最近调研了一下simhash算法,它主要用在谷歌网页去重中,网上有很多原理性的介绍。既然可以用来判断文件的相似性,就想知道效果怎么样,simhash的精确度是否依赖于分词算法?是否和simhash的长度有关?
在数据去重过程中,都是先对文件进行分块,而后得到关于这个文件的所有指纹(SHA-1 digest),那么如果把这些fingerprints视为这个文件的单词,作为simhash的输入,效果会如何呢?接下来自己做了一个简单的测试,测试文件由自己构建的,下表是统计数据,F是基准文件,貌似效果没有那么明显。(其中243/27/27 表示两个文件有243个相同的指纹块(交集), 27是各自拥有的不同的块)
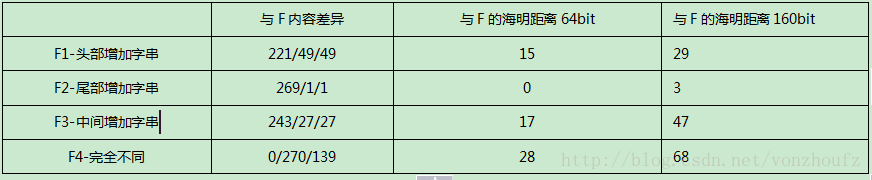
接下来会借用一些分词算法对文件分词后再获得对应的simhash值,与上述情况作对比。
最后
以上就是搞怪月光最近收集整理的关于文件相似性判断 -- SimHash的全部内容,更多相关文件相似性判断内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复