Ceph是统一存储系统,支持三种接口。
Object:有原生的API,而且也兼容Swift和S3的API
Block:支持精简配置、快照、克隆
File:Posix接口,支持快照
Ceph也是分布式存储系统,它的特点是:
高扩展性:使用普通x86服务器,支持10~1000台服务器,支持TB到PB级的扩展。
高可靠性:没有单点故障,多数据副本,自动管理,自动修复。
高性能:数据分布均衡,并行化度高。对于objects storage和block storage,不需要元数据服务器。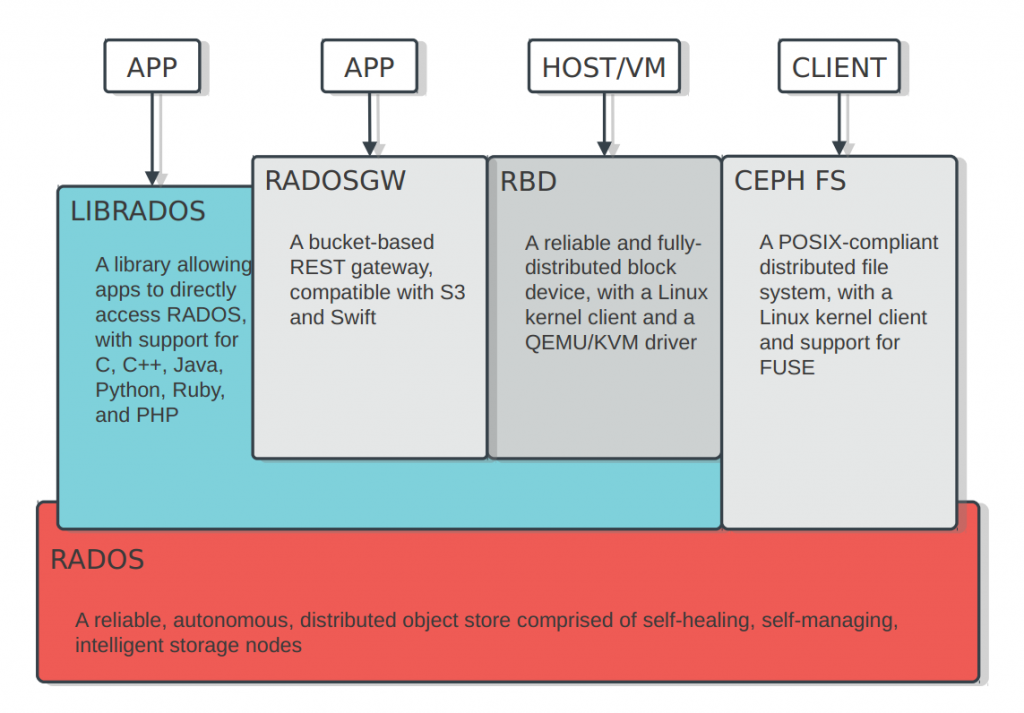
架构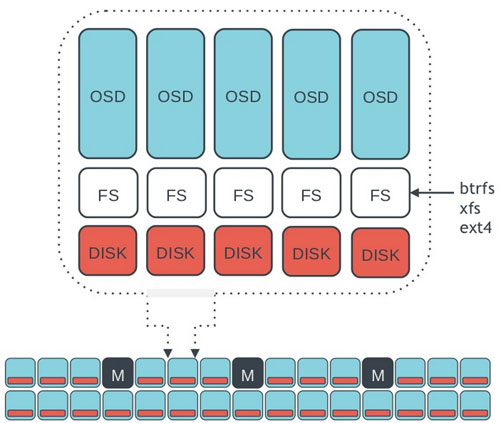
Ceph的底层是RADOS,它的意思是“A reliable, autonomous, distributed object storage”。 RADOS由两个组件组成:
OSD: Object Storage Device,提供存储资源。
Monitor:维护整个Ceph集群的全局状态。
RADOS具有很强的扩展性和可编程性,Ceph基于RADOS开发了
Object Storage、Block Storage、FileSystem。Ceph另外两个组件是:
MDS:用于保存CephFS的元数据。
RADOS Gateway:对外提供REST接口,兼容S3和Swift的API。
映射
Ceph的命名空间是 (Pool, Object),每个Object都会映射到一组OSD中(由这组OSD保存这个Object):
(Pool, Object) → (Pool, PG) → OSD set → Disk
Ceph中Pools的属性有:
Object的副本数
Placement Groups的数量
所使用的CRUSH Ruleset
在Ceph中,Object先映射到PG(Placement Group),再由PG映射到OSD set。每个Pool有多个PG,每个Object通过计算hash值并取模得到它所对应的PG。PG再映射到一组OSD(OSD的个数由Pool 的副本数决定),第一个OSD是Primary,剩下的都是Replicas。
数据映射(Data Placement)的方式决定了存储系统的性能和扩展性。(Pool, PG) → OSD set 的映射由四个因素决定:
CRUSH算法:一种伪随机算法。
OSD MAP:包含当前所有Pool的状态和所有OSD的状态。
CRUSH MAP:包含当前磁盘、服务器、机架的层级结构。
CRUSH Rules:数据映射的策略。这些策略可以灵活的设置object存放的区域。比如可以指定 pool1中所有objecst放置在机架1上,所有objects的第1个副本放置在机架1上的服务器A上,第2个副本分布在机架1上的服务器B上。 pool2中所有的object分布在机架2、3、4上,所有Object的第1个副本分布在机架2的服务器上,第2个副本分布在机架3的服 器上,第3个副本分布在机架4的服务器上。
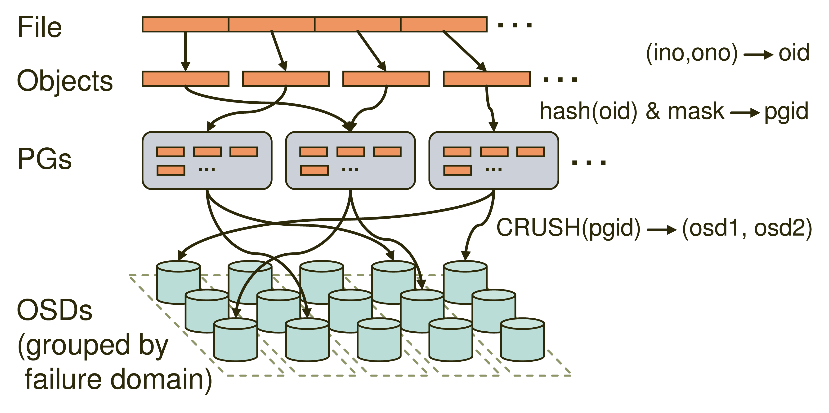
Client从Monitors中得到CRUSH MAP、OSD MAP、CRUSH Ruleset,然后使用CRUSH算法计算出Object所在的OSD set。所以Ceph不需要Name服务器,Client直接和OSD进行通信。伪代码如下所示:
locator = object_name
obj_hash = hash(locator)
pg = obj_hash % num_pg
osds_for_pg = crush(pg) # returns a list of osds
primary = osds_for_pg[0]
replicas = osds_for_pg[1:]
这种数据映射的优点是:
把Object分成组,这降低了需要追踪和处理metadata的数量(在全局的层面上,我们不需要追踪和处理每个object的metadata和placement,只需要管理PG的metadata就可以了。PG的数量级远远低于object的数量级)。
增加PG的数量可以均衡每个OSD的负载,提高并行度。
分隔故障域,提高数据的可靠性。
强一致性
Ceph的读写操作采用Primary-Replica模型,Client只向Object所对应OSD set的Primary发起读写请求,这保证了数据的强一致性。
由于每个Object都只有一个Primary OSD,因此对Object的更新都是顺序的,不存在同步问题。
当Primary收到Object的写请求时,它负责把数据发送给其他Replicas,只要这个数据被保存在所有的OSD上时,Primary才应答Object的写请求,这保证了副本的一致性。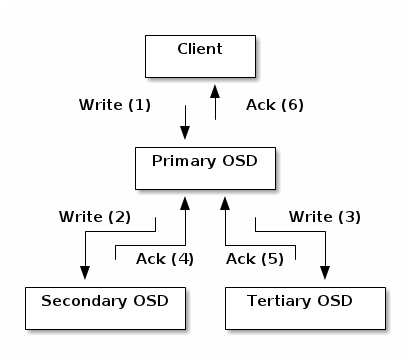
容错性
在分布式系统中,常见的故障有网络中断、掉电、服务器宕机、硬盘故障等,Ceph能够容忍这些故障,并进行自动修复,保证数据的可靠性和系统可用性。
Monitors是Ceph管家,维护着Ceph的全局状态。Monitors的功能和zookeeper类似,它们使用Quorum和Paxos算法去建立全局状态的共识。
OSDs可以进行自动修复,而且是并行修复。
故障检测:
OSD之间有心跳检测,当OSD A检测到OSD B没有回应时,会报告给Monitors说OSD B无法连接,则Monitors给OSD B标记为down状态,并更新OSD Map。当过了M秒之后还是无法连接到OSD B,则Monitors给OSD B标记为out状态(表明OSD B不能工作),并更新OSD Map。
备注:可以在Ceph中配置M的值。
故障恢复:
当某个PG对应的OSD set中有一个OSD被标记为down时(假如是Primary被标记为down,则某个Replica会成为新的Primary,并处理所有读写 object请求),则该PG处于active+degraded状态,也就是当前PG有效的副本数是N-1。
过了M秒之后,假如还是无法连接该OSD,则它被标记为out,Ceph会重新计算PG到OSD set的映射(当有新的OSD加入到集群时,也会重新计算所有PG到OSD set的映射),以此保证PG的有效副本数是N。
新OSD set的Primary先从旧的OSD set中收集PG log,得到一份Authoritative History(完整的、全序的操作序列),并让其他Replicas同意这份Authoritative History(也就是其他Replicas对PG的所有objects的状态达成一致),这个过程叫做Peering。
当Peering过程完成之后,PG进 入active+recoverying状态,Primary会迁移和同步那些降级的objects到所有的replicas上,保证这些objects 的副本数为N。
下面来看一下部署与配置
系统环境:Ubuntu 12.04.2
hostname:s1 osd.0/mon.a/mds.a ip:192.168.242.128
hostname:s2 osd.1/mon.b/mds.b ip:192.168.242.129
hostname:s3 osd.2/mon.c/mds.c ip:192.168.242.130
hostname:s4 client ip:192.168.242.131
免密钥:
s1/s2/s3 启用root,相互之间配置免密钥。
cat id_rsa.pub_s* >> authorized_keys
安装:
apt-get install ceph ceph-common ceph-fs-common (ceph-mds)
更新到新版本:
wget -q -O- ‘https://ceph.com/git/?p=ceph.git;a=blob_plain;f=keys/release.asc’| sudo apt-key add -
echo deb http://ceph.com/debian/ $(lsb_release -sc) main | tee /etc/apt/sources.list.d/ceph.list
apt-get update
apt-get install ceph
分区及挂载(使用btrfs):
root@s1:/data/osd.0# df -h|grep osd
/dev/sdb1 20G 180M 19G 1% /data/osd.0
root@s2:/data/osd.1# df -h|grep osd
/dev/sdb1 20G 173M 19G 1% /data/osd.1
root@s3:/data/osd.2# df -h|grep osd
/dev/sdb1 20G 180M 19G 1% /data/osd.2
root@s1:~/.ssh# mkdir -p /tmp/ceph/(每个server上执行)
配置:
root@s1:/data/osd.0# vim /etc/ceph/ceph.conf
[global]
auth cluster required = none
auth service required = none
auth client required = none
[osd]
osd data = /data/$name
[mon]
mon data = /data/$name
[mon.a]
host = s1
mon addr = 192.168.242.128:6789
[mon.b]
host = s2
mon addr = 192.168.242.129:6789
[mon.c]
host = s3
mon addr = 192.168.242.130:6789
[osd.0]
host = s1
brtfs devs = /dev/sdb1
[osd.1]
host = s2
brtfs devs = /dev/sdb1
[osd.2]
host = s3
brtfs devs = /dev/sdb1
[mds.a]
host = s1
[mds.b]
host = s2
[mds.c]
host = s3
同步配置:
root@s1:~/.ssh# scp /etc/ceph/ceph.conf s2:/etc/ceph/
ceph.conf 100% 555 0.5KB/s 00:00
root@s1:~/.ssh# scp /etc/ceph/ceph.conf s3:/etc/ceph/
ceph.conf 100% 555 0.5KB/s 00:00
所有server上执行:
rm -rf /data/$name/* /data/mon/*(初始化前保持没有任何数据)
root@s1:~/.ssh# mkcephfs -a -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.keyring
temp dir is /tmp/mkcephfs.qLmwP4Nd0G
preparing monmap in /tmp/mkcephfs.qLmwP4Nd0G/monmap
/usr/bin/monmaptool –create –clobber –add a 192.168.242.128:6789 –add b 192.168.242.129:6789 –add c 192.168.242.130:6789 –print /tmp/mkcephfs.qLmwP4Nd0G/monmap
/usr/bin/monmaptool: monmap file /tmp/mkcephfs.qLmwP4Nd0G/monmap
/usr/bin/monmaptool: generated fsid c26fac57-4941-411f-a6ac-3dcd024f2073
epoch 0
fsid c26fac57-4941-411f-a6ac-3dcd024f2073
last_changed 2014-05-08 16:08:06.102237
created 2014-05-08 16:08:06.102237
0: 192.168.242.128:6789/0 mon.a
1: 192.168.242.129:6789/0 mon.b
2: 192.168.242.130:6789/0 mon.c
/usr/bin/monmaptool: writing epoch 0 to /tmp/mkcephfs.qLmwP4Nd0G/monmap (3 monitors)
=== osd.0 ===
** WARNING: No osd journal is configured: write latency may be high.
If you will not be using an osd journal, write latency may be
relatively high. It can be reduced somewhat by lowering
filestore_max_sync_interval, but lower values mean lower write
throughput, especially with spinning disks.
2014-05-08 16:08:11.279610 b72cc740 created object store /data/osd.0 for osd.0 fsid c26fac57-4941-411f-a6ac-3dcd024f2073
creating private key for osd.0 keyring /tmp/mkcephfs.qLmwP4Nd0G/keyring.osd.0
creating /tmp/mkcephfs.qLmwP4Nd0G/keyring.osd.0
=== osd.1 ===
pushing conf and monmap to s2:/tmp/mkfs.ceph.5884
** WARNING: No osd journal is configured: write latency may be high.
If you will not be using an osd journal, write latency may be
relatively high. It can be reduced somewhat by lowering
filestore_max_sync_interval, but lower values mean lower write
throughput, especially with spinning disks.
2014-05-08 16:08:21.146302 b7234740 created object store /data/osd.1 for osd.1 fsid c26fac57-4941-411f-a6ac-3dcd024f2073
creating private key for osd.1 keyring /tmp/mkfs.ceph.5884/keyring.osd.1
creating /tmp/mkfs.ceph.5884/keyring.osd.1
collecting osd.1 key
=== osd.2 ===
pushing conf and monmap to s3:/tmp/mkfs.ceph.5884
** WARNING: No osd journal is configured: write latency may be high.
If you will not be using an osd journal, write latency may be
relatively high. It can be reduced somewhat by lowering
filestore_max_sync_interval, but lower values mean lower write
throughput, especially with spinning disks.
2014-05-08 16:08:27.264484 b72b3740 created object store /data/osd.2 for osd.2 fsid c26fac57-4941-411f-a6ac-3dcd024f2073
creating private key for osd.2 keyring /tmp/mkfs.ceph.5884/keyring.osd.2
creating /tmp/mkfs.ceph.5884/keyring.osd.2
collecting osd.2 key
=== mds.a ===
creating private key for mds.a keyring /tmp/mkcephfs.qLmwP4Nd0G/keyring.mds.a
creating /tmp/mkcephfs.qLmwP4Nd0G/keyring.mds.a
=== mds.b ===
pushing conf and monmap to s2:/tmp/mkfs.ceph.5884
creating private key for mds.b keyring /tmp/mkfs.ceph.5884/keyring.mds.b
creating /tmp/mkfs.ceph.5884/keyring.mds.b
collecting mds.b key
=== mds.c ===
pushing conf and monmap to s3:/tmp/mkfs.ceph.5884
creating private key for mds.c keyring /tmp/mkfs.ceph.5884/keyring.mds.c
creating /tmp/mkfs.ceph.5884/keyring.mds.c
collecting mds.c key
Building generic osdmap from /tmp/mkcephfs.qLmwP4Nd0G/conf
/usr/bin/osdmaptool: osdmap file ‘/tmp/mkcephfs.qLmwP4Nd0G/osdmap’
2014-05-08 16:08:26.100746 b731e740 adding osd.0 at {host=s1,pool=default,rack=unknownrack}
2014-05-08 16:08:26.101413 b731e740 adding osd.1 at {host=s2,pool=default,rack=unknownrack}
2014-05-08 16:08:26.101902 b731e740 adding osd.2 at {host=s3,pool=default,rack=unknownrack}
/usr/bin/osdmaptool: writing epoch 1 to /tmp/mkcephfs.qLmwP4Nd0G/osdmap
Generating admin key at /tmp/mkcephfs.qLmwP4Nd0G/keyring.admin
creating /tmp/mkcephfs.qLmwP4Nd0G/keyring.admin
Building initial monitor keyring
added entity mds.a auth auth(auid = 18446744073709551615 key=AQB3O2tTwDNwLRAAofpkrOMqtHCPTFX36EKAMA== with 0 caps)
added entity mds.b auth auth(auid = 18446744073709551615 key=AQB8O2tT8H8nIhAAq1O2lh4IV/cQ73FUUTOUug== with 0 caps)
added entity mds.c auth auth(auid = 18446744073709551615 key=AQB9O2tTWIfsKRAAVYeueMToC85tRSvlslV/jQ== with 0 caps)
added entity osd.0 auth auth(auid = 18446744073709551615 key=AQBrO2tTOLQpEhAA4MS83CnJRYAkoxrFSvC3aQ== with 0 caps)
added entity osd.1 auth auth(auid = 18446744073709551615 key=AQB1O2tTME0eChAA7U4xSrv7MJUZ8vxcEkILbw== with 0 caps)
added entity osd.2 auth auth(auid = 18446744073709551615 key=AQB7O2tT0FUKERAAQ/EJT5TclI2XSCLAWAZZOw== with 0 caps)
=== mon.a ===
/usr/bin/ceph-mon: created monfs at /data/mon for mon.a
=== mon.b ===
pushing everything to s2
/usr/bin/ceph-mon: created monfs at /data/mon for mon.b
=== mon.c ===
pushing everything to s3
/usr/bin/ceph-mon: created monfs at /data/mon for mon.c
placing client.admin keyring in /etc/ceph/ceph.keyring
上面提示了没有配置journal。
root@s1:~# /etc/init.d/ceph -a start
=== mon.a ===
Starting Ceph mon.a on s1…already running
=== mds.a ===
Starting Ceph mds.a on s1…already running
=== osd.0 ===
Starting Ceph osd.0 on s1…
** WARNING: Ceph is still under development. Any feedback can be directed **
** at ceph-devel@vger.kernel.org or http://ceph.newdream.net/. **
starting osd.0 at 0.0.0.0:6801/2264 osd_data /data/osd.0 (no journal)
查看状态:
root@s1:~# ceph -s
2014-05-09 09:37:40.477978 pg v444: 594 pgs: 594 active+clean; 38199 bytes data, 531 MB used, 56869 MB / 60472 MB avail
2014-05-09 09:37:40.485092 mds e23: 1/1/1 up {0=a=up:active}, 2 up:standby
2014-05-09 09:37:40.485601 osd e34: 3 osds: 3 up, 3 in
2014-05-09 09:37:40.486276 log 2014-05-09 09:36:25.843782 mds.0 192.168.242.128:6800/1053 1 : [INF] closing stale session client.4104 192.168.242.131:0/2123448720 after 302.954724
2014-05-09 09:37:40.486577 mon e1: 3 mons at {a=192.168.242.128:6789/0,b=192.168.242.129:6789/0,c=192.168.242.130:6789/0}</p> <p>root@s1:~# for i in 1 2 3 ;do ceph health;done
2014-05-09 10:05:30.306575 mon <- [health]
2014-05-09 10:05:30.309366 mon.1 -> ‘HEALTH_OK’ (0)
2014-05-09 10:05:30.330317 mon <- [health]
2014-05-09 10:05:30.333608 mon.2 -> ‘HEALTH_OK’ (0)
2014-05-09 10:05:30.352617 mon <- [health]
2014-05-09 10:05:30.353984 mon.0 -> ‘HEALTH_OK’ (0)
并同时查看 s1、s2、s3 log可以看到,证明3个节点都正常:
2014-05-09 09:39:32.316795 b4bfeb40 mon.a@0(leader) e1 handle_command mon_command(health v 0) v1
2014-05-09 09:39:40.789748 b4bfeb40 mon.a@0(leader).osd e35 e35: 3 osds: 3 up, 3 in
2014-05-09 09:40:00.796979 b4bfeb40 mon.a@0(leader).osd e36 e36: 3 osds: 3 up, 3 in
2014-05-09 09:40:41.781141 b4bfeb40 mon.a@0(leader) e1 handle_command mon_command(health v 0) v1
2014-05-09 09:40:42.409235 b4bfeb40 mon.a@0(leader) e1 handle_command mon_command(health v 0) v1
log 里面会看到如下时间未同步信息:
2014-05-09 09:43:13.485212 b49fcb40 log [WRN] : message from mon.0 was stamped 6.050738s in the future, clocks not synchronized
2014-05-09 09:43:13.861985 b49fcb40 log [WRN] : message from mon.0 was stamped 6.050886s in the future, clocks not synchronized
2014-05-09 09:43:14.012633 b49fcb40 log [WRN] : message from mon.0 was stamped 6.050681s in the future, clocks not synchronized
2014-05-09 09:43:15.809439 b49fcb40 log [WRN] : message from mon.0 was stamped 6.050781s in the future, clocks not synchronized
所以我们在做集群之前最好能在集群内部做好ntp服务器,确保各节点之前时间一致。
3. 接下来在客户机s4上进行验证操作:
root@s4:/mnt# mount -t ceph s1:6789:/ /mnt/s1fs/
root@s4:/mnt# mount -t ceph s2:6789:/ /mnt/s2fs/
root@s4:/mnt# mount -t ceph s3:6789:/ /mnt/s3fs/
root@s4:~# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda1 79G 1.3G 74G 2% /
udev 241M 4.0K 241M 1% /dev
tmpfs 100M 304K 99M 1% /run
none 5.0M 0 5.0M 0% /run/lock
none 248M 0 248M 0% /run/shm
192.168.242.130:6789:/ 60G 3.6G 56G 6% /mnt/s3fs
192.168.242.129:6789:/ 60G 3.6G 56G 6% /mnt/s2fs
192.168.242.128:6789:/ 60G 3.6G 56G 6% /mnt/s1fs</p> <p>root@s4:/mnt/s2fs# touch aa
root@s4:/mnt/s2fs# ls -al /mnt/s1fs
total 4
drwxr-xr-x 1 root root 0 May 8 18:08 ./
drwxr-xr-x 7 root root 4096 May 8 17:28 ../
-rw-r–r– 1 root root 0 May 8 18:08 aa
root@s4:/mnt/s2fs# ls -al /mnt/s3fs
total 4
drwxr-xr-x 1 root root 0 May 8 18:08 ./
drwxr-xr-x 7 root root 4096 May 8 17:28 ../
-rw-r–r– 1 root root 0 May 8 18:08 aa</p> <p>root@s4:/mnt/s2fs# rm -f aa
root@s4:/mnt/s2fs# ls -al /mnt/s1fs/
total 4
drwxr-xr-x 1 root root 0 May 8 2014 ./
drwxr-xr-x 7 root root 4096 May 8 17:28 ../
root@s4:/mnt/s2fs# ls -al /mnt/s3fs/
total 4
drwxr-xr-x 1 root root 0 May 8 18:07 ./
drwxr-xr-x 7 root root 4096 May 8 17:28 ../
接下来我们验证单点故障:
将s1服务停掉,
root@s1:~# /etc/init.d/ceph stop
=== mon.a ===
Stopping Ceph mon.a on s1…kill 965…done
=== mds.a ===
Stopping Ceph mds.a on s1…kill 1314…done
=== osd.0 ===
Stopping Ceph osd.0 on s1…kill 2265…done
s2上log 立马显示:
省掉了很多,基本的意思就是mon监控中心发现,剔除故障节点,进行自动切换,集群恢复。
2014-05-09 10:16:44.906370 a5af0b40 — 192.168.242.129:6802/1495 >> 192.168.242.128:6802/1466 pipe(0xb1e1b1a8 sd=19 pgs=3 cs=3 l=0).fault with nothing to send, going to standby
2014-05-09 10:16:44.906982 a68feb40 — 192.168.242.129:6803/1495 >> 192.168.242.128:0/1467 pipe(0xa6e00d50 sd=17 pgs=1 cs=1 l=0).fault with nothing to send, going to standby
2014-05-09 10:16:44.907415 a63f9b40 — 192.168.242.129:0/1506 >> 192.168.242.128:6803/1466 pipe(0xb1e26d50 sd=20 pgs=1 cs=1 l=0).fault with nothing to send, going to standby
2014-05-09 10:16:49.028640 b5199b40 mds.0.6 handle_mds_map i am now mds.0.6
2014-05-09 10:16:49.029018 b5199b40 mds.0.6 handle_mds_map state change up:reconnect –> up:rejoin
2014-05-09 10:16:49.029260 b5199b40 mds.0.6 rejoin_joint_start
2014-05-09 10:16:49.032134 b5199b40 mds.0.6 rejoin_done
==> /var/log/ceph/mon.b.log <==
2014-05-09 10:16:49.060870 b5198b40 log [INF] : mds.0 192.168.242.129:6804/1341 up:active
==> /var/log/ceph/mds.b.log <==
2014-05-09 10:16:49.073135 b5199b40 mds.0.6 handle_mds_map i am now mds.0.6
2014-05-09 10:16:49.073237 b5199b40 mds.0.6 handle_mds_map state change up:rejoin --> up:active
2014-05-09 10:16:49.073252 b5199b40 mds.0.6 recovery_done — successful recovery!
2014-05-09 10:16:49.073871 b5199b40 mds.0.6 active_start
2014-05-09 10:16:49.073934 b5199b40 mds.0.6 cluster recovered.
==> /var/log/ceph/mds.b.log <==
2014-05-09 10:16:49.073135 b5199b40 mds.0.6 handle_mds_map i am now mds.0.6
2014-05-09 10:16:49.073237 b5199b40 mds.0.6 handle_mds_map state change up:rejoin --> up:active
2014-05-09 10:16:49.073252 b5199b40 mds.0.6 recovery_done — successful recovery!
2014-05-09 10:16:49.073871 b5199b40 mds.0.6 active_start
2014-05-09 10:16:49.073934 b5199b40 mds.0.6 cluster recovered.
==> /var/log/ceph/mon.b.log <==
2014-05-09 10:18:24.366217 b5198b40 mon.b@1(leader) e1 handle_command mon_command(health v 0) v1
2014-05-09 10:18:25.717589 b5198b40 mon.b@1(leader) e1 handle_command mon_command(health v 0) v1
2014-05-09 10:18:29.481811 b5198b40 mon.b@1(leader) e1 handle_command mon_command(health v 0) v1
2014-05-09 10:21:39.184889 b4997b40 log [INF] : osd.0 out (down for 303.572445)
2014-05-09 10:21:39.195596 b5198b40 mon.b@1(leader).osd e42 e42: 3 osds: 2 up, 2 in
2014-05-09 10:21:40.199772 b5198b40 mon.b@1(leader).osd e43 e43: 3 osds: 2 up, 2 in
root@s2:~# ceph -s
2014-05-09 10:24:18.075291 pg v501: 594 pgs: 594 active+clean; 47294 bytes data, 359 MB used, 37907 MB / 40315 MB avail
2014-05-09 10:24:18.093637 mds e27: 1/1/1 up {0=b=up:active}, 1 up:standby
2014-05-09 10:24:18.094047 osd e43: 3 osds: 2 up, 2 in
2014-05-09 10:24:18.094833 log 2014-05-09 10:21:39.185547 mon.1 192.168.242.129:6789/0 40 : [INF] osd.0 out (down for 303.572445)
2014-05-09 10:24:18.095606 mon e1: 3 mons at {a=192.168.242.128:6789/0,b=192.168.242.129:6789/0,c=192.168.242.130:6789/0}
root@s1:~# ceph health
2014-05-09 10:18:43.185714 mon <- [health]
2014-05-09 10:18:43.189028 mon.2 -> ‘HEALTH_WARN 1/3 in osds are down; 1 mons down, quorum 1,2′ (0)
root@s2:~# ceph health
2014-05-09 10:23:40.655548 mon <- [health]
2014-05-09 10:23:40.658293 mon.2 -> ‘HEALTH_WARN 1 mons down, quorum 1,2′ (0)
root@s3:~# ceph health
2014-05-09 10:23:28.058080 mon <- [health]
2014-05-09 10:23:28.061126 mon.1 -> ‘HEALTH_WARN 1 mons down, quorum 1,2′ (0)
再接下来,关闭s2,只开启s3:
s3上log显示大量
==> /var/log/ceph/mds.c.log <==
2014-05-09 10:33:04.274503 b5180b40 mds.-1.0 ms_handle_connect on 192.168.242.130:6789/0</p> <p>==> /var/log/ceph/osd.2.log <==
2014-05-09 10:33:04.832597 b4178b40 osd.2 43 heartbeat_check: no heartbeat from osd.1 since 2014-05-09 10:29:54.607954 (cutoff 2014-05-09 10:32:44.832568)
2014-05-09 10:33:05.084620 a7be9b40 osd.2 43 heartbeat_check: no heartbeat from osd.1 since 2014-05-09 10:29:54.607954 (cutoff 2014-05-09 10:32:45.084592)
2014-05-09 10:33:05.585583 a7be9b40 osd.2 43 heartbeat_check: no heartbeat from osd.1 since 2014-05-09 10:29:54.607954 (cutoff 2014-05-09 10:32:45.585553)
2014-05-09 10:33:05.834589 b4178b40 osd.2 43 heartbeat_check: no heartbeat from osd.1 since 2014-05-09 10:29:54.607954 (cutoff 2014-05-09 10:32:45.834559)
2014-05-09 10:33:06.086562 a7be9b40 osd.2 43 heartbeat_check: no heartbeat from osd.1 since 2014-05-09 10:29:54.607954 (cutoff 2014-05-09 10:32:46.086533)
2014-05-09 10:33:06.835683 b4178b40 osd.2 43 heartbeat_check: no heartbeat from osd.1 since 2014-05-09 10:29:54.607954 (cutoff 2014-05-09 10:32:46.835641)
2014-05-09 10:33:07.287766 a7be9b40 osd.2 43 heartbeat_check: no heartbeat from osd.1 since 2014-05-09 10:29:54.607954 (cutoff 2014-05-09 10:32:47.287737)
健康检测不能从s2上的osd.1 获取no heartbeat 。
s1、s2、s3上都有mon、mds、osd。但是总个集群中只有一个节点,所以不能提供服务。
最后
以上就是听话小霸王最近收集整理的关于在Ubuntu系统上部署分布式系统Ceph的全部内容,更多相关在Ubuntu系统上部署分布式系统Ceph内容请搜索靠谱客的其他文章。








发表评论 取消回复