前言:
作为一名从小就看篮球的球迷,会经常逛虎扑篮球及湿乎乎等论坛,在论坛里面会存在很多精美图片,包括NBA球队、CBA明星、花边新闻、球鞋美女等等,如果一张张右键另存为的话真是手都点疼了。作为程序员还是写个程序来进行吧!
所以我通过Python+Selenium+正则表达式+urllib2进行海量图片爬取。
运行效果:
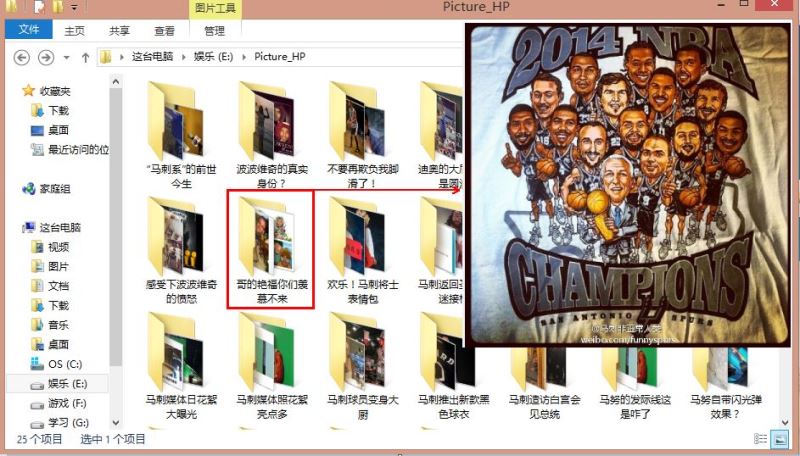
http://photo.hupu.com/nba/tag/马刺
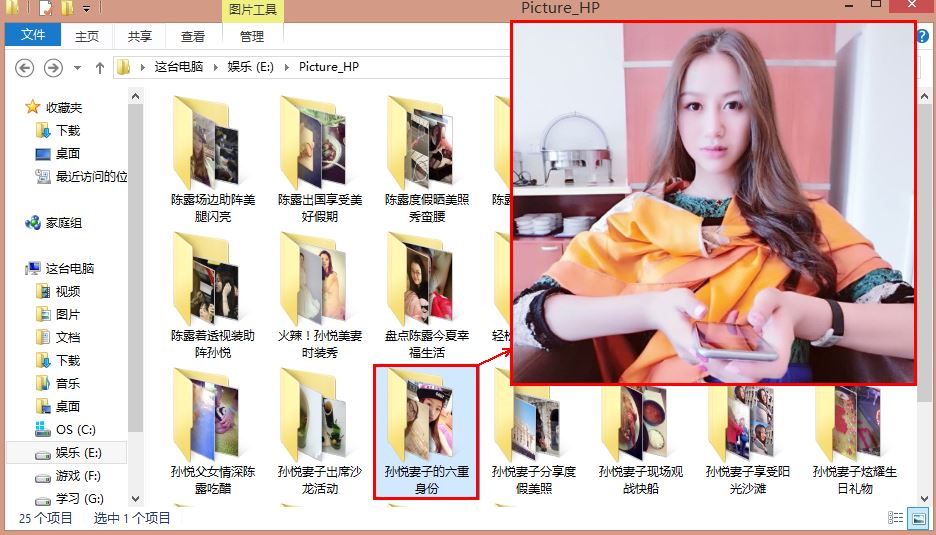
http://photo.hupu.com/nba/tag/陈露
源代码:
# -*- coding: utf-8 -*-
"""
Crawling pictures by selenium and urllib
url: 虎扑 马刺 http://photo.hupu.com/nba/tag/%E9%A9%AC%E5%88%BA
url: 虎扑 陈露 http://photo.hupu.com/nba/tag/%E9%99%88%E9%9C%B2
Created on 2015-10-24
@author: Eastmount CSDN
"""
import time
import re
import os
import sys
import urllib
import shutil
import datetime
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
#Open PhantomJS
driver = webdriver.PhantomJS(executable_path="G:\phantomjs-1.9.1-windows\phantomjs.exe")
#driver = webdriver.Firefox()
wait = ui.WebDriverWait(driver,10)
#Download one Picture By urllib
def loadPicture(pic_url, pic_path):
pic_name = os.path.basename(pic_url) #删除路径获取图片名字
pic_name = pic_name.replace('*','') #去除'*' 防止错误 invalid mode ('wb') or filename
urllib.urlretrieve(pic_url, pic_path + pic_name)
#爬取具体的图片及下一张
def getScript(elem_url, path, nums):
try:
#由于链接 http://photo.hupu.com/nba/p29556-1.html
#只需拼接 http://..../p29556-数字.html 省略了自动点击"下一张"操作
count = 1
t = elem_url.find(r'.html')
while (count <= nums):
html_url = elem_url[:t] + '-' + str(count) + '.html'
#print html_url
'''
driver_pic.get(html_url)
elem = driver_pic.find_element_by_xpath("//div[@class='pic_bg']/div/img")
url = elem.get_attribute("src")
'''
#采用正则表达式获取第3个<div></div> 再获取图片URL进行下载
content = urllib.urlopen(html_url).read()
start = content.find(r'<div class="flTab">')
end = content.find(r'<div class="comMark" style>')
content = content[start:end]
div_pat = r'<div.*?>(.*?)<\/div>'
div_m = re.findall(div_pat, content, re.S|re.M)
#print div_m[2]
link_list = re.findall(r"(?<=href=\").+?(?=\")|(?<=href=\').+?(?=\')", div_m[2])
#print link_list
url = link_list[0] #仅仅一条url链接
loadPicture(url, path)
count = count + 1
except Exception,e:
print 'Error:',e
finally:
print 'Download ' + str(count) + ' pictures\n'
#爬取主页图片集的URL和主题
def getTitle(url):
try:
#爬取URL和标题
count = 0
print 'Function getTitle(key,url)'
driver.get(url)
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='piclist3']"))
print 'Title: ' + driver.title + '\n'
#缩略图片url(此处无用) 图片数量 标题(文件名) 注意顺序
elem_url = driver.find_elements_by_xpath("//a[@class='ku']/img")
elem_num = driver.find_elements_by_xpath("//div[@class='piclist3']/table/tbody/tr/td/dl/dd[1]")
elem_title = driver.find_elements_by_xpath("//div[@class='piclist3']/table/tbody/tr/td/dl/dt/a")
for url in elem_url:
pic_url = url.get_attribute("src")
html_url = elem_title[count].get_attribute("href")
print elem_title[count].text
print html_url
print pic_url
print elem_num[count].text
#创建图片文件夹
path = "E:\\Picture_HP\\" + elem_title[count].text + "\\"
m = re.findall(r'(\w*[0-9]+)\w*', elem_num[count].text) #爬虫图片张数
nums = int(m[0])
count = count + 1
if os.path.isfile(path): #Delete file
os.remove(path)
elif os.path.isdir(path): #Delete dir
shutil.rmtree(path, True)
os.makedirs(path) #create the file directory
getScript(html_url, path, nums) #visit pages
except Exception,e:
print 'Error:',e
finally:
print 'Find ' + str(count) + ' pages with key\n'
#Enter Function
def main():
#Create Folder
basePathDirectory = "E:\\Picture_HP"
if not os.path.exists(basePathDirectory):
os.makedirs(basePathDirectory)
#Input the Key for search str=>unicode=>utf-8
key = raw_input("Please input a key: ").decode(sys.stdin.encoding)
print 'The key is : ' + key
#Set URL List Sum:1-2 Pages
print 'Ready to start the Download!!!\n\n'
starttime = datetime.datetime.now()
num=1
while num<=1:
#url = 'http://photo.hupu.com/nba/tag/%E9%99%88%E9%9C%B2?p=2&o=1'
url = 'http://photo.hupu.com/nba/tag/%E9%A9%AC%E5%88%BA'
print '第'+str(num)+'页','url:'+url
#Determine whether the title contains key
getTitle(url)
time.sleep(2)
num = num + 1
else:
print 'Download Over!!!'
#get the runtime
endtime = datetime.datetime.now()
print 'The Running time : ',(endtime - starttime).seconds
main()
代码解析:
源程序主要步骤如下:
1.入口main函数中,在E盘下创建图片文件夹Picture_HP,然后输入图集url,本打算输入tag来进行访问的,因为URL如下:
http://photo.hupu.com/nba/tag/马刺
但是解析URL中文总是错误,故改成输入URL,这不影响大局。同时你可能发现了代码中while循环条件为num<=1,它只执行一次,建议需要下载哪页图集,就赋值URL即可。但是虎扑的不同页链接如下,通过分析URL拼接也是可以实现循环获取所有页的。
http://photo.hupu.com/nba/tag/%E9%99%88%E9%9C%B2?p=2&o=1
2.调用getTitle(rul)函数,通过Selenium和Phantomjs分析HTML的DOM结构,通过find_elements_by_xpath函数获取原图路径URL、图集的主题和图片数量。如图:
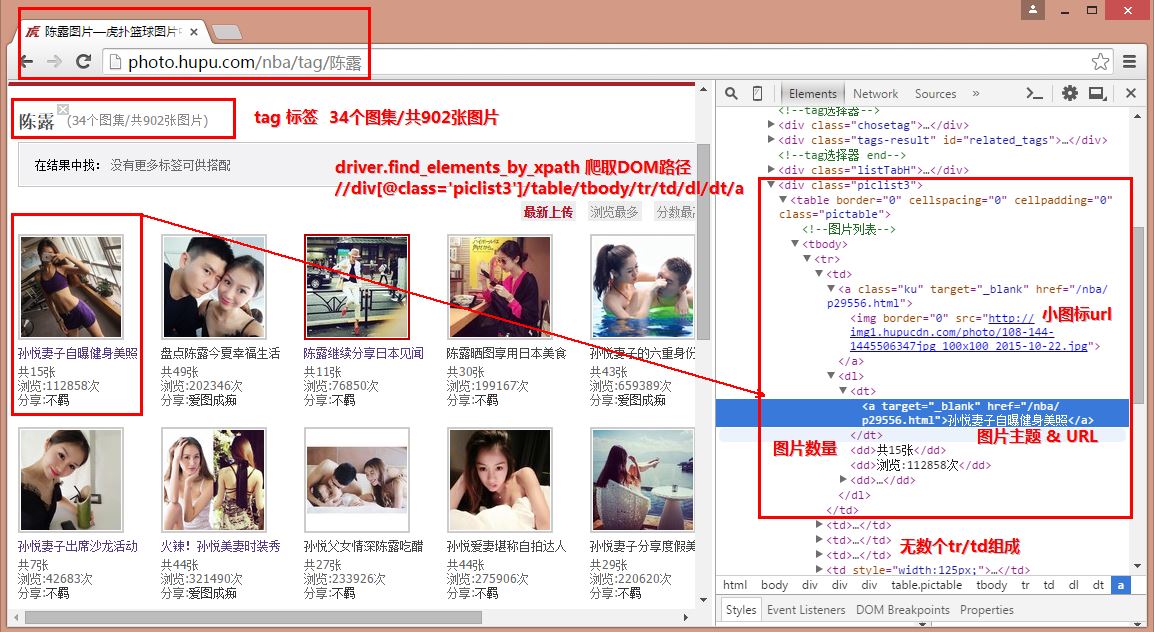
通过该函数即可获取每个图集的主题、URL及图片个数,同时根据图集主题创建相应的文件夹,代码中涉及正则表达式获取图片数量,从"共19张"到数字"19"。如图:
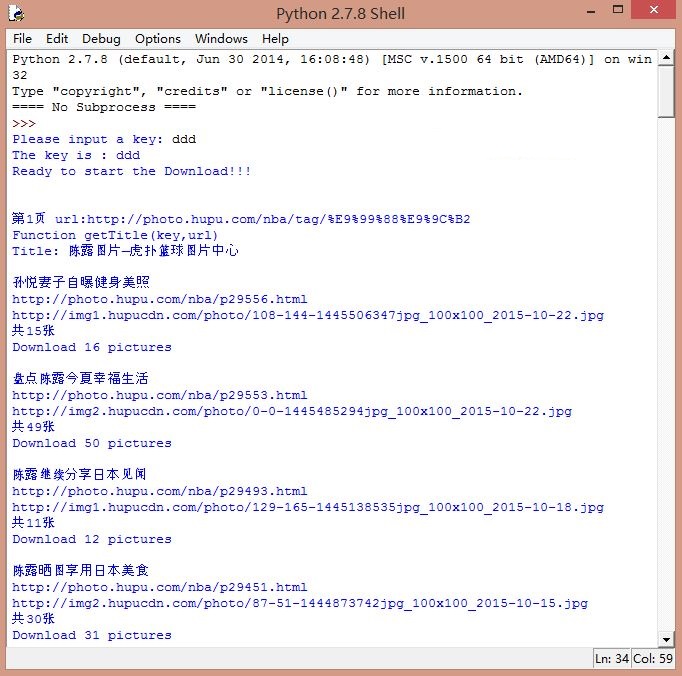
3.再调用函数getScript(elem_url, path, nums),参数分别是图片url、保存路径和图片数量。那么如何获取下一张图片的URL呢?
当通过步骤二爬取了图集URL,如:http://photo.hupu.com/nba/p29556.html
(1).如果是通过Ajax、JavaScript动态加载的图片,url无规律则需要调用Selenium动态模拟鼠标操作点击“下一张”来获取原图url;
(2).但很多网站都会存在一些规律,如虎扑的第九张图片链接如下,通过URL字符串分割处理即可实现:"p29556-"+"数字"+".html"即可。
http://photo.hupu.com/nba/p29556-9.html
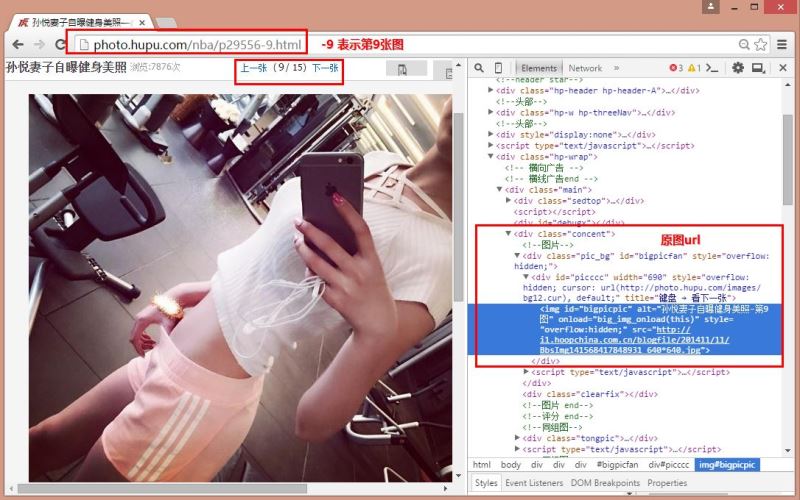
在该函数中,我第一次也是通过Selenium分析HTML结构获取原始图片url,但每张图片都需要调用一次Phantomjs无界面浏览器,这速度太慢了。故该成了正则表达式获取HTML中的原图URL,其原因如下图:
虎扑又偷懒了,它在下面定义了原图链接,直接获取即可。
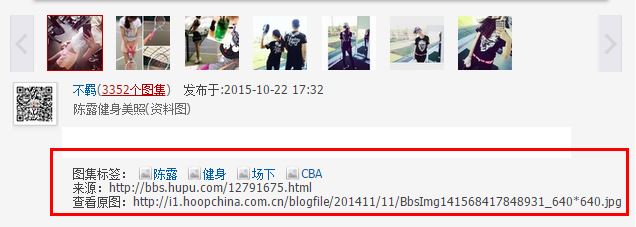
4.最后一步即urllib.urlretrieve(pic_url, pic_path + pic_name)下载图片即可。
当然你可能会遇到错误“Error: [Errno 22] invalid mode ('wb') or filename”,参考 stackoverflow

总结:
这是一篇讲述Selenium和Python爬取虎扑图集的文章,文章内容算是爬虫里面比较基础的,其中下载的“陈露”图片和网站给出的34个图集、902张图片一样。同时采用正则后时间估计3分钟左右,很快~当然,虎扑里面的标签很多,足球应该也是类似,只要修改URL即可下载图集,非常之方便。
以上就是本文关于python爬虫系列Selenium定向爬取虎扑篮球图片详解的全部内容,希望对大家有所帮助。感兴趣的朋友可以继续参阅本站:
Python爬虫实例爬取网站搞笑段子
Python探索之爬取电商售卖信息代码示例
python中requests爬去网页内容出现乱码问题解决方法介绍
如有不足之处,欢迎留言指出。
最后
以上就是俭朴棒球最近收集整理的关于python爬虫系列Selenium定向爬取虎扑篮球图片详解的全部内容,更多相关python爬虫系列Selenium定向爬取虎扑篮球图片详解内容请搜索靠谱客的其他文章。








发表评论 取消回复