NEON
- 1.简介
- 2.简单实例
- 3.总结
1.简介
没有长篇大论,只用于NEON快速入门!
SIMD:
- 单指令处理多个数据的并行技术
- 例如在C语言中对一个int[8]的数组里每一个数都执行加1操作,SIMD技术可以通过一条add指令并行处理;而通常我们自己写for循环需要执行8次add才能完成,耗时更多
NEON:
- 一种基于SIMD并适用于ARM的技术,从ARM-V7开始被采用,目前可以在ARM Cortex-A和Cortex-R系列处理器中使用
- 寄存器,用于存放需要操作的数据;16个128bit的寄存器(128bit代表最大长度,对于int类型数据,能存放4个,对于char类型数据能存放16个,也就是说我能直接把int[4]或者char[16]直接放到128bit的寄存器中)、32个64bit寄存器
- 支持的数据类型,上官网查询
- 常用操作:加减乘除,数据之间的读写等
2.简单实例
实例内容:两个长度为5000的int型数组相加,把每个结果存入另一个长度为5000的数组当中,对比纯C语言实现和NEON实现的性能。
纯C实现函数:平平无奇,谁都能写
void add_int_c(int* dst, int* src1, int* src2, int count)
{
int i;
for (i = 0; i < count; i++)
dst[i] = src1[i] + src2[i];
}
NEON实现函数:
int32x4_t in1, in2, out:用于存放4个int型数据的变量,int32x4_t是一个数据类型声明(和int效果一致),类似的还有int16x8_t(用于存放8个short类型数据)、int8x16_t(用于存放16个char类型数据),更详细的去官网查询
in1 = vld1q_s32(src1):将指针src1的4个数据加载到in1当中,vld1q_s32用于加载int型的数据,并且只会是4个数据,其余类型的加载函数自行查询,但都是相对应的
src1 += 4:数据加载完成后,指针向后移动4位,用于后续数据加载
out = vaddq_s32(in1, in2):执行in1和in2两个向量相加操作,并存入out中
vst1q_s32(dst, out):将out里的数据存入dst指针指向的内存中
完毕!
void add_int_neon(int* dst, int* src1, int* src2, int count)
{
int i;
for (i = 0; i < count; i += 4)
{
int32x4_t in1, in2, out;
in1 = vld1q_s32(src1);
src1 += 4;
in2 = vld1q_s32(src2);
src2 += 4;
out = vaddq_s32(in1, in2);
vst1q_s32(dst, out);
dst += 4;
}
}
整体代码
#include<time.h>
#include<stdio.h>
#include<stdlib.h>
#include<arm_neon.h>
void add_int_c(int* dst, int* src1, int* src2, int count)
{
int i;
for (i = 0; i < count; i++)
dst[i] = src1[i] + src2[i];
}
void add_int_neon(int* dst, int* src1, int* src2, int count)
{
int i;
for (i = 0; i < count; i += 4)
{
int32x4_t in1, in2, out;
in1 = vld1q_s32(src1);
src1 += 4;
in2 = vld1q_s32(src2);
src2 += 4;
out = vaddq_s32(in1, in2);
vst1q_s32(dst, out);
dst += 4;
}
}
int main()
{
/* 数据内存分配,初始化 */
int size = 5000;
int *dst = (int*)malloc(size * sizeof(int));
int *src1 = (int*)malloc(size * sizeof(int));
int *src2 = (int*)malloc(size * sizeof(int));
for(int i = 0; i < size; i++)
{
src1[i] = i;
src2[i] = i;
}
/* 时间初始化 */
struct timespec time1_img = {0, 0};
struct timespec time2_img = {0, 0};
clock_gettime(CLOCK_REALTIME, &time1_img);
for(int i = 0; i < size; i++)
{
add_int_c(dst, src1, src2, size);
}
clock_gettime(CLOCK_REALTIME, &time2_img);
printf("C time:%d msn", (time2_img.tv_sec - time1_img.tv_sec)*1000 + (time2_img.tv_nsec - time1_img.tv_nsec)/1000000);
printf("dst[0]:%dn", dst[0]);
memset(dst, 0, size);
clock_gettime(CLOCK_REALTIME, &time1_img);
for(int i = 0; i < size; i++)
{
add_int_neon(dst, src1, src2, size);
}
clock_gettime(CLOCK_REALTIME, &time2_img);
printf("Neon time:%d msn", (time2_img.tv_sec - time1_img.tv_sec)*1000 + (time2_img.tv_nsec - time1_img.tv_nsec)/1000000);
printf("dst[0]:%dn", dst[0]);
free(dst);
free(src1);
free(src2);
return 0;
}
Makefile
CC = @echo " GCC $@"; $(CROSS)gcc
CROSS = arm-xmv2-linux-
CFLAGS += -mcpu=cortex-a9 -mfloat-abi=softfp -mfpu=neon -mno-unaligned-access -fno-aggressive-loop-optimizations -flax-vector-conversions -fsigned-char -fopenmp
CFLAGS += -std=gnu99 -Wall -O2
TESTSOURCE = $(wildcard ./main.c)
TESTTARGET = main.out
TARGET = $(TESTTARGET)
all:$(TARGET)
$(TESTTARGET):
$(CC) $(CFLAGS) -save-temps -o $(TESTTARGET) $(TESTSOURCE) -lstdc++ -lm
clean:
rm -f $(TESTTARGET)
效果对比
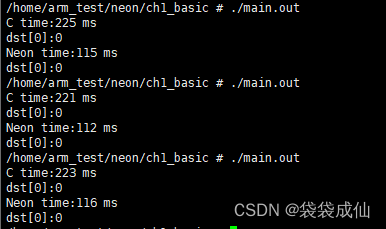
3.总结
- demo中可以明显看到程序执行耗时减少一半,效果非常明显
- neon只适用于重复运算,我们只需要找到那些具有重复运算的地方,然后使用neon进行加速
- 第一次看到这些函数非常陌生,多去官网查几次就熟悉了
最后
以上就是大胆月饼最近收集整理的关于NEON快速入门1.简介2.简单实例3.总结的全部内容,更多相关NEON快速入门1内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复