数据在哪里都是重要的,高考分数、股票价格,在互联网就是dau、用户时长、留存等指标。写代码也要对数据敏感,知道数据的意义是什么,又是怎么算出来的。
这篇聊下头条号的文章发出去之后,被人阅读、评论的那些数是怎么来的。里面用到的就是这几年捧的很高对于外行也很迷的大数据技术。
头条号的数据指标有哪些
作为头条号的作者,文章写好发出去之后肯定是关心文章的消费数据的,最关心的就是昨天文章有多少人看了,有多少人点赞了,多少人评论、转发了。 那么头条号提供了历史天级别的统计数据,如下图。
在头条内部文章在app上的分发也就叫消费,虽然用户没有花钱但花了时间,用户花的时间越多对APP的价值就越大。
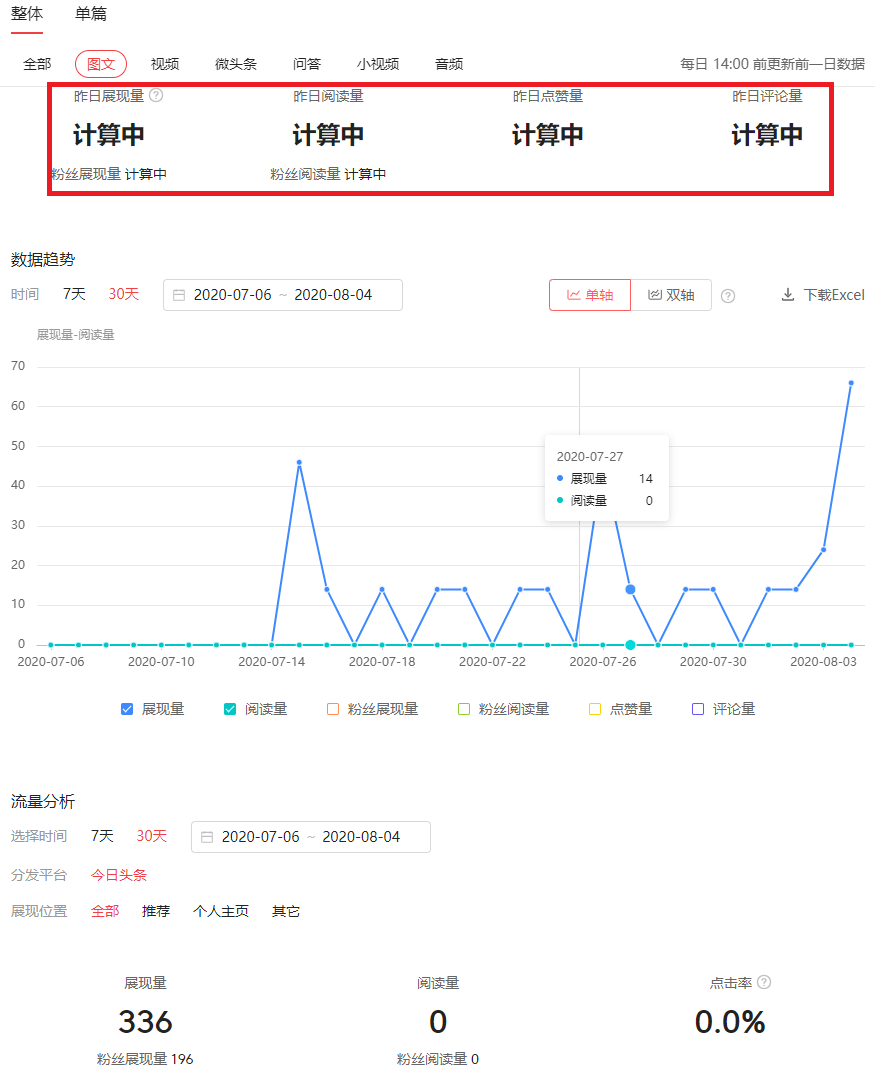
这个图里面重点关注下面几点:
(1)红框框柱的几个指标:展现、阅读、点赞、评论,有没有注意到昨天的数据还是计算中,我是下午截的图。这里解释下展现,在今日头条APP里面,刷一下会更新很多文章,这些文章展现在了你眼前,但你可能不会点进去看。那么展现在你眼前的文章就算一次展现,但不会算阅读。
(2)数据趋势,默认分析的是30天的,每天的数据作为一个点,画在折线图里。
这里的天级别的数据就是离线数据,即非实时的,也就是昨天的阅读量要等到第二天可能第三天才算出来,而不是在第一天结束的下1秒就算出来。那是需要上没必要还是技术上做不到? 一是需求上确实没多大必要,作者晚个一两天看前面的统计数据影响不大,二也是技术难度大,实现的成本很高。一般汇总类的数据是离线的,也就是作者所有文章在昨天的阅读量,而一般不会给某一篇文章在昨天的统计量,也是没必要。
头条号还有一部分数据是实时的,实际上是准实时的,也就是你阅读了一篇文章,文章的阅读数要等个几分钟才会更新。你可以发一篇质量很差的文章测试下,因为质量差不会推荐出去基本上就你自己阅读。下图红框里显示的展现、阅读、评论就是实时数据。一般是具体某个对象的数据是实时的,头条这里就是某一篇文章。
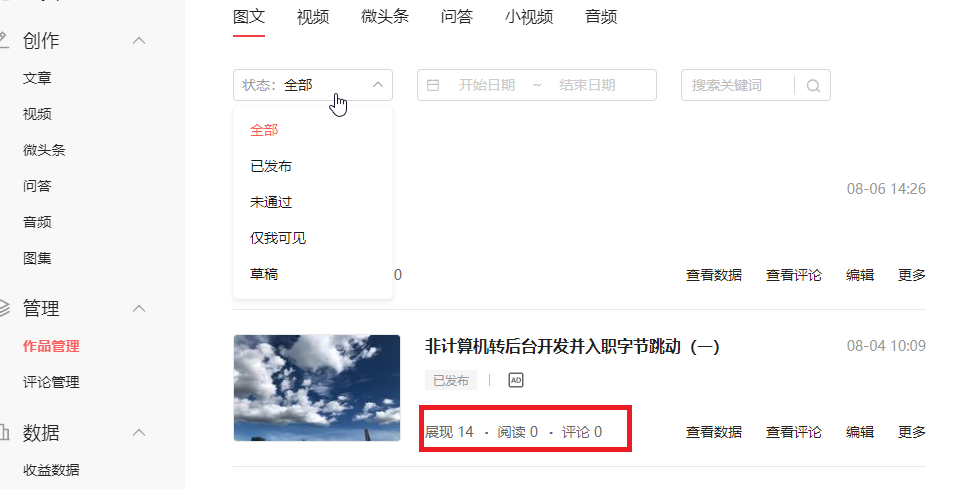
实时数据统计实现
先看单篇文章的统计数据怎么实现,先不管文章在APP里面怎么推荐。
现在的情况是文章已经展现给了用户,用户点击了文章跳转到文章详情页,不管用户是否用心看,都要算一次阅读。现在产品提了个需求:统计阅读数。 你作为研发,需要实现这个需求,需要考虑方案然后编码实现。
有了需求我们还是先做下需求分析,尤其对于这种一句话需求,坑是很多的。读者可以自己先想下有哪些点需要细化,然后会出什么样的方案。
这里大概列下需要考虑的:
(1)如果一个用户在短时间内(比如半个小时或者一个小时内)反复点击这篇文章,阅读数要怎么算? 有些用户可能故意反复点击,也有些确实看了之后过几分钟又想看一下。
(2)如果一个用户在较长时间内比如12小时或者1天以上的时间内反复阅读的,要不要算多次?
(3)阅读数的更新时间要多久,也就是用户实际阅读了,那么任何有阅读数这个指标的地方的数据要多久更新,分钟级小时级还是天级。
(4)根据上面的场景,就有一个更重要的问题,就是阅读数是否要非常准确,就是任何一个读者的阅读了,至少都要算上,但不能多算也不能少算。
那么互联网广大的做法都是:同一用户短时间(半个小时左右)内点击多次只算一次阅读,不需要精确计数,因为阅读数一般只关心一个范围,比如千级别,万级别,10万级别。 无需精确计数给技术实现降低了很大的难度。 那有人会问,那如果我就要精确计数了,不重不丢,要怎么实现?也能做,阿里双十一的订单成交量、成交金额统计就是这么做的,但一般是涉及到钱的场景才会去做,这种场景ROI(投入产出比)才是值得的。脱离业务场景讲技术是不现实的。
怎么区分是哪个用户?对于注册用户肯定比较容易有userid,对于非注册用户,APP也是做了处理的,会用设备id进行区分。
现在需求进一步明确了,那实现方案该怎么做?可能的做法是:
(1)阅读数存mysql表里面,点击文章的时候发起一个HTTP请求,后端接受到这个请求就直接对mysql的字段加1。那么怎么解决半个小时内的重复阅读不计数?直接写mysql那服务器抗得住吗,热门文章百万阅读量,同时阅读可能也会上千。考虑用redis缓存下,先写redis,然后定期刷新到mysql,嗯,果然缓存大法好。那既然用redis为啥还用mysql,只用redis不行吗,反正就是存一个数?首先redis是可以做持久化存储的,当然只用redis是可以的。
(2)既然不要精确也不要求实时,那是不是会想到用kafka,异步处理,也容易抗住大流量。点击一次文章,就发个消息到kafka,说有个用户看了,然后kafka的消费者就批量处理。那消费者要怎么统计了?还不是得跟方式1一样要写处理逻辑。处理完之后不还是得存数据库,存mysql还是redis。好像问题并没有完全解决。
是的,难点就在于怎么半个小时内去重,去重的id应该是userid+文章id,考虑下用redis记住阅读时间,每次统计的时候访问下redis。当然没有问题。
但这类需求太多了,每个业务逻辑都这样实现一遍成本是有点高的,因为头条有这个需求,抖音也有这个需求,TikTok也有,西瓜视频也有。是不是就得考虑一个通用的平台。
实时计数属于流式计算问题,业界有开源的spark和flink可以处理(flink又是比较火的技术)。头条开始用的spark,现在已经全部用flink进行计数统计了。也就是数据先发kakak,数据从kafka出来接flink,flink统计完之后将数据更新到kv存储(不是redis)。flink统计是有时间窗的概念,具体让flink怎么统计就需要按照flink框架写代码,一般用java或python开发。这里又出现了数据流,最直观的数据流动路径。
在flink之上,还有一个专用的平台做相关的业务处理。比如文章的阅读数10万+了,这个时候是不是要重点关注下,万一这个文章是搞huangse才是10万+的,那不得重蹈内涵段子的覆辙。所以就得做些特殊处理。后台开发工程师工作中少不了的就是写配置。
而对于评论数这种,每一个评论数都是对应到一条具体的评论内容的,也就是要不重不丢,那评论内容肯定要存储,用mysql可以,用kv存储也可以。但评论总数仍然可以跟阅读数一样的处理,不然每次取总数都count一把,也比较废资源。
离线数据统计实现
有了单篇文章实时的数据,对于天级别汇总类的数据,那加起来就可以了。具体怎么加,又是门学问。这里的汇总数据不是要求很精确,只要在汇总的时候,把文章当前时刻所有数据加起来。
如果在线去计算,遍历mysql或者redis的所有数据,然后算一遍。首先mysql和redis绝对是承受不住的,百亿级别的文章量,全量数据直接去操作,内存、CPU、带宽任何一个都扛不住。
如果让没经验的人直接想方案是很难想出来的。业界的做法是用hdfs和hive,对大数据感兴趣的人基本都听过。hdfs是一种分布式存储的方案,可以简单理解为存PB级大小的数据,百亿级别的文章是存的下的。hive就是对HDFS上存的数据进行分析计算,怎么分析,就只要写SQL就行,hive会对SQL进行翻译处理。
mysql或redis的数据都是可以导到hdfs的以hive表的形式,因为本质都是文件。大公司内部都有对应的平台,对于后台开发人员使用很方便,基本就是写个定时任务,做一些配置就可以。任务配置好了,一搬每天凌晨2-3点这些任务就被调度起来执行。执行完之后相当于对mysql和redis的数据做了一份快照,也就是任务执行时刻的数据都copy下来了,任务执行之后的数据mysql或redis会继续更新,但是hdfs的数据不再更新,所以说是离线的,即非实时的。
数据导到了hdfs,那怎么累加文章的阅读量? 这就是让hive慢慢算了,hive具体怎么算就要依赖工程师写的SQL了。因为hive集群一般有很多服务器,内存可能是TB级别,CPU可能上万核,所以数据量虽大,但这么多CPU一起算,快一点几分钟,几个小时,慢一点一天两天也就可以算出来了。 所以最开始截图里面的计算中,就是这些离线任务还没跑完,可能资源比较紧张。
hive算出来的数据是存放到哪里的?能直接写回mysql吗?不能直接写mysql,只能又放到hdfs上以hive表的形式,那要展示的数据是直接从hdfs读取。从来没听过是从文件系统读取,一般都是从数据库读取。这中间就还得用一个定时任务,把计算好的数据从hive表再写到mysql。因为是汇总的数据,量级可能是百万级别,因为一个作者只要汇总出一份数据,作者总数比读者数是少很多的。所以可以慢慢的写mysql。
上面也提到了两个定时任务,从mysql到hive表以,从hive表到mysql。那么这些定时任务怎么管理调度。开源的有airflow这些框架,头条是自研的框架,非常好用。
大数据应用总结
实时数据、离线数据统计这一套流程就是大数据处理最典型的应用。大数据确实体现了数据量大,传统的mysql等无法直接处理。大数据处理框架也是非常成熟了,当然还是在不断发展中。应用的话只需要关注hdfs、hive、spark、flink,深入学习原理后又会接触到mapreduce、yarn。
互联网的技术太多了,想学一辈子都学不完,一定要尽早找到自己的方向。那怎么找方向,一条路就是看实际工作用到什么。工作中用到的面试官当然会问,因为他比较熟悉,面试官大部分只会问他会的。对于要入门的同学来以这些为突破口,通过实践去学习,而不是只看,一定要实践。知易行难,《剑指offer》大家都看了,但别人没去写代码,你去写了,你才会领先。 至于刷题,最好是有了代码量之后才去刷,然后面试前重点突击,这样投入产出比会更高。如果上来就刷题,对于非科班的同学,你大概率会怀疑自己的智商。
下篇会聊下ETL和推荐,然后会对这几篇文章中聊到的技术按照“安装、使用、原理”三步法去学。
最后
以上就是大意朋友最近收集整理的关于互联网业务实战(二)--大数据在头条的应用(离线和实时数据处理)的全部内容,更多相关互联网业务实战(二)--大数据在头条内容请搜索靠谱客的其他文章。








发表评论 取消回复