初衷
首先说明一下既然网上有那么多教程为什么要还要写这样一个安装教程呢?网上教程虽然多,但是有些教程比较老,许多教程忽略许多安装过程中的细节,比如添加用户的权限,文件权限,小编在安装过程遇到许多这样的问题所以想写一篇完整的教程,希望对初学Hadoop的人有一个直观的了解,我们接触真集群的机会比较少,虚拟机是个不错的选择,可以基本完全模拟真实的情况,前提是你的电脑要配置相对较好不然跑起来都想死,废话不多说。
环境说明
本文使用VMware® Workstation 12 Pro虚拟机创建并安装三台Ubuntu16.04系统分别命名为master、slave1、slave2对应对应NameNode、DataNode、DataNode。
安装过程中要求三个系统中配置基本相同除个别配置(比如:节点的命名)
192.168.190.128 master
192.168.190.129 slave1
192.168.190.131 slave2
在虚拟机Linux上安装与配置Hadoop
需要说明的是下面的所有配置三台Ubuntu系统都要配置而且是基本一样,为了使配置一致,先在一台机器上配置然后将对应配置scp到其他机器上
虚拟机的安装不是本文重点,这里就不赘述了。安装之后是这样的:

在Linux上安装Hadoop之前,需要安装两个程序:
1)JDK1.6(或更高版本),本文采用JDK 1.7。Hadoop是Java编写的程序,Hadoop的编译及MapReduce都需要使用JDK。因此,在安装Hadoop前,必须安装JDK1.6或更高版本。
2)SSH(安装外壳协议),推荐安装OpenSSH.Hadoop需要通过SSH来启动Slave列表中各台机器的守护进程,因此SSH也是必须安装的,即使是安装伪分布版本(因为Hadoop并没有区分集群式和伪分布式)。对于伪分布式,Hadoop会采用与集群相同处理方式,即按次序启动文件conf/slaves中记载的主机上的进程,只不过在伪分布式中Slave为localhost(即本身),所以对于伪分布式Hadoop,SSH也是一样必须的。
部署步骤
添加一个hadoop用户,并赋予相应权利,我们接下来hadoop Hbase的安装都要在hadoop用户下操作,所以hadoop用户要将hadoop的文件权限以及文件所有者赋予给hadoop用户。
1.每个虚拟机系统上都添加 hadoop 用户,并添加到 sudoers
sudo adduser hadoop
sudo gedit /etc/sudoers
找到对应添加如下:
# User privilege specification root ALL=(ALL:ALL) ALL hadoop ALL=(ALL:ALL) ALL
2.切换到 hadoop 用户:
su hadoop
3.修改 /etc/hostname 主机名为 master
当然master虚拟机设置为master
其他两个虚拟机分别设置为slave1、slave2
4.、修改 /etc/hosts
127.0.0.1 localhost 127.0.1.1 localhost.localdomain localhost 192.168.190.128 master 192.168.190.129 slave1 192.168.190.131 slave2 # The following lines are desirable for IPv6 capable hosts ::1 ip6-localhost ip6-loopback fe00::0 ip6-localnet ff00::0 ip6-mcastprefix ff02::1 ip6-allnodes ff02::2 ip6-allrouters
5.安装JDK 1.7
(1)下载和安装JDK 1.7
jdk-7u76-linux-x64.tar.gz
使用tar命令
tar -zxvf jdk-7u76-linux-x64.tar.gz
将安装文件移动到JDK安装目录,本文JDK的安装目录为/usr/lib/jvm/jdk1.7.0_76
(2)配置环境变量
输入命令:
sudo gedit /etc/profile
输入密码,打开profile文件。在最下面输入如下内容:
#set java environment
export JAVA_HOME=/usr/lib/jvm/jdk1.7.0_76
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:/home/hadoop/hadoop-2.7.1/bin:/home/hadoop/hadoop-2.7.1/sbin:/home/hadoop/hbase-1.2.4/bin:$PATH
需要说明的是可能profile文件当前权限是只读的,需要使用
sudo chmod 777 /etc/profile
命令修改文件读写权限。文件中已经包含了Hadoop以及Hbase的环境配置。
这一步的意义是配置环境变量,使系统可以找到JDK。
(4)验证JDK是否安装成功
输入命令:
java -version
会出现如下JDK版本信息:
java version "1.7.0_76" Java(TM) SE Runtime Environment (build 1.7.0_76-b13) Java HotSpot(TM) 64-Bit Server VM (build 24.76-b04, mixed mode)
如果出现上述JDK版本信息说明当前安装JDK并未设置成Ubuntu系统默认的JDK,接下来还需要手动将安装的JDK设置成系统默认的JDK。
(5)手动设置系统默认JDK
在终端依次输入命令:
sudo update-alternatives --install /usr/bin/java java /usr/lib/jvm/jdk1.7.0_76/bin/java 300
sudo update-alternatives --install /usr/bin/javac javac /usr/lib/jvm/jdk1.7.0_76/bin/javac 300
sudo update-alternatives --config java
接下来输入java -version就可以看到所安装的JDK的版本信息了。
三台虚拟机都要安装Vmware Tools工具方便复制粘贴
6.配置SSH免密码登录
(1)确认已经连上互联网,然后输入命令:
sudo apt-get install ssh
(2)配置 master、slave1 和 slave2 节点可以通过 SSH 无密码互相访问
注意这里的所有操作都是在hadoop用户下操作的。
首先,查看下hadoop用户下是否存在.ssh文件夹(注意ssh文件前面有”.”这是一个隐藏文件夹),输入命令:
ls -a -l
可以得到
drwxr-xr-x 9 root root 4096 Feb 1 02:41 . drwxr-xr-x 4 root root 4096 Jan 27 01:50 .. drwx------ 3 root root 4096 Jan 31 03:35 .cache drwxr-xr-x 5 root root 4096 Jan 31 03:35 .config drwxrwxrwx 11 hadoop root 4096 Feb 1 00:18 hadoop-2.7.1 drwxrwxrwx 8 hadoop root 4096 Feb 1 02:47 hbase-1.2.4 drwxr-xr-x 3 root root 4096 Jan 31 03:35 .local drwxr-xr-x 2 root root 4096 Jan 31 14:47 software drwxr-xr-x 2 hadoop root 4096 Feb 1 00:01 .ssh
一般来说,安装SSH时会自动在当前用户下创建这个隐藏文件夹,如果没有,可以手动创建一个。
sudo mkdir .ssh
注意这里的.ssh要是hadoop权限拥有,如果是root的话,使用下面命令:
sudo chown -R hadoop .ssh
接下来,输入命令:
ssh-keygen -t rsa
如果没有权限前面加一个sudo.
执行完可以看到一个图标并在.ssh文件下创建两个文件:id_rsa和id_rsa.pub
cat ~/ssh/id_rsa.pub >> ~/ssh/authorized_keys
在Ubuntu中,~代表单前用户文件夹,此处即/home/hadoop。
这表命令的功能是把公钥加到用于认证的公钥文件中,这里的authorized_keys是用于认证的公钥文件。
然后使用命令:
sudo gedit authorized_keys
打开对应虚拟机生成的密码,如master主机的hadoop用户生成了hadoop@master,将其他主机生成的秘钥添加到master主机的authorized_keys文件的末尾,这样master主机就拥有slave1的hadoop用户以及slave2的hadoop用户的秘钥了。
如下:
不要复制我的,复制我的没用,我这里只是实例一下,复制你自己的三台虚拟机各自生成的秘钥
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC743oCP2Voa3deHBkA+N7cYJC4Jv2Tj8Z6tGVWCxg0NJl3yKwYIfgC9RiyFyRWcl5byI34Oe7dYtf+9UtvH85hca1/IDP1m02NLPXsIJmcPS4uNgMLfsWg/F/C3Bqut7i4t6eHwO/FRhjeIBu5O/9GHoXk/ykhgJIbyh8hhAlcke6Jtt80I63r2+3DnlHlNzw1sQRJp2qFRgyV61j5DfuYrhfd+/eTkFtXc7izLVCkC7x6hMo4qIMQ0GbSx9iqTO0tO1skGYLhCX3Cbo3hf4i19RUKt168eg/X2l1qIvf+vgxQudM3lZa9/pxDieK5p8c8xupcaoR67jMFLWLl3EUb hadoop@master ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDQ1Jf6ds9Y+KlQNIHq+pDGxM1OsF+RSXcgLDdlzw+qGK7NT28bRK6QUCm3kJqa/ekEkqDHdWegtiQVriOsY4A2fABkRsjiOrnc4QYQ/rqB06JuvshwToB91qwmV/J/o3mgsentJLfmBUpSyW8rRxQV+tYtqQ+gipL7x0WGUBRQYRhJJZKAxqgLGE3Md/siYjn8Ge4G31rrTcx9QDVcfTCtHkvqca0b0f98Y+U9Fu6w4Ari28oLxFTlzuCsebIPMzE4uWQuXT+2kMz0HunpejSDrLkrFqO1OKUs0peZrUVRmYBY5flt4tnV0XOQBYClzxieev/ppgH8AeB4Qs/zXB25 hadoop@slave1 ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDI8PpgXt94SAEtUhvt2JmlO4Ed11r1WLoN1Eha5vI3qqm7cgT4yS7lvxL53Dc5G7R0n4Jwsf2hTvD9JF77vEIxp5g3xQGa7HafbIMzQupuCyAHqY+v0RTepaBUNGkFz0uKv+Nq8bzjfSUv4HgRorW7Yzqaa0LjEvHiI8uVZA7dcZ6Ba1on/TlKVVzz3MdZulcn7+AzjTPTG8hPQaELQqws1UuIYIUanOSqFPCADart/pJpAzGkqek0LBRSvI+U+P0oSrz9aX3wVOUQknheinM4tmuo3TGYionjeV1jqroCxBbZaeqLLwnpA0YZBl/ZMnJHkeSITypmgZWszh3ylC8p hadoop@slave2
至此免密码登录主机已配置完毕。
(3)验证SSH是否已安装成功,以及是否可以免密码登录主机。
输入命令:
ssh -V
显示结果:
OpenSSH_7.2p2 Ubuntu-4ubuntu2.1, OpenSSL 1.0.2g 1 Mar 2016
输入命令:
ssh localhost
会有如下显示:
Welcome to Ubuntu 16.04 LTS (GNU/Linux 4.4.0-21-generic x86_64) * Documentation: https://help.ubuntu.com/ 458 packages can be updated. 171 updates are security updates. The programs included with the Ubuntu system are free software; the exact distribution terms for each program are described in the individual files in /usr/share/doc/*/copyright. Ubuntu comes with ABSOLUTELY NO WARRANTY, to the extent permitted by applicable law. The programs included with the Ubuntu system are free software; the exact distribution terms for each program are described in the individual files in /usr/share/doc/*/copyright. Ubuntu comes with ABSOLUTELY NO WARRANTY, to the extent permitted by applicable law. Last login: Wed Feb 1 00:02:53 2017 from 127.0.0.1 To run a command as administrator (user "root"), use "sudo <command>". See "man sudo_root" for details.
这说明已经安装成功,第一次登录会询问是否继续链接,输入yes即可以进入。
实际上,在Hadoop的安装过程中,是否免密码登录是无关紧要的,但是如果不配置免密码登录,每次启动Hadoop都需要输入密码以登录到每台机器的DataNode上,考虑到一般的Hadoop集群动辄数百或者上千台机器,因此一般来说都会配置SSH免密码登录。
master 节点无密码访问 slave1 和 slave2 节点:
ssh slave1
运行结果:
Welcome to Ubuntu 16.04 LTS (GNU/Linux 4.4.0-59-generic x86_64) * Documentation: https://help.ubuntu.com/ 312 packages can be updated. 10 updates are security updates. The programs included with the Ubuntu system are free software; the exact distribution terms for each program are described in the individual files in /usr/share/doc/*/copyright. Ubuntu comes with ABSOLUTELY NO WARRANTY, to the extent permitted by applicable law. The programs included with the Ubuntu system are free software; the exact distribution terms for each program are described in the individual files in /usr/share/doc/*/copyright. Ubuntu comes with ABSOLUTELY NO WARRANTY, to the extent permitted by applicable law. Last login: Wed Feb 1 00:03:30 2017 from 192.168.190.131
不需要密码,需要密码说明没有配置成功,看看是不是哪步出现了问题。
安装并运行Hadoop
介绍Hadoop的安装之前,先介绍一下Hadoop对各个节点的角色定义。
Hadoop分别从三个角度将主机划分为两种角色。第一,最基本的划分为Master和Slave,即主人和奴隶;第二,从HDFS的角度,将主机划分为NameNode和DataNode(在分布式文件系统中,目录的管理很重要,管理目录相当于主任,而NameNode就是目录管理者);第三,从MapReduce角度,将主机划分为JobTracker和TaskTracker(一个Job经常被划分为多个Task,从这个角度不难理解它们之间的关系)。
Hadoop有三种运行方式:单机模式、伪分布与完全分布式。乍看之下,前两种并不能体现云计算的优势,但是它们便于程序的测试与调试,所以还是有意义的。
我的博客中有介绍单机模式和伪分布式方式这里就不赘述,本文主要着重介绍分布式方式配置。
(1)hadoop 用户目录下解压下载的hadoop-2.7.1.tar.gz
使用解压命令:
tar -zxvf hadoop-2.7.1.tar.gz
注意一下操作都是在hadoop用户下操作的也就是hadoop-2.7.1的所有者是hadoop.如下所示:
total 120 drwxr-xr-x 19 hadoop hadoop 4096 Feb 1 02:28 . drwxr-xr-x 4 root root 4096 Jan 31 14:24 .. -rw------- 1 hadoop hadoop 1297 Feb 1 03:37 .bash_history -rw-r--r-- 1 hadoop hadoop 220 Jan 31 14:24 .bash_logout -rw-r--r-- 1 hadoop hadoop 3771 Jan 31 14:24 .bashrc drwx------ 3 root root 4096 Jan 31 22:49 .cache drwx------ 5 root root 4096 Jan 31 23:59 .config drwx------ 3 root root 4096 Jan 31 23:59 .dbus drwxr-xr-x 2 hadoop hadoop 4096 Feb 1 00:55 Desktop -rw-r--r-- 1 hadoop hadoop 25 Feb 1 00:55 .dmrc drwxr-xr-x 2 hadoop hadoop 4096 Feb 1 00:55 Documents drwxr-xr-x 2 hadoop hadoop 4096 Feb 1 00:55 Downloads -rw-r--r-- 1 hadoop hadoop 8980 Jan 31 14:24 examples.desktop drwx------ 2 hadoop hadoop 4096 Feb 1 00:56 .gconf drwx------ 3 hadoop hadoop 4096 Feb 1 00:55 .gnupg drwxrwxrwx 11 hadoop hadoop 4096 Feb 1 00:30 hadoop-2.7.1 drwxrwxrwx 8 hadoop hadoop 4096 Feb 1 02:44 hbase-1.2.4 -rw------- 1 hadoop hadoop 318 Feb 1 00:56 .ICEauthority drwxr-xr-x 3 root root 4096 Jan 31 22:49 .local drwxr-xr-x 2 hadoop hadoop 4096 Feb 1 00:55 Music drwxr-xr-x 2 hadoop hadoop 4096 Feb 1 00:55 Pictures -rw-r--r-- 1 hadoop hadoop 675 Jan 31 14:24 .profile drwxr-xr-x 2 hadoop hadoop 4096 Feb 1 00:55 Public drwx------ 2 hadoop hadoop 4096 Feb 1 00:02 .ssh drwxr-xr-x 2 hadoop hadoop 4096 Feb 1 00:55 Templates drwxr-xr-x 2 hadoop hadoop 4096 Feb 1 00:55 Videos -rw------- 1 hadoop hadoop 51 Feb 1 00:55 .Xauthority -rw------- 1 hadoop hadoop 1492 Feb 1 00:58 .xsession-errors
(2)配置 hadoop 的环境变量
sudo gedit /etc/profile
配置如下:
#set java environment
export JAVA_HOME=/usr/lib/jvm/jdk1.7.0_76
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:/home/hadoop/hadoop-2.7.1/bin:/home/hadoop/hadoop-2.7.1/sbin:/home/hadoop/hbase-1.2.4/bin:$PATH
(3)配置三台主机的Hadoop文件,内容如下。
conf/Hadoop-env.sh:
/home/master/hadoop-2.7.1/etc/hadoop
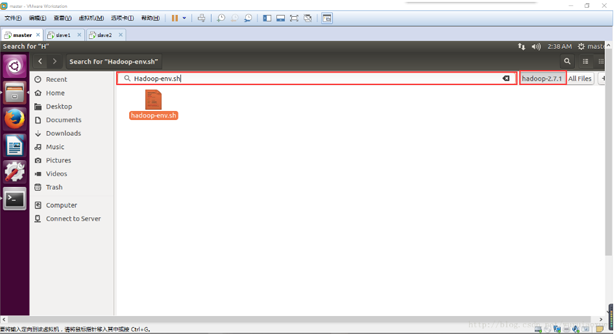
首先如何找到这个文件呢,使用Ubuntu的搜索工具如图所示:
这里写图片描述
# The java implementation to use. export JAVA_HOME=/usr/lib/jvm/jdk1.7.0_76 export HADOOP_HOME=/home/master/hadoop-2.7.1 export PATH=$PATH:/home/master/hadoop-2.7.1/bin
conf/core-site.xml
/home/master/hadoop-2.7.1/etc/hadoop
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>fs.default.name</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/tmp</value> </property> </configuration>
conf/hdfs-site.xml
/home/master/hadoop-2.7.1/etc/hadoop
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>dfs.replication</name> <value>2</value> </property> </configuration>
conf/mapred-site.xml
/home/master/hadoop-2.7.1/etc/hadoop
搜索发现没有这个文件需要复制mapred-site.xml.template这个文件的内容到mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
配置如下:
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>mapred.job.tracker</name> <value>master:9001</value> </property> </configuration>
conf/masters
/home/master/hadoop-2.7.1/etc/hadoop
没有手动添加一个master文件
配置如下:
master
conf/slaves:
slave1 slave2
(4) 向 slave1 和 slave2 节点复制 hadoop2.7.1 整个目录至相同的位置
进入hadoop@master节点hadoop目录下使用
scp -r hadoop-2.7.1 hadoop@slave1:~/ scp -r hadoop-2.7.1 hadoop@slave2:~/
(5)启动Hadoop
在hadoop@master节点上执行
hadoop@master:~$ hadoop namenode -format
如果提示:
hadoop: command not found
需要source一下环境变量文件
source /etc/profile
执行结果如下:
hadoop@master:~$ hadoop namenode -format DEPRECATED: Use of this script to execute hdfs command is deprecated. Instead use the hdfs command for it. 17/02/02 02:59:44 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = master/192.168.190.128 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.7.1 STARTUP_MSG: classpath = /home/hadoop/hadoop-2.7.1/etc/hadoop:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/log4j-1.2.17.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/jsr305-3.0.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/apacheds-i18n-2.0.0-M15.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/commons-cli-1.2.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/jaxb-impl-2.2.3-1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/commons-beanutils-1.7.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/asm-3.2.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/jaxb-api-2.2.2.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/java-xmlbuilder-0.4.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/commons-net-3.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/commons-io-2.4.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/servlet-api-2.5.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/protobuf-java-2.5.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/netty-3.6.2.Final.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/curator-recipes-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/jetty-util-6.1.26.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/slf4j-api-1.7.10.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/jackson-core-asl-1.9.13.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/commons-configuration-1.6.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/htrace-core-3.1.0-incubating.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/activation-1.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/paranamer-2.3.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/commons-digester-1.8.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/jettison-1.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/jetty-6.1.26.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/hamcrest-core-1.3.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/commons-lang-2.6.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/hadoop-auth-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/avro-1.7.4.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/api-util-1.0.0-M20.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/guava-11.0.2.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/jsch-0.1.42.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/gson-2.2.4.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/apacheds-kerberos-codec-2.0.0-M15.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/snappy-java-1.0.4.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/curator-client-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/hadoop-annotations-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/stax-api-1.0-2.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/commons-httpclient-3.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/httpclient-4.2.5.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/jersey-core-1.9.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/curator-framework-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/xz-1.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/commons-math3-3.1.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/commons-beanutils-core-1.8.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/jackson-jaxrs-1.9.13.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/xmlenc-0.52.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/commons-logging-1.1.3.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/jackson-xc-1.9.13.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/jets3t-0.9.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/api-asn1-api-1.0.0-M20.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/commons-compress-1.4.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/jackson-mapper-asl-1.9.13.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/jsp-api-2.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/jersey-json-1.9.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/mockito-all-1.8.5.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/commons-codec-1.4.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/jersey-server-1.9.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/httpcore-4.2.5.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/commons-collections-3.2.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/zookeeper-3.4.6.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/junit-4.11.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/hadoop-common-2.7.1-tests.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/hadoop-nfs-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/hadoop-common-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/log4j-1.2.17.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/jsr305-3.0.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/commons-cli-1.2.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/asm-3.2.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/commons-io-2.4.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/servlet-api-2.5.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/protobuf-java-2.5.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/netty-3.6.2.Final.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/jetty-util-6.1.26.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/jackson-core-asl-1.9.13.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/xml-apis-1.3.04.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/htrace-core-3.1.0-incubating.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/netty-all-4.0.23.Final.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/jetty-6.1.26.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/xercesImpl-2.9.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/commons-lang-2.6.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/guava-11.0.2.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/jersey-core-1.9.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/xmlenc-0.52.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/commons-logging-1.1.3.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/commons-daemon-1.0.13.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/jackson-mapper-asl-1.9.13.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/commons-codec-1.4.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/leveldbjni-all-1.8.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/jersey-server-1.9.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/hadoop-hdfs-2.7.1-tests.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/hadoop-hdfs-nfs-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/hadoop-hdfs-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/log4j-1.2.17.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/jsr305-3.0.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/commons-cli-1.2.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/jaxb-impl-2.2.3-1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/asm-3.2.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/jaxb-api-2.2.2.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/commons-io-2.4.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/servlet-api-2.5.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/protobuf-java-2.5.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/netty-3.6.2.Final.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/jetty-util-6.1.26.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/jackson-core-asl-1.9.13.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/activation-1.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/jersey-guice-1.9.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/jettison-1.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/jetty-6.1.26.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/commons-lang-2.6.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/jersey-client-1.9.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/guava-11.0.2.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/aopalliance-1.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/guice-3.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/stax-api-1.0-2.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/jersey-core-1.9.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/xz-1.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/zookeeper-3.4.6-tests.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/jackson-jaxrs-1.9.13.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/commons-logging-1.1.3.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/javax.inject-1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/jackson-xc-1.9.13.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/commons-compress-1.4.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/jackson-mapper-asl-1.9.13.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/guice-servlet-3.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/jersey-json-1.9.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/commons-codec-1.4.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/leveldbjni-all-1.8.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/jersey-server-1.9.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/commons-collections-3.2.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/zookeeper-3.4.6.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/hadoop-yarn-api-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/hadoop-yarn-server-common-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/hadoop-yarn-applications-unmanaged-am-launcher-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/hadoop-yarn-server-resourcemanager-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/hadoop-yarn-registry-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/hadoop-yarn-server-nodemanager-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/hadoop-yarn-applications-distributedshell-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/hadoop-yarn-server-web-proxy-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/hadoop-yarn-server-sharedcachemanager-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/hadoop-yarn-client-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/hadoop-yarn-server-applicationhistoryservice-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/hadoop-yarn-server-tests-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/hadoop-yarn-common-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/log4j-1.2.17.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/asm-3.2.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/commons-io-2.4.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/protobuf-java-2.5.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/netty-3.6.2.Final.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/jackson-core-asl-1.9.13.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/paranamer-2.3.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/jersey-guice-1.9.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/hamcrest-core-1.3.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/avro-1.7.4.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/aopalliance-1.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/guice-3.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/snappy-java-1.0.4.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/hadoop-annotations-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/jersey-core-1.9.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/xz-1.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/javax.inject-1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/commons-compress-1.4.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/jackson-mapper-asl-1.9.13.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/guice-servlet-3.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/leveldbjni-all-1.8.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/jersey-server-1.9.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/junit-4.11.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-plugins-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/hadoop-mapreduce-client-shuffle-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/hadoop-mapreduce-client-app-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.1-tests.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.1.jar:/home/master/hadoop-2.7.1/contrib/capacity-scheduler/*.jar:/home/master/hadoop-2.7.1/contrib/capacity-scheduler/*.jar STARTUP_MSG: build = https://git-wip-us.apache.org/repos/asf/hadoop.git -r 15ecc87ccf4a0228f35af08fc56de536e6ce657a; compiled by 'jenkins' on 2015-06-29T06:04Z STARTUP_MSG: java = 1.7.0_76 ************************************************************/ 17/02/02 02:59:44 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT] 17/02/02 02:59:44 INFO namenode.NameNode: createNameNode [-format] Formatting using clusterid: CID-ef219bd8-5622-49d9-b501-6370f3b5fc73 17/02/02 03:00:03 INFO namenode.FSNamesystem: No KeyProvider found. 17/02/02 03:00:03 INFO namenode.FSNamesystem: fsLock is fair:true 17/02/02 03:00:04 INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit=1000 17/02/02 03:00:04 INFO blockmanagement.DatanodeManager: dfs.namenode.datanode.registration.ip-hostname-check=true 17/02/02 03:00:04 INFO blockmanagement.BlockManager: dfs.namenode.startup.delay.block.deletion.sec is set to 000:00:00:00.000 17/02/02 03:00:04 INFO blockmanagement.BlockManager: The block deletion will start around 2017 Feb 02 03:00:04 17/02/02 03:00:04 INFO util.GSet: Computing capacity for map BlocksMap 17/02/02 03:00:04 INFO util.GSet: VM type = 64-bit 17/02/02 03:00:04 INFO util.GSet: 2.0% max memory 966.7 MB = 19.3 MB 17/02/02 03:00:04 INFO util.GSet: capacity = 2^21 = 2097152 entries 17/02/02 03:00:04 INFO blockmanagement.BlockManager: dfs.block.access.token.enable=false 17/02/02 03:00:04 INFO blockmanagement.BlockManager: defaultReplication = 2 17/02/02 03:00:04 INFO blockmanagement.BlockManager: maxReplication = 512 17/02/02 03:00:04 INFO blockmanagement.BlockManager: minReplication = 1 17/02/02 03:00:04 INFO blockmanagement.BlockManager: maxReplicationStreams = 2 17/02/02 03:00:04 INFO blockmanagement.BlockManager: shouldCheckForEnoughRacks = false 17/02/02 03:00:04 INFO blockmanagement.BlockManager: replicationRecheckInterval = 3000 17/02/02 03:00:04 INFO blockmanagement.BlockManager: encryptDataTransfer = false 17/02/02 03:00:04 INFO blockmanagement.BlockManager: maxNumBlocksToLog = 1000 17/02/02 03:00:04 INFO namenode.FSNamesystem: fsOwner = hadoop (auth:SIMPLE) 17/02/02 03:00:04 INFO namenode.FSNamesystem: supergroup = supergroup 17/02/02 03:00:04 INFO namenode.FSNamesystem: isPermissionEnabled = true 17/02/02 03:00:04 INFO namenode.FSNamesystem: HA Enabled: false 17/02/02 03:00:04 INFO namenode.FSNamesystem: Append Enabled: true 17/02/02 03:00:05 INFO util.GSet: Computing capacity for map INodeMap 17/02/02 03:00:05 INFO util.GSet: VM type = 64-bit 17/02/02 03:00:05 INFO util.GSet: 1.0% max memory 966.7 MB = 9.7 MB 17/02/02 03:00:05 INFO util.GSet: capacity = 2^20 = 1048576 entries 17/02/02 03:00:05 INFO namenode.FSDirectory: ACLs enabled? false 17/02/02 03:00:05 INFO namenode.FSDirectory: XAttrs enabled? true 17/02/02 03:00:05 INFO namenode.FSDirectory: Maximum size of an xattr: 16384 17/02/02 03:00:05 INFO namenode.NameNode: Caching file names occuring more than 10 times 17/02/02 03:00:05 INFO util.GSet: Computing capacity for map cachedBlocks 17/02/02 03:00:05 INFO util.GSet: VM type = 64-bit 17/02/02 03:00:05 INFO util.GSet: 0.25% max memory 966.7 MB = 2.4 MB 17/02/02 03:00:05 INFO util.GSet: capacity = 2^18 = 262144 entries 17/02/02 03:00:05 INFO namenode.FSNamesystem: dfs.namenode.safemode.threshold-pct = 0.9990000128746033 17/02/02 03:00:05 INFO namenode.FSNamesystem: dfs.namenode.safemode.min.datanodes = 0 17/02/02 03:00:05 INFO namenode.FSNamesystem: dfs.namenode.safemode.extension = 30000 17/02/02 03:00:05 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10 17/02/02 03:00:05 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10 17/02/02 03:00:05 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25 17/02/02 03:00:05 INFO namenode.FSNamesystem: Retry cache on namenode is enabled 17/02/02 03:00:05 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis 17/02/02 03:00:06 INFO util.GSet: Computing capacity for map NameNodeRetryCache 17/02/02 03:00:06 INFO util.GSet: VM type = 64-bit 17/02/02 03:00:06 INFO util.GSet: 0.029999999329447746% max memory 966.7 MB = 297.0 KB 17/02/02 03:00:06 INFO util.GSet: capacity = 2^15 = 32768 entries Re-format filesystem in Storage Directory /tmp/dfs/name ? (Y or N) y 17/02/02 03:00:28 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1867851271-192.168.190.128-1485975628037 17/02/02 03:00:28 INFO common.Storage: Storage directory /tmp/dfs/name has been successfully formatted. 17/02/02 03:00:29 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 17/02/02 03:00:29 INFO util.ExitUtil: Exiting with status 0 17/02/02 03:00:29 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at master/192.168.190.128 ************************************************************/
说明初始格式化文件系统成功!
启动Hadoop
注意启动Hadoop是在主节点上执行命令,其他节点不需要,主节点会自动按照文件配置启动从节点
hadoop@master:~$ start-all.sh
执行结果如下:
hadoop@master:~$ start-all.sh This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh Starting namenodes on [master] master: starting namenode, logging to /home/hadoop/hadoop-2.7.1/logs/hadoop-hadoop-namenode-master.out slave1: starting datanode, logging to /home/hadoop/hadoop-2.7.1/logs/hadoop-hadoop-datanode-slave1.out slave2: starting datanode, logging to /home/hadoop/hadoop-2.7.1/logs/hadoop-hadoop-datanode-slave2.out Starting secondary namenodes [0.0.0.0] 0.0.0.0: starting secondarynamenode, logging to /home/hadoop/hadoop-2.7.1/logs/hadoop-hadoop-secondarynamenode-master.out starting yarn daemons starting resourcemanager, logging to /home/hadoop/hadoop-2.7.1/logs/yarn-hadoop-resourcemanager-master.out slave1: starting nodemanager, logging to /home/hadoop/hadoop-2.7.1/logs/yarn-hadoop-nodemanager-slave1.out slave2: starting nodemanager, logging to /home/hadoop/hadoop-2.7.1/logs/yarn-hadoop-nodemanager-slave2.out
可以通过jps命令查看各个节点运行的进程查看运行是否成功。
master节点:
hadoop@master:~$ jps 11012 Jps 10748 ResourceManager 10594 SecondaryNameNode
slave1节点:
hadoop@slave1:~$ jps 7227 Jps 7100 NodeManager 6977 DataNode
slave2节点:
hadoop@slave2:~$ jps 6654 Jps 6496 NodeManager 6373 DataNode
你可以通过以下命令或者通过http://master:50070查看集群状态。
Hadoop dfsadmin -report
至此Haoop的安装配置已经全部讲完。
HBase的安装
HBase有三种运行模式,其中单机模式的配置非常简单,几乎不用对安装文件做任何修改就可以使用。如果要运行分布式模式,Hadoop是必不可少的。另外在对HBase的某些文件进行配置之前,需要具备一下先决条件也是我们刚才介绍Hadoop介绍过的。
(1)JDK
( 2 )Hadoop
( 3 )SSH
完全分布式模式安装
对于完全分布式安装HBase,我们需要通过hbase-site.xml文档来配置本机的HBase特性,通过hbase-env.sh来配置全局HBase集群系统的特性,也就是说每一台机器都可以通过hbase-env.sh来了解全局的HBase的某些特性。另外,各个HBase实例之间需要通过Zookeeper来进行通信,因此我们还需要维护一个(一组)Zookeeper系统。
首先通过查看下hbase文件的所有者和权限
ls -a -l
得到如下:
total 36 drwxr-xr-x 9 root root 4096 Feb 1 02:41 . drwxr-xr-x 4 root root 4096 Jan 27 01:50 .. drwx------ 3 root root 4096 Jan 31 03:35 .cache drwxr-xr-x 5 root root 4096 Jan 31 03:35 .config drwxrwxrwx 11 hadoop root 4096 Feb 1 00:18 hadoop-2.7.1 drwxrwxrwx 8 hadoop root 4096 Feb 1 02:47 hbase-1.2.4 drwxr-xr-x 3 root root 4096 Jan 31 03:35 .local drwxr-xr-x 2 root root 4096 Jan 31 14:47 software drwxr-xr-x 2 hadoop root 4096 Feb 1 00:01 .ssh
(1)conf/hbase-site.xml文件的配置
hbase.rootdir和hbase.cluster.distributed两个参数的配置对于HBase来说是必须的。我们通过hbase.rootdir来指定本台机器HBase的存储目录;通过hbase.cluster.distributed来说明其运行模式(true为全分布式模式,false为单机模式或伪分布式模式);另外hbase.master指定的是HBase的master位置,hbase.zookeeper.quorum指定的是Zookeeper集群的位置。如下所示为示例配置文档:
同样,通过Ubuntu的目录查找hbase-site.xml
/home/hadoop/hbase-1.2.4/conf
配置如下:
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- /** * * Licensed to the Apache Software Foundation (ASF) under one * or more contributor license agreements. See the NOTICE file * distributed with this work for additional information * regarding copyright ownership. The ASF licenses this file * to you under the Apache License, Version 2.0 (the * "License"); you may not use this file except in compliance * with the License. You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */ --> <configuration> <property> <name>hbase.rootdir</name> <value>hdfs://master:9000/hbase</value> <description>HBase Data storge directory</description> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> <description>Assign HBase run mode</description> </property> <property> <name>hbase.master</name> <value>hdfs://master:60000</value> <description>Assign Master position</description> </property> <property> <name>hbase.zookeeper.quorum</name> <value>master,slave1,slave2</value> <description>Assign Zookeeper cluster</description> </property> </configuration>
(2)conf/regionservers的配置
regionservers文件列出了所有运行HBase RegionServer CHRegion Server的机器。此文件的配置和Hadoop的slaves文件十分类似,每一行指定一台机器。当HBase启动的时候,会将此文件中列出的机器启动;同样,当HBase关闭的时候,也会同时自动读取文件并将所有机器关闭。
在我们配置中,HBase Master及HDFS NameNode运行在hostname为Master的机器上,HBase RegionServers运行在master、slave1、slave2上。根据上述配置,我们只需要将每台机器上HBase安装目录下的conf/regionservers文件的内容设置为:
/home/hadoop/hbase-1.2.4/conf
master slave1 slave2
另外,我们可以将HBase的Master和HRegionServer服务器分开。这样只需要在上述配置文件中删除master一行即可。
(3)Zookeeper配置
完全分布式的HBase集群需要Zookeeper实例运行,并且需要所有的HBase节点能够与Zookeeper实例通信。默认情况下HBase自身维护着一组默认的Zookeeper实例。不过,用户可以配置独立的Zookeeper实例,这样能够使HBase系统更加健壮。
conf/hbase-env.sh配置文档中HBASE_MANAGES_ZK的默认值为true,它表示HBase使用自身所带的Zookeeper实例。但是,该实例只能为单机或者伪分布式模式下的HBase提供服务。当安装完全分布模式时需要配置自己的Zookeeper实例。在HBase-site.xml文档中配置了hbase.zookeeper.quorum属性后,系统将有限使用该属性所指定的Zookeeper列表。此时,若HBASE_MANAGES_ZK变量值为true,那么在启动HBase时,Hbase将把Zookeeper作为自身的一部分运行,其对应进程为“HQuorumPeer”;若该变量值为false,那么在启动HBase之前必须首先手动运行hbase.zookeeper.quorum属性所指定的Zookeeper集群,其对应的进程显示为QuorumPeerMain.若将Zookeeper作为HBase的一部分来运行,那么关闭HBase时Zookeeper将被自动关闭,否则需要手动停止Zookeeper服务。
运行Hbase
运行之前,在hdfs文件系统中添加hbase目录:
hdfs dfs -mkdir hdfs://master:9000/hbase
执行start-hbase.sh
hadoop@master:~$ start-hbase.sh slave1: starting zookeeper, logging to /home/hadoop/hbase-1.2.4/logs/hbase-hadoop-zookeeper-slave1.out slave2: starting zookeeper, logging to /home/hadoop/hbase-1.2.4/logs/hbase-hadoop-zookeeper-slave2.out master: starting zookeeper, logging to /home/hadoop/hbase-1.2.4/logs/hbase-hadoop-zookeeper-master.out starting master, logging to /home/hadoop/hbase-1.2.4/logs/hbase-hadoop-master-master.out master: starting regionserver, logging to /home/hadoop/hbase-1.2.4/logs/hbase-hadoop-regionserver-master.out slave2: starting regionserver, logging to /home/hadoop/hbase-1.2.4/logs/hbase-hadoop-regionserver-slave2.out slave1: starting regionserver, logging to /home/hadoop/hbase-1.2.4/logs/hbase-hadoop-regionserver-slave1.out
在启动Hbase之后,用户可以通过下面命令进入HBase Shell之中:
hbase shell
成功进入之后,用户会看到如下所示:
hadoop@master:~$ hbase shell SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/home/hadoop/hbase-1.2.4/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] HBase Shell; enter 'help<RETURN>' for list of supported commands. Type "exit<RETURN>" to leave the HBase Shell Version 1.2.4, r67592f3d062743907f8c5ae00dbbe1ae4f69e5af, Tue Oct 25 18:10:20 CDT 2016 hbase(main):001:0>
进去HBase Shell输入status命令,如果看到如下结果,证明HBase安装成功。
hbase(main):009:0> status 1 active master, 0 backup masters, 3 servers, 0 dead, 0.6667 average load
输入list
hbase(main):010:0> list TABLE 0 row(s) in 0.3250 seconds => []
至此hbase安装已经全部讲完了,过程主要出现的问题是权限问题,如果hadoop文件放在root目录下,而在hadoop用户目录下会出现访问权限问题,访问hadoop目录权限不够也是问题,比如hadoop在/home/目录下,需要赋予相应权限,希望对初学hadoop,hbase的人有所帮助!
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
最后
以上就是洁净老虎最近收集整理的关于详解VMware12使用三台虚拟机Ubuntu16.04系统搭建hadoop-2的全部内容,更多相关详解VMware12使用三台虚拟机Ubuntu16内容请搜索靠谱客的其他文章。








发表评论 取消回复