对于数据库来说,索引是一个必选项,但对于现在的各种大型数据库来说,索引可以大大提高数据库的性能,以至于它变成了数据库不可缺少的一部分。
索引分类:
逻辑分类
single column or concatenated 对一列或多列建所引
unique or nonunique 唯一的和非唯一的所引,也就是对某一列或几列的键值(key)是否是唯一的。
Function-based 基于某些函数索引,当执行某些函数时需要对其进行计算,可以将某些函数的计算结果事先保存并加以索引,提高效率。
Doman 索引数据库以外的数据,使用相对较少
物理分类
B-Tree :normal or reverse key B-Tree索引也是我们传统上常见所理解的索引,它又可以分为正常所引和倒序索引。
Bitmap : 位图所引,后面会细讲
B-Tree 索引
B-Tree index 也是我们传统上常见所理解的索引。B-tree (balance tree)即平衡树,左右两个分支相对平衡。
B-Tree index

Root为根节点,branch 为分支节点,leaf 到最下面一层称为叶子节点。每个节点表示一层,当查找某一数据时先读根节点,再读支节点,最后找到叶子节点。叶子节点会存放index entry (索引入口),每个索引入口对应一条记录。
Index entry 的组成部分:
Indexentry entry header 存放一些控制信息。
Key column length 某一key的长度
Key column value 某一个key 的值
ROWID 指针,具体指向于某一个数据
创建索引:
用户登录:
SQL> conn as1/as1
Connected.
创建表:
SQL> create table dex (id int,sex char(1),name char(10));
Table created.
向表中插入1000条数据
SQL> begin
for i in 1..1000
loop
insert into dex values(i,'M','chongshi');
end loop;
commit;
end;
/
PL/SQL procedure successfully completed.
查看表记录
SQL> select * from dex;
ID SE NAME
---------- -- --------------------
... . .....
M chongshi
M chongshi
M chongshi
M chongshi
M chongshi
M chongshi
M chongshi
M chongshi
M chongshi
M chongshi
rows selected.
创建索引:
SQL> create index dex_idx1 on dex(id);
Index created.
注:对表的第一列(id)创建索引。
查看创建的表与索引
SQL> select object_name,object_type from user_objects;
OBJECT_NAME OBJECT_TYPE
--------------------------------------------------------------------------------
DEX TABLE
DEX_IDX1 INDEX
索引分离于表,作为一个单独的个体存在,除了可以根据单个字段创建索引,也可以根据多列创建索引。Oracle要求创建索引最多不可超过32列。
SQL> create index dex_index2 on dex(sex,name);
Index created.
SQL> select object_name,object_type from user_objects;
OBJECT_NAME OBJECT_TYPE
--------------------------------------------------------------------------------
DEX TABLE
DEX_IDX1 INDEX
DEX_INDEX2 INDEX
这里需要理解:
编写一本书,只有章节页面定好之后再设置目录;数据库索引也是一样,只有先插入好数据,再建立索引。那么我们后续对数据库的内容进行插入、删除,索引也需要随之变化。但索引的修改是由oracle自动完成的。
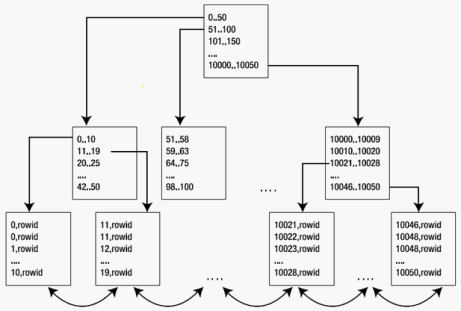
上面这张图能更加清晰的描述索引的结构。
跟节点记录0至50条数据的位置,分支节点进行拆分记录0至10.......42至50,叶子节点记录每第数据的长度和值,并由指针指向具体的数据。
最后一层的叶子节是双向链接,它们是被有序的链接起来,这样才能快速锁定一个数据范围。
如:
SQL> select * from dex where id>23 and id<32;
ID SE NAME
---------- -- --------------------
M chongshi
M chongshi
M chongshi
M chongshi
M chongshi
M chongshi
M chongshi
M chongshi
rows selected.
如上面查找的列子,通过索引的方式先找到第23条数据,再找到第32条数据,这样就能快速的锁定一个查找的范围,如果每条数据都要从根节点开始查找的话,那么效率就会非常低下。
位图索引
位图索引主要针对大量相同值的列而创建。拿全国居民登录一第表来说,假设有四个字段:姓名、性别、年龄、和身份证号,年龄和性别两个字段会产生许多相同的值,性别只有男女两种值,年龄,1到120(假设最大年龄120岁)个值。那么不管一张表有几亿条记录,但根据性别字段来区分的话,只有两种取值(男、女)。那么位图索引就是根据字段的这个特性所建立的一种索引。
Bitmap Index
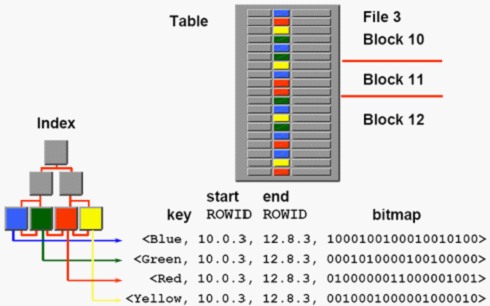
从上图,我们可以看出,一个叶子节点(用不同颜色标识)代表一个key , start rowid 和 end rowid规定这种类型的检索范围,一个叶子节点标记一个唯一的bitmap值。因为一个数值类型对应一个节点,当时行查询时,位图索引通过不同位图取值直接的位运算(与或),来获取到结果集合向量(计算出的结果)。
举例讲解:
假设存在数据表T,有两个数据列A和B,取值如下,我们看到A和B列中存在相同的数据。
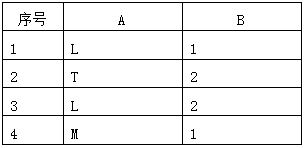
对两个数据列A、B分别建立位图索引:idx_t_bita和idx_t_bitb。两个索引对应的存储逻辑结构如下:
Idx_t_bita索引结构,对应的是叶子节点:
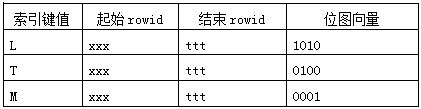
Idx_t_bitb索引结构,对应的是叶子节点:
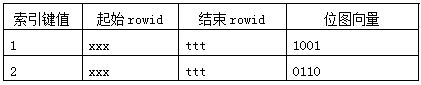
分析:位图索引使用方面,和B*索引有很大的不同。B*索引的使用,通常是从根节点开始,经过不断的分支节点比较到最近的符合条件叶子节点。通过叶子节点上的不断Scan操作,“扫描”出结果集合rowid。
而位图索引的工作方式截然不同。通过不同位图取值直接的位运算(与或),来获取到结果集合向量(计算出的结果)。
针对实例SQL,可以拆分成如下的操作:
1、a='L' or a='M'
a=L:向量:1010
a=M:向量:0001
or操作的结果,就是两个向量的或操作:结果为1011。
2、结合b=1的向量
中间结果向量:1011
B=1:向量:1001
and操作的结果,1001。翻译过来就是第一和第四行是查询结果。
3、获取到结果rowid
目前知道了起始rowid和终止rowid,以及第一行和第四行为操作结果。可以通过试算的方法获取到结果集合rowid。
位图索引的特点:
1.Bitmap索引的存储空间节省
2.Bitmap索引创建的速度快
3.Bitmap索引允许键值为空
4.Bitmap索引对表记录的高效访问
创建位图索引:
查看表记录
SQL> select * from dex;
...................
ID SEX NAME
---------- -- --------------------
M chongshi
M chongshi
G chongshi
G chongshi
G chongshi
M chongshi
G chongshi
G chongshi
G chongshi
M chongshi
rows selected.
对于上面表来说sex(性别)只有两种值,最适合用来创建位图所引
创建索引:
SQL> create bitmap index my_bit_idx on dex(sex);
Index created.
查看创建的所引
SQL> select object_name,object_type from user_objects;
OBJECT_NAME OBJECT_TYPE
--------------------------------------------------------------------------------
MY_BIT_IDX INDEX
创建索引的一些规则
1、权衡索引个数与DML之间关系,DML也就是插入、删除数据操作。
这里需要权衡一个问题,建立索引的目的是为了提高查询效率的,但建立的索引过多,会影响插入、删除数据的速度,因为我们修改的表数据,索引也要跟着修改。这里需要权衡我们的操作是查询多还是修改多。
2、把索引与对应的表放在不同的表空间。
当读取一个表时表与索引是同时进行的。如果表与索引和在一个表空间里就会产生资源竞争,放在两个表这空就可并行执行。
3、最好使用一样大小是块。
Oracle默认五块,读一次I/O,如果你定义6个块或10个块都需要读取两次I/O。最好是5的整数倍更能提高效率。
4、如果一个表很大,建立索引的时间很长,因为建立索引也会产生大量的redo信息,所以在创建索引时可以设置不产生或少产生redo信息。只要表数据存在,索引失败了大不了再建,所以可以不需要产生redo信息。
5、建索引的时候应该根据具体的业务SQL来创建,特别是where条件,还有where条件的顺序,尽量将过滤大范围的放在后面,因为SQL执行是从后往前的。(小李飛菜刀)
索引常见操作
改变索引:
SQL> alter index employees_last _name_idx storage(next 400K maxextents 100);
索引创建后,感觉不合理,也可以对其参数进行修改。详情查看相关文档
调整索引的空间:
新增加空间
SQL> alter index orders_region_id_idx allocate extent (size 200K datafile '/disk6/index01.dbf');
释放空间
SQL> alter index oraers_id_idx deallocate unused;
索引在使用的过程中可能会出现空间不足或空间浪费的情况,这个时候需要新增或释放空间。上面两条命令完成新增与释放操作。关于空间的新增oracle可以自动帮助,如果了解数据库的情况下手动增加可以提高性能。
重新创建索引:
所引是由oracle自动完成,当我们对数据库频繁的操作时,索引也会跟着进行修改,当我们在数据库中删除一条记录时,对应的索引中并没有把相应的索引只是做一个删除标记,但它依然占据着空间。除非一个块中所有的标记全被删除的时,整个块的空间才会被释放。这样时间久了,索引的性能就会下降。这个时候可以重新建立一个干净的索引来提高效率。
SQL> alter index orders_region_id_idx rebuild tablespace index02;
通过上面的命令就可以重现建立一个索引,oracle重建立索引的过程:
1、锁表,锁表之后其他人就不能对表做任何操作。
2、创建新的(干净的)临时索引。
3、把老的索引删除掉
4、把新的索引重新命名为老索引的名字
5、对表进行解锁。
移动所引:
其实,我们移动索引到其它表空间也同样使用上面的命令,在指定表空间时指定不同的表空间。新的索引创建在别位置,把老的干掉,就相当于移动了。
SQL> alter index orders_region_id_idx rebuild tablespace index03;
在线重新创建索引:
上面介绍,在创建索引的时候,表是被锁定,不能被使用。对于一个大表,重新创建索引所需要的时间较长,为了满足用户对表操作的需求,就产生的这种在线重新创建索引。
SQL> alter index orders_id_idx rebuild online;创建过程:
1、锁住表
2、创建立临时的和空的索引和IOT表用来存在on-going DML。普通表存放的键值,IOT所引表直接存放的表中数据;on-gong DML也就是用户所做的一些增删改的操作。
3、对表进行解锁
4、从老的索引创建一个新的索引。
5、IOT表里存放的是on-going DML信息,IOT表的内容与新创建的索引合并。
6、锁住表
7、再次将IOT表的内容更新到新索引中,把老的索引干掉。
8、把新的索引重新命名为老索引的名字
9、对表进行解锁
整合索引碎片:
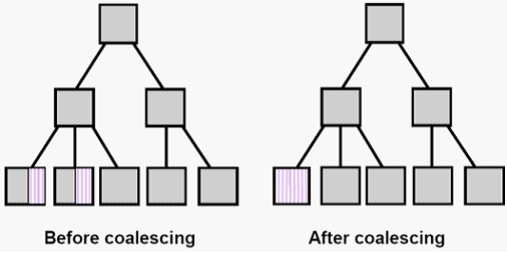
如上图,在很多索引中有剩余的空间,可以通过一个命令把剩余空间整合到一起。
SQL> alter index orders_id_idx coalesce;
删除索引:
SQL> drop index hr.departments_name_idx;
分析索引
检查所引的有效果,前面介绍,索引用的时间久了会产生大量的碎片、垃圾信息与浪费的剩余空间了。可以通过重新创建索引来提高所引的性能。

可以通过一条命令来完成分析索引,分析的结果会存放在在index_stats表中。
查看存放分析数据的表:
SQL> select count(*) from index_stats;
COUNT(*)
----------
执行分析索引命令:
SQL> analyze index my_bit_idx validate structure;
Index analyzed.
再次查看 index_stats 已经有了一条数据
SQL> select count(*) from index_stats;
COUNT(*)
----------
把数据查询出来:
SQL> select height,name,lf_rows,lf_blks,del_lf_rows from index_stats;
HEIGHT NAME LF_ROWS LF_BLKS DEL_LF_ROWS
---------- ---------------------------------------------------------------------- ---------- -----------
MY_BIT_IDX 1000 3 100
分析数据分析:
(HEIGHT)这个所引高度是2 ,(NAME)索引名为MY_BIT_IDX ,(LF_ROWS)所引表有1000行数据,(LF_BLKS)占用3个块,(DEL_LF_ROWS)删除100条记录。
这里也验证了前面所说的一个问题,删除的100条数据只是标记为删除,因为总的数据条数依然为1000条,占用3个块,那么每个块大于333条记录,只有删除的数据大于333条记录,这时一个块被清空,总的数据条数才会减少。
最后
以上就是细心河马最近收集整理的关于oracle索引介绍(图文详解)的全部内容,更多相关oracle索引介绍(图文详解)内容请搜索靠谱客的其他文章。








发表评论 取消回复