最近在做一些数据标注的工作,虽然标注数据比较枯燥,但这也是每个做算法的工程师升级打怪的必由之路。使用一些合适的工具往往可以事半功倍,效率UP。
一:数据标注流程
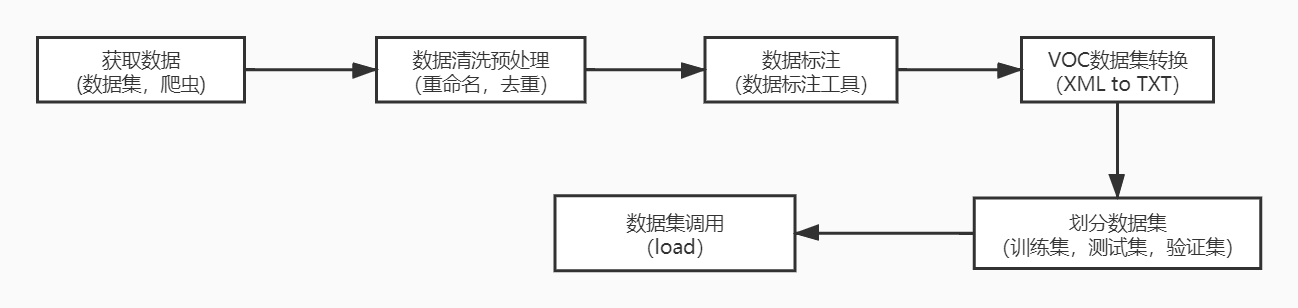
二:数据处理的一些小代码
1:重命名
当得到这样格式命名不一致的数据的时候,重命名是最好的方法。
代码:
#coding=UTF-8
'''
重命名工具
'''
import os
import sys
def rename():
path=input(r"请输入路径(例如D:picture):")
name=input("请输入开头名:")
startNumber=input("请输入开始数:")
fileType=input("请输入后缀名(如 .jpg、.txt等等):")
print("正在生成以"+name+startNumber+fileType+"迭代的文件名")
count=0
filelist=os.listdir(path)
for files in filelist:
Olddir=os.path.join(path,files)
if os.path.isdir(Olddir):
continue
Newdir=os.path.join(path,name+str(count+int(startNumber))+fileType)
os.rename(Olddir,Newdir)
count+=1
print("一共修改了"+str(count)+"个文件")
if __name__ == '__main__':
rename()重命名后的文件会覆盖之前的文件,记得操作之前备份原始数据(如有需要的话)
2:数据标注工具:
对于VOC数据集,使用labelimgs很方便,安装过程也很简单:
开源地址如下:https://github.com/tzutalin/labelImg
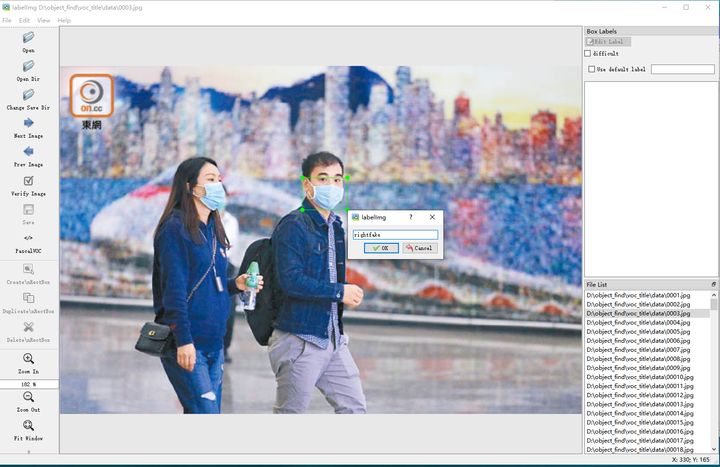
如上图所示,框选完口罩后,点击OK会生成一个跟你文件名一致的XML文件,XML中包括有文件路径,文件名称,以及你给的标签等等信息,如下图:

3:划分数据集
因为要符合VOC数据集格式,这里简单说一下VOC数据集格式类型。做深度学习目标检测方面的同学怎么都会接触到PASCAL VOC这个数据集。也许很少用到整个数据集,但是一般都会按照它的格式准备自己的数据集。所以这里就来记录一下PASCAL VOC的格式,包括目录构成以及各个文件夹的内容格式,方便以后自己按照VOC的标准格式制作自己的数据集。

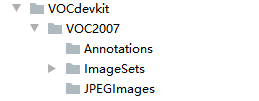
但是我们一般情况下,自己制作数据集不需要Segment开头的,着重关注这三个文件夹:
Annotation文件夹存放的是xml文件,该文件是对图片的解释,每张图片都对于一个同名的xml文件。
ImageSets文件夹存放的是txt文件,这些txt将数据集的图片分成了各种集合。
JPEGImages文件夹存放的是数据集的原图片
转换代码:
import os
import random
xmlfilepath = r'D:/object_find/voc_title/VOCdevkit/VOC2007/Annotations'
saveBasePath = r"D:/object_find/voc_title/VOCdevkit/VOC2007/ImageSets/Main/"
#训练集和验证集所占的比例
trainval_percent = 0.8
train_percent = 0.8
temp_xml = os.listdir(xmlfilepath)
total_xml = []
for xml in temp_xml:
if xml.endswith(".xml"):
total_xml.append(xml)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
print("train and val size", tv)
print("traub suze", tr)
#trainval,训练集测试集文件名,train,训练集,test,测试集,val验证集的文件名
ftrainval = open(os.path.join(saveBasePath, 'trainval.txt'), 'w')
ftest = open(os.path.join(saveBasePath, 'test.txt'), 'w')
ftrain = open(os.path.join(saveBasePath, 'train.txt'), 'w')
fval = open(os.path.join(saveBasePath, 'val.txt'), 'w')
for i in list:
name = total_xml[i][:-4] + 'n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
运行结果:
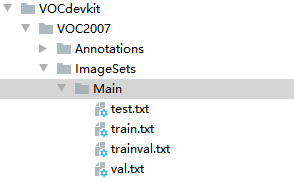
4:XML转TXT
这里要用到XML工具包来匹配一下:
代码:
import xml.etree.ElementTree as ET
from os import getcwd
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
classes = ["nomask","rightmask","wrongmask"]
def convert_annotation(year, image_id, list_file):
in_file = open('D:/object_find/voc_title/VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
tree=ET.parse(in_file)
root = tree.getroot()
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (int(xmlbox.find('xmin').text), int(xmlbox.find('ymin').text), int(xmlbox.find('xmax').text), int(xmlbox.find('ymax').text))
list_file.write(" " + ",".join([str(a) for a in b]) + ',' + str(cls_id))
wd = getcwd()
for year, image_set in sets:
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg'%(wd, year, image_id))
convert_annotation(year, image_id, list_file)
list_file.write('n')
list_file.close()
生成结果:
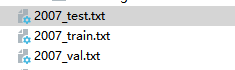
生成txt文件,包括:图片位置信息,目标位置,类别

最后
以上就是奋斗银耳汤最近收集整理的关于数据集制作_CV学习笔记(二十四):数据集标注与制作的全部内容,更多相关数据集制作_CV学习笔记(二十四)内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复