在本教程中,您将发现Keras和tf.keras之间的区别,包括TensorFlow 2.0中的新增功能。
Keras vs. tf.keras: 在TensorFlow 2.0中有什么区别?
https://www.pyimagesearch.com/2019/10/21/keras-vs-tf-keras-whats-the-difference-in-tensorflow-2-0/

在本教程中,您将发现Keras和tf.keras之间的区别,包括TensorFlow 2.0中的新增功能。
万众期待的TensorFlow 2.0于9月30日正式发布。
虽然肯定是值得庆祝的时刻,但许多深度学习从业人员(例如耶利米)都在挠头:
- 作为Keras用户,TensorFlow 2.0版本对我意味着什么?
- 我是否应该使用keras软件包来训练自己的神经网络?
- 还是应该在TensorFlow 2.0中使用tf.keras子模块?
- 作为Keras用户,我应该关注TensorFlow 2.0功能吗?
从TensorFlow 1.x到TensorFlow 2.0的过渡至少有些艰难,至少要开始,但是有了正确的了解,您将能够轻松地进行迁移导航。
在本教程的其余部分中,我将讨论Keras,tf.keras和TensorFlow 2.0版本之间的相似之处,包括您应注意的功能。
在本教程的第一部分中,我们将讨论Keras和TensorFlow之间相互交织的历史,包括他们共同的受欢迎程度如何相互滋养,彼此成长和滋养,从而使我们走向今天。
然后,我将讨论为什么您应该在以后的所有深度学习项目和实验中都使用tf.keras。
接下来,我将讨论“计算backend”的概念,以及TensorFlow的流行度如何使其成为Keras最流行的backend,为Keras集成到TensorFlow的tf.keras子模块中铺平道路。
最后,我们将讨论您作为Keras用户应关注的一些最受欢迎的TensorFlow 2.0功能,包括:
- Sessions and eager execution
- Automatic differentiation
- Model and layer subclassing
- Better multi-GPU/distributed training support
TensorFlow 2.0中包含一个完整的生态系统,其中包括TensorFlow Lite(用于移动和嵌入式设备)和TensorFlow Extended,用于开发生产机器学习管道(用于部署生产模型)。
让我们开始吧!
Keras和TensorFlow之间的纠缠关系
[1]: Keras和TensorFlow之间有着复杂的历史。 在TensorFlow 2.0中,您应该使用tf.keras而不是单独的Keras软件包。
理解Keras和TensorFlow之间复杂,纠缠的关系就像聆听两位高中情侣的爱情故事,他们开始约会,分手并最终找到了自己的路,这很长,很详尽,有时甚至矛盾。
我们不会为您回忆完整的爱情故事,而是会回顾CliffsNotes:
- Keras最初是由Google AI开发人员/研究人员Francois Chollet创建和开发的。
- Francois于2015年3月27日承诺将Keras的第一个版本发布到他的GitHub。
- 最初,Francois开发了Keras,以促进他自己的研究和实验。
- 但是,随着深度学习的普及,许多开发人员,程序员和机器学习从业人员都因其易于使用的API而蜂拥而至Keras。
- 那时,可用的深度学习库还不多,热门的库包括Torch,Theano和Caffe。
- 这些库的问题在于,这就像试图编写程序集/ C ++来执行您的实验一样——繁琐,耗时且效率低下。
- 另一方面,Keras非常易于使用,这使得研究人员和开发人员可以更快地迭代他们的实验。
- 为了训练您自己的自定义神经网络,Keras需要一个backend。
- backend是一个计算引擎——它构建网络图/拓扑,运行优化器并执行实际的数字运算。
- **要了解backend的概念,请考虑从头开始构建网站。**在这里,您可以使用PHP编程语言和SQL数据库。您的SQL数据库是您的backend。您可以使用MySQL,PostgreSQL或SQL Server作为数据库。但是,用于与数据库进行交互的PHP代码不会更改(当然,前提是您使用的是某种抽象数据库层的MVC范例)。本质上,PHP并不关心正在使用哪个数据库,只要它符合PHP的规则即可。
- **Keras也是如此。**您可以将backend视为数据库,将Keras视为用于访问数据库的编程语言。您可以交换自己喜欢的任何backend,只要它遵守某些规则,您的代码就不必更改。
- 因此,您可以将Keras视为一组抽象的概念,这使得执行深度学习更加容易(请注意:尽管Keras始终启用快速原型制作,但对研究人员来说不够灵活。TensorFlow2.0对此进行了更改——在稍后的内容中将对此进行详细介绍)。
- 最初,Keras的默认backend是Theano,直到v1.1.0为止都是默认的。
- 同时,Google发布了TensorFlow,这是一个用于机器学习和训练神经网络的符号数学库。
- Keras开始支持TensorFlow作为backend,缓慢但可以肯定的是,TensorFlow成为最受欢迎的backend,因此从Keras v1.1.0版本开始,TensorFlow成为默认的backend。
- 根据定义,一旦TensorFlow成为Keras的默认backend,TensorFlow和Keras的使用量就会一起增长——如果没有TensorFlow,就无法拥有Keras,并且如果在系统上安装了Keras,那么您还将安装TensorFlow。
- 同样,TensorFlow用户越来越被高级Keras API的简单性吸引。
- TensorFlow v1.10.0中引入了tf.keras子模块,这是将Keras直接集成在TensorFlow包本身中的第一步。
- tf.keras软件包与您将要通过pip安装的keras软件包分开(即pip install keras)。
- 原始的keras软件包不包含在tensorflow中以确保兼容性,因此它们都可以有机地发展。
- 但是,现在情况正在发生变化——当Google在2019年6月发布TensorFlow 2.0时,他们宣布Keras现在是TensorFlow的官方高级API,可以快速,轻松地进行模型设计和训练。
- 随着Keras 2.3.0的发布,Francois声明:
- 这是Keras的第一个版本,使keras软件包与tf.keras同步
- 这是Keras的最终版本,它将支持多个backend(例如Theano,CNTK等)。
- 最重要的是,所有深度学习从业人员都应将其代码切换到TensorFlow 2.0和tf.keras软件包。
- 原始的keras软件包仍将收到错误修复,但是继续前进,您应该使用tf.keras。
如您所知,Keras和TensorFlow之间的历史悠久,复杂且交织在一起。
但是,作为Keras用户,对您来说最重要的收获是,您应该在将来的项目中使用TensorFlow 2.0和tf.keras。
在以后的所有项目中开始使用tf.keras

[2]: TensorFlow 2.0中的Keras和tf.keras有什么区别?
在2019年9月17日,Keras v2.3.0正式发布-在发行版Francois Chollet(Keras的创建者和首席维护者)中指出:
Keras v2.3.0是使keras与tf.keras同步的第一个版本,
这将是最后一个支持TensorFlow以外的backend(即Theano,CNTK等)的主要版本。
最重要的是,深度学习从业人员应该开始转向TensorFlow 2.0和tf.keras软件包
对于大多数项目,这就像从以下位置更改导入行一样简单:
from keras... import ...
要使用tensorflow导入:
from tensorflow.keras... import ...
如果您使用自定义训练循环或会话(Session),则必须更新代码才能使用新的GradientTape功能,但是总的来说,更新代码相当容易。
为了帮助您(自动)将代码从keras更新为tf.keras,Google发布了一个名为tf_upgrade_v2脚本,该脚本顾名思义可以分析您的代码并报告需要更新的行——该脚本甚至可以执行为您进行升级的过程。
您可以参考此处以了解有关自动将代码更新为TensorFlow 2.0的更多信息
https://www.tensorflow.org/guide/upgrade
Keras的计算“backend”

[3]: Keras支持哪些计算backend? 通过tf.keras在TensorFlow中直接使用Keras是什么意思?
正如我在本文前面提到的那样,Keras依赖于计算backend的概念。
计算backend在构建模型图,数值计算等方面执行所有“繁重的工作”。
然后Keras作为abstraction坐在此计算引擎的顶部,使深度学习开发人员/从业人员更容易实现和训练他们的模型。
最初,Keras支持Theano作为其首选的计算backend——后来又支持其他backend,包括CNTK和mxnet等。
但是,到目前为止,最受欢迎的backend是TensorFlow,最终成为Keras的默认计算backend。
随着越来越多的TensorFlow用户开始使用Keras的易于使用的高级API,越来越多的TensorFlow开发人员不得不认真考虑将Keras项目纳入TensorFlow中名为tf.keras的单独模块中。
TensorFlow v1.10是TensorFlow的第一个版本,在tf.keras中包含了一个keras分支。
现在已经发布了TensorFlow 2.0,keras和tf.keras都是同步的,这意味着keras和tf.keras仍然是单独的项目; 但是,开发人员应该开始使用tf.keras,因为keras软件包仅支持错误修复。
引用Keras的创建者和维护者Francois Chollet:
这也是多后端Keras的最后一个主要版本。 展望未来,我们建议用户考虑在TensorFlow 2.0中将其Keras代码切换为tf.keras。
它实现了相同的Keras 2.3.0
API(因此切换应该像更改Keras导入语句一样容易),但是它对TensorFlow用户具有许多优势,例如支持eager
execution, distribution, TPU training, and generally far better
integration 在低层TensorFlow和高层概念(如“层”和“模型”)之间。它也得到更好的维护。
如果您同时是Keras和TensorFlow用户,则应考虑将代码切换到TensorFlow 2.0和tf.keras。
TensorFlow 2.0中Sessions and Eager Execution

[4]: Eager execution是一种处理动态计算图的Python方式。 TensorFlow 2.0支持Eager execution(PyTorch也是如此)。 您可以利用TensorFlow 2.0和tf.keras的Eager execution和Sessions
使用tf.keras中的Keras API的TensorFlow 1.10+用户将熟悉创建会话以训练其模型:
with tf.Session() as session:
session.run(tf.global_variables_initializer())
session.run(tf.tables_initializer())
model.fit(X_train, y_train, validation_data=(X_valid, y_valid),
epochs=10, batch_size=64)
创建Session对象并要求提前构建整个模型图有点麻烦,因此TensorFlow 2.0引入了Eager Execution的概念,从而将代码简化为:
model.fit(X_train, y_train, validation_data=(X_valid, y_valid),
epochs=10, batch_size=64)
Eager Execution 的好处是不必构建整个模型图。
取而代之的是,将立即评估操作,从而更轻松地开始构建模型(以及调试模型)。
有关Eager Execution的更多详细信息,包括如何与TensorFlow 2.0一起使用,请参阅本文。
https://medium.com/coding-blocks/eager-execution-in-tensorflow-a-more-pythonic-way-of-building-models-e461810618c8
而且,如果您想比较“Eager Execution”与“Sessions”及其对训练模型速度的影响,请参阅此页面。
https://github.com/sayakpaul/TF-2.0-Hacks/tree/master/Speed%20comparison%20between%20TF%201.x%20and%20TF%202.0
使用TensorFlow 2.0的Automatic differentiation(自动微分)和GradientTape(梯度带)

[5]: TensorFlow 2.0如何更好地处理自定义网络层或损失函数? 答案在于自动微分和梯度带
如果您是需要实施自定义网络层或损失函数的研究人员,那么您可能不喜欢TensorFlow 1.x(理应如此)。
至少可以说,TensorFlow 1.x的自定义实现很笨拙——还有很多不足之处。
随着TensorFlow 2.0版本的开始变化——现在实现您自己的自定义损失要容易得多。
变得更容易的一种方法是通过自动微分和GradientTape实施。
要利用GradientTape,我们要做的就是实现我们的模型架构:
# Define our model architecture
model = tf.keras.Sequential([
tf.keras.layers.Dropout(rate=0.2, input_shape=X.shape[1:]),
tf.keras.layers.Dense(units=64, activation='relu'),
tf.keras.layers.Dropout(rate=0.2),
tf.keras.layers.Dense(units=1, activation='sigmoid')
])
定义我们的损失函数和优化器:
# Define loss and optimizer
loss_func = tf.keras.losses.BinaryCrossentropy()
optimizer = tf.keras.optimizers.Adam()
创建负责执行单个批处理更新的函数:
def train_loop(features, labels):
# Define the GradientTape context
with tf.GradientTape() as tape:
# Get the probabilities
predictions = model(features)
# Calculate the loss
loss = loss_func(labels, predictions)
# Get the gradients
gradients = tape.gradient(loss, model.trainable_variables)
# Update the weights
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
return loss
然后开始训练模型:
# Train the model
def train_model():
start = time.time()
for epoch in range(10):
for step, (x, y) in enumerate(dataset):
loss = train_loop(x, y)
print('Epoch %d: last batch loss = %.4f' % (epoch, float(loss)))
print("It took {} seconds".format(time.time() - start))
# Initiate training
train_model()
GradientTape为我们在后台处理差异化处理,使处理自定义损失和网络层变得容易得多。
说到自定义层和模型实现,一定要参考下一节。
TensorFlow 2.0中的模型和网络层子类化(Model and layer subclassing )
TensorFlow 2.0和tf.keras为我们提供了三种单独的方法来实现我们自己的自定义模型:
- Sequential
- Function
- Subclassing
Sequential和Function范式都已经在Keras中存在很长时间了,但是对于许多深度学习从业者来说,Subclassing功能仍然是未知的。
我将在下周针对这三种方法进行专门的教程,但是暂时,让我们看一下如何使用(1)TensorFlow 2.0,(2)tf基于开创性的LeNet架构实现简单的CNN。 keras,以及(3)模型subclassing 功能:
class LeNet(tf.keras.Model):
def __init__(self):
super(LeNet, self).__init__()
self.conv2d_1 = tf.keras.layers.Conv2D(filters=6,
kernel_size=(3, 3), activation='relu',
input_shape=(32,32,1))
self.average_pool = tf.keras.layers.AveragePooling2D()
self.conv2d_2 = tf.keras.layers.Conv2D(filters=16,
kernel_size=(3, 3), activation='relu')
self.flatten = tf.keras.layers.Flatten()
self.fc_1 = tf.keras.layers.Dense(120, activation='relu')
self.fc_2 = tf.keras.layers.Dense(84, activation='relu')
self.out = tf.keras.layers.Dense(10, activation='softmax')
def call(self, input):
x = self.conv2d_1(input)
x = self.average_pool(x)
x = self.conv2d_2(x)
x = self.average_pool(x)
x = self.flatten(x)
x = self.fc_2(self.fc_1(x))
return self.out(x)
lenet = LeNet()
注意LeNet类是Model的子类(subclass )。
LeNet的构造函数(即init)定义了模型内部的每个单独层。
然后,call方法将执行前向传递,使您可以根据需要自定义前向传递。
使用模型子类化(model subclassing )的好处是您的模型:
- 变得完全可定制(fully-customizable)。
- 使您能够实施和利用自己的自定义损失实现。
而且,由于您的体系结构继承了Model类,因此您仍然可以调用.fit()、. compile()和.evaluate()之类的方法,从而维护易于使用(且熟悉)的Keras API。
如果您想了解有关LeNet的更多信息,可以参考下面这篇文章。
https://www.pyimagesearch.com/2016/08/01/lenet-convolutional-neural-network-in-python/
TensorFlow 2.0引入了更好的多GPU和分布式训练支持
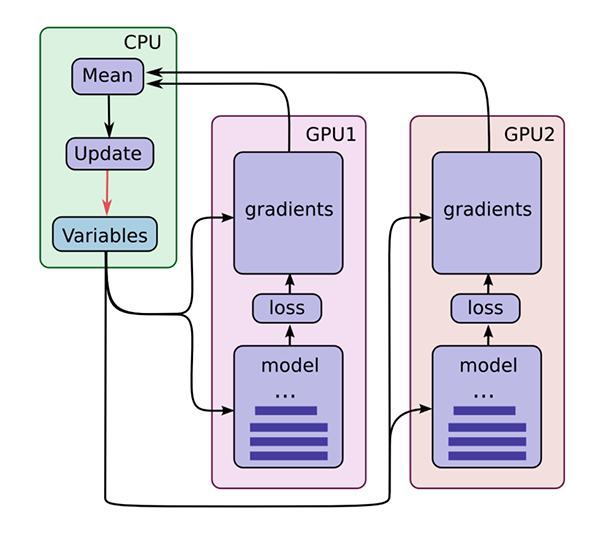
[6]: TensorFlow 2.0是否经过多个GPU训练更好? 是的
TensorFlow 2.0和tf.keras通过其MirroredStrategy提供更好的多GPU和分布式训练。
https://www.tensorflow.org/guide/distributed_training#mirroredstrategy
引用TensorFlow 2.0文档:“ MirroredStrategy支持在一台机器上的多个GPU上的同步分布式训练”。
如果要使用多台计算机(每台计算机可能具有多个GPU),则应查看MultiWorkerMirroredStrategy。
https://www.tensorflow.org/guide/distributed_training#multiworkermirroredstrategy
或者,如果您使用Google的云服务器进行训练,请查看TPUStrategy。
https://www.tensorflow.org/guide/distributed_training#tpustrategy
不过,现在,假设您位于一台具有多个GPU的机器上,并且想要确保所有GPU都用于训练。
您可以先创建MirroredStrategy来完成此操作:
strategy = tf.distribute.MirroredStrategy()
print ('Number of devices: {}'.format(strategy.num_replicas_in_sync))
然后,您需要声明您的模型架构,并在 strategy 范围内对其进行编译:
# Call the distribution scope context manager
with strategy.scope():
# Define a model to fit the above data
model = tf.keras.Sequential([
tf.keras.layers.Dropout(rate=0.2, input_shape=X.shape[1:]),
tf.keras.layers.Dense(units=64, activation='relu'),
tf.keras.layers.Dropout(rate=0.2),
tf.keras.layers.Dense(units=1, activation='sigmoid')
])
# Compile the model
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
从那里,您可以调用.fit训练模型:
# Train the model
model.fit(X, y, epochs=5)
如果您的机器具有多个GPU,TensorFlow将为您处理多GPU训练。
TensorFlow 2.0是一个生态系统,包括TF 2.0,TF Lite,TFX,量化(quantization)和部署(deployment)
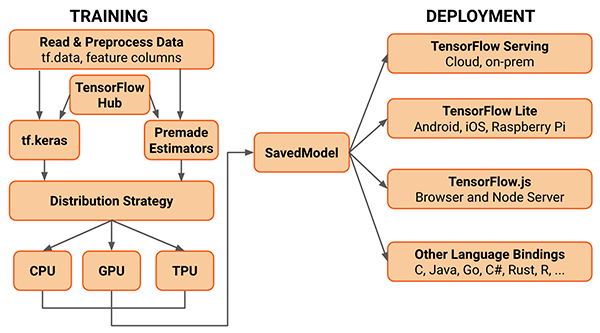
[7]: TensorFlow 2.0生态系统中有哪些新功能? 我应该单独使用Keras还是应该使用tf.keras?
TensorFlow 2.0不仅仅是一个计算引擎和一个用于训练神经网络的深度学习库,它还具有更多功能。
借助TensorFlow Lite(TF Lite),我们可以训练,优化和量化旨在在资源受限的设备上运行的模型,例如智能手机和其他嵌入式设备(例如Raspberry Pi,Google Coral等)。
https://www.tensorflow.org/lite/
或者,如果您需要将模型部署到生产环境,则可以使用TensorFlow Extended(TFX),这是用于模型部署的端到端平台。
研究和实验完成后,您可以利用TFX为生产准备模型,并使用Google的生态系统扩展模型。
借助TensorFlow 2.0,我们真正开始看到在研究,实验,模型准备/量化和部署到生产之间更好,更高效的桥梁。
我对TensorFlow 2.0的发布及其对深度学习社区的影响感到非常兴奋。
Credits
本文中的所有代码示例均来自TensorFlow 2.0的官方示例。 有关更多详细信息,请确保参考Francois Chollet提供的完整代码示例。
https://www.tensorflow.org/tutorials
https://colab.research.google.com/drive/17u-pRZJnKN0gO5XZmq8n5A2bKGrfKEUg
此外,一定要查阅Sayak Paul的TensorFlow 2.0的十个重要更新,这有助于启发今天的博客文章。
https://www.datacamp.com/community/tutorials/ten-important-updates-tensorflow
总结
在本教程中,您了解了Keras,tf.keras和TensorFlow 2.0。
首先重要的一点是,使用keras软件包的深度学习从业人员应该开始在TensorFlow 2.0中使用tf.keras。
您不仅会享受TensorFlow 2.0的更快的速度和优化,而且还将获得新的功能更新-keras软件包的最新版本(v2.3.0)将成为支持多个后端和功能更新的最新版本。展望未来,keras软件包将仅收到错误修复。
您应该在未来的项目中认真考虑迁移到tf.keras和TensorFlow 2.0。
第二个要点是TensorFlow 2.0不仅仅是GPU加速的深度学习库。
您不仅可以使用TensorFlow 2.0和tf.keras训练自己的模型,而且现在可以:
- 采取这些模型,并使用TensorFlow Lite(TF Lite)为移动/嵌入式部署做好准备。
- 使用TensorFlow Extended(TF Extended)将模型部署到生产中。
从我的角度来看,我已经开始将原始的keras代码移植到tf.keras。我建议您开始做同样的事情。
希望您喜欢今天的教程-我很快就会回来使用新的TensorFlow 2.0和tf.keras教程。
翻译原文:https://www.pyimagesearch.com/2019/10/21/keras-vs-tf-keras-whats-the-difference-in-tensorflow-2-0/
最后
以上就是小巧小蚂蚁最近收集整理的关于Keras vs. tf.keras: 在TensorFlow 2.0中有什么区别?的全部内容,更多相关Keras内容请搜索靠谱客的其他文章。








发表评论 取消回复