定义:也叫合成模式,或者部分-整体模式,主要是用来描述部分与整体的关系,定义,将对象组合成树形结构以表示“部分-整体”的层次结构,使得用户对单个对象和组合对象的使用具有一致性。
类图:
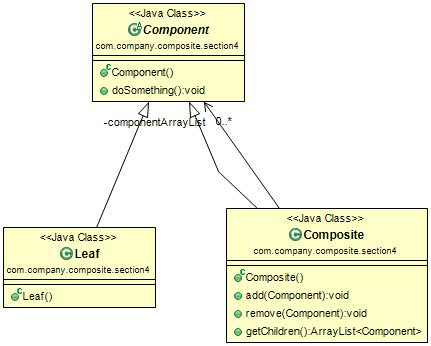
角色说明:
Componnent抽象构件角色:定义参加组合对象的共有方法和属性,可以定义一些默认的行为或属性。
Leaf叶子构件:叶子对象,其下再也没有其他的分支,也就是遍历的最小单位。
Composite树枝构件:树枝对象,它的作用是组合树枝节点和叶子节点形成一个树形结构。
实例:
听说你们公司最近新推出了一款电子书阅读应用,市场反应很不错,应用里还有图书商城,用户可以在其中随意选购自己喜欢的书籍。你们公司也是对此项目高度重视,加大了投入力度,决定给此应用再增加点功能。
好吧,你也知道你是逃不过此劫了,没过多久你的leader就找到了你。他告诉你目前的应用对每本书的浏览量和销售量做了统计,但现在想增加对每个书籍分类的浏览量和销售量以及所有书籍总的浏览量和销售量做统计的功能,希望你可以来完成这项功能。
领导安排的工作当然是推脱不掉的,你只能硬着头皮上了,不过好在这个功能看起来也不怎么复杂。
你比较喜欢看小说,那么就从小说类的统计功能开始做起吧。首先通过get_all_novels方法可以获取到所有的小说名,然后将小说名传入get_browse_count方法可以得到该书的浏览量,将小说名传入get_sale_count方法可以得到该书的销售量。你目前只有这几个已知的API可以使用,那么开始动手吧!
def get_novels_browse_count
browse_count = 0
all_novels = get_all_novels()
all_novels.each do |novel|
browse_count += get_browse_count(novel)
end
browse_count
end
def get_novels_sale_count
sale_count = 0
all_novels = get_all_novels()
all_novels.each do |novel|
sale_count += get_browse_count(novel)
end
sale_count
end
很快你就写下了以上两个方法,这两个方法都是通过获取到所有的小说名,然后一一计算每本小说的浏览量和销售量,最后将结果相加得到总量。
小说类的统计就完成了,然后你开始做计算机类书籍的统计功能,代码如下所示:
def get_computer_books_browse_count
browse_count = 0
all_computer_books = get_all_computer_books()
all_computer_books.each do |computer_book|
browse_count += get_browse_count(computer_book)
end
browse_count
end
def get_computer_books_sale_count
sale_count = 0
all_computer_books = get_all_computer_books()
all_computer_books.each do |computer_book|
sale_count += get_browse_count(computer_book)
end
sale_count
end
除了使用了get_all_computer_books方法获取到所有的计算机类书名,其它的代码基本和小说统计中的是一样的。
现在你才完成了两类书籍的统计功能,后面还有医学类、自然类、历史类、法律类、政治类、哲学类、旅游类、美食类等等等等书籍。你突然意识到了一些问题的严重性,工作量大倒还不算什么,但再这么写下去,你的方法就要爆炸了,这么多的方法让人看都看不过来,别提怎么使用了。
这个时候你只好向你的leader求助了,跟他说明了你的困惑。只见你的leader思考了片刻,然后自信地告诉你,使用组合模式不仅可以轻松消除你的困惑,还能出色地完成功能。
他立刻向你秀起了编码操作,首先定义一个Statistics类,里面有两个方法:
class Statistics
def get_browse_count
raise "You should override this method in subclass."
end
def get_sale_count
raise "You should override this method in subclass."
end
end
这两个方法都是简单地抛出一个异常,因为需要在子类中重写这两个方法。
然后定义一个用于统计小说类书籍的NovelStatistics类,继承刚刚定义的Statistics类,并重写Statistics中的两个方法:
class NovelStatistics < Statistics
def get_browse_count
browse_count = 0
all_novels = get_all_novels()
all_novels.each do |novel|
browse_count += get_browse_count(novel)
end
browse_count
end
def get_sale_count
sale_count = 0
all_novels = get_all_novels()
all_novels.each do |novel|
sale_count += get_browse_count(novel)
end
sale_count
end
end
在这两个方法中分别统计了小说类书籍的浏览量和销售量。那么同样的方法,你的leader又定义了一个ComputerBookStatistics类用于统计计算机类书籍的浏览量和销售量:
class ComputerBookStatistics < Statistics
def get_browse_count
browse_count = 0
all_computer_books = get_all_computer_books()
all_computer_books.each do |computer_book|
browse_count += get_browse_count(computer_book)
end
browse_count
end
def get_sale_count
sale_count = 0
all_computer_books = get_all_computer_books()
all_computer_books.each do |computer_book|
sale_count += get_browse_count(computer_book)
end
sale_count
end
end
这样将具体的统计实现分散在各个类中,就不会再出现你刚刚那种方法爆炸的情况了。不过这还没开始真正使用组合模式呢,好戏还在后头,你的leader吹嘘道。
再定义一个MedicalBookStatistics类继承Statistics,用于统计医学类书籍的浏览量和销售量,代码如下如示:
class MedicalBookStatistics < Statistics
def get_browse_count
browse_count = 0
all_medical_books = get_all_medical_books()
all_medical_books.each do |medical_book|
browse_count += get_browse_count(medical_book)
end
browse_count
end
def get_sale_count
sale_count = 0
all_medical_books = get_all_medical_books()
all_medical_books.each do |medical_book|
sale_count += get_browse_count(medical_book)
end
sale_count
end
end
不知道你发现了没有,计算机类书籍和医学类书籍其实都算是科技类书籍,它们是可以组合在一起的。这个时候你的leader定义了一个TechnicalStatistics类用于对科技这一组合类书籍进行统计:
class TechnicalStatistics < Statistics
def initialize
@statistics = []
@statistics << ComputerBookStatistics.new
@statistics << MedicalBookStatistics.new
end
def get_browse_count
browse_count = 0
@statistics.each do |s|
browse_count += s.get_browse_count
end
browse_count
end
def get_sale_count
sale_count = 0
@statistics.each do |s|
sale_count += s.get_sale_count
end
sale_count
end
end
可以看到,由于这个类是组合类,和前面几个类还是有不少区别的。首先TechnicalStatistics中有一个构造函数,在构造函数中将计算机类书籍和医学类书籍作为子分类添加到statistics数组当中,然后分别在get_browse_count和get_sale_count方法中遍历所有的子分类,计算出它们各自的浏览量和销售量,然后相加得到总额返回。
组合模式的扩展性非常好,没有各种条条框框,想怎么组合就怎么组合,比如所有书籍就是由各个分类组合而来的,你的leader马上又向你炫耀了统计所有书籍的浏览量和销售量的办法。
定义一个AllStatistics类继承Statistics,具体代码如下所示:
class AllStatistics < Statistics
def initialize
@statistics = []
@statistics << NovelStatistics.new
@statistics << TechnicalStatistics.new
end
def get_browse_count
browse_count = 0
@statistics.each do |s|
browse_count += s.get_browse_count
end
browse_count
end
def get_sale_count
sale_count = 0
@statistics.each do |s|
sale_count += s.get_sale_count
end
sale_count
end
end
在AllStatistics的构造函数中将小说类书籍和科技类书籍作为子分类添加到了statistics数组当中,目前你也就只写好了这几个分类。然后使用同样的方法在get_browse_count和get_sale_count方法中统计出所有书籍的浏览量和销售量。
当前组合结构的示意图如下:
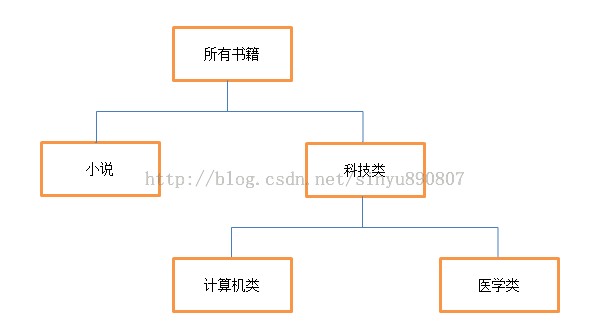
现在你就可以非常方便的得到任何分类书籍的浏览量和销售量了,比如说获取科技类书籍的浏览量,你只需要调用:
TechnicalStatistics.new.get_browse_count
而获取所有书籍的总销量,你只需要调用:
AllStatistics.new.get_sale_count
当然你后面还可以对这个组合结构随意地改变,添加各种子分类书籍,而且子分类的层次结构可以任意深,正如前面所说,组合模式的扩展性非常好。
你的leader告诉你,目前他写的这份代码重复度比较高,其实还可以好好优化一下的,把冗余代码都去除掉。当然这个任务就交给你来做了,你的leader可是大忙人,早就一溜烟跑开了。
总结
组合模式的优点:
能够灵活的组合局部对象和整体对象之间的关心,对客户端来说,局部对象和整体对象的调用没有差别,使调用简单。
组合模式的缺点:
1.组合操作的成本很高,如果一个对象树中有很多子对象,可能一个简单的调用就可能使系统崩溃;
2.对象持久化的问题,组合模式是树形结构,不能很好地在关系数据库中保存数据,但是却非常适合用于xml持久化。
组合模式的适用场景:
1.维护和展示部分—整体关系得场景,如树形菜单、文件和文件夹管理。
2.从一个整体中能够独立出部分模块或功能的场景。
最后
以上就是大力水壶最近收集整理的关于详解组合模式的结构及其在Ruby设计模式编程中的运用的全部内容,更多相关详解组合模式内容请搜索靠谱客的其他文章。








发表评论 取消回复