本文思路主要来源于实验楼的教程,但是一些具体的一些细节是我自己发现的,比如哪里获得站点对应的3位英文编号,怎么获得这个查询的url
本文用到的库主要有requests(获取url的内容),prettytable(让文本输出美观),argparse(命令行参数解析)
关于这些库怎么使用,可以参见我之前的博文
1、首先打开12306余票查询的界面
https://kyfw.12306.cn/otn/lcxxcx/init
我们想要的信息当然就是在输入了始发站、终点站和日期之后各车次的时间和车票余量,那么我们尝试在始发站使用检查元素,观察一下它是怎么上传始发站的信息的,那么我们不妨随便输入出发地、目的地和信息,使用抓包工具来看看它是怎么发包的(使用浏览器也可以,因为我们只需要查看包的内容,不需要更改包)
2、
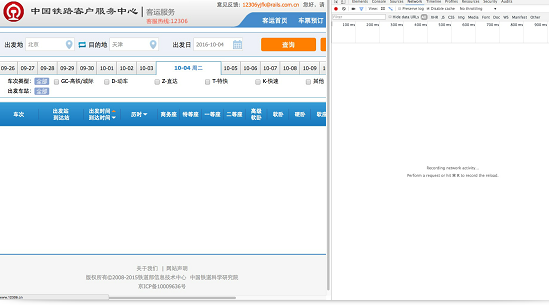
在chrome的network中我们可以查看到我们点击之后浏览器发送的所有包(关于http包的知识不熟悉的同学,可以看看《图解http》这本书)
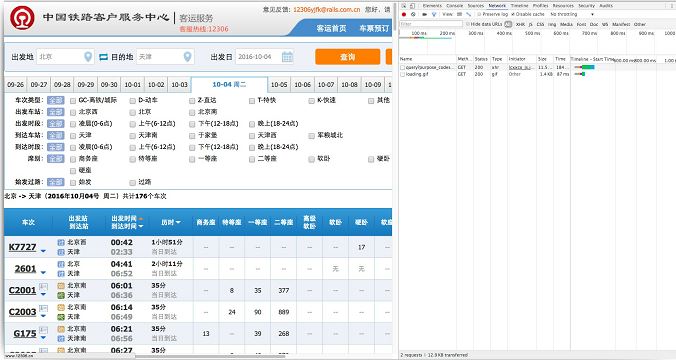
点击查询之后我们马上就会注意到以query开头的这个包,显然这就是一个查询指令,我们看看这个包的url
'https://kyfw.12306.cn/otn/lcxxcx/query?purpose_codes=ADULT&queryDate=2016-10-04&from_station=BJP&to_station=XKS'
然后我们看看它的response
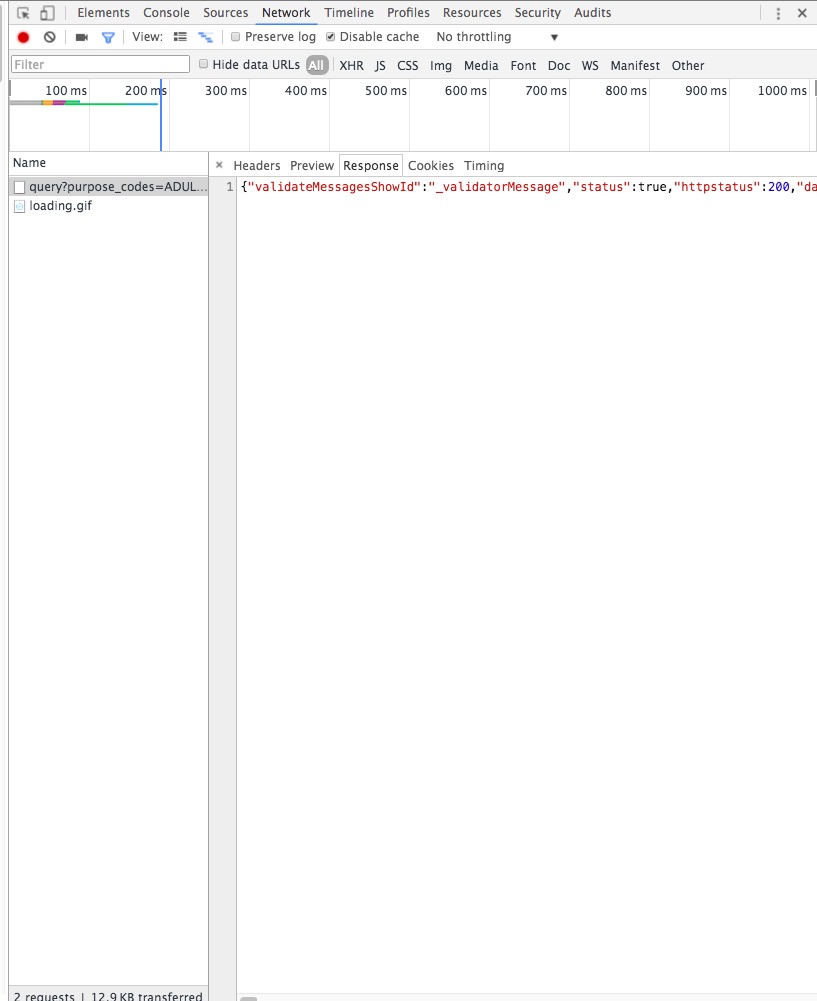
仔细观察就能发现它其实是一串json格式的字符串(要非常有经验。。。。)
3、经过以上这些过程,我们大致就能知道我们需要做的是什么了,我们只需要更改url中的data,fromstaion,tostaion后面的内容,然后用requests获得response,然后解析这一串json字符就行了。
但是我们会发现,日期还好说,对于fromstation和tostaion的代码,我们该怎么办呢?
4、有两种可能,一中可能是这些文件在服务器上,每回改变站点网页都会从服务器请求这个站点的代码,还有一种可能是这个已经下载到本地了,如何判断呢?我们不妨改变一下始发站,然后用抓包软件(或者浏览器)观察我们的浏览器是否向12306发送了包
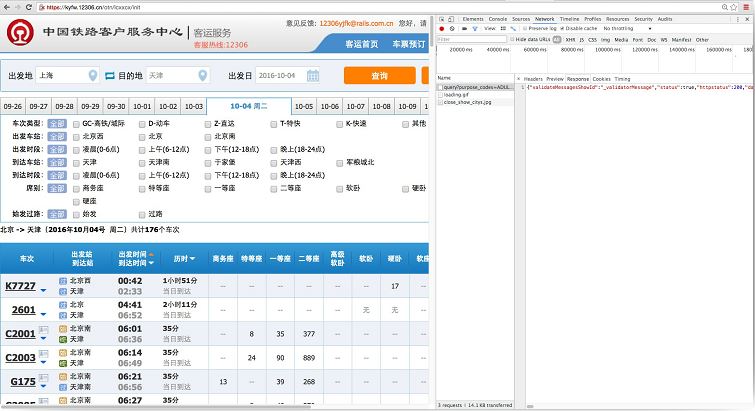
把北京改成了上海,但是我们发现浏览器并没有发送包
这样我们基本可以肯定这个车站编号信息是存在本地了(已经从服务器下载下来)
5、我们这时候,就需要分析html来发现这个编号信息到底储存在了那里
我们试着检查一下出发地附近的html标签,在‘热门'上面点击检查,我们很容易发现这个标签上面带了一个onclick方法
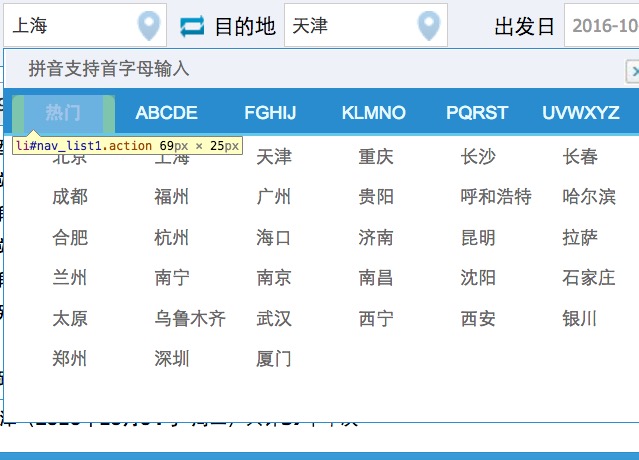
我们发现这个onclick方法指向了一个js文件,并且名字是‘Stationfor12306',基本我们可以确定这个js文件就是我们需要的站点信息文件了。
6、我们尝试在这个html(12306余票查询界面)里面搜一下stationfor,我们马上就能发现,它就在<head>标签的<script>元素里,并且指向了一个url
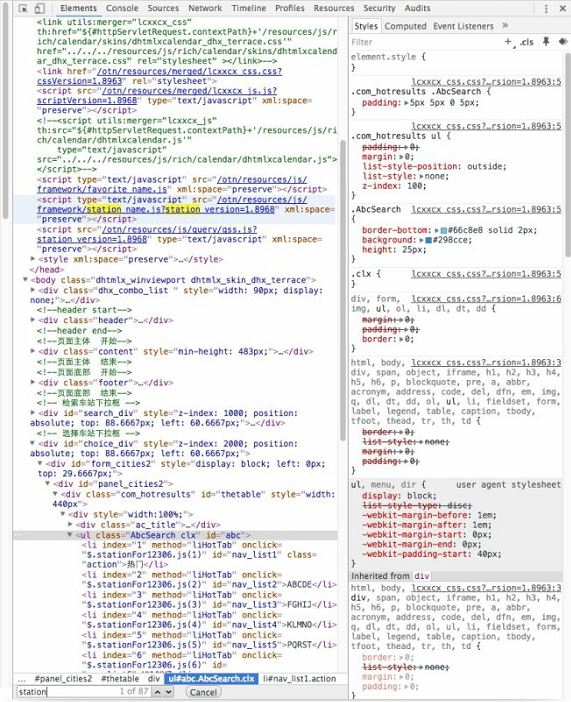
进入这个url看看,我们马上就发现站点信息已经被我们找到啦(注意这是一个相对URL,绝对url需要在前面补上https://kyfw.12306.cn/)
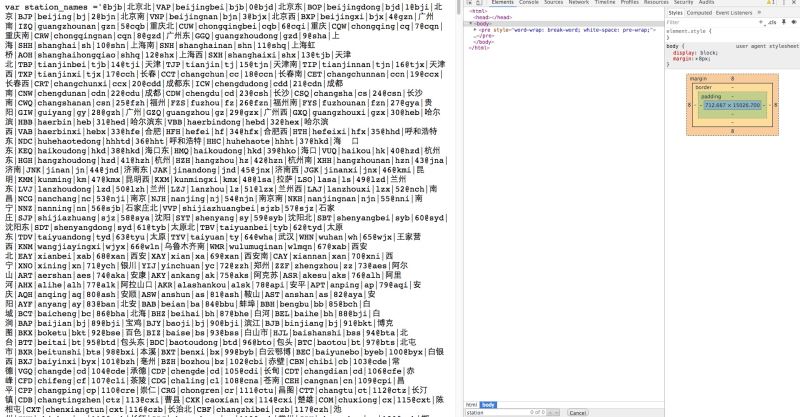
关于怎么获取三位数的车站代码,用正则,字符串查询都是可以的啦,由于这里是固定的3位车站代码,我就用简单的字符串查询来提取这个代码了。
7、剩下的工作,基本就是代码实现了,关于具体怎么实现,我把我的代码贴在下面了。
#coding=utf-8
import requests
import argparse
import datetime
import re
from prettytable import PrettyTable
now = datetime.datetime.now()
tomorrow = now+datetime.timedelta(days=1)
tomorrow = tomorrow.strftime('%Y-%m-%d')
print tomorrow
argument = argparse.ArgumentParser()
argument.add_argument('--fromcity','-f',default='hangzhoudong')
argument.add_argument('--tocity','-t',default='xiamen')
argument.add_argument('--date','-d',default=tomorrow)
# argument.add_argument('-d',action='store_true')
args =argument.parse_args()
from_station = args.fromcity
to_station = args.tocity
Date = args.date
stationlist_url = 'https://kyfw.12306.cn/otn/resources/js/framework/station_name.js'
r = requests.get(stationlist_url, verify=False)
stationlist = r.content
ToStation = ''
FromStation = ''
placea = stationlist.find(from_station)
placeb = stationlist.find(to_station)
for i in range(-4,-1):
FromStation += stationlist[placea+i]
for i in range(-4,-1):
ToStation += stationlist[placeb+i]
query_url='https://kyfw.12306.cn/otn/lcxxcx/query?purpose_codes=ADULT&queryDate='+Date+'&from_station='+FromStation+'&to_station='+ToStation
r = requests.get(query_url,verify=False)
with open('json.txt','w') as fp:
fp.write(str(r.json()))
if 'datas' in r.json()["data"]:
rj = r.json()["data"]["datas"]
pt = PrettyTable()
header = '车次 车站 到站时间 时长 一等座 二等座 软卧 硬卧 硬座 无座'.split()
pt._set_field_names(header)
for x in rj:
ptrow = []
ptrow.append(x["station_train_code"])
ptrow.append('\n'.join([x["from_station_name"],x["to_station_name"]]))
ptrow.append('\n'.join([x["start_time"], x["arrive_time"]]))
ptrow.append(x["lishi"].replace(':','h')+'m')
ptrow.append(x['zy_num'])
ptrow.append(x['ze_num'])
ptrow.append(x['rw_num'])
ptrow.append(x['yw_num'])
ptrow.append(x['yz_num'])
ptrow.append(x['wz_num'])
pt.add_row(ptrow)
print pt
else :
print '这两个站点没有直达列车'
总结
以上就是本文关于python编程实现12306的一个小爬虫实例的全部内容,希望对大家有所帮助。感兴趣的朋友可以继续参阅本站其他相关专题,如有不足之处,欢迎留言指出。感谢朋友们对本站的支持!
最后
以上就是落寞香烟最近收集整理的关于python编程实现12306的一个小爬虫实例的全部内容,更多相关python编程实现12306内容请搜索靠谱客的其他文章。








发表评论 取消回复