开篇词-打好 JS 基石,走稳前端进阶之路
我从事 Web 前端开发工作将近 9 年,前美团前端技术专家。
我在美团工作期间,负责和参与过 “到家”“团购” 及“电影”等业务的前端研发,以及团队搭建。其间,我还致力于前端性能优化、质量保证、效率提升、跨端融合等方向的研究,并且都有一定的技术落地,得到了超出预期的结果。
我也持续为公司进行前端岗位的社招、校招面试近 6 年多,面试候选人近千人,深谙大厂面试套路及定级之道,因此也总结了很多前端面试经验、技术提升心得,希望通过这个专栏分享给你。
为什么要学习这门课
随着前端技术的日新月异,前端应用的复杂度日益提升。与此同时,市场上对于前端人才的要求也愈加严格。
通过招聘网站可以看出,大厂普遍要求前端人才精通 JavaScript,其他各种高薪岗位也不乏 “理解并掌握 JavaScript” 等字眼。


作为前端人,我们必须认识到这样一个现状:想要在这一领域走得长远,就必须具备扎实的 JavaScript 编码能力,它既是前端人的自检清单,更是进阶的必修课。
而经过多年的面试招聘,我发现了一个 “通病”:很大一部分候选人的技术水平,只停留在前端框架(如 Vue、React)API 的使用层面,对于框架的源码逻辑一知半解,甚至对源码的思路也只是依靠死记硬背,很少愿意花时间去深入研究原生 JavaScript 的底层逻辑,因此造成了一系列的问题:
-
对框架的源码理解起来比较困难,导致在编码过程中只会写业务逻辑,却又不注重代码性能;
-
只会简单地调用 JS 框架的 API,而对于复杂的、非常依赖原生 JavaScript 实现的组件,实现的过程很吃力,甚至难以完成开发需求;
-
工作中往往需要通过阅读别人的代码去了解当前项目状况,而对于公司内其他人自研的前端组件的实现方式和原理,理解起来又较为困难,更别说在这个基础上进行维护了。
也正是这些问题,往往让初级开发者在业务场景里面无法呈现优秀的工作表现,做出更多的创新,更何况开发出更高效的前端工具。
很显然,正是自身的技术差异,导致了这些人职业发展停滞不前——职级晋升、面试大厂无果。
尤其是想进大厂的前端同学,如果能力仅仅停留在使用层面,是很难通过大厂层层考核的,因为面试官将会通过深挖技术背后的实现原理,来判断你对技术的掌握程度,以及是否对技术有钻研精神。如果你只是以熟练使用 Vue 或者 React 框架作为靠山,而 JavaScript 技术基础能力不过关,那么将在行业中举步维艰。
至此,以我多年的从业经验和招聘经验来看,未来互联网行业对候选人的能力要求只会越来越高,总结下来就是:扎实掌握并加强原生 JavaScript 的核心原理及编码功底、深入理解前端框架源代码,对于提升自己的前端技术能力、提高职业生涯天花板是非常有必要的。
我要带你怎么学
那么,怎样才能有效地提升原生 JS 能力,从而摆脱上面所说的那些困境呢?
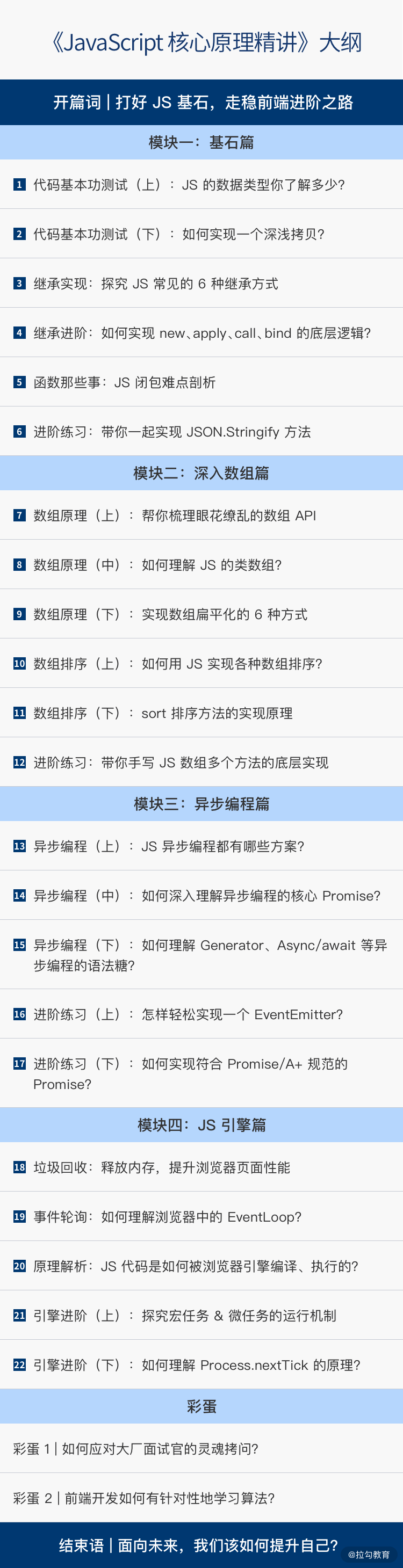
这个专栏就是为帮你夯实前端 JavaScript 核心基础知识而写就。我将围绕基础原理、数组、异步编程、V8 引擎几个核心知识点展开,通过 4 个模块、22 讲内容,带你深挖 JavaScript 底层原理。
模块一,我会深入讲解 JavaScript 数据类型、继承、闭包等核心基础知识,分析它们的底层原理。这是构建前端工具的基础,只有掌握好这部分内容,你才能为以后的编码能力打下基础。
并且这其中的一些知识点,比如深浅拷贝和自己手工实现 JSON.Stringfy 这样的题目,是大厂面试官经常会问到的内容,所以这部分我将以进阶练习的形式帮你轻松掌握。
模块二,我会介绍 JavaScript 的数组相关知识。要知道,在日常开发中,数组是经常会用到的数据类型,使用和出现频率非常之高。所以我会从数组原理、数组排序两大方向带你了解它,比如梳理数组 API、实现数组扁平化,以及数组 sort 方法。
掌握这部分知识,你可以在每次写前端业务逻辑、处理一些数组数据的时候,不用再去翻看相关的数组 API 文档,从而提升你的开发效率。
此外,由于 Javascript 语言的执行环境是 “单线程”,如果有多个任务,就必须排队,前面一个任务完成,再执行后面的任务,因此在浏览器端比较耗时的操作都应该进行异步操作来减少等待时间。由此可见,异步编程在浏览器端是非常重要的,如果不采用异步编程模式,大量的同步代码会造成浏览器的性能急剧下降。
因此,模块三会从 JavaScript 最基础的异步编程方式讲起,比如 Promise、Async/await、Co 等。当掌握了 JavaScript 异步编程源码精髓,你就可以摆脱前端代码的 “回调地狱”,更优雅地实现并解决业务场景的复杂问题、提升页面性能。
模块四是浏览器核心 V8 引擎相关的内容,它是执行 JavaScript 代码的程序或解释器,可以使得 JS 的执行性能大幅提升,这也是目前大多数浏览器普遍使用的引擎。
这一模块我会通过讲解浏览器垃圾回收机制、浏览器核心引擎的工作逻辑等内容,帮助你理解 JavaScript 代码是如何被 V8 引擎编译和执行的。这对于写出高性能的 JavaScript 代码帮助甚大。
在最后的彩蛋部分,我也会带你剖析一些互联网大厂的面试题目,让你真正了解互联网大厂的职级体系和面试定级标准,梳理面试思路和前端知识的学习方法,实现自身的突破和提升。
除此之外,每一个模块的最后我都会专门拿出 1~2 讲来带你实操,手把手帮助你实践,比如实现一个 JSON.Stringfy 方法、手写 JS 数组多个 API 的底层实现、实现一个 EventEmitter 等。这种更贴合实践的学习方式,会比你天天抱着编程的书啃,学习效率要高很多。
讲师寄语
前端技术的快速发展和充满希望的前景,也吸引了更多人加入前端工程师的行列,各种前端新技术、新框架的出现,也在考验前端工程师的能力。那么如何提升技术能力、建立自己的 “核心竞争力”,是每一位优秀的前端工程师应该思考的问题。
希望你不仅跟着我的思路去理解内容本身,还能在学习过程中在 IDE 里面亲自动手实现一遍,从而深刻体会程序实现逻辑的一些细节,进而加深对每一部分知识点的理解,做到融会贯通。
你也不妨给自己养成一个好习惯,每看完一篇文章就对知识点进行总结,形成自己的学习思维脑图,等到学完全部课程以后再来回顾,以便加深知识理解。
希望这个专栏,能够带你了解原生 JS 的底层原理,更好地掌握 JS 框架源码的代码实现逻辑,在写业务代码时可以做到游刃有余,提升工作效率,加强自身技术储备,拿高薪,进大厂!
01-代码基本功测试(上):JS 的数据类型你了解多少
在第一讲我要为你介绍的是 JS 数据类型的相关知识。
作为 JavaScript 的入门级知识点,JS 数据类型在整个 JavaScript 的学习过程中其实尤为重要。因为在 JavaScript 编程中,我们经常会遇到边界数据类型条件判断问题,很多代码只有在某种特定的数据类型下,才能可靠地执行。
尤其在大厂面试中,经常需要你现场手写代码,因此你很有必要提前考虑好数据类型的边界判断问题,并在你的 JavaScript 逻辑编写前进行前置判断,这样才能让面试官看到你严谨的编程逻辑和深入思考的能力,面试才可以加分。
因此,这一讲我将从数据类型的概念、检测方法、转换方法几个方面,帮你梳理和深入学习 JavaScript 的数据类型的知识点。
我希望通过本讲的学习,你能够熟练掌握数据类型的判断以及转换等相关知识点,并且在遇到数据类型判断以及数据类型的隐式转换等问题时可以轻松应对。
数据类型概念
JavaScript 的数据类型有下图所示的 8 种:
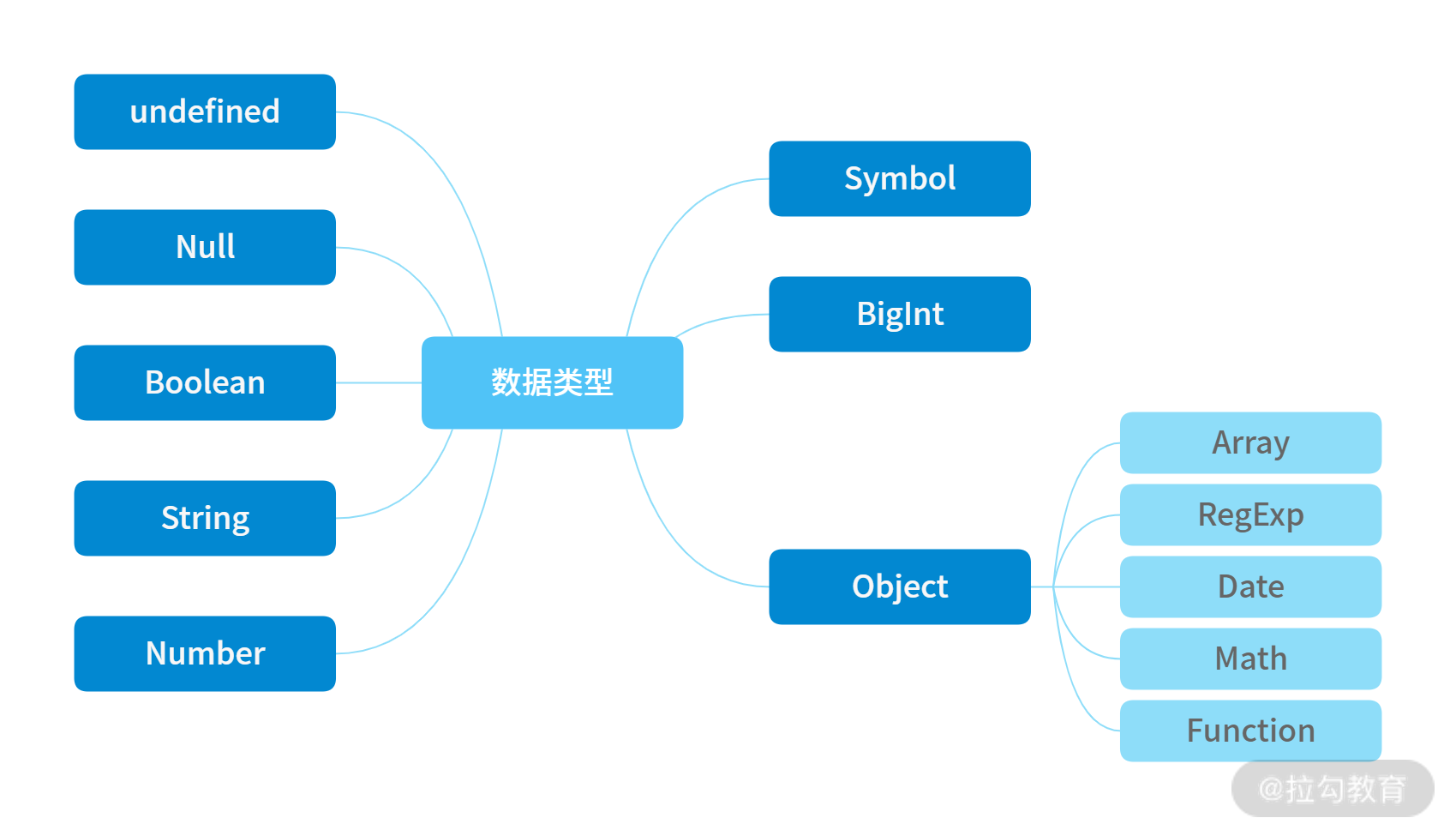
其中,前 7 种类型为基础类型,最后 1 种(Object)为引用类型,也是你需要重点关注的,因为它在日常工作中是使用得最频繁,也是需要关注最多技术细节的数据类型。
而引用数据类型(Object)又分为图上这几种常见的类型:Array - 数组对象、RegExp - 正则对象、Date - 日期对象、Math - 数学函数、Function - 函数对象。
在这里,我想先请你重点了解下面两点,因为各种 JavaScript 的数据类型最后都会在初始化之后放在不同的内存中,因此上面的数据类型大致可以分成两类来进行存储:
-
基础类型存储在栈内存,被引用或拷贝时,会创建一个完全相等的变量;
-
引用类型存储在堆内存,存储的是地址,多个引用指向同一个地址,这里会涉及一个 “共享” 的概念。
关于引用类型下面直接通过两段代码来讲解,让你深入理解一下核心 “共享” 的概念。
题目一:初出茅庐
let a = {
name: 'lee',
age: 18
}
let b = a;
console.log(a.name);
b.name = 'son';
console.log(a.name);
console.log(b.name);
这道题比较简单,我们可以看到第一个 console 打出来 name 是’lee’,这应该没什么疑问;但是在执行了 b.name=‘son’ 之后,结果你会发现 a 和 b 的属性 name 都是’son’,第二个和第三个打印结果是一样的,这里就体现了引用类型的 “共享” 的特性,即这两个值都存在同一块内存中共享,一个发生了改变,另外一个也随之跟着变化。
你可以直接在 Chrome 控制台敲一遍,深入理解一下这部分概念。下面我们再看一段代码,它是比题目一稍复杂一些的对象属性变化问题。
题目二:渐入佳境
let a = {
name: 'Julia',
age: 20
}
function change(o) {
o.age = 24;
o = {
name: 'Kath',
age: 30
}
return o;
}
let b = change(a);
console.log(b.age);
console.log(a.age);
这道题涉及了 function,你通过上述代码可以看到第一个 console 的结果是 30,b 最后打印结果是 {name: “Kath”, age: 30};第二个 console 的返回结果是 24,而 a 最后的打印结果是 {name: “Julia”, age: 24}。
是不是和你预想的有些区别?你要注意的是,这里的 function 和 return 带来了不一样的东西。
原因在于:函数传参进来的 o,传递的是对象在堆中的内存地址值,通过调用 o.age = 24(第 7 行代码)确实改变了 a 对象的 age 属性;但是第 12 行代码的 return 却又把 o 变成了另一个内存地址,将 {name: “Kath”, age: 30} 存入其中,最后返回 b 的值就变成了 {name: “Kath”, age: 30}。而如果把第 12 行去掉,那么 b 就会返回 undefined。这里你可以再仔细琢磨一下。
讲完数据类型的基本概念,我们继续看下一部分,如何对数据类型进行检测,这也是比较重要的问题。
数据类型检测
数据类型检测也是面试过程中经常会遇到的问题,比如:如何判断是否为数组?让你写一段代码把 JavaScript 的各种数据类型判断出来,等等。类似的题目会很多,而且在平常写代码过程中我们也会经常用到。
我也经常在面试一些候选人的时候,有些回答比如 “用 typeof 来判断”,然后就没有其他答案了,但这样的回答是不能令面试官满意的,因为他要考察你对 JS 的数据类型理解的深度,所以我们先要做到的是对各种数据类型的判断方法了然于胸,然后再进行归纳总结,给面试官一个满意的答案。
数据类型的判断方法其实有很多种,比如 typeof 和 instanceof,下面我来重点介绍三种在工作中经常会遇到的数据类型检测方法。
第一种判断方法:typeof
这是比较常用的一种,那么我们通过一段代码来快速回顾一下这个方法。
typeof 1
typeof '1'
typeof undefined
typeof true
typeof Symbol()
typeof null
typeof []
typeof {}
typeof console
typeof console.log
你可以看到,前 6 个都是基础数据类型,而为什么第 6 个 null 的 typeof 是’object’ 呢?这里要和你强调一下,虽然 typeof null 会输出 object,但这只是 JS 存在的一个悠久 Bug,不代表 null 就是引用数据类型,并且 null 本身也不是对象。因此,null 在 typeof 之后返回的是有问题的结果,不能作为判断 null 的方法。如果你需要在 if 语句中判断是否为 null,直接通过 ‘===null’来判断就好。
此外还要注意,引用数据类型 Object,用 typeof 来判断的话,除了 function 会判断为 OK 以外,其余都是’object’,是无法判断出来的。
第二种判断方法:instanceof
想必 instanceof 的方法你也听说过,我们 new 一个对象,那么这个新对象就是它原型链继承上面的对象了,通过 instanceof 我们能判断这个对象是否是之前那个构造函数生成的对象,这样就基本可以判断出这个新对象的数据类型。下面通过代码来了解一下。
let Car = function() {}
let benz = new Car()
benz instanceof Car
let car = new String('Mercedes Benz')
car instanceof String
let str = 'Covid-19'
str instanceof String
上面就是用 instanceof 方法判断数据类型的大致流程,那么如果让你自己实现一个 instanceof 的底层实现,应该怎么写呢?请看下面的代码。
function myInstanceof(left, right) {
if(typeof left !== 'object' || left === null) return false;
let proto = Object.getPrototypeOf(left);
while(true) {
if(proto === null) return false;
if(proto === right.prototype) return true;
proto = Object.getPrototypeof(proto);
}
}
console.log(myInstanceof(new Number(123), Number));
console.log(myInstanceof(123, Number));
现在你知道了两种判断数据类型的方法,那么它们之间有什么差异呢?我总结了下面两点:
-
instanceof 可以准确地判断复杂引用数据类型,但是不能正确判断基础数据类型;
-
而 typeof 也存在弊端,它虽然可以判断基础数据类型(null 除外),但是引用数据类型中,除了 function 类型以外,其他的也无法判断。
总之,不管单独用 typeof 还是 instanceof,都不能满足所有场景的需求,而只能通过二者混写的方式来判断。但是这种方式判断出来的其实也只是大多数情况,并且写起来也比较难受,你也可以试着写一下。
其实我个人还是比较推荐下面的第三种方法,相比上述两个而言,能更好地解决数据类型检测问题。
第三种判断方法:Object.prototype.toString
toString() 是 Object 的原型方法,调用该方法,可以统一返回格式为 “[object Xxx]” 的字符串,其中 Xxx 就是对象的类型。对于 Object 对象,直接调用 toString() 就能返回 [object Object];而对于其他对象,则需要通过 call 来调用,才能返回正确的类型信息。我们来看一下代码。
Object.prototype.toString({})
Object.prototype.toString.call({})
Object.prototype.toString.call(1)
Object.prototype.toString.call('1')
Object.prototype.toString.call(true)
Object.prototype.toString.call(function(){})
Object.prototype.toString.call(null)
Object.prototype.toString.call(undefined)
Object.prototype.toString.call(/123/g)
Object.prototype.toString.call(new Date())
Object.prototype.toString.call([])
Object.prototype.toString.call(document)
Object.prototype.toString.call(window)
从上面这段代码可以看出,Object.prototype.toString.call() 可以很好地判断引用类型,甚至可以把 document 和 window 都区分开来。
但是在写判断条件的时候一定要注意,使用这个方法最后返回统一字符串格式为 “[object Xxx]” ,而这里字符串里面的 “Xxx” ,第一个首字母要大写(注意:使用 typeof 返回的是小写),这里需要多加留意。
那么下面来实现一个全局通用的数据类型判断方法,来加深你的理解,代码如下。
function getType(obj){
let type = typeof obj;
if (type !== "object") {
return type;
}
return Object.prototype.toString.call(obj).replace(/^[object (S+)]$/, '$1');
}
getType([])
getType('123')
getType(window)
getType(null)
getType(undefined)
getType()
getType(function(){})
getType(/123/g)
到这里,数据类型检测的三种方法就介绍完了,最后也给出来了示例代码,希望你可以对比着来学习、使用,并且不断加深记忆,以便遇到问题时不会手忙脚乱。你如果一遍记不住可以多次来回看巩固,直到把上面的代码都能全部理解,并且把几个特殊的问题都强化记忆,这样未来你去做类似题目才不会有问题。
下面我们来看本讲的最后一部分:数据类型的转换。
数据类型转换
在日常的业务开发中,经常会遇到 JavaScript 数据类型转换问题,有的时候需要我们主动进行强制转换,而有的时候 JavaScript 会进行隐式转换,隐式转换的时候就需要我们多加留心。
那么这部分都会涉及哪些内容呢?我们先看一段代码,了解下大致的情况。
'123' == 123
'' == null
'' == 0
[] == 0
[] == ''
[] == ![]
null == undefined
Number(null)
Number('')
parseInt('');
{}+10
let obj = {
[Symbol.toPrimitive]() {
return 200;
},
valueOf() {
return 300;
},
toString() {
return 'Hello';
}
}
console.log(obj + 200);
上面这 12 个问题相信你并不陌生,基本涵盖了我们平常容易疏漏的一些情况,这就是在做数据类型转换时经常会遇到的强制转换和隐式转换的方式,那么下面我就围绕数据类型的两种转换方式详细讲解一下,希望可以为你提供一些借鉴。
强制类型转换
强制类型转换方式包括 Number()、parseInt()、parseFloat()、toString()、String()、Boolean(),这几种方法都比较类似,通过字面意思可以很容易理解,都是通过自身的方法来进行数据类型的强制转换。下面我列举一些来详细说明。
上面代码中,第 8 行的结果是 0,第 9 行的结果同样是 0,第 10 行的结果是 NaN。这些都是很明显的强制类型转换,因为用到了 Number() 和 parseInt()。
其实上述几个强制类型转换的原理大致相同,下面我挑两个比较有代表性的方法进行讲解。
Number() 方法的强制转换规则
-
如果是布尔值,true 和 false 分别被转换为 1 和 0;
-
如果是数字,返回自身;
-
如果是 null,返回 0;
-
如果是 undefined,返回 NaN;
-
如果是字符串,遵循以下规则:如果字符串中只包含数字(或者是 0X / 0x 开头的十六进制数字字符串,允许包含正负号),则将其转换为十进制;如果字符串中包含有效的浮点格式,将其转换为浮点数值;如果是空字符串,将其转换为 0;如果不是以上格式的字符串,均返回 NaN;
-
如果是 Symbol,抛出错误;
-
如果是对象,并且部署了 [Symbol.toPrimitive] ,那么调用此方法,否则调用对象的 valueOf() 方法,然后依据前面的规则转换返回的值;如果转换的结果是 NaN ,则调用对象的 toString() 方法,再次依照前面的顺序转换返回对应的值(Object 转换规则会在下面细讲)。
下面通过一段代码来说明上述规则。
Number(true);
Number(false);
Number('0111');
Number(null);
Number('');
Number('1a');
Number(-0X11);
Number('0X11')
其中,我分别列举了比较常见的 Number 转换的例子,它们都会把对应的非数字类型转换成数字类型,而有一些实在无法转换成数字的,最后只能输出 NaN 的结果。
Boolean() 方法的强制转换规则
这个方法的规则是:除了 undefined、 null、 false、 ‘’、 0(包括 +0,-0)、 NaN 转换出来是 false,其他都是 true。
这个规则应该很好理解,没有那么多条条框框,我们还是通过代码来形成认知,如下所示。
Boolean(0)
Boolean(null)
Boolean(undefined)
Boolean(NaN)
Boolean(1)
Boolean(13)
Boolean('12')
其余的 parseInt()、parseFloat()、toString()、String() 这几个方法,你可以按照我的方式去整理一下规则,在这里不占过多篇幅了。
隐式类型转换
凡是通过逻辑运算符 (&&、 ||、 !)、运算符 (+、-、*、/)、关系操作符 (>、 <、 <= 、>=)、相等运算符 (==) 或者 if/while 条件的操作,如果遇到两个数据类型不一样的情况,都会出现隐式类型转换。这里你需要重点关注一下,因为比较隐蔽,特别容易让人忽视。
下面着重讲解一下日常用得比较多的 “==” 和“+”这两个符号的隐式转换规则。
‘==’ 的隐式类型转换规则
-
如果类型相同,无须进行类型转换;
-
如果其中一个操作值是 null 或者 undefined,那么另一个操作符必须为 null 或者 undefined,才会返回 true,否则都返回 false;
-
如果其中一个是 Symbol 类型,那么返回 false;
-
两个操作值如果为 string 和 number 类型,那么就会将字符串转换为 number;
-
如果一个操作值是 boolean,那么转换成 number;
-
如果一个操作值为 object 且另一方为 string、number 或者 symbol,就会把 object 转为原始类型再进行判断(调用 object 的 valueOf/toString 方法进行转换)。
如果直接死记这些理论会有点懵,我们还是直接看代码,这样更容易理解一些,如下所示。
null == undefined
null == 0
'' == null
'' == 0
'123' == 123
0 == false
1 == true
var a = {
value: 0,
valueOf: function() {
this.value++;
return this.value;
}
};
console.log(a == 1 && a == 2 && a ==3);
对照着这个规则看完上面的代码和注解之后,你可以再回过头做一下我在讲解 “数据类型转换” 之前的那 12 道题目,是不是就很容易解决了?
‘+’ 的隐式类型转换规则
‘+’ 号操作符,不仅可以用作数字相加,还可以用作字符串拼接。仅当 ‘+’ 号两边都是数字时,进行的是加法运算;如果两边都是字符串,则直接拼接,无须进行隐式类型转换。
除了上述比较常规的情况外,还有一些特殊的规则,如下所示。
-
如果其中有一个是字符串,另外一个是 undefined、null 或布尔型,则调用 toString() 方法进行字符串拼接;如果是纯对象、数组、正则等,则默认调用对象的转换方法会存在优先级(下一讲会专门介绍),然后再进行拼接。
-
如果其中有一个是数字,另外一个是 undefined、null、布尔型或数字,则会将其转换成数字进行加法运算,对象的情况还是参考上一条规则。
-
如果其中一个是字符串、一个是数字,则按照字符串规则进行拼接。
下面还是结合代码来理解上述规则,如下所示。
1 + 2
'1' + '2'
'1' + undefined
'1' + null
'1' + true
'1' + 1n
1 + undefined
1 + null
1 + true
1 + 1n
'1' + 3
整体来看,如果数据中有字符串,JavaScript 类型转换还是更倾向于转换成字符串,因为第三条规则中可以看到,在字符串和数字相加的过程中最后返回的还是字符串,这里需要关注一下。
了解了 ‘+’ 的转换规则后,我们最后再看一下 Object 的转换规则。
Object 的转换规则
对象转换的规则,会先调用内置的 [ToPrimitive] 函数,其规则逻辑如下:
-
如果部署了 Symbol.toPrimitive 方法,优先调用再返回;
-
调用 valueOf(),如果转换为基础类型,则返回;
-
调用 toString(),如果转换为基础类型,则返回;
-
如果都没有返回基础类型,会报错。
直接理解有些晦涩,还是直接来看代码,你也可以在控制台自己敲一遍来加深印象。
var obj = {
value: 1,
valueOf() {
return 2;
},
toString() {
return '3'
},
[Symbol.toPrimitive]() {
return 4
}
}
console.log(obj + 1);
10 + {}
[1,2,undefined,4,5] + 10
关于 Object 的转化,就讲解到这里,希望你可以深刻体会一下上面讲的原理和内容。
总结
以上就是本讲的内容了,在这一讲中,我们从三个方面学习了数据类型相关内容,下面整体回顾一下。
-
数据类型的基本概念:这是必须掌握的知识点,作为深入理解 JavaScript 的基础。
-
数据类型的判断方法:typeof 和 instanceof,以及 Object.prototype.toString 的判断数据类型、手写 instanceof 代码片段,这些是日常开发中经常会遇到的,因此你需要好好掌握。
-
数据类型的转换方式:两种数据类型的转换方式,日常写代码过程中隐式转换需要多留意,如果理解不到位,很容易引起在编码过程中的 bug,得到一些意想不到的结果。
对于本讲内容,如果你有不清楚的地方,欢迎在评论区留言,我们一起探讨、进步。
下一讲我会在本讲内容的基础上,为你详细介绍手写一个深浅拷贝代码的完整思路以及代码的实现。我们下一讲见。
02-代码基本功测试(下):如何实现一个深浅拷贝
上一讲我们介绍了 JS 的两种数据类型,分别是基础数据类型和引用数据类型,你可以回忆一下我提到的重点内容。那么这一讲要聊的浅拷贝和深拷贝,其实就是围绕着这两种数据类型展开的。
我把深浅拷贝单独作为一讲来专门讲解,是因为在 JavaScript 的编程中经常需要对数据进行复制,什么时候用深拷贝、什么时候用浅拷贝,是开发过程中需要思考的;同时深浅拷贝也是前端面试中比较高频的题目。
但是我在面试候选人的过程中,发现有很多同学都没有搞懂深拷贝和浅拷贝的区别和定义。最近我也在一些关于 JavaScript 的技术文章中发现,里面很多关于深浅拷贝的代码写得比较简陋,从面试官的角度来讲,简陋的答案是不太能让人满意的。
因此,深入学习这部分知识有助于提高你手写 JS 的能力,以及对一些边界特殊情况的深入思考能力,这一讲我会结合最基础但是又容易写不好的的题目来帮助你提升。
在开始之前,我先抛出来两个问题,你可以思考一下。
-
拷贝一个很多嵌套的对象怎么实现?
-
在面试官眼中,写成什么样的深拷贝代码才能算合格?
带着这两个问题,我们先来看下浅拷贝的相关内容。
浅拷贝的原理和实现
对于浅拷贝的定义我们可以初步理解为:
自己创建一个新的对象,来接受你要重新复制或引用的对象值。如果对象属性是基本的数据类型,复制的就是基本类型的值给新对象;但如果属性是引用数据类型,复制的就是内存中的地址,如果其中一个对象改变了这个内存中的地址,肯定会影响到另一个对象。
下面我总结了一些 JavaScript 提供的浅拷贝方法,一起来看看哪些方法能实现上述定义所描述的过程。
方法一:object.assign
object.assign 是 ES6 中 object 的一个方法,该方法可以用于 JS 对象的合并等多个用途,其中一个用途就是可以进行浅拷贝。该方法的第一个参数是拷贝的目标对象,后面的参数是拷贝的来源对象(也可以是多个来源)。
object.assign 的语法为:Object.assign(target, …sources)
object.assign 的示例代码如下:
let target = {};
let source = { a: { b: 1 } };
Object.assign(target, source);
console.log(target);
从上面的代码中可以看到,通过 object.assign 我们的确简单实现了一个浅拷贝,“target” 就是我们新拷贝的对象,下面再看一个和上面不太一样的例子。
let target = {};
let source = { a: { b: 2 } };
Object.assign(target, source);
console.log(target);
source.a.b = 10;
console.log(source);
console.log(target);
从上面代码中我们可以看到,首先通过 Object.assign 将 source 拷贝到 target 对象中,然后我们尝试将 source 对象中的 b 属性由 2 修改为 10。通过控制台可以发现,打印结果中,三个 target 里的 b 属性都变为 10 了,证明 Object.assign 暂时实现了我们想要的拷贝效果。
但是使用 object.assign 方法有几点需要注意:
-
它不会拷贝对象的继承属性;
-
它不会拷贝对象的不可枚举的属性;
-
可以拷贝 Symbol 类型的属性。
可以简单理解为:Object.assign 循环遍历原对象的属性,通过复制的方式将其赋值给目标对象的相应属性,来看一下这段代码,以验证它可以拷贝 Symbol 类型的对象。
let obj1 = { a:{ b:1 }, sym:Symbol(1)};
Object.defineProperty(obj1, 'innumerable' ,{
value:'不可枚举属性',
enumerable:false
});
let obj2 = {};
Object.assign(obj2,obj1)
obj1.a.b = 2;
console.log('obj1',obj1);
console.log('obj2',obj2);
我们来看一下控制台打印的结果,如下图所示。

从上面的样例代码中可以看到,利用 object.assign 也可以拷贝 Symbol 类型的对象,但是如果到了对象的第二层属性 obj1.a.b 这里的时候,前者值的改变也会影响后者的第二层属性的值,说明其中依旧存在着访问共同堆内存的问题,也就是说这种方法还不能进一步复制,而只是完成了浅拷贝的功能。
方法二:扩展运算符方式
我们也可以利用 JS 的扩展运算符,在构造对象的同时完成浅拷贝的功能。
扩展运算符的语法为:let cloneObj = {…obj};
代码如下所示。
let obj = {a:1,b:{c:1}}
let obj2 = {...obj}
obj.a = 2
console.log(obj)
obj.b.c = 2
console.log(obj)
let arr = [1, 2, 3];
let newArr = [...arr];
扩展运算符 和 object.assign 有同样的缺陷,也就是实现的浅拷贝的功能差不多,但是如果属性都是基本类型的值,使用扩展运算符进行浅拷贝会更加方便。
方法三:concat 拷贝数组
数组的 concat 方法其实也是浅拷贝,所以连接一个含有引用类型的数组时,需要注意修改原数组中的元素的属性,因为它会影响拷贝之后连接的数组。不过 concat 只能用于数组的浅拷贝,使用场景比较局限。代码如下所示。
let arr = [1, 2, 3];
let newArr = arr.concat();
newArr[1] = 100;
console.log(arr);
console.log(newArr);
方法四:slice 拷贝数组
slice 方法也比较有局限性,因为它仅仅针对数组类型。slice 方法会返回一个新的数组对象,这一对象由该方法的前两个参数来决定原数组截取的开始和结束时间,是不会影响和改变原始数组的。
slice 的语法为:arr.slice(begin, end);
我们来看一下 slice 怎么使用,代码如下所示。
let arr = [1, 2, {val: 4}];
let newArr = arr.slice();
newArr[2].val = 1000;
console.log(arr);
从上面的代码中可以看出,这就是浅拷贝的限制所在了——它只能拷贝一层对象。如果存在对象的嵌套,那么浅拷贝将无能为力。因此深拷贝就是为了解决这个问题而生的,它能解决多层对象嵌套问题,彻底实现拷贝。这一讲的后面我会介绍深拷贝相关的内容。
手工实现一个浅拷贝
根据以上对浅拷贝的理解,如果让你自己实现一个浅拷贝,大致的思路分为两点:
-
对基础类型做一个最基本的一个拷贝;
-
对引用类型开辟一个新的存储,并且拷贝一层对象属性。
那么,围绕着这两个思路,请你跟着我的操作,自己来实现一个浅拷贝吧,代码如下所示。
const shallowClone = (target) => {
if (typeof target === 'object' && target !== null) {
const cloneTarget = Array.isArray(target) ? []: {};
for (let prop in target) {
if (target.hasOwnProperty(prop)) {
cloneTarget[prop] = target[prop];
}
}
return cloneTarget;
} else {
return target;
}
}
从上面这段代码可以看出,利用类型判断,针对引用类型的对象进行 for 循环遍历对象属性赋值给目标对象的属性,基本就可以手工实现一个浅拷贝的代码了。
那么了解了实现浅拷贝代码的思路,接下来我们再看看深拷贝是怎么实现的。
深拷贝的原理和实现
浅拷贝只是创建了一个新的对象,复制了原有对象的基本类型的值,而引用数据类型只拷贝了一层属性,再深层的还是无法进行拷贝。深拷贝则不同,对于复杂引用数据类型,其在堆内存中完全开辟了一块内存地址,并将原有的对象完全复制过来存放。
这两个对象是相互独立、不受影响的,彻底实现了内存上的分离。总的来说,深拷贝的原理可以总结如下:
将一个对象从内存中完整地拷贝出来一份给目标对象,并从堆内存中开辟一个全新的空间存放新对象,且新对象的修改并不会改变原对象,二者实现真正的分离。
现在原理你知道了,那么怎么去实现深拷贝呢?我也总结了几种方法分享给你。
方法一:乞丐版(JSON.stringfy)
JSON.stringfy() 是目前开发过程中最简单的深拷贝方法,其实就是把一个对象序列化成为 JSON 的字符串,并将对象里面的内容转换成字符串,最后再用 JSON.parse() 的方法将 JSON 字符串生成一个新的对象。示例代码如下所示。
let obj1 = { a:1, b:[1,2,3] }
let str = JSON.stringify(obj1);
let obj2 = JSON.parse(str);
console.log(obj2);
obj1.a = 2;
obj1.b.push(4);
console.log(obj1);
console.log(obj2);
从上面的代码可以看到,通过 JSON.stringfy 可以初步实现一个对象的深拷贝,通过改变 obj1 的 b 属性,其实可以看出 obj2 这个对象也不受影响。
但是使用 JSON.stringfy 实现深拷贝还是有一些地方值得注意,我总结下来主要有这几点:
-
拷贝的对象的值中如果有函数、undefined、symbol 这几种类型,经过 JSON.stringify 序列化之后的字符串中这个键值对会消失;
-
拷贝 Date 引用类型会变成字符串;
-
无法拷贝不可枚举的属性;
-
无法拷贝对象的原型链;
-
拷贝 RegExp 引用类型会变成空对象;
-
对象中含有 NaN、Infinity 以及 -Infinity,JSON 序列化的结果会变成 null;
-
无法拷贝对象的循环应用,即对象成环 (obj[key] = obj)。
针对这些存在的问题,你可以尝试着用下面的这段代码亲自执行一遍,来看看如此复杂的对象,如果用 JSON.stringfy 实现深拷贝会出现什么情况。
function Obj() {
this.func = function () { alert(1) };
this.obj = {a:1};
this.arr = [1,2,3];
this.und = undefined;
this.reg = /123/;
this.date = new Date(0);
this.NaN = NaN;
this.infinity = Infinity;
this.sym = Symbol(1);
}
let obj1 = new Obj();
Object.defineProperty(obj1,'innumerable',{
enumerable:false,
value:'innumerable'
});
console.log('obj1',obj1);
let str = JSON.stringify(obj1);
let obj2 = JSON.parse(str);
console.log('obj2',obj2);
通过上面这段代码可以看到执行结果如下图所示。
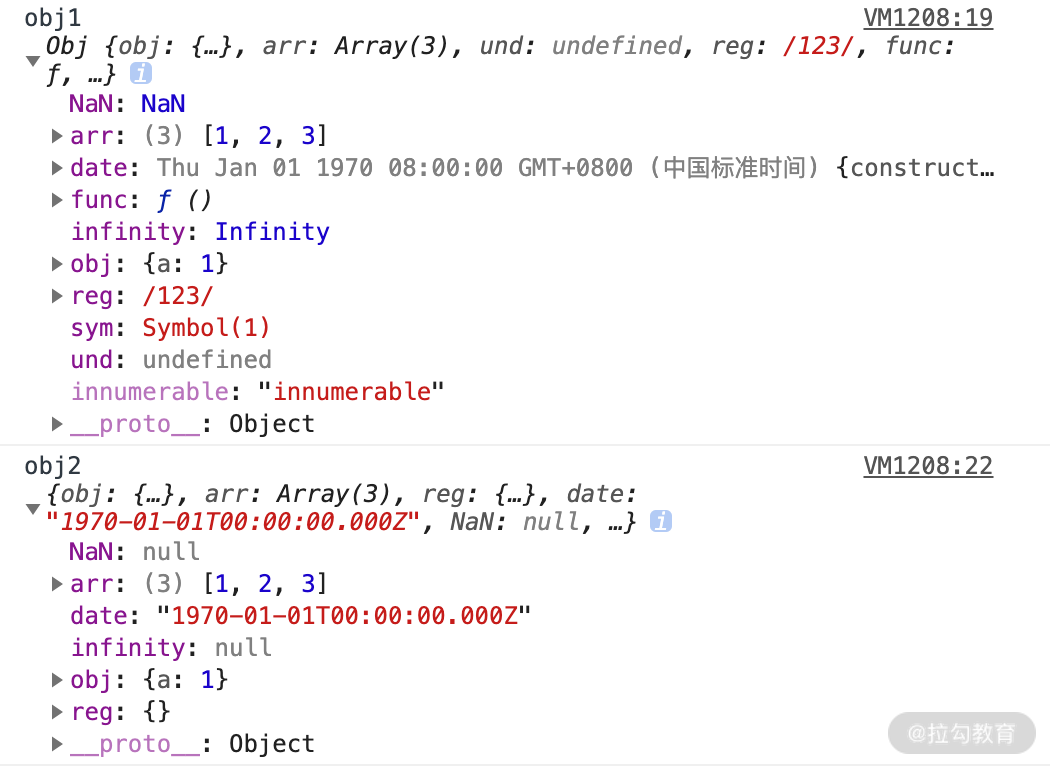
使用 JSON.stringify 方法实现深拷贝对象,虽然到目前为止还有很多无法实现的功能,但是这种方法足以满足日常的开发需求,并且是最简单和快捷的。而对于其他的也要实现深拷贝的,比较麻烦的属性对应的数据类型,JSON.stringify 暂时还是无法满足的,那么就需要下面的几种方法了。
方法二:基础版(手写递归实现)
下面是一个实现 deepClone 函数封装的例子,通过 for in 遍历传入参数的属性值,如果值是引用类型则再次递归调用该函数,如果是基础数据类型就直接复制,代码如下所示。
let obj1 = {
a:{
b:1
}
}
function deepClone(obj) {
let cloneObj = {}
for(let key in obj) {
if(typeof obj[key] ==='object') {
cloneObj[key] = deepClone(obj[key])
} else {
cloneObj[key] = obj[key]
}
}
return cloneObj
}
let obj2 = deepClone(obj1);
obj1.a.b = 2;
console.log(obj2);
虽然利用递归能实现一个深拷贝,但是同上面的 JSON.stringfy 一样,还是有一些问题没有完全解决,例如:
-
这个深拷贝函数并不能复制不可枚举的属性以及 Symbol 类型;
-
这种方法只是针对普通的引用类型的值做递归复制,而对于 Array、Date、RegExp、Error、Function 这样的引用类型并不能正确地拷贝;
-
对象的属性里面成环,即循环引用没有解决。
这种基础版本的写法也比较简单,可以应对大部分的应用情况。但是你在面试的过程中,如果只能写出这样的一个有缺陷的深拷贝方法,有可能不会通过。
所以为了 “拯救” 这些缺陷,下面我带你一起看看改进的版本,以便于你可以在面试种呈现出更好的深拷贝方法,赢得面试官的青睐。
方法三:改进版(改进后递归实现)
针对上面几个待解决问题,我先通过四点相关的理论告诉你分别应该怎么做。
-
针对能够遍历对象的不可枚举属性以及 Symbol 类型,我们可以使用 Reflect.ownKeys 方法;
-
当参数为 Date、RegExp 类型,则直接生成一个新的实例返回;
-
利用 Object 的 getOwnPropertyDescriptors 方法可以获得对象的所有属性,以及对应的特性,顺便结合 Object 的 create 方法创建一个新对象,并继承传入原对象的原型链;
-
利用 WeakMap 类型作为 Hash 表,因为 WeakMap 是弱引用类型,可以有效防止内存泄漏(你可以关注一下 Map 和 weakMap 的关键区别,这里要用 weakMap),作为检测循环引用很有帮助,如果存在循环,则引用直接返回 WeakMap 存储的值。
关于第 4 点的 WeakMap,这里我不进行过多的科普讲解了,你如果不清楚可以自己再通过相关资料了解一下。我也经常在给人面试中看到有人使用 WeakMap 来解决循环引用问题,但是很多解释都是不够清晰的。
当你不太了解 WeakMap 的真正作用时,我建议你不要在面试中写出这样的代码,如果只是死记硬背,会给自己挖坑的。因为你写的每一行代码都是需要经过深思熟虑并且非常清晰明白的,这样你才能经得住面试官的推敲。
当然,如果你在考虑到循环引用的问题之后,还能用 WeakMap 来很好地解决,并且向面试官解释这样做的目的,那么你所展示的代码,以及你对问题思考的全面性,在面试官眼中应该算是合格的了。
那么针对上面这几个问题,我们来看下改进后的递归实现的深拷贝代码应该是什么样子的,如下所示。
const isComplexDataType = obj => (typeof obj === 'object' || typeof obj === 'function') && (obj !== null)
const deepClone = function (obj, hash = new WeakMap()) {
if (obj.constructor === Date)
return new Date(obj)
if (obj.constructor === RegExp)
return new RegExp(obj)
if (hash.has(obj)) return hash.get(obj)
let allDesc = Object.getOwnPropertyDescriptors(obj)
let cloneObj = Object.create(Object.getPrototypeOf(obj), allDesc)
hash.set(obj, cloneObj)
for (let key of Reflect.ownKeys(obj)) {
cloneObj[key] = (isComplexDataType(obj[key]) && typeof obj[key] !== 'function') ? deepClone(obj[key], hash) : obj[key]
}
return cloneObj
}
let obj = {
num: 0,
str: '',
boolean: true,
unf: undefined,
nul: null,
obj: { name: '我是一个对象', id: 1 },
arr: [0, 1, 2],
func: function () { console.log('我是一个函数') },
date: new Date(0),
reg: new RegExp('/我是一个正则/ig'),
[Symbol('1')]: 1,
};
Object.defineProperty(obj, 'innumerable', {
enumerable: false, value: '不可枚举属性' }
);
obj = Object.create(obj, Object.getOwnPropertyDescriptors(obj))
obj.loop = obj
let cloneObj = deepClone(obj)
cloneObj.arr.push(4)
console.log('obj', obj)
console.log('cloneObj', cloneObj)
我们看一下结果,cloneObj 在 obj 的基础上进行了一次深拷贝,cloneObj 里的 arr 数组进行了修改,并未影响到 obj.arr 的变化,如下图所示。
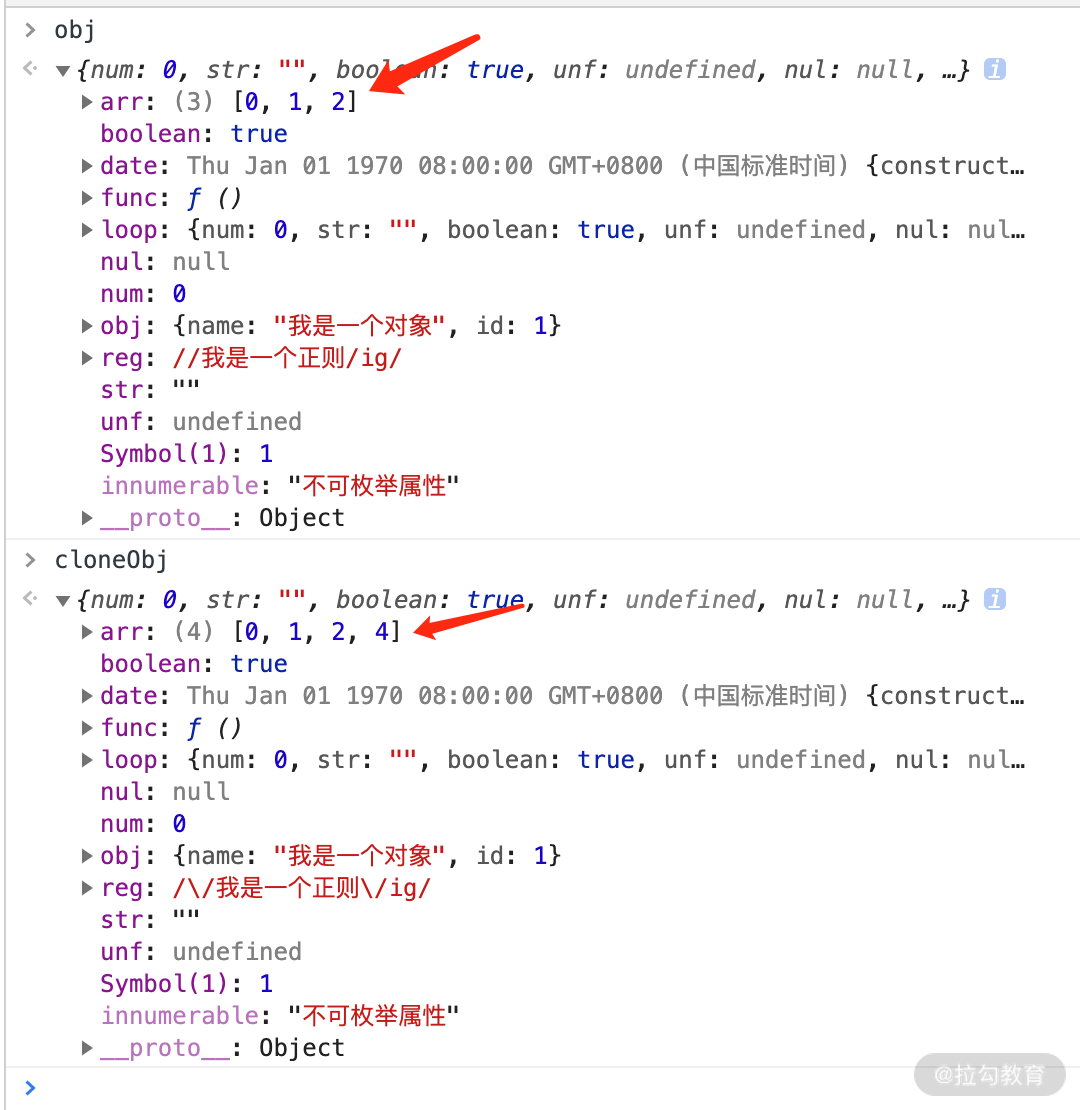
从这张截图的结果可以看出,改进版的 deepClone 函数已经对基础版的那几个问题进行了改进,也验证了我上面提到的那四点理论。
那么到这里,深拷贝的相关内容就介绍得差不多了。
总结
这一讲,我们探讨了如何实现一个深浅拷贝。在日常的开发中,由于开发者可以使用一些现成的库来实现深拷贝,所以很多人对如何实现深拷贝的细节问题并不清楚。但是如果仔细研究你就会发现,这部分内容对于你深入了解 JS 底层的原理有很大帮助。如果未来你需要自己实现一个前端相关的工具或者库,对 JS 理解的深度会决定你能把这个东西做得有多好。
其实到最后我们可以看到,自己完整实现一个深拷贝,还是考察了不少的知识点和编程能力,总结下来大致分为这几点,请看下图。
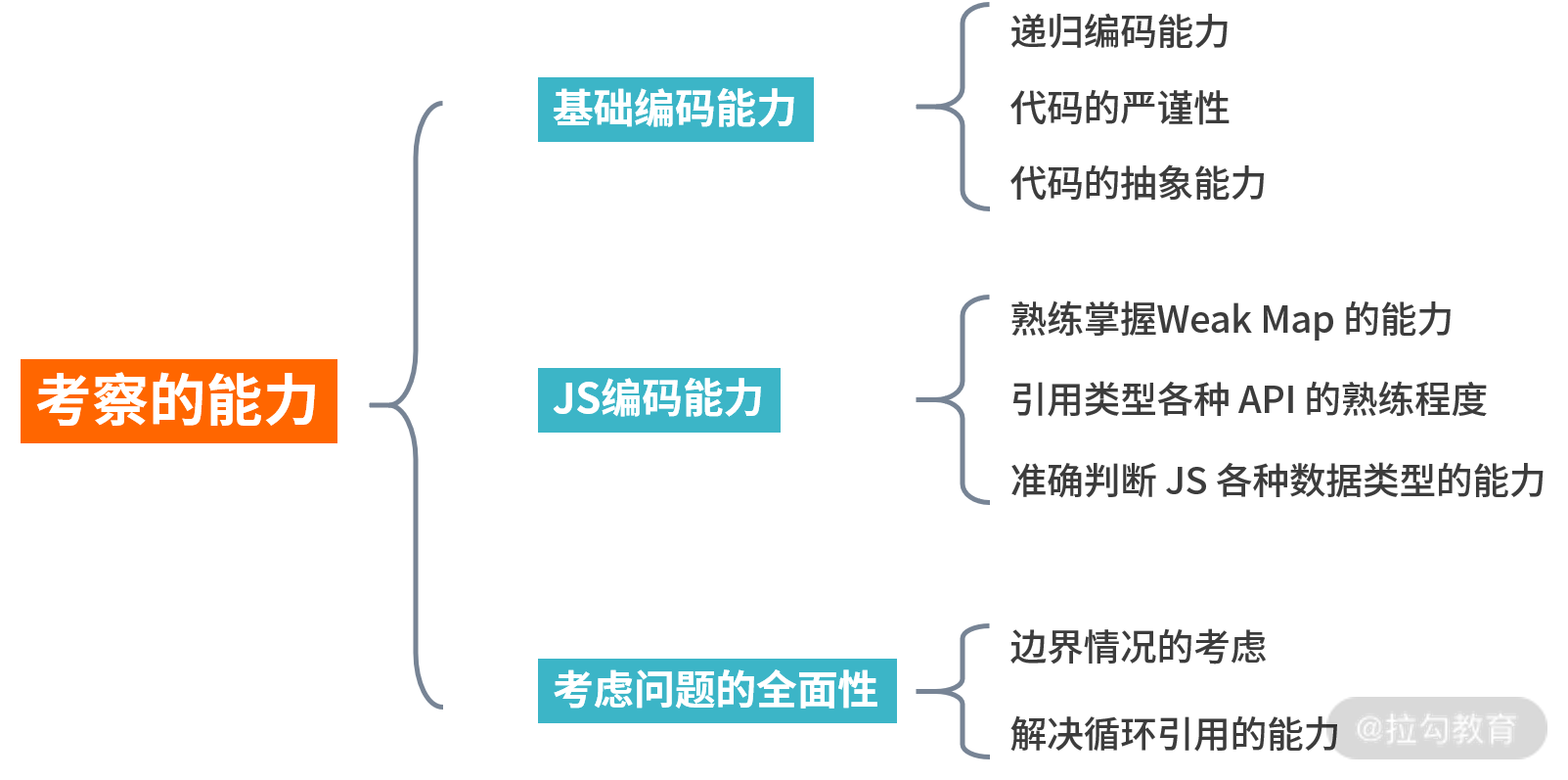
可以看到通过这一个问题能考察的能力有很多,因此千万不要用最低的标准来要求自己,应该用类似的方法去分析每个问题深入考察的究竟是什么,这样才能更好地去全面提升自己的基本功。
关于深浅拷贝如果你有不清楚的地方,欢迎在评论区留言,最好的建议还是要多动手,不清楚的地方自己敲一遍代码,这样才能加深印象,然后更容易地去消化这部分内容。
下一讲,我们将迎来继承方式的学习,这部分知识也是非常重要的,你需要熟练掌握并理解其原理。也欢迎你提前预习相关知识,这样才能在不同的角度有所收获。下一讲再见。
eObj
}
let obj = {
num: 0,
str: ‘’,
boolean: true,
unf: undefined,
nul: null,
obj: { name: ‘我是一个对象’, id: 1 },
arr: [0, 1, 2],
func: function () { console.log(‘我是一个函数’) },
date: new Date(0),
reg: new RegExp(‘/我是一个正则/ig’),
};
Object.defineProperty(obj, ‘innumerable’, {
enumerable: false, value: ‘不可枚举属性’ }
);
obj = Object.create(obj, Object.getOwnPropertyDescriptors(obj))
obj.loop = obj
let cloneObj = deepClone(obj)
cloneObj.arr.push(4)
console.log(‘obj’, obj)
console.log(‘cloneObj’, cloneObj)
我们看一下结果,cloneObj 在 obj 的基础上进行了一次深拷贝,cloneObj 里的 arr 数组进行了修改,并未影响到 obj.arr 的变化,如下图所示。
[外链图片转存中...(img-v6Ux7YcX-1657763530863)]
从这张截图的结果可以看出,改进版的 deepClone 函数已经对基础版的那几个问题进行了改进,也验证了我上面提到的那四点理论。
那么到这里,深拷贝的相关内容就介绍得差不多了。
### 总结
这一讲,我们探讨了如何实现一个深浅拷贝。在日常的开发中,由于开发者可以使用一些现成的库来实现深拷贝,所以很多人对如何实现深拷贝的细节问题并不清楚。但是如果仔细研究你就会发现,这部分内容对于你深入了解 JS 底层的原理有很大帮助。如果未来你需要自己实现一个前端相关的工具或者库,对 JS 理解的深度会决定你能把这个东西做得有多好。
其实到最后我们可以看到,自己完整实现一个深拷贝,还是考察了不少的知识点和编程能力,总结下来大致分为这几点,请看下图。
[外链图片转存中...(img-X5V9rMJw-1657763530864)]
可以看到通过这一个问题能考察的能力有很多,因此千万不要用最低的标准来要求自己,应该用类似的方法去分析每个问题深入考察的究竟是什么,这样才能更好地去全面提升自己的基本功。
关于深浅拷贝如果你有不清楚的地方,欢迎在评论区留言,最好的建议还是要多动手,不清楚的地方自己敲一遍代码,这样才能加深印象,然后更容易地去消化这部分内容。
下一讲,我们将迎来继承方式的学习,这部分知识也是非常重要的,你需要熟练掌握并理解其原理。也欢迎你提前预习相关知识,这样才能在不同的角度有所收获。下一讲再见。
最后
以上就是高挑小天鹅最近收集整理的关于JavaScript核心原理精讲第一章 基本功的全部内容,更多相关JavaScript核心原理精讲第一章内容请搜索靠谱客的其他文章。








发表评论 取消回复