感谢参考原文-http://bjbsair.com/2020-04-01/tech-info/18556.html
本文精选了几篇因果表示学习领域的最新文献,并细致分析了不同方法的基本架构,希望能帮助感兴趣的你对因果学习应用于机器学习的方向和可能一探究竟。

因果推理(Causal inference)是根据影响发生的条件得出因果关系结论的过程,是研究如何更加科学地识别变量间的因果关系(Causality)。在因果关系中,原因对结果负有部分责任,而结果又部分取决于原因。客观事物普遍存在着内在的因果联系,人们只有弄清事物发展变化的前因后果,才能全面地、本质地认识事物。基干事物发展的这种规律,在论证观点时,有时就可以直接从事物本身的因果关系中进行推论,这就叫因果推理法。几十年来,因果推理一直是统计学、计算机科学、教育学、公共政策和经济学等许多领域的重要研究课题。
为了解决观测数据因果推断中的这些问题,研究人员开发了各种框架,包括潜在结果框架(the potential outcome framework)(潜在结果框架也称为内曼-鲁宾潜在结果或鲁宾因果模型(the Rubin Causal Model))和结构因果模型(the structural causal model,SCM)。UCLA 教授 Judea Pearl 在他的著作《Causality: models, reasoning, and inference》[1] 中介绍了 RCM 和 SCM 的等价性,就应用来看,RCM 更加精确,而 SCM 更加直观。Judea Pearl 是因果关系模型的倡导者之一。
机器之心在 2018 年也有一篇对于他的论文的报道:https://cloud.tencent.com/developer/article/1119926,探讨了机器学习的理论局限性与因果推理的七大特性。来自 University at Buffalo、University of Georgia、Alibaba 和 University of Virginia 的几位学者在 AAAI 2020 中发表了一篇关于 RCM 因果推理方法的的文章《A Survey on Causal Inference》[2],是第一篇对 RCM 和机器学习问题的综述,而关于 SCM 的介绍则主要可以参见 Judea Pearl 的综述《Causal inference in statistics: An overview》[3]。
而近年来,在以上提及的两个理论框架的基础上,机器学习领域的蓬勃发展促进了因果推理领域的发展。采用决策树、集成方法、深层神经网络等强大的机器学习方法,可以更准确地估计潜在结果。除了对结果估计模型的改进外,机器学习方法也为处理混杂问题提供了一个新的方向。借鉴近年来产生式对抗性神经网络等深度表征学习方法,通过学习所有协变量的平衡表征来调整共焦变量,使得在学习表征的条件下,处理任务独立于共焦变量。在机器学习中,数据越多越好。然而,在因果推理中,仅仅有更多的数据是不够的。拥有更多的数据只会有助于获得更精确的估计,但在因果推理的框架下,如果使用传统机器学习技巧,不能确保这些因果估计是正确和无偏的。
与传统的使用因果图连接随机变量来完成因果发现和推理假设任务的因果推理不同,近年来,关于**因果的表示学习(Causal Representation Learning)**问题吸引了越来越多的关注。因果表示学习是指从数据中学习变量,也就意味着,经过大数据学习,基于因果表示学习的机器学习算法或者能够超越传统的符号人工智能(symbolic AI)。它不要求人工划分的先验知识,就能从数据中学到信息。直接定义与因果模型相关的对象或变量,相当于直接提取真实世界的更详细的粗粒度模型。尽管经济学、医学或心理学中的每一个因果模型所使用的变量都是基本概念的抽象,但是要在存在干预的情况下使用粗粒度变量描述因果模型,仍然是非常困难的。
现有机器学习面临的另外一个困难是有效的训练数据。对于每个任务/领域,尤其以医学为例,只能掌握有限的数据。为了提高模型的效果,就必须想办法搜寻、汇集、重新使用或者人工编制数据的有效方法。这与目前由人类进行大规模标签工作的行业实践形成鲜明对比。因此,因果表示学习对人类和机器智能都是一项挑战,但它符合现代机器学习的总体目标,即学习数据的有意义表示,其中有意义表示稳健、可转移、可解释或公平。
在这篇文章中,我们选了几篇关于因果表示学习的最新文献,其中涉及了基于 SCM 和基于 RCM 的工作。我们主要分析了不同方法的基本架构,目的是对因果学习应用于机器学习的方向和可能一探究竟。
提取模块化结构(Learning modular structures)
因果表示学习的一个方向是提取模块化的结构,即世界的不同组件在一系列环境、任务和设置中存在,那么对于一个模型来说,使用相应的模块就是利用了有效的因果表示。例如,如果自然光的变化(太阳、云层等的位置)意味着视觉环境可以在几个数量级的亮度条件下出现,那么人类的神经系统中的视觉处理算法应该采用能够将这些变化因素化的方法,而不是建立单独的人脸识别器,比如说,适用于各种照明条件。如果大脑通过增益控制机制来补偿光照的变化,那么这个机制本身就不需要和导致亮度差异的物理机制有任何关系。Goyal 等针对这个方向,尝试将一组动态模块嵌入到一个递归神经网络中,由所谓的注意机制进行协调,这允许学习模块独立动态运行,同时也会存在相互影响。

论文地址:https://arxiv.org/pdf/1909.10893.pdf
RIM 中几个重要的概念:(1)**模块化:**机器学习中的生成模型可以看作是独立机制或「因果」模块的合成体,根据因果推理理论,模块化是对模型生成的变量进行局部干预(localized intervention)的先决条件。(2)**独立性:**独立性是因果推理的重要理论,即不同物体的运动或改变机制是相互独立的。(3)**稀疏性:**无需每次都对所有子系统付出同等的注意力,模型在制定决策或规划时,只考虑在当前时间节点存在强交互需求的子系统。
基于 RIM 架构学习得到的模型能够有效捕获真实世界中的组合生成结构(compositional generative structure)或因果结构(Causal structure),从而提升了模型完成不同任务的范化性能(这些任务大多数机制是相同的,只有一小部分机制发生变化)。RIM 整体架构见图 1。
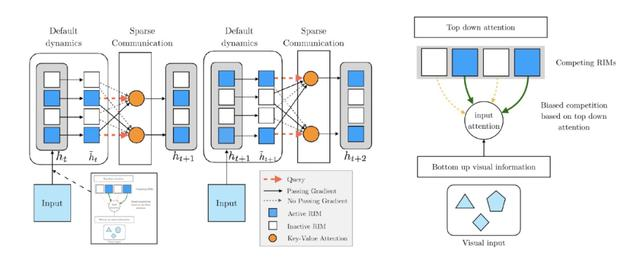
图 1. RIM 架构
RIM 架构的一个步骤分为四个阶段(图 1 中的左图显示了两个步骤)。在第一阶段中,各个 RIM 生成一个用于从当前输入读取的查询 query。在第二阶段,使用基于注意力的竞争机制,根据编码的视觉输入选择要激活的 RIM(右图)(基于注意力得分,蓝色 RIM 处于活动状态,白色 RIM 保持非活动状态)。在第三阶段,单个激活 RIM 按照默认转换动态运行,而非激活 RIM 保持不变。在第四阶段,使用注意力机制在 RIMs 之间进行稀疏通信。
在 RIM 架构中,将模型划分为 k 个子系统,其中每个子系统都可以单独的捕获转换动态,具体的,每个子系统设置为一个循环独立机(RIM),每个 RIM 基于自身函数、利用训练数据自动学习。在时间 k,RIM 的状态为 h_(t,k),参数为 θ_k。默认的机制是每个 RIM 专注于自身的小问题、单独处理自己的动态,根据决策任务的需要,与其他 RIM 进行交互。相较于传统的直接训练大型的系统,基于 RIM 架构能够节省计算消耗、提高系统的稳定性。
首先,对于未激活的 RIM(激活组为 St),其隐藏状态保持不变:
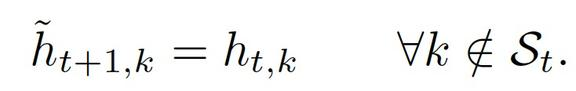
而对于激活的 RIM,运行一个独立的转换动态,将这些独立的转换动态记为 D_k,同时保证每个 RIM 都有自己的独立参数。以 LSTM 为例,激活的 RIM 响应于当前输入的注意力机制 A 的函数以下式更新
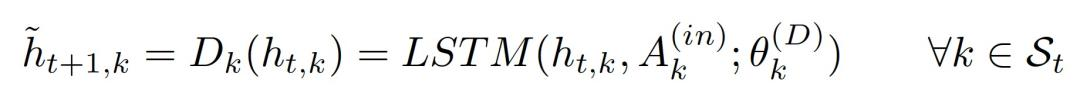
当输入与其相关时,激活并更新对应的 RIM,并为之分配所需要的表征和计算资源。如果训练数据是由一组独立的物理机制生成的,则其学习机制也是独立的。
注意力机制
这篇文章引入了注意力机制(attention mechanism)来选择:根据心理学研究显示,大脑对复杂实体进行并行处理的能力是有限的,许多代表视觉信息的大脑系统基于竞争(在整个视觉领域并行运行)来分配资源,以及这种分配通常还会受到来自更高大脑区域的反馈的影响,该理论在认知科学上称为差异竞争(biased competition)。基于内容的软注意力机制(content-based soft-attention mechanisms)对类型化的可互换对象集进行操作。这一思想目前广泛应用于最新的 transformer 的多头点乘自注意力模型,并在许多任务中获得了很好的效果。根据这个原理,软注意力机制计算一个 query(或称为 key)与对应的 key 矩阵的乘积,进行规范化处理之后,输出 softmax 值:
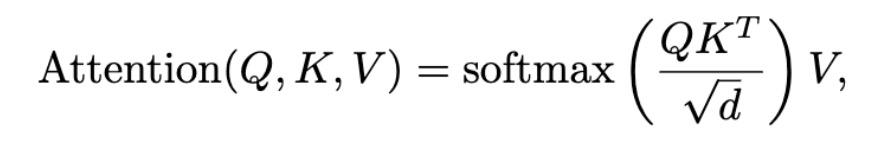
其中,softmax 应用于其参数矩阵的每一行,产生一组凸权重。作为结果,得到值 V 的凸组合。如果注意力集中在特定行的一个元素上(即 softmax 已饱和),则只需选择一个对象并将其值设置为结果中行 j 的值。请注意,键中的维度可以拆分为多个头(heads),然后分别计算它们的注意力矩阵和写入值。
当每个 RIM 的输入和输出是一组对象或实体(每一个都与键和值向量相关联)时,RIM 处理就变成了一个通用的对象属性的处理机器,它可以在类似于编程语言中变量的意义上操作「变量」:作为函数的可交换参数。因为每个对象都有一个密钥嵌入(可以理解为名字 name 或类型 type),所以相同的 RIM 处理可以应用于任何适合预期的「分布式类型」(由查询向量指定)的变量。然后,每个注意力的头对应于 RIM 计算的函数的一个类型参数。当对象的键与查询匹配时,它可以用作 RIM 的输入。而在常规的神经网络(没有使用注意力机制)中,神经元是以固定的变量(从前一层给它们输入的神经元)工作的。每个 RIM 有一组不同的查询嵌入,利用键值注意机制就可以动态选择哪个变量实例(即哪个实体或对象)将用作 RIM 动态机制的每个参数的输入。这些输入可以来自外部输入,也可以来自其它 RIM 的输出。因此,如果单个 RIM 可以用类型化参数表示这些「函数」,那么它们可以「绑定」到当前可用且最适合它的任何输入(根据它的注意力得分):「输入注意力」机制将查看候选输入目标的键,并评估其「类型」是否与 RIM 期望的匹配(在查询中指定)。
自上而下的框架
该模型动态地选择与当前输入相关的 RIM,令每个 RIM 在处理实际输入实例和一个特殊的空输入之间做出选择,空输入完全由零组成,因此不包含任何信息。在每个步骤中,根据实际输入的 softmax 值来选择最优的 k_A 个 RIM。这些 RIMs 必须在每个步骤上竞争以从输入中读取数据,只有赢得这一竞争的 RIM 才能从输入中读取数据并更新其状态。
时间 t 的输入值 x_t 被视为一组元素,结构为一个矩阵的行(对于图像数据,它可以是 CNN 的输出)。首先连接生成一个全零行向量,以获得:
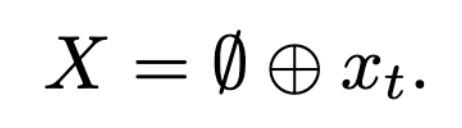
⊕表示行级级联操作。定义线性转换构造键(K=XW.k,每个输入元素一个,空元素一个)、值(V=XW.v,每个元素一个)和查询(Q=RW_k.^q,每个 RIM 注意头一个),其中 R 是每行(r_i)与单个 RIM 的隐藏状态相对应的矩阵。W_v 是从一个从输入元素到相应的加权注意值向量的映射矩阵,W_k 为权重矩阵,它将输入映射到键。W_k.^q 是从 RIM 的每个隐藏状态映射到其查询的权重矩阵。此时注意力机制为:
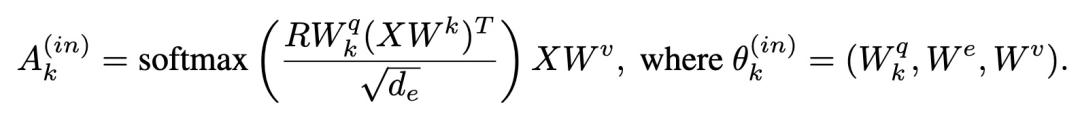
为每个步骤选择前 k 个 RIMs 进行激活,这些步骤对空输入的关注最少,将此集合定义为 S_t。由于查询依赖于 RIM 的状态,这使得单个 RIM 只关注与特定 RIM 相关的部分输入,从而基于自上而下的注意过程实现选择性注意(如图 1 所示的架构)。
RIM 之间的交互
虽然在默认情况下 RIM 是独立运行的,但是注意力机制允许 RIM 之间共享信息。具体来说,允许激活的 RIM 读取所有其他 RIM(无论激活与否)。这是由于,虽然未激活的 RIM 与当前输入无关因而其值不应改变,但是,它们仍然可以存储与激活的 RIM 相关的上下文信息。为了实现 RIM 之间的交互,本文使用了一种残余连接的方法防止长序列上的梯度消失或爆炸问题 [4]:
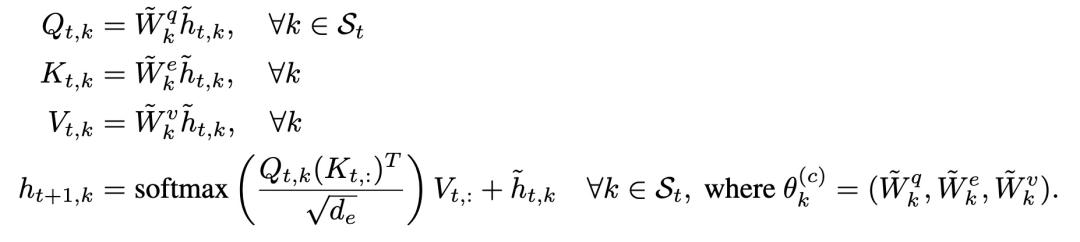
实验分析
当 RIM 用于处理包含不同时间模式的序列时,能够实现专门化以便根据不同模式激活不同的 RIM。因此,当修改模式的子集(特别是那些与类标签无关的子集)时,RIM 具有很好的泛化性能,而大多数递归模型并不能很好地泛化这些变体。
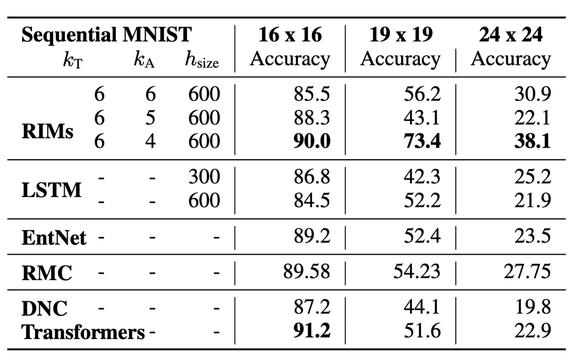
表 1. 序列 MNIST 分辨率任务的实验结果

图 2. 预测弹跳球的运动
反事实推理(Counterfactual)
因果表示学习的另外一个有趣的研究方向是反事实推理在领域适应问题中的应用。统计学习理论中最基本的假设是训练数据和测试数据来自同一分布。然而,在大多数实际情况下,测试数据是从只与训练数据的分布相关但不完全相同的分布中提取的。在因果推理中,这也是一个很大的挑战,反事实分布一般会与事实分布不同。因此,有必要通过从实际数据中学习来预测反事实结果,从而将因果推理问题转化为领域适应问题。关于反事实推理的应用,我们找到两篇有趣的文章,分别遵循 SCM 和 RCM 架构进行分析,一篇聚焦图像处理问题,另一篇则探讨文本分析问题。

论文地址:https://arxiv.org/pdf/1812.03253.pdf
**基于 SCM 提取独立分离的表征。**在图像处理领域中,一些基本表征是问题不变的,或者说它们是可以被独立地干预 (intervention) 来实现,对于部分独立分离的表征进行处理和操作,仍然能够生成有效的图像,这些图像可以使用生成性对抗网络(a generative adversarial network,GAN)的鉴别器来训练。在极端情况下,还可以混合潜在向量,其中每个分量都是从另一个训练示例中计算出来的。对于遵循独立同分布(IID)的训练集,这些潜在向量具有统计独立的分量。在这样的架构中,编码器是一个识别或重建世界上因果驱动因素的反因果映射,解码器建立了低维潜在表示(驱动因果模型的噪声)和高维世界之间的联系。如果潜在表征重构了(驱动)真正因果变量的噪声,则通过对这些噪声(及其驱动机制)进行干预,能够生成有效的图像数据。
这篇文章提出了一个因果生成模型(A Causal Generative Model,CGM)框架。如图 2b 所示, 本质也是一个因果图模型,其基本假设前提仍然是因果原理的独立机制,即促成生成过程的因果机制相互之间无影响。因此,可以通过单独修改某些生成机制来研究直接干预神经网络模型的效果。具体到生成模型中,因果关系允许分析如果某些变量采用不同的值(称为「反事实值」,counterfactual),结果会如何改变,进而评估生成模型捕获因果机制的能力。CGM 框架如图 3 所示,其中,(a)给出 生成映射和分离变换的图示,(b)为显示节点之间不同类型独立性的示例 CGM 的因果图,(c)为显示与分离变换 t 相关的潜在空间中的稀疏变换 t′的交换图,(d)为内在分离的图示。
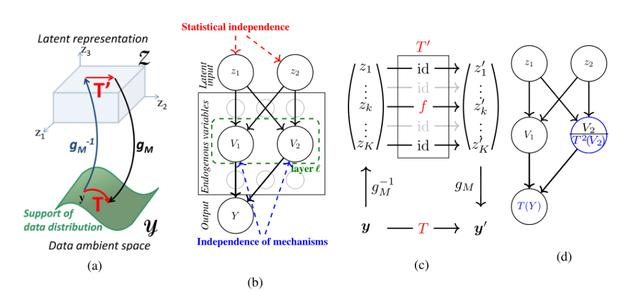
图 3. CGM 框架
给定一个实现函数 g_M 的生成模型 M,该模型将潜空间 Z 映射到学习数据点所在的流形 y_M,嵌入到周围欧氏空间 Y 中。模型中的一个样本是通过从具有相互独立的分量、完全支持 z 的先前潜在变量分布中提取实现 z 来生成的。使用术语表示(representation)来指定从 y_M 到某个表示空间 R 的映射 r(也将 r(y)称为点 y∈y_M 的表示)。此外,假定 g_M 可逆,(g_M).^-1 为数据表示,记为潜在表示(latent representation)。假设生成模型是由一个非递归神经网络实现的,使用一个因果图形模型(即 SCM)来表示通过一系列操作实现映射 g_M 的计算图(因果语言中称为函数赋值, functional assignments)。除了潜在表示,还可以选择一组可能由因果图中的节点表示的多维内生(内部)变量(endogenous variables)(图 3b),例如,映射 g_M 是由内生变量赋值 v_M 和内生映射 g_M 组成的:
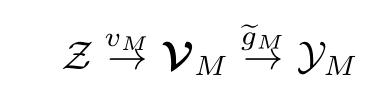
这些变量的一个典型选择是在卷积神经网络的一个隐藏层中收集每个通道的输出激活图。对于潜在情况,使用了一些条件来保证 g_M 可逆的,进而定义了网络的内部表示。给定潜在变量和内生变量的典型维度选择,约束 V_k 的取值为比其欧氏周围空间 V_k 更小维度的子集 (V.^k)_M 中的值。
无监督独立:从统计原理到因果原理
经典的独立表征(disentangled representation)概念假设个体潜在变量「对现实世界的转变进行的稀疏编码」。虽然,所谓「现实世界的转变」这一概念是很难具象化的,但这种对统计概念不可知的洞察力,推动了有监督的方法实现分离表示,在这种方法中,相关的转变可以通过适当的数据集和训练程序得到明确的识别和操作。
相比之下,无监督的独立性表示学习则需要从未标记的数据中学习这种现实世界的转变。为了应对这一挑战,SOTA 方法试图通过个体潜在因素的变化来实现这种转换,并借助于一种分离的统计概念,在潜在因素之间实现条件独立。
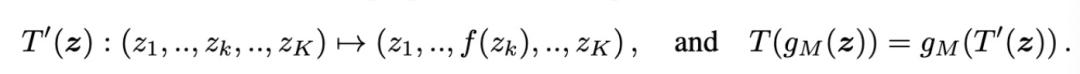
通过操纵内部表示来实现独立
如图 3b 的 CGM 所示,与潜在变量相比,由于常见的延迟原因,由图形模型的内生变量编码的属性无法保证在统计上是独立的,但是仍然能够遵循独立性原则独立的干预数据。由图 3d 所示,其中分割节点表示在应用变换 T.^2 之前,在原始 CGM(3b)中计算 V2 的值。
发现深度模型中的模块性
我们不会详细介绍模型中的详细算法,但会简略介绍它的体系设计:模块性定义为能够实现任意独立转换的内部表示的结构属性。考虑一个标准的前向多层神经网络,选择「内生变量」作为给定层 L 的「通道」的所有输出激活的集合。令 E 为这些通道的子集,模块间杂交过程如图 4 所示。举两个潜在变量 z1 和 z2 的独立例子,它们将生成两个原始输出示例(y1,y2)=(gM(z1),gM(z2))(称之为 Original1 和 Original2)。同时生成 Original2 时定义 v(z2) 收集由 E 索引的全部变量的值,以及 tilde{v}(z1)表示在生成 Original 1 时由该层上所有其他内生变量获取的值的元组。假设选择模块化的结构tilde{v}(z1)和 v(z2)将对其相应生成图像的不同方面进行编码,以便可以通过将层的输出值集合与特定元组分配来生成混合这些特征的混合示例,并将其发送至生成网络的下游部分。
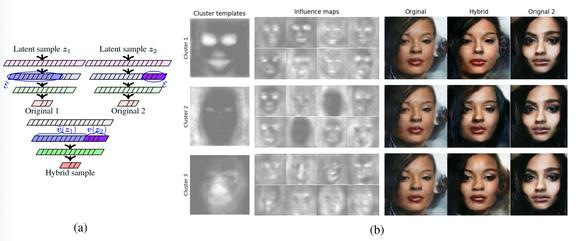
图 4. 影响图的生成
衡量因果效应
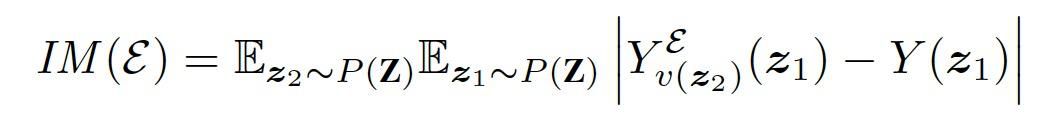
其中 Y(z1) 是潜在输入 z1 生成的无干扰输出。绝对值内的差异可以解释为潜在结果框架中的单元级因果效应 (unit-level causal effect),以及,求取这种期望近似于计算平均治疗效果(average treatment effect)。上式的输出 IM 与输出图像的尺寸相同时,通过颜色通道对其求取平均,从而得到一个灰度热图像素图。
模块和反事实图像的无监督检测
图 5 给出了一个在 CelebA 数据库上训练得到的 VAE 卷积层通道的表示 EIMs 示例,以及,图中通道实现了功能性的分级,例如一些影响更精细的面部特征(眼睛、嘴,…)和其他影响图像的背景或头发等等。这就说明,单个通道可以聚合形成模块,而这些模块对应于输出(人脸图像)的一个特定特征。

图 5. 生成影响图。VAE 在 CelebA 数据库上生成的影响图示例(颜色较浅的像素代表较大的方差,以及扰动对该像素的影响更大)
为了在无监督的情况下实现这种分组,使用 EIM 作为特征向量对通过进行聚类:首先对每个影响图进行预处理,方法是:(1)使用一个小的矩形滑动窗口进行算术平均,以在空间上平滑贴图;(2)在图像上的值分布的 75% 的百分位处对生成的贴图进行阈值化处理,以获得二值图像。在对图像进行降维后,得到一个(通道×像素)矩阵,然后用人工选择的秩 K 将其输入到一个非负矩阵分解(Non-negative Matrix Factorization,NMF)算法中,得到 S=WH。从得到的两个因子矩阵中,得到 K 聚类模板模式(通过根据图像维度重塑 H 的每一行得到),以及每一个模式对单个映射(在 W 中编码)贡献的权重表示。每个影响图都是一个基于模板模式的最大权重聚类。
实验分析

图 6. BigGAN 跨类杂交的示例。左:鸵鸟公鸡,右:考拉泰迪

论文地址:https://www.ijcai.org/Proceedings/2019/570
平衡因果表示学习
治疗效果 (treatment effect),又称因果效应 (causal effect),是指一个变量(即治疗)对另一个变量(即结果)的影响。如果对治疗进行干预,假设协变量不变(即这些协变量的条件),治疗效果被定义为结果的变化,其中协变量是与治疗和结果相关的变量或特征。在文本分析领域,大多数模型关注的是数值协变量,而如何处理具有文本信息的协变量来估计模型效果仍是一个悬而未决的问题。然而,在现实世界中,文本数据几乎无处不在,如临床治疗记录、电影评论、新闻、社交媒体帖子等。针对这一问题,这篇文章提出了一种基于条件治疗的对抗性学习匹配(conditional treatment-adversarial learning based matching,CTAM)方法。CTAM 融合了治疗对抗性学习,在学习表征时过滤掉与工具变量相关的信息,然后在学习表征之间进行匹配,以估计处理效果。
令 Z 和 Z’分别表示观察到的文本协变量 T 和非文本协变量 X 的潜在表示。在潜在表示中,Z’更接近工具变量,因此比结果 Y 更能预测治疗分配。任务目标是学习潜在的表征,过滤掉与仪器变量相关的信息。CTAM 的因果图表示为:
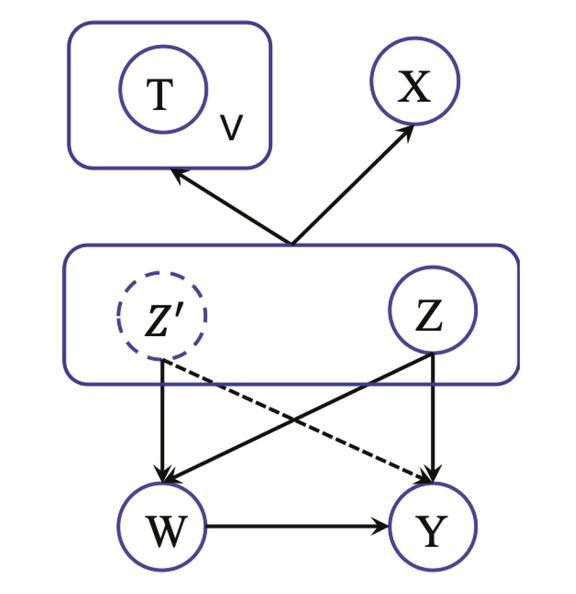
图 7. CTAM 因果图
CTAM 引入条件治疗对抗学习,以尽可能地消除潜在表征中与 Z’相关的信息。CTAM 框架的结构为:
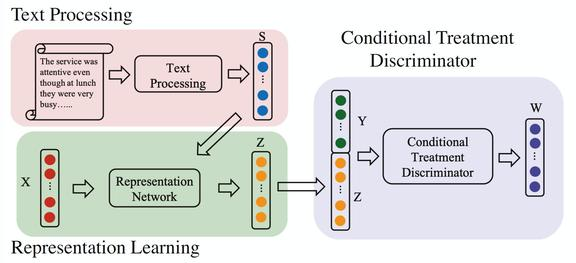
图 8. CTAM 框架
CTAM 包含三个主要部分:文本处理、表示学习和条件处理鉴别器。通过文本处理组件,将原始文本转化为矢量化的表示 S,将 S 与非文本协变量 X 连接起来,构造一个统一的特征向量 C,然后将其输入到表示神经网络中,得到潜在表示 Z。在学习了表示之后,Z 和潜在结果 Y 一起被输入到条件治疗鉴别器中。在训练过程中,表示学习与条件治疗鉴别器进行极大极小博弈:通过阻止鉴别器进行正确的治疗,使表征学习过滤掉与结构变量相关的信息。
文本处理
文本处理过程将文本数据 T 转换为向量表示 S。这篇文章采用了 GloVe 单词嵌入方法 [6],S 是一个文档中所有单词嵌入的平均值。
表示学习
条件处理鉴别器
条件处理鉴别器的输入是潜在表示 Z 和潜在结果 Y,输出是处理分配 W。判别条件只依赖于潜在表示 (latent representation) 的结果,这使得潜在表示只通过潜在的结果分布与治疗相关。也就是说,通过使用条件处理鉴别器,利用极大极小博弈,学习的潜在表示能够通过处理分配消除掉条件依赖。
条件处理鉴别器也是一种前馈神经网络 D,其目标是正确地预测治疗分配。条件处理鉴别器的损失用交叉熵来衡量:
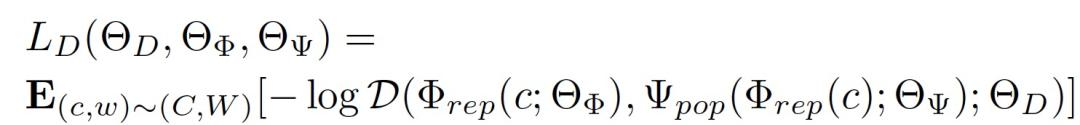
由于此处的潜在结果仅适用于条件治疗鉴别器,而不是显示结果,因此将其命名为伪潜在结果。
条件治疗对抗性学习的目的是去除掉与近似工具变量有关的信息。近似工具变量指的是对治疗分配更具预测性的变量而不是结果,这种过滤策略相当于去除潜在表示和治疗分配之间的条件依赖。因此,通过训练一种对抗性学习模式来达到这一目标。鉴别器 D 执行极小极大博弈。鉴别器 D 一方面通过最小化上式给出正确的治疗;另一方面,向表示学习重新发送结果预测值进行训练,使上述损失最大化,过滤掉有利于鉴别器 D 的信息。当成功的「愚弄」了条件治疗鉴别器,就能够从潜在表示中消除掉增强治疗分配的信息,即,成功地过滤掉与结构变量相关的信息。
损失函数
CTAM 三层结构的完整损失函数为:
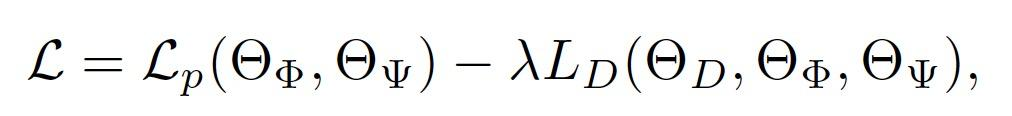
其中 L_D 为上文介绍的条件处理鉴别器的交叉熵损失,L_p 是群距离和伪结果预测损失之和:
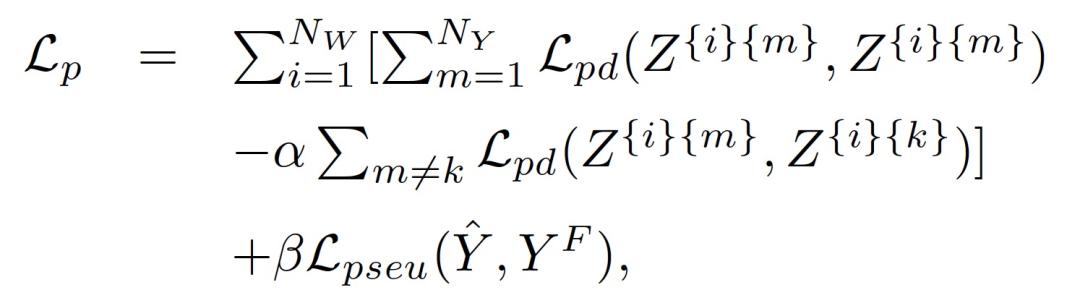
L_p 中的第一项测量相同治疗下共享观察结果标签的记录之间的成对距离,第二项测量具有不同观察结果的记录之间的成对距离。最小化两项之间的差异会使得相似的记录彼此靠近,而使得表示空间中的不同记录彼此远离。第三项是伪结果预测损失,最小化它可以更好地预测条件治疗鉴别器的潜在结果。
模型训练
训练过程包括优化鉴别者、表示学习和伪结果预测者之间的极大极小博弈,可以看作:
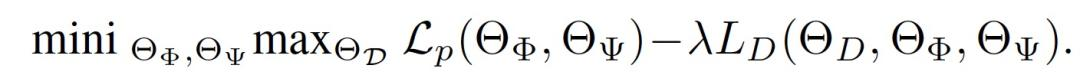
以及三层更新过程为:
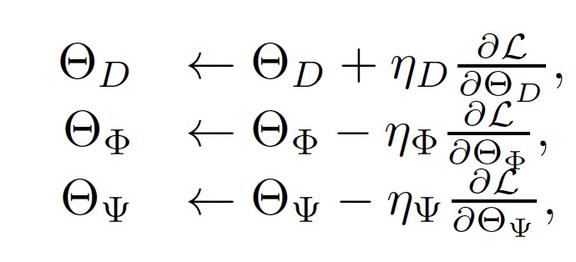
实验分析
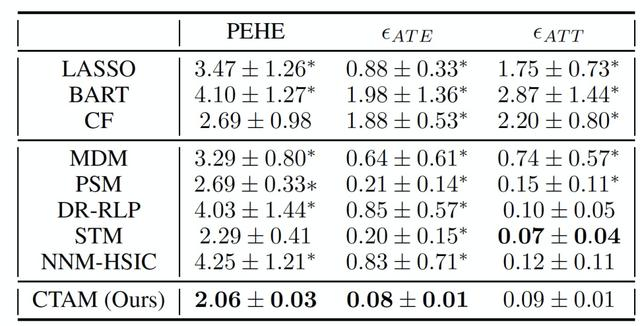
表 2.News 新闻数据集中的实验结果
由表 2,CTAM 在 PEHE 和 E_ATE 指标下具有最好的性能,在 E_ATT 指标下性能与最佳基线方法 STM 相比类似。这一结果表明,条件治疗鉴别器能有效地滤除与近似工具变量有关的信息,从而减少治疗效果估计的偏差。
展望
现代机器学习的表示学习主要目标是学习到能够保持相关统计特性的数据表征。然而,这种做法没有考虑到变量的因果性质,也就是说,它不关心它分析或重建的变量的介入性质。本文介绍了 3 篇利用表征学习实现因果学习的目的,其中共同之处是如何在物理世界、有限的数据采集情况下,在表征中实现物理因果关系的特性分离(disentanglement)。这在数据有限,以及实验不能重复 (也就是 counterfactual)中尤其难办。为了解决这问题,第二三篇都采用了生成模型(generative model) 或者类似思想来在潜在空间「虚拟」一个独立的原因,而第一篇则着重利用了注意力机制来模拟大脑从上而下(top-down)的预测过程。总体来说,引入因果关系,将能够把表示学习提升到更高的层次:超越统计依赖结构的表征,向支持干预、规划和推理的模型迈进,实现康拉德·洛伦兹(Konrad Lorenz)的想象空间思维概念(thinking as acting in an imagined space)。这最终要求机器有能力反省自己的行为和设想其他的情况,即需要(幻想)自由意志。自我意志的生物学功能可能与在洛伦兹想象的空间中需要一个代表自己的变量有关,自由意志则可能是一种交流该变量所采取行动的手段,对社会和文化学习至关重要,虽然它是人类智能的核心,但目前,机器学习还无法真正的实现。本篇文章结合最新的研究成果分析了向已有的表示学习方法/模型中引入因果机制的效果,但实际上最困难的问题尚未得到解决,关于这一领域的基础性分析有待更深入的研究。
感谢参考原文-http://bjbsair.com/2020-04-01/tech-info/18556.html
本文精选了几篇因果表示学习领域的最新文献,并细致分析了不同方法的基本架构,希望能帮助感兴趣的你对因果学习应用于机器学习的方向和可能一探究竟。
因果推理(Causal inference)是根据影响发生的条件得出因果关系结论的过程,是研究如何更加科学地识别变量间的因果关系(Causality)。在因果关系中,原因对结果负有部分责任,而结果又部分取决于原因。客观事物普遍存在着内在的因果联系,人们只有弄清事物发展变化的前因后果,才能全面地、本质地认识事物。基干事物发展的这种规律,在论证观点时,有时就可以直接从事物本身的因果关系中进行推论,这就叫因果推理法。几十年来,因果推理一直是统计学、计算机科学、教育学、公共政策和经济学等许多领域的重要研究课题。
为了解决观测数据因果推断中的这些问题,研究人员开发了各种框架,包括潜在结果框架(the potential outcome framework)(潜在结果框架也称为内曼-鲁宾潜在结果或鲁宾因果模型(the Rubin Causal Model))和结构因果模型(the structural causal model,SCM)。UCLA 教授 Judea Pearl 在他的著作《Causality: models, reasoning, and inference》[1] 中介绍了 RCM 和 SCM 的等价性,就应用来看,RCM 更加精确,而 SCM 更加直观。Judea Pearl 是因果关系模型的倡导者之一。
机器之心在 2018 年也有一篇对于他的论文的报道:https://cloud.tencent.com/developer/article/1119926,探讨了机器学习的理论局限性与因果推理的七大特性。来自 University at Buffalo、University of Georgia、Alibaba 和 University of Virginia 的几位学者在 AAAI 2020 中发表了一篇关于 RCM 因果推理方法的的文章《A Survey on Causal Inference》[2],是第一篇对 RCM 和机器学习问题的综述,而关于 SCM 的介绍则主要可以参见 Judea Pearl 的综述《Causal inference in statistics: An overview》[3]。
而近年来,在以上提及的两个理论框架的基础上,机器学习领域的蓬勃发展促进了因果推理领域的发展。采用决策树、集成方法、深层神经网络等强大的机器学习方法,可以更准确地估计潜在结果。除了对结果估计模型的改进外,机器学习方法也为处理混杂问题提供了一个新的方向。借鉴近年来产生式对抗性神经网络等深度表征学习方法,通过学习所有协变量的平衡表征来调整共焦变量,使得在学习表征的条件下,处理任务独立于共焦变量。在机器学习中,数据越多越好。然而,在因果推理中,仅仅有更多的数据是不够的。拥有更多的数据只会有助于获得更精确的估计,但在因果推理的框架下,如果使用传统机器学习技巧,不能确保这些因果估计是正确和无偏的。
与传统的使用因果图连接随机变量来完成因果发现和推理假设任务的因果推理不同,近年来,关于**因果的表示学习(Causal Representation Learning)**问题吸引了越来越多的关注。因果表示学习是指从数据中学习变量,也就意味着,经过大数据学习,基于因果表示学习的机器学习算法或者能够超越传统的符号人工智能(symbolic AI)。它不要求人工划分的先验知识,就能从数据中学到信息。直接定义与因果模型相关的对象或变量,相当于直接提取真实世界的更详细的粗粒度模型。尽管经济学、医学或心理学中的每一个因果模型所使用的变量都是基本概念的抽象,但是要在存在干预的情况下使用粗粒度变量描述因果模型,仍然是非常困难的。
现有机器学习面临的另外一个困难是有效的训练数据。对于每个任务/领域,尤其以医学为例,只能掌握有限的数据。为了提高模型的效果,就必须想办法搜寻、汇集、重新使用或者人工编制数据的有效方法。这与目前由人类进行大规模标签工作的行业实践形成鲜明对比。因此,因果表示学习对人类和机器智能都是一项挑战,但它符合现代机器学习的总体目标,即学习数据的有意义表示,其中有意义表示稳健、可转移、可解释或公平。
在这篇文章中,我们选了几篇关于因果表示学习的最新文献,其中涉及了基于 SCM 和基于 RCM 的工作。我们主要分析了不同方法的基本架构,目的是对因果学习应用于机器学习的方向和可能一探究竟。
提取模块化结构(Learning modular structures)
因果表示学习的一个方向是提取模块化的结构,即世界的不同组件在一系列环境、任务和设置中存在,那么对于一个模型来说,使用相应的模块就是利用了有效的因果表示。例如,如果自然光的变化(太阳、云层等的位置)意味着视觉环境可以在几个数量级的亮度条件下出现,那么人类的神经系统中的视觉处理算法应该采用能够将这些变化因素化的方法,而不是建立单独的人脸识别器,比如说,适用于各种照明条件。如果大脑通过增益控制机制来补偿光照的变化,那么这个机制本身就不需要和导致亮度差异的物理机制有任何关系。Goyal 等针对这个方向,尝试将一组动态模块嵌入到一个递归神经网络中,由所谓的注意机制进行协调,这允许学习模块独立动态运行,同时也会存在相互影响。
论文地址:https://arxiv.org/pdf/1909.10893.pdf
RIM 中几个重要的概念:(1)**模块化:**机器学习中的生成模型可以看作是独立机制或「因果」模块的合成体,根据因果推理理论,模块化是对模型生成的变量进行局部干预(localized intervention)的先决条件。(2)**独立性:**独立性是因果推理的重要理论,即不同物体的运动或改变机制是相互独立的。(3)**稀疏性:**无需每次都对所有子系统付出同等的注意力,模型在制定决策或规划时,只考虑在当前时间节点存在强交互需求的子系统。
基于 RIM 架构学习得到的模型能够有效捕获真实世界中的组合生成结构(compositional generative structure)或因果结构(Causal structure),从而提升了模型完成不同任务的范化性能(这些任务大多数机制是相同的,只有一小部分机制发生变化)。RIM 整体架构见图 1。
图 1. RIM 架构
RIM 架构的一个步骤分为四个阶段(图 1 中的左图显示了两个步骤)。在第一阶段中,各个 RIM 生成一个用于从当前输入读取的查询 query。在第二阶段,使用基于注意力的竞争机制,根据编码的视觉输入选择要激活的 RIM(右图)(基于注意力得分,蓝色 RIM 处于活动状态,白色 RIM 保持非活动状态)。在第三阶段,单个激活 RIM 按照默认转换动态运行,而非激活 RIM 保持不变。在第四阶段,使用注意力机制在 RIMs 之间进行稀疏通信。
在 RIM 架构中,将模型划分为 k 个子系统,其中每个子系统都可以单独的捕获转换动态,具体的,每个子系统设置为一个循环独立机(RIM),每个 RIM 基于自身函数、利用训练数据自动学习。在时间 k,RIM 的状态为 h_(t,k),参数为 θ_k。默认的机制是每个 RIM 专注于自身的小问题、单独处理自己的动态,根据决策任务的需要,与其他 RIM 进行交互。相较于传统的直接训练大型的系统,基于 RIM 架构能够节省计算消耗、提高系统的稳定性。
首先,对于未激活的 RIM(激活组为 St),其隐藏状态保持不变:
而对于激活的 RIM,运行一个独立的转换动态,将这些独立的转换动态记为 D_k,同时保证每个 RIM 都有自己的独立参数。以 LSTM 为例,激活的 RIM 响应于当前输入的注意力机制 A 的函数以下式更新
当输入与其相关时,激活并更新对应的 RIM,并为之分配所需要的表征和计算资源。如果训练数据是由一组独立的物理机制生成的,则其学习机制也是独立的。
注意力机制
这篇文章引入了注意力机制(attention mechanism)来选择:根据心理学研究显示,大脑对复杂实体进行并行处理的能力是有限的,许多代表视觉信息的大脑系统基于竞争(在整个视觉领域并行运行)来分配资源,以及这种分配通常还会受到来自更高大脑区域的反馈的影响,该理论在认知科学上称为差异竞争(biased competition)。基于内容的软注意力机制(content-based soft-attention mechanisms)对类型化的可互换对象集进行操作。这一思想目前广泛应用于最新的 transformer 的多头点乘自注意力模型,并在许多任务中获得了很好的效果。根据这个原理,软注意力机制计算一个 query(或称为 key)与对应的 key 矩阵的乘积,进行规范化处理之后,输出 softmax 值:
其中,softmax 应用于其参数矩阵的每一行,产生一组凸权重。作为结果,得到值 V 的凸组合。如果注意力集中在特定行的一个元素上(即 softmax 已饱和),则只需选择一个对象并将其值设置为结果中行 j 的值。请注意,键中的维度可以拆分为多个头(heads),然后分别计算它们的注意力矩阵和写入值。
当每个 RIM 的输入和输出是一组对象或实体(每一个都与键和值向量相关联)时,RIM 处理就变成了一个通用的对象属性的处理机器,它可以在类似于编程语言中变量的意义上操作「变量」:作为函数的可交换参数。因为每个对象都有一个密钥嵌入(可以理解为名字 name 或类型 type),所以相同的 RIM 处理可以应用于任何适合预期的「分布式类型」(由查询向量指定)的变量。然后,每个注意力的头对应于 RIM 计算的函数的一个类型参数。当对象的键与查询匹配时,它可以用作 RIM 的输入。而在常规的神经网络(没有使用注意力机制)中,神经元是以固定的变量(从前一层给它们输入的神经元)工作的。每个 RIM 有一组不同的查询嵌入,利用键值注意机制就可以动态选择哪个变量实例(即哪个实体或对象)将用作 RIM 动态机制的每个参数的输入。这些输入可以来自外部输入,也可以来自其它 RIM 的输出。因此,如果单个 RIM 可以用类型化参数表示这些「函数」,那么它们可以「绑定」到当前可用且最适合它的任何输入(根据它的注意力得分):「输入注意力」机制将查看候选输入目标的键,并评估其「类型」是否与 RIM 期望的匹配(在查询中指定)。
自上而下的框架
该模型动态地选择与当前输入相关的 RIM,令每个 RIM 在处理实际输入实例和一个特殊的空输入之间做出选择,空输入完全由零组成,因此不包含任何信息。在每个步骤中,根据实际输入的 softmax 值来选择最优的 k_A 个 RIM。这些 RIMs 必须在每个步骤上竞争以从输入中读取数据,只有赢得这一竞争的 RIM 才能从输入中读取数据并更新其状态。
时间 t 的输入值 x_t 被视为一组元素,结构为一个矩阵的行(对于图像数据,它可以是 CNN 的输出)。首先连接生成一个全零行向量,以获得:
⊕表示行级级联操作。定义线性转换构造键(K=XW.k,每个输入元素一个,空元素一个)、值(V=XW.v,每个元素一个)和查询(Q=RW_k.^q,每个 RIM 注意头一个),其中 R 是每行(r_i)与单个 RIM 的隐藏状态相对应的矩阵。W_v 是从一个从输入元素到相应的加权注意值向量的映射矩阵,W_k 为权重矩阵,它将输入映射到键。W_k.^q 是从 RIM 的每个隐藏状态映射到其查询的权重矩阵。此时注意力机制为:
为每个步骤选择前 k 个 RIMs 进行激活,这些步骤对空输入的关注最少,将此集合定义为 S_t。由于查询依赖于 RIM 的状态,这使得单个 RIM 只关注与特定 RIM 相关的部分输入,从而基于自上而下的注意过程实现选择性注意(如图 1 所示的架构)。
RIM 之间的交互
虽然在默认情况下 RIM 是独立运行的,但是注意力机制允许 RIM 之间共享信息。具体来说,允许激活的 RIM 读取所有其他 RIM(无论激活与否)。这是由于,虽然未激活的 RIM 与当前输入无关因而其值不应改变,但是,它们仍然可以存储与激活的 RIM 相关的上下文信息。为了实现 RIM 之间的交互,本文使用了一种残余连接的方法防止长序列上的梯度消失或爆炸问题 [4]:
实验分析
当 RIM 用于处理包含不同时间模式的序列时,能够实现专门化以便根据不同模式激活不同的 RIM。因此,当修改模式的子集(特别是那些与类标签无关的子集)时,RIM 具有很好的泛化性能,而大多数递归模型并不能很好地泛化这些变体。
表 1. 序列 MNIST 分辨率任务的实验结果
图 2. 预测弹跳球的运动
反事实推理(Counterfactual)
因果表示学习的另外一个有趣的研究方向是反事实推理在领域适应问题中的应用。统计学习理论中最基本的假设是训练数据和测试数据来自同一分布。然而,在大多数实际情况下,测试数据是从只与训练数据的分布相关但不完全相同的分布中提取的。在因果推理中,这也是一个很大的挑战,反事实分布一般会与事实分布不同。因此,有必要通过从实际数据中学习来预测反事实结果,从而将因果推理问题转化为领域适应问题。关于反事实推理的应用,我们找到两篇有趣的文章,分别遵循 SCM 和 RCM 架构进行分析,一篇聚焦图像处理问题,另一篇则探讨文本分析问题。
论文地址:https://arxiv.org/pdf/1812.03253.pdf
**基于 SCM 提取独立分离的表征。**在图像处理领域中,一些基本表征是问题不变的,或者说它们是可以被独立地干预 (intervention) 来实现,对于部分独立分离的表征进行处理和操作,仍然能够生成有效的图像,这些图像可以使用生成性对抗网络(a generative adversarial network,GAN)的鉴别器来训练。在极端情况下,还可以混合潜在向量,其中每个分量都是从另一个训练示例中计算出来的。对于遵循独立同分布(IID)的训练集,这些潜在向量具有统计独立的分量。在这样的架构中,编码器是一个识别或重建世界上因果驱动因素的反因果映射,解码器建立了低维潜在表示(驱动因果模型的噪声)和高维世界之间的联系。如果潜在表征重构了(驱动)真正因果变量的噪声,则通过对这些噪声(及其驱动机制)进行干预,能够生成有效的图像数据。
这篇文章提出了一个因果生成模型(A Causal Generative Model,CGM)框架。如图 2b 所示, 本质也是一个因果图模型,其基本假设前提仍然是因果原理的独立机制,即促成生成过程的因果机制相互之间无影响。因此,可以通过单独修改某些生成机制来研究直接干预神经网络模型的效果。具体到生成模型中,因果关系允许分析如果某些变量采用不同的值(称为「反事实值」,counterfactual),结果会如何改变,进而评估生成模型捕获因果机制的能力。CGM 框架如图 3 所示,其中,(a)给出 生成映射和分离变换的图示,(b)为显示节点之间不同类型独立性的示例 CGM 的因果图,(c)为显示与分离变换 t 相关的潜在空间中的稀疏变换 t′的交换图,(d)为内在分离的图示。
图 3. CGM 框架
给定一个实现函数 g_M 的生成模型 M,该模型将潜空间 Z 映射到学习数据点所在的流形 y_M,嵌入到周围欧氏空间 Y 中。模型中的一个样本是通过从具有相互独立的分量、完全支持 z 的先前潜在变量分布中提取实现 z 来生成的。使用术语表示(representation)来指定从 y_M 到某个表示空间 R 的映射 r(也将 r(y)称为点 y∈y_M 的表示)。此外,假定 g_M 可逆,(g_M).^-1 为数据表示,记为潜在表示(latent representation)。假设生成模型是由一个非递归神经网络实现的,使用一个因果图形模型(即 SCM)来表示通过一系列操作实现映射 g_M 的计算图(因果语言中称为函数赋值, functional assignments)。除了潜在表示,还可以选择一组可能由因果图中的节点表示的多维内生(内部)变量(endogenous variables)(图 3b),例如,映射 g_M 是由内生变量赋值 v_M 和内生映射 g_M 组成的:
这些变量的一个典型选择是在卷积神经网络的一个隐藏层中收集每个通道的输出激活图。对于潜在情况,使用了一些条件来保证 g_M 可逆的,进而定义了网络的内部表示。给定潜在变量和内生变量的典型维度选择,约束 V_k 的取值为比其欧氏周围空间 V_k 更小维度的子集 (V.^k)_M 中的值。
无监督独立:从统计原理到因果原理
经典的独立表征(disentangled representation)概念假设个体潜在变量「对现实世界的转变进行的稀疏编码」。虽然,所谓「现实世界的转变」这一概念是很难具象化的,但这种对统计概念不可知的洞察力,推动了有监督的方法实现分离表示,在这种方法中,相关的转变可以通过适当的数据集和训练程序得到明确的识别和操作。
相比之下,无监督的独立性表示学习则需要从未标记的数据中学习这种现实世界的转变。为了应对这一挑战,SOTA 方法试图通过个体潜在因素的变化来实现这种转换,并借助于一种分离的统计概念,在潜在因素之间实现条件独立。
通过操纵内部表示来实现独立
如图 3b 的 CGM 所示,与潜在变量相比,由于常见的延迟原因,由图形模型的内生变量编码的属性无法保证在统计上是独立的,但是仍然能够遵循独立性原则独立的干预数据。由图 3d 所示,其中分割节点表示在应用变换 T.^2 之前,在原始 CGM(3b)中计算 V2 的值。
发现深度模型中的模块性
我们不会详细介绍模型中的详细算法,但会简略介绍它的体系设计:模块性定义为能够实现任意独立转换的内部表示的结构属性。考虑一个标准的前向多层神经网络,选择「内生变量」作为给定层 L 的「通道」的所有输出激活的集合。令 E 为这些通道的子集,模块间杂交过程如图 4 所示。举两个潜在变量 z1 和 z2 的独立例子,它们将生成两个原始输出示例(y1,y2)=(gM(z1),gM(z2))(称之为 Original1 和 Original2)。同时生成 Original2 时定义 v(z2) 收集由 E 索引的全部变量的值,以及 tilde{v}(z1)表示在生成 Original 1 时由该层上所有其他内生变量获取的值的元组。假设选择模块化的结构tilde{v}(z1)和 v(z2)将对其相应生成图像的不同方面进行编码,以便可以通过将层的输出值集合与特定元组分配来生成混合这些特征的混合示例,并将其发送至生成网络的下游部分。
图 4. 影响图的生成
衡量因果效应
其中 Y(z1) 是潜在输入 z1 生成的无干扰输出。绝对值内的差异可以解释为潜在结果框架中的单元级因果效应 (unit-level causal effect),以及,求取这种期望近似于计算平均治疗效果(average treatment effect)。上式的输出 IM 与输出图像的尺寸相同时,通过颜色通道对其求取平均,从而得到一个灰度热图像素图。
模块和反事实图像的无监督检测
图 5 给出了一个在 CelebA 数据库上训练得到的 VAE 卷积层通道的表示 EIMs 示例,以及,图中通道实现了功能性的分级,例如一些影响更精细的面部特征(眼睛、嘴,…)和其他影响图像的背景或头发等等。这就说明,单个通道可以聚合形成模块,而这些模块对应于输出(人脸图像)的一个特定特征。
图 5. 生成影响图。VAE 在 CelebA 数据库上生成的影响图示例(颜色较浅的像素代表较大的方差,以及扰动对该像素的影响更大)
为了在无监督的情况下实现这种分组,使用 EIM 作为特征向量对通过进行聚类:首先对每个影响图进行预处理,方法是:(1)使用一个小的矩形滑动窗口进行算术平均,以在空间上平滑贴图;(2)在图像上的值分布的 75% 的百分位处对生成的贴图进行阈值化处理,以获得二值图像。在对图像进行降维后,得到一个(通道×像素)矩阵,然后用人工选择的秩 K 将其输入到一个非负矩阵分解(Non-negative Matrix Factorization,NMF)算法中,得到 S=WH。从得到的两个因子矩阵中,得到 K 聚类模板模式(通过根据图像维度重塑 H 的每一行得到),以及每一个模式对单个映射(在 W 中编码)贡献的权重表示。每个影响图都是一个基于模板模式的最大权重聚类。
实验分析
图 6. BigGAN 跨类杂交的示例。左:鸵鸟公鸡,右:考拉泰迪
论文地址:https://www.ijcai.org/Proceedings/2019/570
平衡因果表示学习
治疗效果 (treatment effect),又称因果效应 (causal effect),是指一个变量(即治疗)对另一个变量(即结果)的影响。如果对治疗进行干预,假设协变量不变(即这些协变量的条件),治疗效果被定义为结果的变化,其中协变量是与治疗和结果相关的变量或特征。在文本分析领域,大多数模型关注的是数值协变量,而如何处理具有文本信息的协变量来估计模型效果仍是一个悬而未决的问题。然而,在现实世界中,文本数据几乎无处不在,如临床治疗记录、电影评论、新闻、社交媒体帖子等。针对这一问题,这篇文章提出了一种基于条件治疗的对抗性学习匹配(conditional treatment-adversarial learning based matching,CTAM)方法。CTAM 融合了治疗对抗性学习,在学习表征时过滤掉与工具变量相关的信息,然后在学习表征之间进行匹配,以估计处理效果。
令 Z 和 Z’分别表示观察到的文本协变量 T 和非文本协变量 X 的潜在表示。在潜在表示中,Z’更接近工具变量,因此比结果 Y 更能预测治疗分配。任务目标是学习潜在的表征,过滤掉与仪器变量相关的信息。CTAM 的因果图表示为:
图 7. CTAM 因果图
CTAM 引入条件治疗对抗学习,以尽可能地消除潜在表征中与 Z’相关的信息。CTAM 框架的结构为:
图 8. CTAM 框架
CTAM 包含三个主要部分:文本处理、表示学习和条件处理鉴别器。通过文本处理组件,将原始文本转化为矢量化的表示 S,将 S 与非文本协变量 X 连接起来,构造一个统一的特征向量 C,然后将其输入到表示神经网络中,得到潜在表示 Z。在学习了表示之后,Z 和潜在结果 Y 一起被输入到条件治疗鉴别器中。在训练过程中,表示学习与条件治疗鉴别器进行极大极小博弈:通过阻止鉴别器进行正确的治疗,使表征学习过滤掉与结构变量相关的信息。
文本处理
文本处理过程将文本数据 T 转换为向量表示 S。这篇文章采用了 GloVe 单词嵌入方法 [6],S 是一个文档中所有单词嵌入的平均值。
表示学习
条件处理鉴别器
条件处理鉴别器的输入是潜在表示 Z 和潜在结果 Y,输出是处理分配 W。判别条件只依赖于潜在表示 (latent representation) 的结果,这使得潜在表示只通过潜在的结果分布与治疗相关。也就是说,通过使用条件处理鉴别器,利用极大极小博弈,学习的潜在表示能够通过处理分配消除掉条件依赖。
条件处理鉴别器也是一种前馈神经网络 D,其目标是正确地预测治疗分配。条件处理鉴别器的损失用交叉熵来衡量:
由于此处的潜在结果仅适用于条件治疗鉴别器,而不是显示结果,因此将其命名为伪潜在结果。
条件治疗对抗性学习的目的是去除掉与近似工具变量有关的信息。近似工具变量指的是对治疗分配更具预测性的变量而不是结果,这种过滤策略相当于去除潜在表示和治疗分配之间的条件依赖。因此,通过训练一种对抗性学习模式来达到这一目标。鉴别器 D 执行极小极大博弈。鉴别器 D 一方面通过最小化上式给出正确的治疗;另一方面,向表示学习重新发送结果预测值进行训练,使上述损失最大化,过滤掉有利于鉴别器 D 的信息。当成功的「愚弄」了条件治疗鉴别器,就能够从潜在表示中消除掉增强治疗分配的信息,即,成功地过滤掉与结构变量相关的信息。
损失函数
CTAM 三层结构的完整损失函数为:
其中 L_D 为上文介绍的条件处理鉴别器的交叉熵损失,L_p 是群距离和伪结果预测损失之和:
L_p 中的第一项测量相同治疗下共享观察结果标签的记录之间的成对距离,第二项测量具有不同观察结果的记录之间的成对距离。最小化两项之间的差异会使得相似的记录彼此靠近,而使得表示空间中的不同记录彼此远离。第三项是伪结果预测损失,最小化它可以更好地预测条件治疗鉴别器的潜在结果。
模型训练
训练过程包括优化鉴别者、表示学习和伪结果预测者之间的极大极小博弈,可以看作:
以及三层更新过程为:
实验分析
表 2.News 新闻数据集中的实验结果
由表 2,CTAM 在 PEHE 和 E_ATE 指标下具有最好的性能,在 E_ATT 指标下性能与最佳基线方法 STM 相比类似。这一结果表明,条件治疗鉴别器能有效地滤除与近似工具变量有关的信息,从而减少治疗效果估计的偏差。
展望
现代机器学习的表示学习主要目标是学习到能够保持相关统计特性的数据表征。然而,这种做法没有考虑到变量的因果性质,也就是说,它不关心它分析或重建的变量的介入性质。本文介绍了 3 篇利用表征学习实现因果学习的目的,其中共同之处是如何在物理世界、有限的数据采集情况下,在表征中实现物理因果关系的特性分离(disentanglement)。这在数据有限,以及实验不能重复 (也就是 counterfactual)中尤其难办。为了解决这问题,第二三篇都采用了生成模型(generative model) 或者类似思想来在潜在空间「虚拟」一个独立的原因,而第一篇则着重利用了注意力机制来模拟大脑从上而下(top-down)的预测过程。总体来说,引入因果关系,将能够把表示学习提升到更高的层次:超越统计依赖结构的表征,向支持干预、规划和推理的模型迈进,实现康拉德·洛伦兹(Konrad Lorenz)的想象空间思维概念(thinking as acting in an imagined space)。这最终要求机器有能力反省自己的行为和设想其他的情况,即需要(幻想)自由意志。自我意志的生物学功能可能与在洛伦兹想象的空间中需要一个代表自己的变量有关,自由意志则可能是一种交流该变量所采取行动的手段,对社会和文化学习至关重要,虽然它是人类智能的核心,但目前,机器学习还无法真正的实现。本篇文章结合最新的研究成果分析了向已有的表示学习方法/模型中引入因果机制的效果,但实际上最困难的问题尚未得到解决,关于这一领域的基础性分析有待更深入的研究。
最后
以上就是犹豫煎蛋最近收集整理的关于反事实推理,特征分离,「因果表示学习」的最新研究都在讲何的全部内容,更多相关反事实推理,特征分离,「因果表示学习」内容请搜索靠谱客的其他文章。








发表评论 取消回复