爬虫与反爬虫,这相爱相杀的一对,简直可以写出一部壮观的斗争史。而在大数据时代,数据就是金钱,很多企业都为自己的网站运用了反爬虫机制,防止网页上的数据被爬虫爬走。然而,如果反爬机制过于严格,可能会误伤到真正的用户请求;如果既要和爬虫死磕,又要保证很低的误伤率,那么又会加大研发的成本。
简单低级的爬虫速度快,伪装度低,如果没有反爬机制,它们可以很快的抓取大量数据,甚至因为请求过多,造成服务器不能正常工作。
1、爬取过程中的302重定向
在爬取某个网站速度过快或者发出的请求过多的时候,网站会向你所在的客户端发送一个链接,需要你去验证图片。我在爬链家和拉钩网的过程中就曾经遇到过:
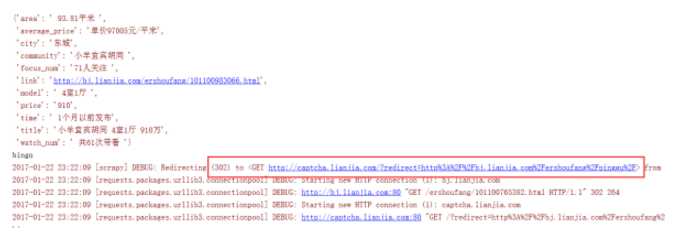
对于302重定向的问题,是由于抓取速度过快引起网络流量异常,服务器识别出是机器发送的请求,于是将请求返回链接定到某一特定链接,大多是验证图片或空链接。
在这种时候,既然已经被识别出来了,就使用代理ip再继续抓取。
2、headers头文件
有些网站对爬虫反感,对爬虫请求一律拒绝,这时候我们需要伪装成浏览器,通过修改http中的headers来实现
headers = {
'Host': "bj.lianjia.com",
'Accept': "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
'Accept-Encoding': "gzip, deflate, sdch",
'Accept-Language': "zh-CN,zh;q=0.8",
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.87 Safari/537.36",
'Connection': "keep-alive",
}
p = requests.get(url, headers=headers)
print(p.content.decode('utf-8'))
3、模拟登陆
一般登录的过程都伴随有验证码,这里我们通过selenium自己构造post数据进行提交,将返回验证码图片的链接地址输出到控制台下,点击图片链接识别验证码,输入验证码并提交,完成登录。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys #
from selenium.webdriver.support.ui import WebDriverWait # WebDriverWait的作用是等待某个条件的满足之后再往后运行
from selenium.webdriver import ActionChains
import time
import sys
driver = webdriver.PhantomJS(executable_path='C:\PyCharm 2016.2.3\phantomjs\phantomjs.exe') # 构造网页驱动
driver.get('https://www.zhihu.com/#signin') # 打开网页
driver.find_element_by_xpath('//input[@name="password"]').send_keys('your_password')
driver.find_element_by_xpath('//input[@name="account"]').send_keys('your_account')
driver.get_screenshot_as_file('zhihu.jpg') # 截取当前页面的图片
input_solution = input('请输入验证码 :')
driver.find_element_by_xpath('//input[@name="captcha"]').send_keys(input_solution)
time.sleep(2)
driver.find_element_by_xpath('//form[@class="zu-side-login-box"]').submit() # 表单的提交 表单的提交,即可以选择登录按钮然后使用click方法,也可以选择表单然后使用submit方法
sreach_widonw = driver.current_window_handle # 用来定位当前页面
# driver.find_element_by_xpath('//button[@class="sign-button submit"]').click()
try:
dr = WebDriverWait(driver,5)
# dr.until(lambda the_driver: the_driver.find_element_by_xpath('//a[@class="zu-side-login-box"]').is_displayed())
if driver.find_element_by_xpath('//*[@id="zh-top-link-home"]'):
print('登录成功')
except:
print('登录失败')
driver.save_screenshot('screen_shoot.jpg') #截取当前页面的图片
sys.exit(0)
driver.quit() #退出驱动
这里面,PhantomJS是一个很棒的exe,下载地址:phantomjs。他可以模拟浏览器行为进行操作。当我们遇到JS渲染的网页,在使用正则表达式、BS4和xpath . . . 都无法匹配出数据时(数据根本没加载上),可以使用PhantomJS模拟浏览器行为发送请求,将会得到网页的原始全部数据。
4、代理ip
当爬取速度过快时,当请求次数过多时都面临ip被封的可能。因此使用代理也是必备的。
使用request加代理
import requests
proxies = { "http": "http://10.10.1.10:3128",
"https": "http://10.10.1.10:1080",}
p = request.get("http://www.baidu.com", proxies = proxies)
print(p.content.decode('utf-8'))
使用urllib加代理
user_agent ='Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0'
headers = {'User-Agent':user_agent}
proxy = {'http':'http://10.10.1.10:1080',}
proxy_handler = urllib.request.ProxyHandler(proxy)
opener = urllib.request.build_opener(proxy_handler)
urllib.request.install_opener(opener)
url = "https://www.baidu.com/"
req = urllib.request.Request(url=url,headers=headers)
res = urllib.request.urlopen(req)
print(res.read().decode('utf-8')) # 打印网页内容
5、验证码输入
遇到验证的问题,我一般都是人工识别:获取验证码的链接再控制台下 ——> 点击链接识别验证码 ——> 在控制台手动输入验证码并提交。
6、ajax加载的数据
对于ajax加载的数据,我们无论通过request或post方法请求得到的网页都无法得到。
关于一个网页是否是ajax加载数据,我们只需将网页内容print到控制台下,将其与网页原始内容进行比对,如果有数据缺失,那么这些数据就是ajax加载。例如:我们想获取京东上商品的价格、销量、好评等方面的数据,但是请求返回的网页中没有这些数据。因为这些数据是ajax加载。对于ajax加载的页面,一般有两种方法。
(1)分析网页
按F12打开浏览器调试工具,在Network下选择XHR或Doc标签,分析(双击点开查看)这两个标签下的链接。如果点开链接打开的网页中正好有那些没有加载的数据,则这些数据是通过该链接传送的。再对该链接进行规律分析,以后对该链接发送请求。
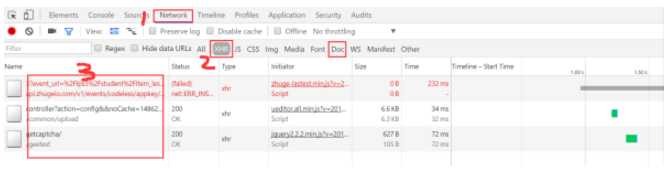
(2)使用PhantomJS模拟浏览器行为
使用PhantomJS模拟浏览器进行发送请求,得到返回的内容是完全的(ajax加载的数据也会有)。但是使用PhantomJS请求速度过慢,一般一个网页4~5s时间,不能忍。一般要使用PhantomJS需要开多线程。
driver = webdriver.PhantomJS(executable_path='C:\PyCharm 2016.2.3\phantomjs\phantomjs.exe') # 构造网页驱动
driver.get('https://www.zhihu.com/')
print(driver.page_source) # 打印网页内容
总结
以上就是本文关于关于反爬虫的一些简单总结的全部内容,希望对大家有所帮助。感兴趣的朋友可以继续参阅本站:
python爬虫系列Selenium定向爬取虎扑篮球图片详解
Python爬虫实例爬取网站搞笑段子
如有不足之处,欢迎留言指出。感谢朋友们对本站的支持!
最后
以上就是勤恳戒指最近收集整理的关于关于反爬虫的一些简单总结的全部内容,更多相关关于反爬虫内容请搜索靠谱客的其他文章。








发表评论 取消回复