文章目录
- 开始之前
- 一、背景
- 1.1 项目速览
- 1.2 模型结构
- 1.3 参考内容
- 二、部署
- 2.1 初始化运行环境
- 2.2 初始化调用函数
- 2.3 Text To Image
- 2.3.1 参数配置
- 2.3.2 载入模型
- 2.3.3 图像生成、保存和展示
- 2.4 Text With Image To Image
- 1.4.1 参数配置
- 2.4.2 导入图片
- 2.4.2 模型载入
- 2.4.4 图像生成、保存和展示
- 2.3 开发代码
- 三、尾巴
开始之前
1. 如果你熟练的掌握了编程并且热爱机器学习,那么我建议你阅读全文,并亲自部署模型
2. 如果你是一个小白,仅仅想要感受效果,那么我建议你访问DreamStudio在线试用网站
3. 如果你想要深度体验并且是Google用户,那么我建议你访问我的云端硬盘Colab中关于Stabled Diffusion的demo
4. 欢迎大家交流
一、背景
扩散模型在计算机视觉领域成果斐然,能够高效的合成数据,图像生成中甚至击败了 GAN,在其他领域也展现出潜力,例如视频生成、音频合成和强化学习等
1.1 项目速览
Stabled Diffusion 项目的内核是在论文 High-Resolution Image Synthesis with Latent Diffusion Models 中提出的模型 IDM,项目开源许可证是 CreativeML Open RAIL M License
-
扩散模式

-
文字到图像

-
文字加图像到图像

-
Data Pipeline
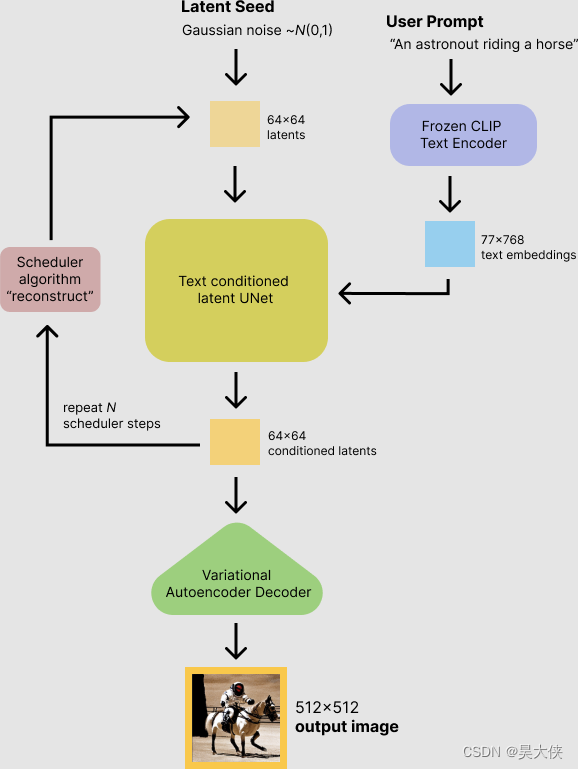
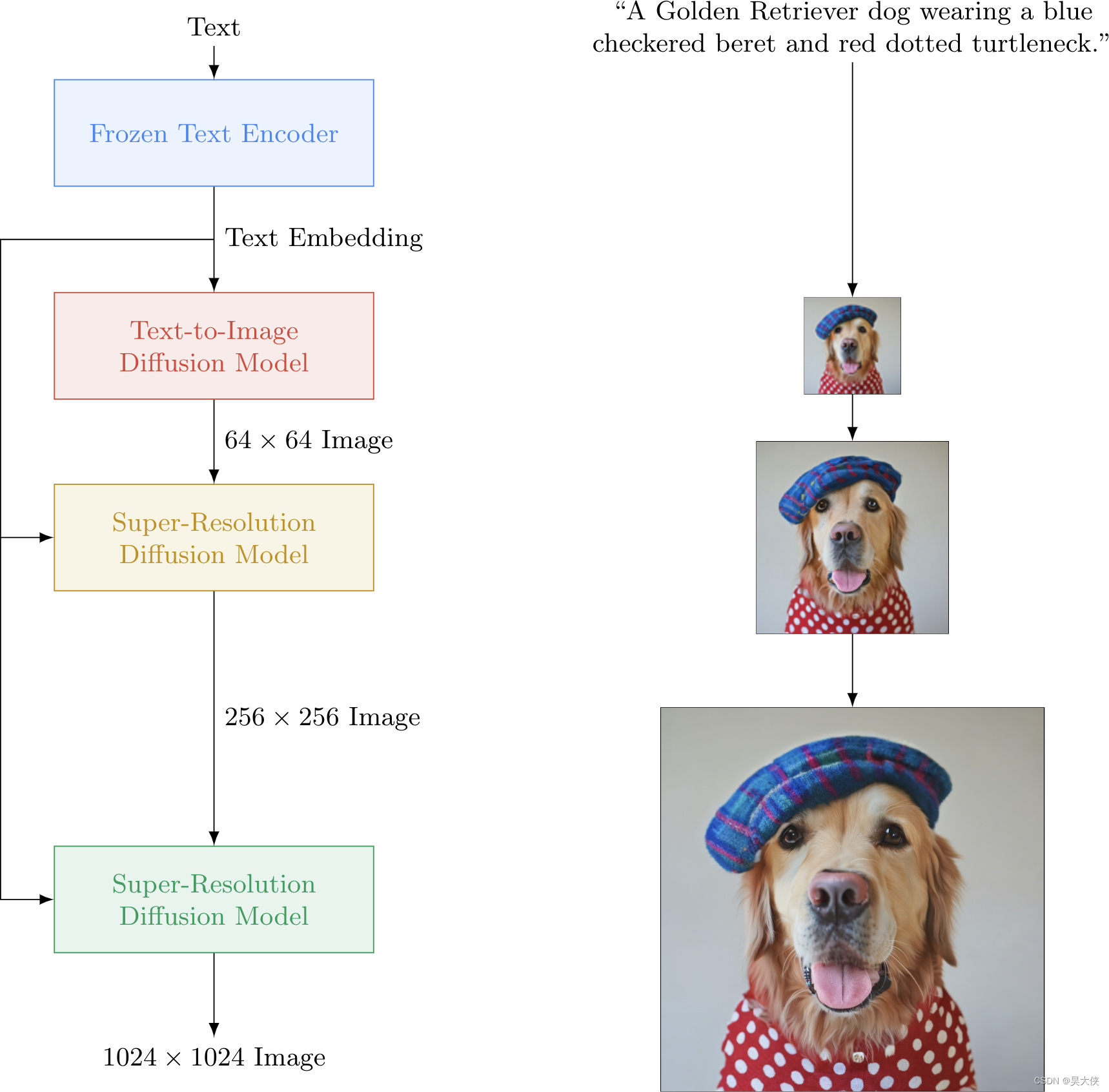
... Stabled Deiffusion 的 IDM 相似的模型 ImageGen ... - 稳定扩散模型将潜在种子和文本提示作为输入。然后使用潜在种子生成大小的随机潜在图像表示 64 × 64 64×64 64×64 当文本提示转换为大小的文本嵌入时 77 × 768 77×768 77×768 通过 CLIP 的文本编码器
- 接下来,UNet 在以文本嵌入为条件的同时迭代地对随机潜在图像表示进行去噪。UNet 的输出,即噪声残差,用于通过调度器算法计算去噪的潜在图像表示,去噪过程大约重复,50 次逐步检索更好的潜在图像表示
- 一旦去噪完成,潜在图像表示将由变分自动编码器的解码器部分解码
1.2 模型结构
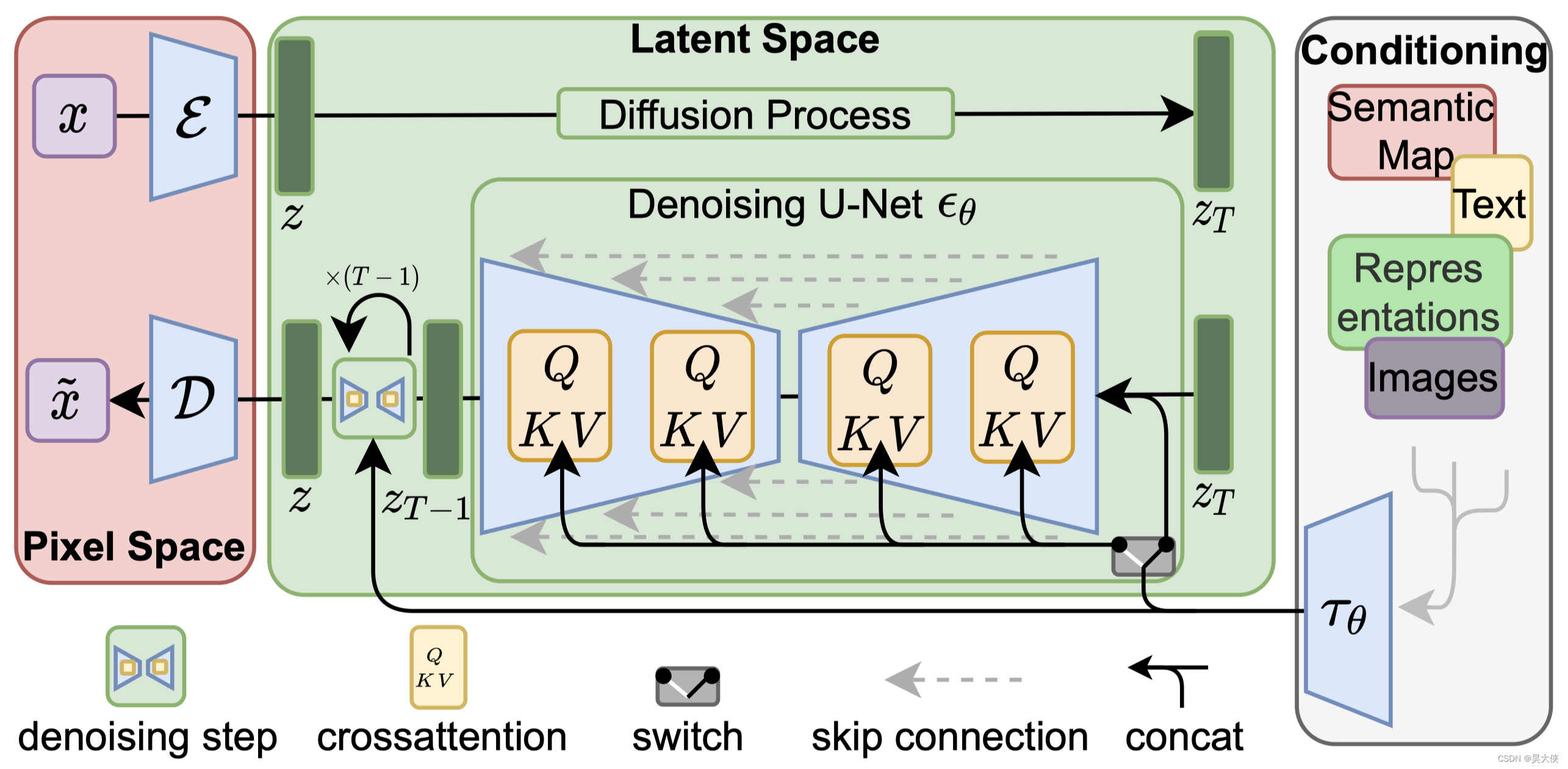
-
文本编码器 CLIP,将文本转换为 U-Net 可以理解的隐空间 -
调度器,用于在训练期间逐步向图像添加噪声 -
运算核心 UNet,由 ResNet 块组成,生成输入潜在表示,预测去噪图像的噪声残差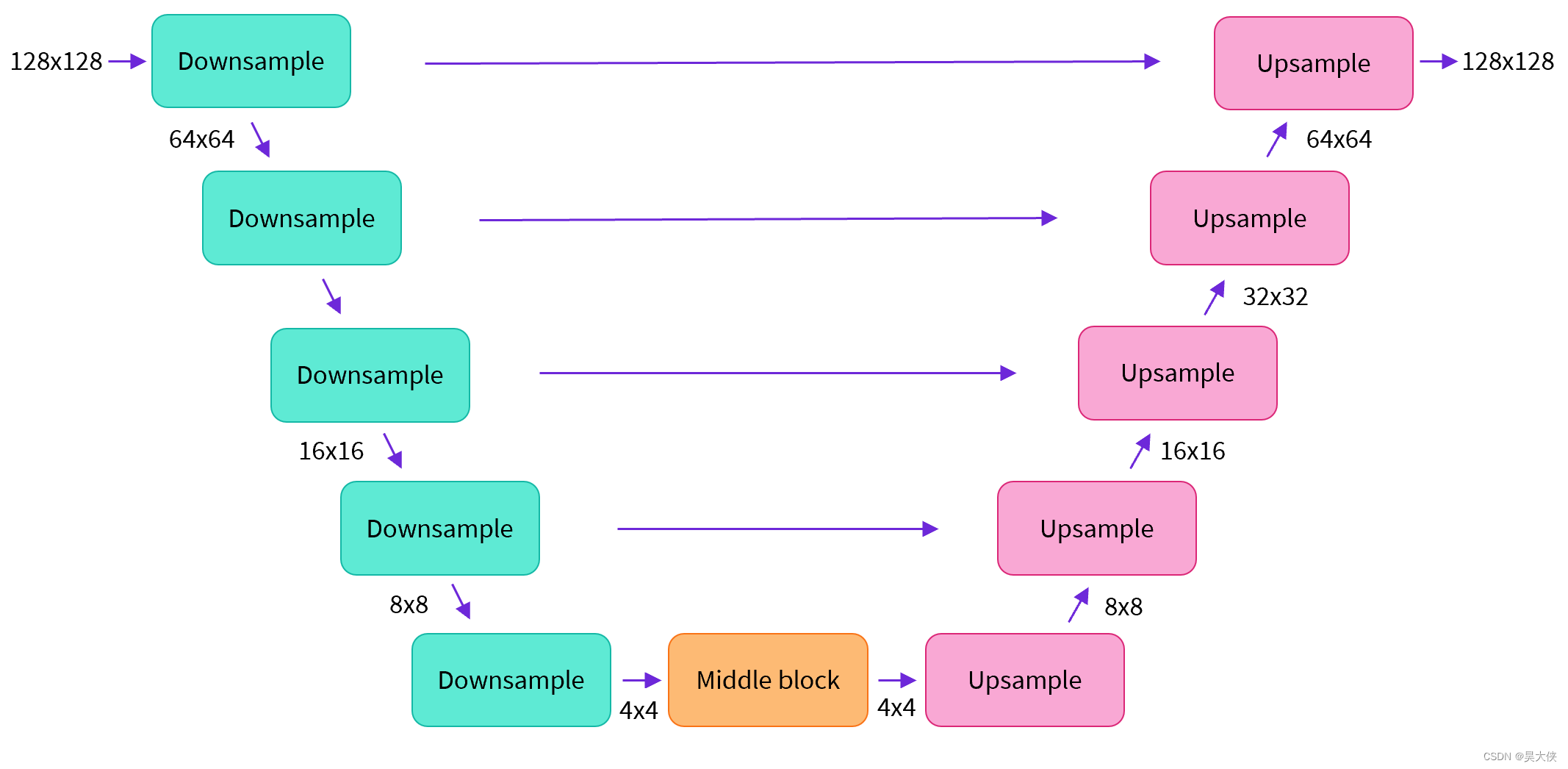
-
变分自编码器 VAE,将潜在表示解码为真实图像,训练期间编码器用于获取图像的潜在表示,推理过程使用解码器转换回图像
1.3 参考内容
- Stability Ai官网 - Github源码托管 - Hugging Face模型托管
- DreamStudio Discord论坛 - DreamStudio在线试用网站
- Stable Diffusion images and prompts仓库
- Stable Diffusion技术细节
- Open Ai官网 - DALL·E2 Prompt参考
二、部署
首先需要安装一个包管理环境 pip、conda 甚至 docker 都行再创建一个 Python 环境,在此基础上还需要安装一些核心库包括 pytorch、diffusers 和 transformers 等
brew install miniconda
conda env create -f environment.yaml
conda activate ldm
conda install pytorch torchvision -c pytorch
pip install transformers==4.19.2 diffusers invisible-watermark
pip install -e .
2.1 初始化运行环境
import os
import sys
import re
import inspect
from tqdm.auto import tqdm
from typing import List, Optional, Union
import torch
from torch import autocast
from diffusers import StableDiffusionPipeline
from diffusers import (
AutoencoderKL,
DiffusionPipeline,
UNet2DConditionModel,
DDIMScheduler,
DDPMScheduler,
PNDMScheduler,
LMSDiscreteScheduler,
EulerDiscreteScheduler,
)
from diffusers.pipelines.stable_diffusion import StableDiffusionSafetyChecker
from transformers import CLIPFeatureExtractor, CLIPTextModel, CLIPTokenizer
from PIL import Image
import numpy as np
import requests
from io import BytesIO
import matplotlib.pyplot as plot
2.2 初始化调用函数
# 图像网格化
def image_grid(inputs, x=1, y=1):
image_list = inputs
assert len(image_list) == x*y
width, height = image_list[0].size
grid = Image.new("RGB", size=(x*width, y*height))
k = 1
for idx in range(x*y):
if x <= y:
if idx == k*y:
k += 1
grid.paste(image_list[idx], box=((idx-(k-1)*x)%y*width, idx//x*height))
if x > y:
grid.paste(image_list[idx], box=(idx%x*width, idx//x*height))
outputs = grid
return outputs
# 展示图像
def show_image(image_list, prompt=0, scale=5, dpi=300, colormap=None):
sizes = np.ceil(np.sqrt(np.array(len(image_list))))
plot.figure(num=prompt, figsize=(sizes*scale, sizes*scale), dpi=dpi)
for idx, image in enumerate(image_list):
plot.subplot(int(sizes), int(sizes), idx+1)
plot.imshow(image, cmap=colormap)
plot.axis("off")
plot.show()
# 存储图像
def save_image(image_list, save_path, prompt):
regex = r"^[^/\:*?"'<>|]{1,255}"
prompt = re.search(regex, prompt).group()
if not os.path.exists(os.path.join(save_path, prompt)):
os.makedirs(os.path.join(save_path, prompt))
for image in image_list:
fn_list = list(map(lambda string: os.path.splitext(string)[0], os.listdir(os.path.join(save_path, prompt))))
k = 0
for idx in range(len(fn_list)):
try:
fn_list[idx] = int(fn_list[idx])
except:
fn_list.remove(fn_list[idx-k])
k += 1
if len(fn_list) == 0:
image.save(os.path.join(save_path, prompt, f"{str(0).zfill(4)}.png"))
else:
name_index = (set(fn_list) ^ set(range(max(fn_list) + 1))).pop() if len(set(fn_list)) != max(
fn_list) + 1 else max(fn_list) + 1
image.save(os.path.join(save_path, prompt, f"{str(name_index).zfill(4)}.png"))
# 文字加图像到图像的数据管道
class StableDiffusionImgToImgPipeline(DiffusionPipeline):
def __init__(self, vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: Union[DDIMScheduler,
DDPMScheduler,
PNDMScheduler,
LMSDiscreteScheduler,
EulerDiscreteScheduler,],
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPFeatureExtractor):
super().__init__()
self.register_modules(vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor)
@staticmethod
def preprocess(inputs):
image = inputs
width, height = image.size
width, height = map(lambda x: x - x % 8, (width, height))
try:
image = image.resize((width, height), resample=Image.Resampling.LANCZOS)
except AttributeError:
image = image.resize((width, height))
image = np.array(image).astype(np.float32) / 255.0
image = image[None].transpose(0, 3, 1, 2)
image = torch.from_numpy(image)
outputs = 2. * image - 1.
return outputs
@torch.no_grad()
def __call__(self, prompt: Union[str, List[str]],
image: torch.FloatTensor,
strength: float = 0.75,
num_inference_steps: Optional[int] = 50,
guidance_scale: Optional[float] = 7.5,
eta: Optional[float] = 0.0,
generator: Optional[torch.Generator] = None,
output_type: Optional[str] = "pil"):
if isinstance(prompt, str):
batch_size = 1
elif isinstance(prompt, list):
batch_size = len(prompt)
else:
raise ValueError(f"### "prompt" has to be of type str or list but is {type(prompt)}")
if strength < 0 or strength > 1:
raise ValueError(f"### The value of strength should in (0.0, 1.0) but is {strength}")
# set timesteps
accepts_offset = "offset" in set(inspect.signature(self.scheduler.set_timesteps).parameters.keys())
extra_set_kwargs = {}
offset = 0
if accepts_offset:
offset = 1
extra_set_kwargs["offset"] = 1
self.scheduler.set_timesteps(num_inference_steps, **extra_set_kwargs)
# encode the init image into latents and scale the latents
init_latents = self.vae.encode(self.preprocess(image).to(self.device)).latent_dist.sample()
init_latents = 0.18215 * init_latents
# prepare init_latents noise to latents
init_latents = torch.cat([init_latents] * batch_size)
# get the original timestep using init_timestep
init_timestep = int(num_inference_steps * strength) + offset
init_timestep = min(init_timestep, num_inference_steps)
timesteps = self.scheduler.timesteps[-init_timestep]
timesteps = torch.tensor([timesteps] * batch_size, dtype=torch.long, device=self.device)
# add noise to latents using the timesteps
noise = torch.randn(init_latents.shape, generator=generator, device=self.device)
init_latents = self.scheduler.add_noise(init_latents, noise, timesteps)
# get prompt text embeddings
text_input = self.tokenizer(prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt")
text_embeddings = self.text_encoder(text_input.input_ids.to(self.device))[0]
# here guidance_scale is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance:
max_length = text_input.input_ids.shape[-1]
uncond_input = self.tokenizer([""] * batch_size, padding="max_length", max_length=max_length, return_tensors="pt")
uncond_embeddings = self.text_encoder(uncond_input.input_ids.to(self.device))[0]
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502 and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
latents = init_latents
t_start = max(num_inference_steps - init_timestep + offset, 0)
for i, t in tqdm(enumerate(self.scheduler.timesteps[t_start:])):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
# predict the noise residual
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeddings)["sample"]
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs)["prev_sample"]
# scale and decode the image latents with vae
latents = 1 / 0.18215 * latents
image = self.vae.decode(latents).sample
image = (image / 2 + 0.5).clamp(0, 1)
image = image.cpu().permute(0, 2, 3, 1).numpy()
# run NSFW safety checker
safety_cheker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(self.device)
image, has_nsfw_concept = self.safety_checker(images=image, clip_input=safety_cheker_input.pixel_values)
if output_type == "pil":
image = self.numpy_to_pil(image)
return {"images": image, "nsfw_content_detected": has_nsfw_concept}
2.3 Text To Image

|

|

|
|
|
|
|

|

|

|
|
|
|
|

|

|

|
|
|
|
|
2.3.1 参数配置
"""
文字提示 - 模型将根据文字提示的内容生成相应的图片, 一般可分三个部分
1. 主体内容(熊猫、武士或高山等);
2. 抽象风格样式(抽象形容加具体指代)如流派加艺术家([写实的、Portrait]、[油画、Edgar Degas]、[铅笔画、Rembrandt]);
3. 补充润色(4k, washed colors, sharp, beautiful, post processing, ambient lighting, epic composition)
"""
prompt_dict = {
"0000": "A photo of an astronaut riding a horse on mars",
"0001": "Digital art of portrait of a woman, holding pencil, inspired, head-and-shoulders shot, white background, cute pixar character",
"0002": "Digital art of a man looking upwards, eyes wide inwonder, awestruck, in the style of Pixar, Up, character, white background",
"0003": "The starry sky painting",
"0004": "Donald Trump wears a panda headgear",
"0005": "A painting of a fox sitting in a field at sunrise in the style of Claude Monet",
"0006": "Dreams flowers and maidens",
"0007": "Teddy bears, working on new AI research, on the moon in the 1980s",
"0008": "An astronaut, lounging in a tropical resort in space, as pixel art",
"0009": "The whale was flying in the air, and below was a volcano and a snow-capped mountain",
"0010": "A beautiful painting, Prince Nezha's Triumph fighting Dragon King's son, colourful clouds, The waves rushed into the sky with the fire, amber&yellow lights pours on the sea, sunset",
"0011": "Robot, looking at the clouds hanging in the distance, solemn expression, strange background",
"0012": "An emerald river, the left bank of the river is volcanoes and scorched earth, the right bank of the river is snow-capped mountains and grasslands, the sun is submerged in the clouds, a few rays of white light sprinkled on the water, matte painting trending on artstation HQ",
"0013": "A dream of a distant galaxy, by Caspar David Friedrich, matte painting trending on artstation HQ",
"0014": "Product photography framing. digital paint krita render of a small square fantasy vacuum - tube motherboard made and powered by crystalline circuitry. trending on artstation. artificer's lab bg. premium print by angus mckie and james gurney",
}
prompt = prompt_dict["0014"]
model_id = "CompVis/stable-diffusion-v1-4" # 模型版本 - 一般可设置为 CompVis/stable-diffusion-v1-4 或 runwayml/stable-diffusion-v1-5
device = "cpu" # 硬件类型 - 一般可设置为 cpu 或 cuda, 其中 cuda 即 nvidi gpu 的运算驱动平台
fp_mode = "fp32" # 浮点数运算精度 - fp32 即 float32 单精度浮点数, fp16 即 float16 半精度浮点数, 一般精度越高计算负载越高生成效果越好
sd_mode = "DDIM" # 调度器 - 定义了用于在训练期间向模型添加噪声的噪声计划, 根据先前的噪声表示和预测的噪声残差计算预测的去噪图像表示
sample_num = 1 # 模型推理的次数 - 即循环执行当前模型的次数
batch = 1 # 模型并行推理的批量 - 使用多批次数将同时生成多张图像, 2 意味着一次推理将生成 2 张图像, 内存的需求也会较 1 增加
height = 512 # 生成图像的高度 - 需要是 8 的倍数(低于 512 将降低图像质量, 与宽同时超过 512 将丧失全局连贯性)
width = 512 # 生成图像的宽度 - 需要是 8 的倍数(低于 512 将降低图像质量, 与高同时超过 512 将丧失全局连贯性)
num_inference_steps = 50 # 每次模型推理的步骤数 - 一般步骤越大生成的图像质量越高, 建议值 50
guidance_scale = 7 # 无分类指导因子 - 能让生成图像匹配文字提示, 稳定扩散, 取值范围 0~20, 过高会牺牲图像质量或多样性, 建议值 7~8.5
generator = torch.Generator(device=device).manual_seed(3939590921) # 随机种子 - 使得紧接着的随机数固定, 如果其他条件不改变, 使用具有相同种子的生成器将得到相同的图像输出, 因此当生成了一张好的图像时可以记录随机种子, 然后微调文字提示
save_path = "./results" # 图像保存目录 - 相对地址./path表示在和当前程序同级别的目录path下保存, 也可使用绝对地址
2.3.2 载入模型
if fp_mode == "fp32":
if not os.path.isdir(model_id):
model_id = f"{model_id}"
print(f"从{model_id}加载精度为{fp_mode}的权重,驱动模式为{device}")
scheduler = DDIMScheduler.from_pretrained(model_id, subfolder="scheduler")
pipe = StableDiffusionPipeline.from_pretrained(model_id,
scheduler=scheduler,
torch_dtype=torch.float32,
use_auth_token=True).to(device)
elif fp_mode == "fp16":
if not os.path.isdir(model_id):
model_id = f"{model_id}"
print(f"从{model_id}加载精度为{fp_mode}的权重,驱动模式为{device}")
scheduler = DDIMScheduler.from_pretrained(model_id, subfolder="scheduler")
pipe = StableDiffusionPipeline.from_pretrained(model_id,
revision="fp16",
scheduler=scheduler,
torch_dtype=torch.float16,
use_auth_token=True).to(device)
pipe.enable_attention_slicing()
else:
print("Current fp_mode only support fp32 or fp16")
sys.exit()
2.3.3 图像生成、保存和展示
%%time
image_list = []
for idx in range(sample_num):
print(f"正在生成第{idx+1}批图像,共{batch}张")
with autocast("cuda"):
data = pipe([prompt]*batch,
height=height, width=width,
num_inference_steps=num_inference_steps,
guidance_scale=guidance_scale,
generator=generator)
image = data["images"]
save_image(image, save_path, prompt)
image_list.append(image_grid(image, x=batch, y=batch))
show_image(image_list, prompt)
2.4 Text With Image To Image

|

|

|
|
|
|
|
1.4.1 参数配置
prompt_dict = {
"0001": "a fantasy landscape, trending on artstation",
}
prompt = prompt_dict["0001"]
image_url = "https://www.shuijiaxian.com/files_image/2023110902/11fc2a2b3aa1471b9bced71ee0ddf507.jpeg" # 图像地址 - 网络图像链接或本地图像路径
strength = 0.75 # 调整强度 - 取值范围 (0, 1) 代表文字提示对原图的修改的程度
model_id = "CompVis/stable-diffusion-v1-4"
device = "cpu"
fp_mode = "fp32"
sd_mode = "DDIM"
sample_num = 10
batch = 1
height= 512
width= 512
num_inference_steps = 50
guidance_scale = 7.5
generator = torch.Generator(device=device).manual_seed(51)
save_path = "./results"
2.4.2 导入图片
init_image = []
try:
init_image = Image.open(BytesIO(requests.get(image_url).content)).convert("RGB") # 导入网络图片
except:
init_image = Image.open(image_url).convert("RGB") # 导入本地图片
finally:
if not init_image:
print("图片未被成功导入, 请检查图像地址是否正确")
init_image = init_image.resize((height, width))
show_image([init_image], prompt)
2.4.2 模型载入
if fp_mode == "fp32":
if not os.path.isdir(model_id):
model_id = f"{model_id}"
print(f"从{model_id}加载精度为{fp_mode}的权重,驱动模式为{device}")
scheduler = DDIMScheduler.from_pretrained(model_id, subfolder="scheduler")
pipe = StableDiffusionImgToImgPipeline.from_pretrained(model_id,
scheduler=scheduler,
torch_dtype=torch.float32,
use_auth_token=True).to(device)
elif fp_mode == "fp16":
if not os.path.isdir(model_id):
model_id = f"{model_id}"
print(f"从{model_id}加载精度为{fp_mode}的权重,驱动模式为{device}")
scheduler = DDIMScheduler.from_pretrained(model_id, subfolder="scheduler")
pipe = StableDiffusionImgToImgPipeline.from_pretrained(model_id,
revision="fp16",
scheduler=scheduler,
torch_dtype=torch.float16,
use_auth_token=True).to(device)
pipe.enable_attention_slicing()
else:
print("Current fp_mode only support fp32 or fp16")
sys.exit()
2.4.4 图像生成、保存和展示
%%time
image_list = []
for idx in range(sample_num):
print(f"正在生成第{idx+1}批图像,共{batch}张")
with autocast("cuda"):
data = pipe([prompt]*batch,
image=init_image,
strength=strength,
num_inference_steps=num_inference_steps,
guidance_scale=guidance_scale,
generator=generator))
image = data["images"]
save_image(image, save_path, prompt)
image_list.append(image_grid(image, x=batch, y=batch))
show_image(image_list, prompt)
2.3 开发代码
import os
import re
import inspect
import argparse
from tqdm.auto import tqdm
from typing import List, Optional, Union
import torch
from torch import autocast
from diffusers import StableDiffusionPipeline
from diffusers import (
AutoencoderKL,
DiffusionPipeline,
UNet2DConditionModel,
DDIMScheduler,
DDPMScheduler,
PNDMScheduler,
LMSDiscreteScheduler,
EulerDiscreteScheduler,
)
from diffusers.pipelines.stable_diffusion import StableDiffusionSafetyChecker
from transformers import CLIPFeatureExtractor, CLIPTextModel, CLIPTokenizer
from PIL import Image
import numpy as np
import requests
from io import BytesIO
import matplotlib.pyplot as plot
def optional_str(string):
return None if string == "None" else string
def image_grid(inputs, x=1, y=1):
image_list = inputs
assert len(image_list) == x*y
width, height = image_list[0].size
grid = Image.new("RGB", size=(x*width, y*height))
k = 1
for idx in range(x*y):
if x <= y:
if idx == k*y:
k += 1
grid.paste(image_list[idx], box=((idx-(k-1)*x)%y*width, idx//x*height))
if x > y:
grid.paste(image_list[idx], box=(idx%x*width, idx//x*height))
outputs = grid
return outputs
def show_image(image_list, prompt=0, scale=5, dpi=300, colormap=None):
sizes = np.ceil(np.sqrt(np.array(len(image_list))))
plot.figure(num=prompt, figsize=(sizes*scale, sizes*scale), dpi=dpi)
for idx, image in enumerate(image_list):
plot.subplot(int(sizes), int(sizes), idx+1)
plot.imshow(image, cmap=colormap)
plot.axis("off")
plot.show()
def save_image(image_list, save_path, prompt):
regex = r"^[^/\:*?"'<>|]{1,255}"
prompt = re.search(regex, prompt).group()
if not os.path.exists(os.path.join(save_path, prompt)):
os.makedirs(os.path.join(save_path, prompt))
for image in image_list:
fn_list = list(map(lambda string: os.path.splitext(string)[0], os.listdir(os.path.join(save_path, prompt))))
k = 0
for idx in range(len(fn_list)):
try:
fn_list[idx] = int(fn_list[idx])
except:
fn_list.remove(fn_list[idx-k])
k += 1
if len(fn_list) == 0:
image.save(os.path.join(save_path, prompt, f"{str(0).zfill(4)}.png"))
else:
name_index = (set(fn_list) ^ set(range(max(fn_list) + 1))).pop() if len(set(fn_list)) != max(
fn_list) + 1 else max(fn_list) + 1
image.save(os.path.join(save_path, prompt, f"{str(name_index).zfill(4)}.png"))
# 文字加图像到图像的数据管道
class StableDiffusionImgToImgPipeline(DiffusionPipeline):
def __init__(self, vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: Union[DDIMScheduler,
DDPMScheduler,
PNDMScheduler,
LMSDiscreteScheduler,
EulerDiscreteScheduler,],
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPFeatureExtractor):
super().__init__()
self.register_modules(vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor)
@staticmethod
def preprocess(inputs):
image = inputs
width, height = image.size
width, height = map(lambda x: x - x % 8, (width, height))
image = image.resize((width, height), resample=Image.Resampling.LANCZOS)
image = np.array(image).astype(np.float32) / 255.0
image = image[None].transpose(0, 3, 1, 2)
image = torch.from_numpy(image)
outputs = 2. * image - 1.
return outputs
@torch.no_grad()
def __call__(self, prompt: Union[str, List[str]],
image: torch.FloatTensor,
strength: float = 0.75,
num_inference_steps: Optional[int] = 50,
guidance_scale: Optional[float] = 7.5,
eta: Optional[float] = 0.0,
generator: Optional[torch.Generator] = None,
output_type: Optional[str] = "pil"):
if isinstance(prompt, str):
batch_size = 1
elif isinstance(prompt, list):
batch_size = len(prompt)
else:
raise ValueError(f"### "prompt" has to be of type str or list but is {type(prompt)}")
if strength < 0 or strength > 1:
raise ValueError(f"### The value of strength should in (0.0, 1.0) but is {strength}")
# set timesteps
accepts_offset = "offset" in set(inspect.signature(self.scheduler.set_timesteps).parameters.keys())
extra_set_kwargs = {}
offset = 0
if accepts_offset:
offset = 1
extra_set_kwargs["offset"] = 1
self.scheduler.set_timesteps(num_inference_steps, **extra_set_kwargs)
# encode the init image into latents and scale the latents
init_latents = self.vae.encode(self.preprocess(image).to(self.device)).latent_dist.sample()
init_latents = 0.18215 * init_latents
# prepare init_latents noise to latents
init_latents = torch.cat([init_latents] * batch_size)
# get the original timestep using init_timestep
init_timestep = int(num_inference_steps * strength) + offset
init_timestep = min(init_timestep, num_inference_steps)
timesteps = self.scheduler.timesteps[-init_timestep]
timesteps = torch.tensor([timesteps] * batch_size, dtype=torch.long, device=self.device)
# add noise to latents using the timesteps
noise = torch.randn(init_latents.shape, generator=generator, device=self.device)
init_latents = self.scheduler.add_noise(init_latents, noise, timesteps)
# get prompt text embeddings
text_input = self.tokenizer(prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt")
text_embeddings = self.text_encoder(text_input.input_ids.to(self.device))[0]
# here guidance_scale is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance:
max_length = text_input.input_ids.shape[-1]
uncond_input = self.tokenizer([""] * batch_size, padding="max_length", max_length=max_length, return_tensors="pt")
uncond_embeddings = self.text_encoder(uncond_input.input_ids.to(self.device))[0]
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502 and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
latents = init_latents
t_start = max(num_inference_steps - init_timestep + offset, 0)
for i, t in tqdm(enumerate(self.scheduler.timesteps[t_start:])):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
# predict the noise residual
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeddings)["sample"]
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs)["prev_sample"]
# scale and decode the image latents with vae
latents = 1 / 0.18215 * latents
image = self.vae.decode(latents).sample
image = (image / 2 + 0.5).clamp(0, 1)
image = image.cpu().permute(0, 2, 3, 1).numpy()
# run NSFW safety checker
safety_cheker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(self.device)
image, has_nsfw_concept = self.safety_checker(images=image, clip_input=safety_cheker_input.pixel_values)
if output_type == "pil":
image = self.numpy_to_pil(image)
return {"images": image, "nsfw_content_detected": has_nsfw_concept}
# 文本到图像生成模型参数设置
class TextToImageSetting:
text2image = "0.0.1"
model_id = "CompVis/stable-diffusion-v1-4"
prompt_dict = {
"0000": "a photo of an astronaut riding a horse on mars",
"0001": "digital art of portrait of a woman, holding pencil, inspired, head-and-shoulders shot, white background, cute pixar character",
"0002": "digital art of a man looking upwards, eyes wide inwonder, awestruck, in the style of Pixar, Up, character, white background",
"0003": "the starry sky painting",
"0004": "donald Trump wears a panda headgear",
"0005": "a painting of a fox sitting in a field at sunrise in the style of Claude Monet",
"0006": "dreams flowers and maidens",
"0007": "teddy bears, working on new AI research, on the moon in the 1980s",
"0008": "an astronaut, lounging in a tropical resort in space, as pixel art",
"0009": "the whale was flying in the air, and below was a volcano and a snow-capped mountain",
"0010": "robot, looking at the clouds hanging in the distance, solemn expression, strange background",
}
prompt = prompt_dict["0010"]
seed = 3939590921
sd_mode = "PNDM"
num_inference_steps = 50
guidance_scale = 7
sample_num = 5
batch = 1
height = 512
width = 512
device = "cpu"
fp_mode = "fp32"
save_dir = "./results"
# 图像到图像风格迁移模型参数设置
class ImageToImageSetting:
image2image = "0.0.1"
model_id = "v1-4"
prompt_dict = {
"0001": "a fantasy landscape, trending on artstation",
}
prompt = prompt_dict["0001"]
image_url = "https://www.shuijiaxian.com/files_image/2023110902/11fc2a2b3aa1471b9bced71ee0ddf507.jpeg"
seed = 3939590921
sd_mode = "DDIM"
num_inference_steps = 50
guidance_scale = 7.5
strength = 0.75
sample_num = 5
batch = 1
height = 512
width = 512
device = "cpu"
fp_mode = "fp32"
save_dir = "./results"
def get_args():
parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument("--model_task", default="text2image", type=str, choices=["text2image", "image2image"],
help="模型任务")
parser.add_argument("--model_id", default="CompVis/stable-diffusion-v1-4", type=str, choices=["CompVis/stable-diffusion-v1-4", "runwayml/stable-diffusion-v1-5"],
help="模型版本")
parser.add_argument("--prompt", default="a photo of an astronaut riding a horse on mars", type=str,
help="提示词 - 模型将根据提示词的描述内容生成图像, 一般可分三个部分主体内容(horse, dog, human, mountain)、抽象风格样式(Portrait, Edgar, Rembrandt)和补充润色(4k, beautiful, epic)")
parser.add_argument("--image_url", default=None, type=optional_str,
help="输入图像链接 - 指定输入图片网址或者本地图片路径")
parser.add_argument("--seed", default=51, type=int,
help="随机种子 - 使得紧接着的随机数固定, 如果其他条件不改变, 使用具有相同种子的生成器将得到相同的图像输出, 因此当生成了一张好的图像时可以记录随机种子, 然后微调文字提示")
parser.add_argument("--sd_mode", default=None, type=optional_str,
help="调度器 - 定义了用于在训练期间向模型添加噪声的噪声计划, 根据先前的噪声表示和预测的噪声残差计算预测的去噪图像表示")
parser.add_argument("--num_inference_steps", default=50, type=int,
help="推理的步骤数 - 一般步骤越大生成的图像质量越高")
parser.add_argument("--guidance_scale", default=7, type=int,
help="无分类指导因子 - 能让生成图像匹配文字提示, 稳定扩散, 取值范围 0~20, 过高会牺牲图像质量或多样性, 建议值 7~8.5")
parser.add_argument("--strength", default=0.75, type=int,
help="调整强度 - 取值范围 0~1, 代表文字提示对原图的修改的程度")
parser.add_argument("--sample_num", default=50, type=int,
help="模型推理的次数 - 即循环执行当前模型的次数")
parser.add_argument("--batch", default=1, type=int,
help="模型并行推理的批量 - 使用多批次数将同时生成多张图像, 2 意味着一次推理将生成 2 张图像, 内存的需求也会较 1 增加")
parser.add_argument("--height", default=512, type=int,
help="生成图像的高度 - 需要是 8 的倍数(低于 512 将降低图像质量, 与宽同时超过 512 将丧失全局连贯性)")
parser.add_argument("--width", default=512, type=int,
help="生成图像的宽度 - 需要是 8 的倍数(低于 512 将降低图像质量, 与高同时超过 512 将丧失全局连贯性)")
parser.add_argument("--device", default="cuda", type=str, choices=["cpu", "cuda"],
help="运算平台,取决于硬件支持,通常cuda更快")
parser.add_argument("--fp_mode", default="fp16", type=str, choices=["fp32", "fp16"],
help="运算精度,影响成像速度与质量")
parser.add_argument("--save_dir", default="./results", type=str,
help="图像保存目录 - 相对地址 ./path 表示在和当前程序同级别的目录 path 下保存, 也可使用绝对地址")
return parser.parse_args()
def get_pipe(settings):
# 设置UNet中的调节器
if settings.sd_mode == "DDIM":
scheduler = DDIMScheduler.from_pretrained(settings.model_id,
subfolder="scheduler",
use_auth_token=True)
elif settings.sd_mode == "DDPM":
scheduler = DDPMScheduler.from_pretrained(settings.model_id,
subfolder="scheduler",
use_auth_token=True)
elif settings.sd_mode == "PNDM":
scheduler = PNDMScheduler.from_pretrained(settings.model_id,
subfolder="scheduler",
use_auth_token=True)
elif settings.sd_mode == "LMSD":
scheduler = LMSDiscreteScheduler.from_pretrained(settings.model_id,
subfolder="scheduler",
use_auth_token=True)
elif settings.sd_mode == "Euler":
scheduler = EulerDiscreteScheduler.from_pretrained(settings.model_id,
subfolder="scheduler",
use_auth_token=True)
else:
scheduler = None
# 设置Diffusion模型
if hasattr(settings, "text2image"):
if scheduler is not None:
if settings.fp_mode == "fp32":
pipe = StableDiffusionPipeline.from_pretrained(settings.model_id,
cheduler=scheduler,
torch_dtype=torch.float32,
use_auth_token=True)
elif settings.fp_mode == "fp16":
pipe = StableDiffusionPipeline.from_pretrained(settings.model_id,
revision="fp16",
scheduler=scheduler,
torch_dtype=torch.float16,
use_auth_token=True)
else:
pass
else:
if settings.fp_mode == "fp32":
pipe = StableDiffusionPipeline.from_pretrained(settings.model_id,
torch_dtype=torch.float32,
use_auth_token=True)
elif settings.fp_mode == "fp16":
pipe = StableDiffusionPipeline.from_pretrained(settings.model_id,
revision="fp16",
torch_dtype=torch.float16,
use_auth_token=True)
else:
pass
elif hasattr(settings, "image2image"):
if scheduler is not None:
if settings.fp_mode == "fp32":
pipe = StableDiffusionImgToImgPipeline.from_pretrained(settings.model_id,
scheduler=scheduler,
use_auth_token=True)
elif settings.fp_mode == "fp16":
pipe = StableDiffusionImgToImgPipeline.from_pretrained(settings.model_id,
revision="fp16",
scheduler=scheduler,
torch_dtype=torch.float16,
use_auth_token=True)
else:
pass
else:
if settings.fp_mode == "fp32":
pipe = StableDiffusionImgToImgPipeline.from_pretrained(settings.model_id,
use_auth_token=True)
elif settings.fp_mode == "fp16":
pipe = StableDiffusionImgToImgPipeline.from_pretrained(settings.model_id,
revision="fp16",
torch_dtype=torch.float16,
use_auth_token=True)
else:
pass
else:
pass
return pipe.to(settings.device)
def main(_args):
# 模型基础设置
if _args.model_task == "text2image":
settings = TextToImageSetting()
elif _args.model_task == "image2image":
settings = ImageToImageSetting()
else:
pass
settings.model_id = _args.model_id
settings.prompt = _args.prompt
if hasattr(settings, "image2image"):
settings.image_url = _args.image_url
settings.seed = _args.seed
settings.sd_mode = _args.sd_mode
settings.num_inference_steps = _args.num_inference_steps
settings.guidance_scale = _args.guidance_scale
if hasattr(settings, "image2image"):
settings.strength = _args.strength
settings.sample_num = _args.sample_num
settings.batch = _args.batch
settings.height = _args.height
settings.width = _args.width
settings.device = _args.device
settings.fp_mode = _args.fp_mode
if settings.device == "cuda":
if not torch.cuda.is_available():
settings.device = "cpu"
if settings.fp_mode == "fp16":
settings.fp_mode = "fp32"
if settings.device == "cpu":
if settings.fp_mode == "fp16":
settings.fp_mode = "fp32"
settings.save_dir = _args.save_dir
# 获取数据管道实例
pipe = get_pipe(settings=settings)
# 运行实例保存并展示结果
image_list = []
generator = torch.Generator(device=settings.device).manual_seed(settings.seed)
if hasattr(settings, "text2image"):
for idx in range(settings.sample_num):
print(f"正在生成第{idx+1}批图像 - 一共{settings.batch}张")
if settings.device == "cuda":
with autocast("cuda"):
data = pipe([settings.prompt]*settings.batch,
height=settings.height, width=settings.width,
num_inference_steps=settings.num_inference_steps,
guidance_scale=settings.guidance_scale,
generator=generator)
else:
data = pipe([settings.prompt]*settings.batch,
height=settings.height, width=settings.width,
num_inference_steps=settings.num_inference_steps,
guidance_scale=settings.guidance_scale,
generator=generator)
image = data["images"]
save_image(image, settings.save_dir, settings.prompt)
image_list.append(image_grid(image, x=settings.batch, y=settings.batch))
show_image(image_list, settings.prompt)
elif hasattr(settings, "image2image"):
init_image = []
try:
init_image = Image.open(BytesIO(requests.get(settings.image_url).content)).convert("RGB")
except:
init_image = Image.open(settings.image_url).convert("RGB")
finally:
if not init_image:
print("图片未被成功导入, 请检查图像链接是否正确")
init_image = init_image.resize((settings.height, settings.width))
show_image([init_image], settings.prompt)
for idx in range(settings.sample_num):
print(f"正在生成第{idx+1}批图像 - 一共{settings.batch}张")
if settings.device == "cuda":
with autocast("cuda"):
data = pipe(prompt=[settings.prompt]*settings.batch,
image=init_image,
strength=settings.strength,
num_inference_steps=settings.num_inference_steps,
guidance_scale=settings.guidance_scale ,
generator=generator)
else:
data = pipe(prompt=[settings.prompt]*settings.batch,
image=init_image,
strength=settings.strength,
num_inference_steps=settings.num_inference_steps,
guidance_scale=settings.guidance_scale ,
generator=generator)
image = data["images"]
save_image(image, settings.save_dir, settings.prompt)
image_list.append(image_grid(image, x=settings.batch, y=settings.batch))
show_image(image_list, settings.prompt)
else:
pass
if __name__ == "__main__":
_args = get_args()
main(_args)
print("运行完成")
三、尾巴
- 我的GItHub仓库中关于Stabled Diffusion的全部内容
- 我的云端硬盘Colab中关于Stabled Diffusion的demo
最后
以上就是积极裙子最近收集整理的关于爱做梦的人工智能「Stabled Diffusion」开始之前的全部内容,更多相关爱做梦的人工智能「Stabled内容请搜索靠谱客的其他文章。








发表评论 取消回复