前言
对于经常写爬虫的大家都知道,有些页面在登录之前是被禁止抓取的,比如知乎的话题页面就要求用户登录才能访问,而 “登录” 离不开 HTTP 中的 Cookie 技术。
登录原理
Cookie 的原理非常简单,因为 HTTP 是一种无状态的协议,因此为了在无状态的 HTTP 协议之上维护会话(session)状态,让服务器知道当前是和哪个客户在打交道,Cookie 技术出现了 ,Cookie 相当于是服务端分配给客户端的一个标识。
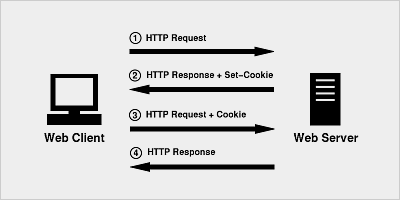
- 浏览器第一次发起 HTTP 请求时,没有携带任何 Cookie 信息
- 服务器把 HTTP 响应,同时还有一个 Cookie 信息,一起返回给浏览器
- 浏览器第二次请求就把服务器返回的 Cookie 信息一起发送给服务器
- 服务器收到HTTP请求,发现请求头中有Cookie字段, 便知道之前就和这个用户打过交道了。
实战应用
用过知乎的都知道,只要提供用户名和密码以及验证码之后即可登录。当然,这只是我们眼中看到的现象。而背后隐藏的技术细节就需要借助浏览器来挖掘了。现在我们就用 Chrome 来查看当我们填完表单后,究竟发生了什么?
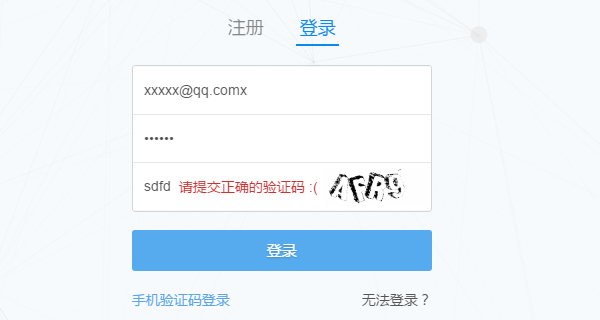
(如果已经登录的,先退出)首先进入知乎的登录页面 https://www.zhihu.com/#signin ,打开 Chrome 的开发者工具条(按 F12)先尝试输入一个错误的验证码观察浏览器是如何发送请求的。
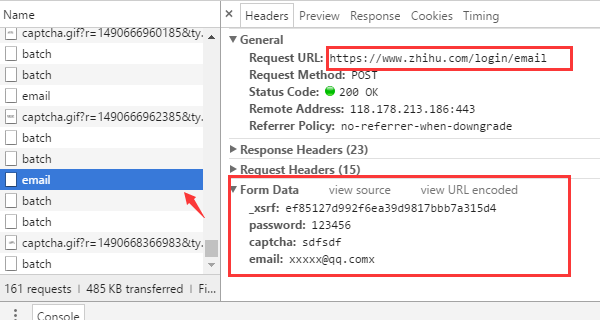
从浏览器的请求可以发现几个关键的信息
- 登录的 URL 地址是 https://www.zhihu.com/login/email
- 登录需要提供的表单数据有4个:用户名(email)、密码(password)、验证码(captcha)、_xsrf。
- 获取验证码的URL地址是 https://www.zhihu.com/captcha.gif?r=1490690391695&type=login
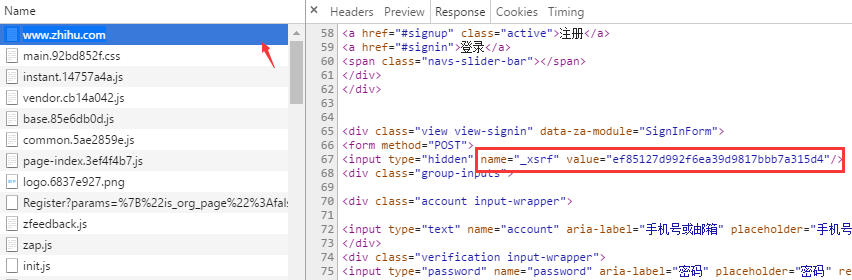
_xsrf 是什么?如果你对CSRF(跨站请求伪造)攻击非常熟悉的话,那么你一定知道它的作用,xsrf是一串伪随机数,它是用于防止跨站请求伪造的。它一般存在网页的 form 表单标签中,为了证实这一点,可以在页面上搜索 “xsrf”,果然,_xsrf在一个隐藏的 input 标签中
摸清了浏览器登录时所需要的数据是如何获取之后,那么现在就可以开始写代码用 Python 模拟浏览器来登录了。登录时所依赖的两个第三方库是 requests 和 BeautifulSoup,先安装
pip install beautifulsoup4==4.5.3 pip install requests==2.13.0
http.cookiejar 模块可用于自动处理HTTP Cookie,LWPCookieJar 对象就是对 cookies 的封装,它支持把 cookies 保存到文件以及从文件中加载。
而 session 对象 提供了 Cookie 的持久化,连接池功能,可以通过 session 对象发送请求
首先从cookies.txt 文件中加载 cookie信息,因为首次运行还没有cookie,所有会出现 LoadError 异常。
from http import cookiejar
session = requests.session()
session.cookies = cookiejar.LWPCookieJar(filename='cookies.txt')
try:
session.cookies.load(ignore_discard=True)
except LoadError:
print("load cookies failed")
获取 xsrf
前面已经找到了 xsrf 所在的标签,,利用 BeatifulSoup 的 find 方法可以非常便捷的获取该值
def get_xsrf():
response = session.get("https://www.zhihu.com", headers=headers)
soup = BeautifulSoup(response.content, "html.parser")
xsrf = soup.find('input', attrs={"name": "_xsrf"}).get("value")
return xsrf
获取验证码
验证码是通过 /captcha.gif 接口返回的,这里我们把验证码图片下载保存到当前目录,由人工识别,当然你可以用第三方支持库来自动识别,比如 pytesser。
def get_captcha():
"""
把验证码图片保存到当前目录,手动识别验证码
:return:
"""
t = str(int(time.time() * 1000))
captcha_url = 'https://www.zhihu.com/captcha.gif?r=' + t + "&type=login"
r = session.get(captcha_url, headers=headers)
with open('captcha.jpg', 'wb') as f:
f.write(r.content)
captcha = input("验证码:")
return captcha
登录
一切参数准备就绪之后,就可以请求登录接口了。
def login(email, password):
login_url = 'https://www.zhihu.com/login/email'
data = {
'email': email,
'password': password,
'_xsrf': get_xsrf(),
"captcha": get_captcha(),
'remember_me': 'true'}
response = session.post(login_url, data=data, headers=headers)
login_code = response.json()
print(login_code['msg'])
for i in session.cookies:
print(i)
session.cookies.save()
请求成功后,session 会自动把 服务端的返回的cookie 信息填充到 session.cookies 对象中,下次请求时,客户端就可以自动携带这些cookie去访问那些需要登录的页面了。
auto_login.py 示例代码
# encoding: utf-8
# !/usr/bin/env python
"""
作者:liuzhijun
"""
import time
from http import cookiejar
import requests
from bs4 import BeautifulSoup
headers = {
"Host": "www.zhihu.com",
"Referer": "https://www.zhihu.com/",
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87'
}
# 使用登录cookie信息
session = requests.session()
session.cookies = cookiejar.LWPCookieJar(filename='cookies.txt')
try:
print(session.cookies)
session.cookies.load(ignore_discard=True)
except:
print("还没有cookie信息")
def get_xsrf():
response = session.get("https://www.zhihu.com", headers=headers)
soup = BeautifulSoup(response.content, "html.parser")
xsrf = soup.find('input', attrs={"name": "_xsrf"}).get("value")
return xsrf
def get_captcha():
"""
把验证码图片保存到当前目录,手动识别验证码
:return:
"""
t = str(int(time.time() * 1000))
captcha_url = 'https://www.zhihu.com/captcha.gif?r=' + t + "&type=login"
r = session.get(captcha_url, headers=headers)
with open('captcha.jpg', 'wb') as f:
f.write(r.content)
captcha = input("验证码:")
return captcha
def login(email, password):
login_url = 'https://www.zhihu.com/login/email'
data = {
'email': email,
'password': password,
'_xsrf': get_xsrf(),
"captcha": get_captcha(),
'remember_me': 'true'}
response = session.post(login_url, data=data, headers=headers)
login_code = response.json()
print(login_code['msg'])
for i in session.cookies:
print(i)
session.cookies.save()
if __name__ == '__main__':
email = "xxxx"
password = "xxxxx"
login(email, password)
github源码地址:https://github.com/lzjun567/crawler_html2pdf/blob/master/zhihu/auto_login.py
总结
以上就是关于Python爬虫之模拟知乎登录的全部内容,希望本文的内容对大家学习或者使用python能带来一定的帮助,如果有疑问大家可以留言交流,谢谢大家对脚本之家的支持。
最后
以上就是年轻豆芽最近收集整理的关于Python爬虫之模拟知乎登录的方法教程的全部内容,更多相关Python爬虫之模拟知乎登录内容请搜索靠谱客的其他文章。








发表评论 取消回复