前言
一直想好好学习一下Python爬虫,之前断断续续的把Python基础学了一下,悲剧的是学的没有忘的快。只能再次拿出来滤了一遍,趁热打铁,通过实例来实践下,下面这篇文章主要介绍了关于Python2下载单张图片与爬取网页的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧。
一、需求分析
1、知道图片的url地址,将图片下载到本地。
2、知道网页地址,将图片列表中的图片全部下载到本地。
二、准备工作
1、开发系统:win7 64位。
2、开发环境:python2.7。
3、开发工具:PyCharm。
4、浏览器:Chrome。
三、操作步骤
A.知道图片的url地址,将图片下载到本地。
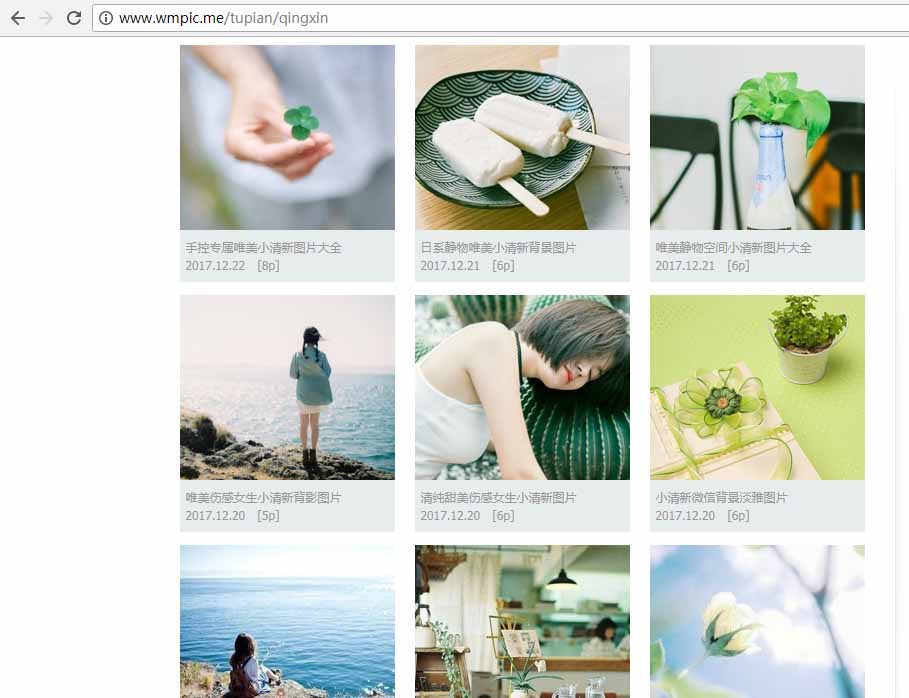
a1、打开Chrome,随意找到一个图片网站。
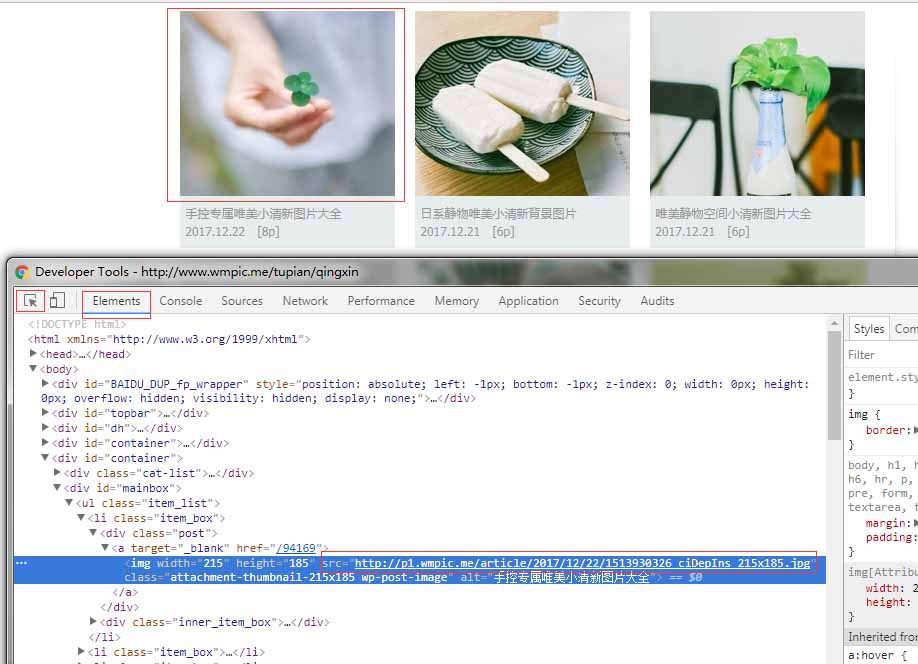
a2、打开开发者工具(f12键或者fn+f12键),选择第一张图片,可以看到它的src属性就是图片的地址,复制出来。
a3、编写代码。这里需要引用urllib库以及使用Python IO相关的知识。
# -*- coding:utf-8 -* ''' 知道图片地址,下载图片到本地 ''' import urllib #图片url地址 url = 'http://p1.wmpic.me/article/2017/12/22/1513930326_ciDepIns_215x185.jpg' #方法一 #获取图片数据 res = urllib.urlopen(url).read() #文件要保存的路径名和文件名 path = "e:\dlimg\pic2.jpg" #使用io写入图片 f = open(path , "wb") f.write(res) f.close() #方法二 res2 = urllib.urlretrieve(url , 'e:\dlimg\pic3.jpg')
B.知道网页地址,将图片列表中的图片全部下载到本地。
b1、还是以上面的网页为爬取对象,在该网页下,图片列表中有30张照片,获取每张图片的src属性值,再来下载即可。
b2、利用BeautifulSoup解析网页,利用标签选择器获取每张图片的src属性值。
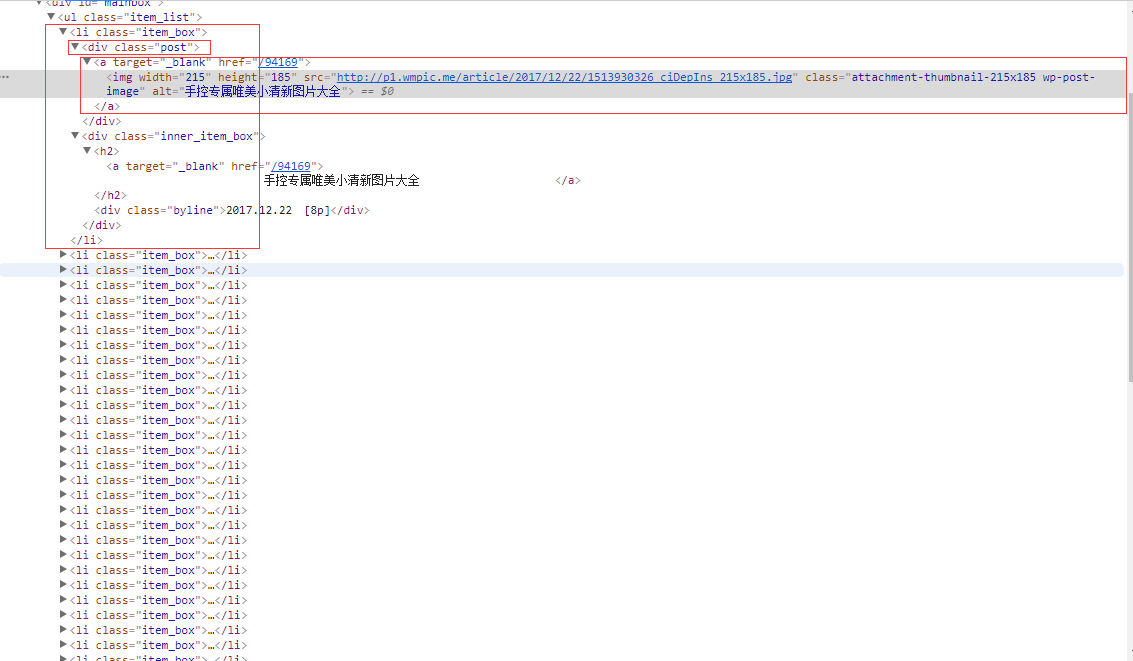
b3、编写代码。
# -*- coding: utf-8 -*-
import requests
import urllib
from bs4 import BeautifulSoup
url = 'http://www.wmpic.me/tupian/qingxin'
res = requests.get(url)
#使用BeautifulSoup解析网页
soup = BeautifulSoup(res.text , 'html.parser')
#通过标签选择器定位到图片位置(与css选择器差不多)
pic_list = soup.select('.item_box .post a img')
i = 0
for img_url in pic_list:
#获取每个img标签的src属性
url_list = img_url['src']
#保存路径,后面是文件名
save_path = 'E:\dlimg\\'+'downloadpic_'+str(i)+'.jpg'
#解析图片,写入到本地
pic_file = urllib.urlopen(url_list).read()
f = open(save_path, "wb")
f.write(pic_file)
f.close()
i = i+1
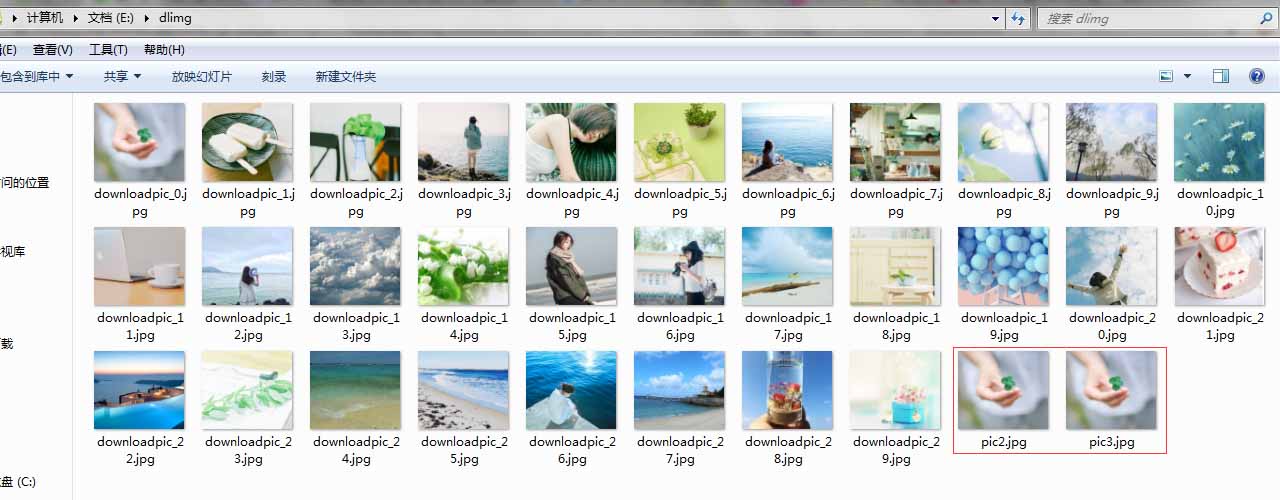
C.运行结果(红色框中pic2.jpg和pic3.jpg是A步骤运行结果,其余以downloadpic_*.jpg命名的图片是步骤B的运行结果)
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对脚本之家的支持。
最后
以上就是无奈花生最近收集整理的关于利用Python2下载单张图片与爬取网页图片实例代码的全部内容,更多相关利用Python2下载单张图片与爬取网页图片实例代码内容请搜索靠谱客的其他文章。








发表评论 取消回复