调用render从而改变该组件中的子元素进行更新。
对比同一类型的元素
当对比两个相同类型的 React 元素时,React 会保留 DOM 节点,仅比对及更新有改变的属性。
<div className="before" title="stuff" /> <div className="after" title="stuff" />
React将div的className由before修改为after(类似于React中更新state的合并操作)。
对子节点进行递归
默认情况下(逐层比较),当递归 DOM 节点的子元素时,React 会同时遍历两个子元素的列表;当产生差异时,生成一个 mutation(突变)。
所以在列表末尾新增元素时,更新开销比较小。例如:
<ul> <li>first</li> <li>second</li> </ul> <ul> <li>first</li> <li>second</li> <li>third</li> </ul>
React 会先匹配两个 <li>first</li> 对应的树,然后匹配第二个元素 <li>second</li> 对应的树,最后插入第三个元素的 <li>third</li> 树。
如果只是简单的将新增元素插入到表头,那么更新开销会比较大。比如:
<ul> <li>Duke</li> <li>Villanova</li> </ul> <ul> <li>Connecticut</li> <li>Duke</li> <li>Villanova</li> </ul>
React 并不会意识到应该保留 <li>Duke</li> 和 <li>Villanova</li>,而是会重建每一个子元素。这种情况会带来性能问题。
Keys
为了解决上述问题,React 引入了 key 属性。当子元素拥有 key 时,React 使用 key 来匹配原有树上的子元素以及最新树上的子元素。以下示例在新增 key 之后,使得树的转换效率得以提高:
<ul> <li key="2015">Duke</li> <li key="2016">Villanova</li> </ul> <ul> <li key="2014">Connecticut</li> <li key="2015">Duke</li> <li key="2016">Villanova</li> </ul>
现在 React 知道只有带着 '2014' key 的元素是新元素,带着 '2015' 以及 '2016' key 的元素仅仅移动了。所以只是创建了 key=2014的元素,并不会创建剩下的两个元素。
所以key的取值最好不要使用数组的下标,因为数组的顺序可能会发生变化,最好使用自身数据携带的唯一标识(id或是其它的属性)。
1. 虚拟DOM中key的作用:
1). 简单的说: key是虚拟DOM对象的标识, 在更新显示时key起着极其重要的作用。
2). 详细的说: 当状态中的数据发生变化时,react会根据【新数据】生成【新的虚拟DOM】, 随后React进行【新虚拟DOM】与【旧虚拟DOM】的diff比较,比较规则如下:
a. 旧虚拟DOM中找到了与新虚拟DOM相同的key:
(1).若虚拟DOM中内容没变, 直接使用之前的真实DOM
(2).若虚拟DOM中内容变了, 则生成新的真实DOM,随后替换掉页面中之前的真实DOM
b. 旧虚拟DOM中未找到与新虚拟DOM相同的key
根据数据创建新的真实DOM,随后渲染到到页面
2. 用index作为key可能会引发的问题:
1. 若对数据进行:逆序添加、逆序删除等破坏顺序操作:
会产生没有必要的真实DOM更新 ==> 界面效果没问题, 但效率低。
2. 如果结构中还包含输入类的DOM:
会产生错误DOM更新 ==> 界面有问题。
3. 注意!如果不存在对数据的逆序添加、逆序删除等破坏顺序操作,
仅用于渲染列表用于展示,使用index作为key是没有问题的。
以上就是React Diff原理深入分析的详细内容,更多关于React Diff原理的资料请关注靠谱客其它相关文章!
最后
以上就是微笑楼房最近收集整理的关于React Diff原理深入分析的全部内容,更多相关React内容请搜索靠谱客的其他文章。








发表评论 取消回复