前言
本文主要给大家介绍了关于Python中序列的修改、散列与切片的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧。
Vector类:用户定义的序列类型
我们将使用组合模式实现 Vector 类,而不使用继承。向量的分量存储在浮点数数组中,而且还将实现不可变扁平序列所需的方法。
Vector 类的第 1 版要尽量与前一章定义的 Vector2d 类兼容。
Vector类第1版:与Vector2d类兼容
Vector 类的第 1 版要尽量与前一章定义的 Vector2d 类兼容。然而我们会故意不让 Vector 的构造方法与 Vector2d 的构造方法兼容。为了编写 Vector(3, 4) 和 Vector(3, 4, 5) 这样的代码,我们可以让 __init__ 方法接受任意个参数(通过 *args);但是,序列类型的构造方法最好接受可迭代的对象为参数,因为所有内置的序列类型都是这样做的。
测试 Vector.__init__ 和 Vector.__repr__ 方法
>>> Vector([3.1, 4.2]) Vector([3.1, 4.2]) >>> Vector((3, 4, 5)) Vector([3.0, 4.0, 5.0]) >>> Vector(range(10)) Vector([0.0, 1.0, 2.0, 3.0, 4.0, ...])
vector_v1.py:从 vector2d_v1.py 衍生而来
from array import array
import reprlib
import math
class Vector:
typecode = 'd'
def __init__(self, components):
self._components = array(self.typecode, components) #self._components是“受保护的”实例属性,把Vector的分量保存在一个数组中
def __iter__(self):
return iter(self._components) #为了迭代,我们使用self._components构建一个迭代器
def __repr__(self):
components = reprlib.repr(self._components) #使用reprlib.repr()函数获取self._components 的有限长度表示形式(如 array('d', [0.0, 1.0, 2.0, 3.0, 4.0, ...]))
components = components[components.find('['):-1] #把字符串插入 Vector 的构造方法调用之前,去掉前面的array('d' 和后面的 )
return 'Vecotr({})'.format(components) #直接使用 self._components 构建 bytes 对象
def __str__(self):
return str(tuple(self))
def __bytes__(self):
return (bytes([ord(self.typecode)]) +
bytes(self._components))
def __eq__(self, other):
return tuple(self) == tuple(other)
def __abs__(self):
return math.hypot(sum(x * x for x in self)) #不能使用hypot方法了,因此我们先计算各分量的平方之和,然后再使用sqrt方法开平方
def __bool__(self):
return bool(abs(self))
@classmethod
def frombytes(cls, octets):
typedcode = chr(octets[0])
memv = memoryview(octets[1:]).cast(typedcode)
return cls(memv) #我们只需在 Vector2d.frombytes 方法的基础上改动最后一行:直接把memoryview传给构造方法,不用像前面那样使用*拆包
协议和鸭子类型
在 Python 中创建功能完善的序列类型无需使用继承,只需实现符合序列协议的方法。不过,这里说的协议是什么呢?
在面向对象编程中,协议是非正式的接口,只在文档中定义,在代码中不定义。例如,Python 的序列协议只需要 __len__ 和 __getitem__ 两个方法。任何类(如 Spam),只要使用标准的签名和语义实现了这两个方法,就能用在任何期待序列的地方。Spam 是不是哪个类的子类无关紧要,只要提供了所需的方法即可。
class FrenchDeck:
ranks = [str(n) for n in range(2, 11)] + list('JQKA')
suits = 'spades diamonds clubs hearts'.split()
def __init__(self):
self._cards = [Card(rank, suit) for suit in self.suits for rank in self.ranks]
def __len__(self):
return len(self._cards)
def __getitem__(self, position):
return self._cards[position]
协议是非正式的,没有强制力,因此如果你知道类的具体使用场景,通常只需要实现一个协议的部分。例如,为了支持迭代,只需实现__getitem__ 方法,没必要提供 __len__ 方法。
Vector类第2版:可切片的序列
如 FrenchDeck 类所示,如果能委托给对象中的序列属性(如self._components 数组),支持序列协议特别简单。下述只有一行代码的 __len__ 和 __getitem__ 方法是个好的开始:
class Vector: # 省略了很多行 # ... def __len__(self): return len(self._components) def __getitem__(self, index): return self._components[index]
添加这两个方法之后,就能执行下述操作了:
>>> v1 = Vector([3, 4, 5])
>>> len(v1)
>>> v1[0], v1[-1]
(3.0, 5.0)
>>> v7 = Vector(range(7))
>>> v7[1:4]
array('d', [1.0, 2.0, 3.0])
可以看到,现在连切片都支持了,不过尚不完美。如果 Vector 实例的切片也是 Vector 实例,而不是数组,那就更好了。前面那个FrenchDeck 类也有类似的问题:切片得到的是列表。对 Vector 来说,如果切片生成普通的数组,将会缺失大量功能。
为了把 Vector 实例的切片也变成 Vector 实例,我们不能简单地委托给数组切片。我们要分析传给 __getitem__ 方法的参数,做适当的处理。
切片原理
了解 __getitem__ 和切片的行为
>>> class MySeq: ... def __getitem__(self, index): ... return index ... >>> s = MySeq() >>> s[1] #__getitem__直接返回传给它的值 >>> s[1:4] #[1:4]表示变成了slice(1, 4, None) slice(1, 4, None) >>> s[1:4:2] #[1:4:2]的意思为从第1个索引开始,到第4个索引结束,步长为2 slice(1, 4, 2) >>> s[1:4:2, 9] (slice(1, 4, 2), 9) #神奇的事情发生了..wtf...如果[]中有逗号,那么__getitem__接收的是元祖 >>> s[1:4:2, 7:9] #元祖中还可以包含多个切片对象 (slice(1, 4, 2), slice(7, 9, None))
🌰 查看slice类的属性
>>> slice <class 'slice'> >>> dir(slice) ['__class__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'indices', 'start', 'step', 'stop']
调用 dir(slice) 得到的结果中有个 indices 属性,这个方法有很大的作用,但是鲜为人知。help(slice.indices) 给出的信息如下。
indices(...)
S.indices(len) -> (start, stop, stride)
给定长度为 len 的序列,计算 S 表示的扩展切片的起始(start)和结尾(stop)索引,以及步幅(stride)。超出边界的索引会被截掉,这与常规切片的处理方式一样。
举个 🌰 假设有个长度为5的序列,例如'ABCDE':
>>> slice(None, 10, 2).indices(5) #'ABCDE'[:10:2]等同于[:] (0, 5, 2) >>> slice(-3, None, None).indices(5) #'ABCDE'[-3:]等同于[2:5:1] (2, 5, 1)
能处理切片的__getitem__方法
vector_v2.py 的部分代码:为 vector_v1.py 中的 Vector类添加 __len__ 和__getitem__ 方法
def __len__(self):
return len(self._components)
def __getitem__(self, index):
cls = type(self) #获取实例的类(Vector)
if isinstance(index, slice): #判断传递进来的index是否为slice对象
return cls(self._components[index]) #调用类的构造方法,创建一个新的Vector实例
elif isinstance(index, numbers.Integral): #如果传递进来的是个整数
return self._components[index] #返回 _components 中相应的元素
else: #抛出异常
msg = '{cls.__name__} indices must be integers'
raise TypeError(msg.format(cls=cls))
测试 🌰 改进的 Vector.__getitem__ 方法
>>> v7 = Vector(range(7)) >>> v7[-1] #获取单个整数索引,返回一个浮点数 6.0 >>> v7[1:4] #切片索引创建一个新的Vector实例 Vector([1.0, 2.0, 3.0]) >>> v7[-1:] #长度为1的切片也会创建一个新的Vector实例 Vector([6.0]) >>> v7[1,2] #我们在上面的slice已经知道,如果slice中包含了,则是一个包含slice的元祖,所以报错了 Traceback (most recent call last): ... TypeError: Vector indices must be integers
Vector类第3版:动态存取属性
Vector2d 变成 Vector 之后,就没办法通过名称访问向量的分量了(如 v.x 和 v.y)。现在我们处理的向量可能有大量分量。不过,若能通过单个字母访问前几个分量的话会比较方便。比如,用 x、y 和 z 代替 v[0]、v[1] 和 v[2]
在 Vector2d 中,我们使用 @property 装饰器把 x 和 y 标记为只读特性。我们可以在 Vector 中编写四个特性,但这样太麻烦。特殊方法 __getattr__ 提供了更好的方式。
属性查找失败后,解释器会调用 __getattr__ 方法。简单来说,对my_obj.x 表达式,Python 会检查 my_obj 实例有没有名为 x 的属性;如果没有,到类(my_obj.__class__ )中查找;如果还没有,顺着继承树继续查找。 如果依旧找不到,调用 my_obj 所属类中定义的__getattr__ 方法,传入 self 和属性名称的字符串形式(如 'x')。
vector_v3.py 的部分代码:在 vector_v2.py 中定义的Vector 类里添加 __getattr__ 方法
def __getattr__(self, name):
cls = type(self) #获取Vector
if len(name) == 1: #如果属性名只有一个字母,可能是shortcut_names中的一个
pos = cls.shorcut_name.find(name) #查找属性name是否在xyzx中的位置,如果木有就返回-1,有就返回对应的索引
if 0 <= pos < len(self._components): #判断这个查找到的索引是否在区间内
return self._components[pos] #返回查找的到的数组中的值
msg = '{.__name__!r} object has no attribute {!r}' #报错的信息
raise AttributeError(msg.format(cls, name)) #抛出异常
测试下效果:
>>> v = Vector(range(5)) >>> v Vector([0.0, 1.0, 2.0, 3.0, 4.0]) >>> v.x # 使用v.x获取第一个元素v[0] 0.0 >>> v.x = 10 # 为v.x赋新的值,按理说应该会报异常 >>> v.x # 读取v.x,返回来的是新的值 >>> v Vector([0.0, 1.0, 2.0, 3.0, 4.0])# 数组并没有改变什么~
如果为 .x 或 .y 实例属性赋值,会抛出 AttributeError。为了避免歧义,在 Vector 类中,如果为名称是单个小写字母的属性赋值,我们也想抛出那个异常。为此,我们要实现 __setattr__ 方法。
vector_v3.py 的部分代码:在 Vector 类中实现__setattr__ 方法
def __setattr__(self, name, value):
cls = type(self)
if len(name) == 1: #特别处理名称是单个字符的属性
if name in self.shorcut_name: #如果name是xyzt中的一个,设置特殊的错误消息
error = 'readonly attribute {attr_name!r}'
elif name.islower(): #如果name是小写字母,为所有小写字母设置一个错误消息
error = "can't set attributes 'a' to 'z' in {cls_name!r}"
else:
error = ''
if error: #否则,把错误消息设为空字符串
msg = error.format(cls_name=cls.__name__, attr_name=name)
raise AttributeError(msg) #如果有错误消息,抛出 AttributeError
super().__setattr__(name, value) #默认情况:在超类上调用__setattr__方法,提供标准行为
Vector类第4版:散列和快速等值测试
我们要再次实现 __hash__ 方法。加上现有的 __eq__ 方法,这会把Vector 实例变成可散列的对象。
我们要使用^(异或)运算符依次计算各个分量的散列值,像这样:v[0] ^ v[1] ^ v[2]...。这正是functools.reduce 函数的作用。
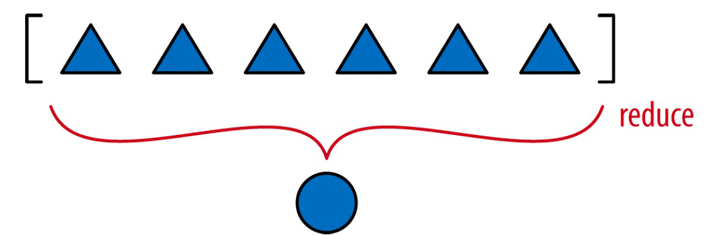
归约函数(reduce、sum、any、all)把序列或有限的可迭代对象变成一个聚合结果
我们已经知道 functools.reduce() 可以替换成 sum() ,下面说说它的原理。它的关键思想是,把一系列值归约成单个值。reduce() 函数的第一个参数是接受两个参数的函数,第二个参数是一个可迭代的对象。假如有个接受两个参数的 fn 函数和一个 lst 列表。调用reduce(fn, lst) 时,fn 会应用到第一对元素上,即 fn(lst[0],lst[1]) ,生成第一个结果 r1。然后,fn 会应用到 r1 和下一个元素上,即 fn(r1, lst[2]) ,生成第二个结果 r2。接着,调用 fn(r2,lst[3]) ,生成 r3……直到最后一个元素,返回最后得到的结果 rN。
举个🌰 使用 reduce 函数可以计算 5!(5 的阶乘):
>>> 2 * 3 * 4 * 5 # 想要的结果是:5! == 120 120 >>> import functools >>> functools.reduce(lambda a,b: a*b, range(1, 6)) 120
回到散列问题上。下面的 🌰 展示了计算聚合异或的 3 种方式:一种使用 for 循环,两种使用 reduce 函数。
>>> n = 0 >>> for i in range(1, 6): # 使用for循环和累加器变量计算聚合异或 ... n ^= i ... >>> n >>> import functools >>> functools.reduce(lambda a, b: a^b, range(6)) # 使用reduce传入匿名函数 >>> import operator >>> functools.reduce(operator.xor, range(6)) # 使用 functools.reduce 函数,把 lambda 表达式换成 operator.xor
给代码中添加__hash__方法
from array import array import reprlib import math import numbers import functools import operator class Vector: typecode = 'd' shorcut_name = 'xyzt' """ 省略的代码 """ def __eq__(self, other): return tuple(self) == tuple(other) def __hash__(self): hashes = (hash(x) for x in self._components) return functools.reduce(operator.xor, hashes, 0) #把hashes提供给reduce函数,使用xor函数计算聚合的散列值;第三个参数,0 是初始值
注意:
使用 reduce 函数时最好提供第三个参数,reduce(function, iterable, initializer) ,这样能避免这个异常:TypeError: reduce() of empty sequence with no initial value(这个错误消息很棒,说明了问题,还提供了解决方法)。如果序列为空,initializer 是返回的结果;否则,在归约中使用它作为第一个参数,因此应该使用恒等值。比如,对 +、| 和 ^ 来说, initializer 应该是 0;而对 * 和 & 来说,应该是 1。
实现的 __hash__ 方法是一种映射归约计算
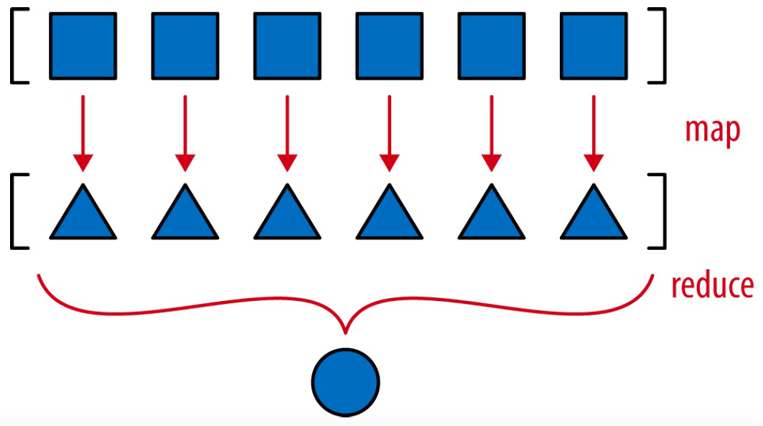
映射归约:把函数应用到各个元素上,生成一个新序列(映射,map),然后计算聚合值(归约,reduce)
映射过程计算各个分量的散列值,归约过程则使用 xor 运算符聚合所有散列值。把生成器表达式替换成 map 方法,映射过程更明显:
def __hash__(self): hashes = map(hash, self._components) return functools.reduce(operator.xor, hashes, 0) #把hashes提供给reduce函数,使用xor函数计算聚合的散列值;第三个参数,0 是初始值
为了提高比较的效率,Vector.__eq__ 方法在 for循环中使用 zip 函数
def __eq__(self, other):
if len(self) != len(other): #如果对比的两个长度不一样,返回False
return False
for a, b in zip(self, other): #如果两个对比Vector实例传递的值通过惰性对比,有不不一样的就返回FALSE
if a != b:
return False
return True
zip的效率很好,不过用于计算聚合值的整个 for 循环可以替换成一行 all 函数调用:如果所有分量对的比较结果都是 True,那么结果就是 True。只要有一次比较的结果是 False,all 函数就返回False。使用 all 函数实现 __eq__ 方法的方式如下:
使用 zip 和 all 函数实现 Vector.__eq__ 方法,效果和上面的代码一样~
def __eq__(self, other): return len(self) == len(other) and all(a == b for a, b in zip(self, other))
出色的 zip 函数
使用 for 循环迭代元素不用处理索引变量,还能避免很多缺陷,但是需要一些特殊的实用函数协助。其中一个是内置的 zip 函数。使用 zip 函数能轻松地并行迭代两个或更多可迭代对象,它返回的元组可以拆包成变量,分别对应各个并行输入中的一个元素。
举个 🌰
>>> zip(range(3), 'abc')
<zip object at 0x1024d7b48>
>>> list(zip(range(3), 'abc')) #zip返回一个生成器,按需生成元祖
[(0, 'a'), (1, 'b'), (2, 'c')]
>>> dict(zip('123', 'abc')) #使用zip快速构造一个字典
{'1': 'a', '2': 'b', '3': 'c'}
>>> from itertools import zip_longest #使用zip_longest可以给给个fillvalue设置一个默认值,当元祖迭代尽的时候可以补充默认值
>>> list(zip_longest(range(3), 'ABC', [0.0, 1.1, 2.2, 3.3], fillvalue=-1))
[(0, 'A', 0.0), (1, 'B', 1.1), (2, 'C', 2.2), (-1, -1, 3.3)]
Vector类第5版:格式化
Vector 类的 __format__ 方法与 Vector2d 类的相似,但是不使用极坐标,而使用球面坐标(也叫超球面坐标),因为 Vector 类支持 n 个维度,而超过四维后,球体变成了“超球体”。 因此,我们会把自定义的格式后缀由 'p' 变成 'h'。
下面几个示例摘自 vector_v5.py 的 doctest,是四维球面坐标格式:
>>> format(Vector([-1, -1, -1, -1]), 'h') '<2.0, 2.0943951023931957, 2.186276035465284, 3.9269908169872414>' >>> format(Vector([2, 2, 2, 2]), '.3eh') '<4.000e+00, 1.047e+00, 9.553e-01, 7.854e-01>' >>> format(Vector([0, 1, 0, 0]), '0.5fh') '<1.00000, 1.57080, 0.00000, 0.00000>'
vector_v5.py:Vector 类最终版的 doctest 和全部代码;带标号的那几行是为了支持 __format__ 方法而添加的代码
from array import array
import reprlib
import math
import numbers
import functools
import operator
import itertools
class Vector:
typecode = 'd'
def __init__(self, components):
self._components = array(self.typecode, components)
def __iter__(self):
return iter(self._components)
def __repr__(self):
components = reprlib.repr(self._components)
components = components[components.find('['):-1]
return 'Vector({})'.format(components)
def __str__(self):
return str(tuple(self))
def __bytes__(self):
return (bytes([ord(self.typecode)]) + bytes(self._components))
def __eq__(self, other):
return (len(self) == len(other) and all(a == b for a, b in zip(self, other)))
def __hash__(self):
hashes = map(hash, self._components)
return functools.reduce(operator.xor, hashes, 0)
def __abs__(self):
return math.sqrt(sum(x * x for x in self))
def __bool__(self):
return bool(abs(self))
def __len__(self):
return len(self._components)
def __getitem__(self, index):
cls = type(self)
if isinstance(index, slice):
return cls(self._components[index])
elif isinstance(index, numbers.Integral):
return self._components[index]
else:
msg = '{.__name__} indices must be integers'
raise TypeError(msg.format(cls))
shorcut_names = 'xyzt'
def __getattr__(self, name):
cls = type(self)
if len(name) == 1:
pos = cls.shorcut_names.find(name)
if 0 <= pos < len(self._components):
return self._components[pos]
msg = '{.__name__!r} object has no attribute {!r}'
raise AttributeError(msg.format(cls, name))
def angle(self, n):
r = math.sqrt(sum(x * x for x in self[n:]))
a = math.atan2(r, self[n-1])
if (n == len(self) - 1 ) and (self[-1] < 0):
return math.pi * 2 - a
else:
return a
def angles(self):
return (self.angle(n) for n in range(1, len(self)))
def __format__(self, fmt_spec=''):
if fmt_spec.endswith('h'):
fmt_spec = fmt_spec[:-1]
coords = itertools.chain([abs(self)], self.angles())
outer_fmt = '<{}>'
else:
coords = self
outer_fmt = '({})'
components = (format(c, fmt_spec) for c in coords)
return outer_fmt.format(', '.join(components))
@classmethod
def frombytes(cls, octets):
typecode = octets[0]
memv = memoryview(octets[1:]).cast(typecode)
return cls(memv)
测试的结果为:
""" A multidimensional ``Vector`` class, take 5 A ``Vector`` is built from an iterable of numbers:: >>> Vector([3.1, 4.2]) Vector([3.1, 4.2]) >>> Vector((3, 4, 5)) Vector([3.0, 4.0, 5.0]) >>> Vector(range(10)) Vector([0.0, 1.0, 2.0, 3.0, 4.0, ...]) Tests with two dimensions (same results as ``vector2d_v1.py``):: >>> v1 = Vector([3, 4]) >>> x, y = v1 >>> x, y (3.0, 4.0) >>> v1 Vector([3.0, 4.0]) >>> v1_clone = eval(repr(v1)) >>> v1 == v1_clone True >>> print(v1) (3.0, 4.0) >>> octets = bytes(v1) >>> octets b'd\\x00\\x00\\x00\\x00\\x00\\x00\\x08@\\x00\\x00\\x00\\x00\\x00\\x00\\x10@' >>> abs(v1) 5.0 >>> bool(v1), bool(Vector([0, 0])) (True, False) Test of ``.frombytes()`` class method: >>> v1_clone = Vector.frombytes(bytes(v1)) >>> v1_clone Vector([3.0, 4.0]) >>> v1 == v1_clone True Tests with three dimensions:: > >> v1 = Vector([3, 4, 5]) >>> x, y, z = v1 >>> x, y, z (3.0, 4.0, 5.0) >>> v1 Vector([3.0, 4.0, 5. 0]) >>> v1_clone = eval(repr(v1)) >>> v1 == v1_clone True >>> print(v1) (3.0, 4.0, 5.0) >> abs(v1) # doctest:+ELLIPSIS 7.071067811... >>> bool(v1), bool(Vector([0, 0, 0])) (True, False) Tests with many dimensions:: >>> v7 = Vector(range(7)) >>> v7 Vector([0.0, 1.0, 2.0, 3.0, 4.0, ...]) >>> abs(v7) # doctest:+ELLIPSIS 9.53939201.. Test of ``.__bytes__`` and ``.frombytes()`` methods:: >>> v1 = Vector([3, 4, 5]) >>> v1_clone = Vector.frombytes(bytes(v1)) >>> v1_clone Vector([3.0, 4.0, 5.0]) >>> v1 == v1_clone True Tests of sequence behavior:: >>> v1 = Vector([3, 4, 5]) >>> len(v1) >>> v1[0], v1[len(v1)-1], v1[-1] (3.0, 5.0, 5.0) Test of slicing:: >>> v7 = Vector(range(7)) >>> v7[-1] 6.0 >>> v7[1:4] Vector([1.0, 2.0, 3.0]) >>> v7[-1:] Vector([6.0]) >>> v7[1,2] Traceback (most recent call last): ... TypeError: Vector indices must be integers Tests of dynamic attribute access:: >>> v7 = Vector(range(10)) >>> v7.x 0.0 >>> v7.y, v7.z, v7.t (1.0, 2.0, 3.0) Dynamic attribute lookup failures:: >>> v7.k Traceback (most recent call last): ... AttributeError: 'Vector' object has no attribute 'k' >>> v3 = Vector(range(3)) >>> v3.t Traceback (most recent call last): ... AttributeError: 'Vector' object has no attribute 't' >>> v3.spam Traceback (most recent call last): ... AttributeError: 'Vector' object has no attribute 'spam' Tests of hashing:: >>> v1 = Vector([3, 4]) >>> v2 = Vector([3.1, 4.2]) >>> v3 = Vector([3, 4, 5]) >>> v6 = Vector(range(6)) >>> hash(v1), hash(v3), hash(v6) (7, 2, 1) Most hash values of non-integers vary from a 32-bit to 64-bit CPython build:: >>> import sys >>> hash(v2) == (384307168202284039 if sys.maxsize > 2**32 else 357915986) True Tests of ``format()`` with Cartesian coordinates in 2D:: >>> v1 = Vector([3, 4]) >>> format(v1) '(3.0, 4.0)' >>> format(v1, '.2f') '(3.00, 4.00)' >>> format(v1, '.3e') '(3.000e+00, 4.000e+00)' Tests of ``format()`` with Cartesian coordinates in 3D and 7D:: >>> v3 = Vector([3, 4, 5]) >>> format(v3) '(3.0, 4.0, 5.0)' >>> format(Vector(range(7))) '(0.0, 1.0, 2.0, 3.0, 4.0, 5.0, 6.0)' Tests of ``format()`` with spherical coordinates in 2D, 3D and 4D:: >>> format(Vector([1, 1]), 'h') # doctest:+ELLIPSIS '<1.414213..., 0.785398...>' >>> format(Vector([1, 1]), '.3eh') '<1.414e+00, 7.854e-01>' >>> format(Vector([1, 1]), '0.5fh') '<1.41421, 0.78540>' >>> format(Vector([1, 1, 1]), 'h') # doctest:+ELLIPSIS '<1.73205..., 0.95531..., 0.78539...>' >>> format(Vector([2, 2, 2]), '.3eh') '<3.464e+00, 9.553e-01, 7.854e-01>' >>> format(Vector([0, 0, 0]), '0.5fh') '<0.00000, 0.00000, 0.00000>' >>> format(Vector([-1, -1, -1, -1]), 'h') # doctest:+ELLIPSIS '<2.0, 2.09439..., 2.18627..., 3.92699...>' >>> format(Vector([2, 2, 2, 2]), '.3eh') '<4.000e+00, 1.047e+00, 9.553e-01, 7.854e-01>' >>> format(Vector([0, 1, 0, 0]), '0.5fh') '<1.00000, 1.57080, 0.00000, 0.00000>' """
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作能带来一定的帮助,如果有疑问大家可以留言交流,谢谢大家对脚本之家的支持。
最后
以上就是精明黑米最近收集整理的关于Python中序列的修改、散列与切片详解的全部内容,更多相关Python中序列内容请搜索靠谱客的其他文章。








发表评论 取消回复