抓住一只文章:
https://www.jianshu.com/p/79a896a5442f
10.2 数据加载
http://archive.ics.uci.edu/ml/datasets/Wholesale+customers
hdfs dfs -put Wholesale_customers_data.csv /u01/bigdata/data
import org.apache.spark.ml.clustering.KMeans
import org.apache.spark.ml.feature.VectorAssembler
import org.apache.spark.ml.feature.OneHotEncoder
import org.apache.spark.ml.feature.StandardScaler
import org.apache.spark.ml.{Pipeline, PipelineModel}
val raw_data = spark.read.format("csv").option("header", true).load("hdfs://XX/u01/bigdata/data/Wholesale_customers_data.csv")
10.3 探索特征的相关性
scala> raw_data.show(5)
+-------+------+-----+----+-------+------+----------------+----------+
|Channel|Region|Fresh|Milk|Grocery|Frozen|Detergents_Paper|Delicassen|
+-------+------+-----+----+-------+------+----------------+----------+
| 2| 3|12669|9656| 7561| 214| 2674| 1338|
| 2| 3| 7057|9810| 9568| 1762| 3293| 1776|
| 2| 3| 6353|8808| 7684| 2405| 3516| 7844|
| 1| 3|13265|1196| 4221| 6404| 507| 1788|
| 2| 3|22615|5410| 7198| 3915| 1777| 5185|
+-------+------+-----+----+-------+------+----------------+----------+
scala> raw_data.printSchema
root
|-- Channel: string (nullable = true)
|-- Region: string (nullable = true)
|-- Fresh: string (nullable = true)
|-- Milk: string (nullable = true)
|-- Grocery: string (nullable = true)
|-- Frozen: string (nullable = true)
|-- Detergents_Paper: string (nullable = true)
|-- Delicassen: string (nullable = true)
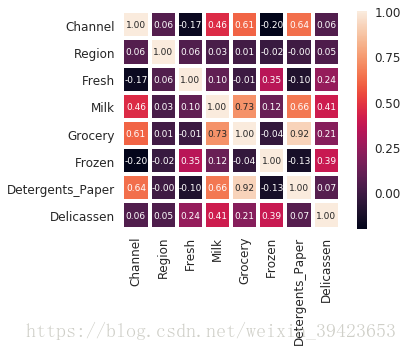
# pyspark画出特征相关性
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.read_csv("/root/data/Wholesale_customers_data.csv", header=0)
cols = ['Channel','Region','Fresh','Milk','Grocery','Frozen','Detergents_Paper','Delicassen']
cm = np.corrcoef(df[cols].values.T)
sns.set(font_scale=1.2)
hm = sns.heatmap(cm,cbar=True,annot=True,square=True,fmt='.2f',annot_kws={'size':9},yticklabels=cols,xticklabels=cols,linewidths=3)
plt.show()
# plt.savefig('sale_corr.png')
10.4 数据预处理
// 转换为数值型
val data1 = raw_data.select(
raw_data("Channel").cast("Double"),
raw_data("Region").cast("Double"),
raw_data("Fresh").cast("Double"),
raw_data("Milk").cast("Double"),
raw_data("Grocery").cast("Double"),
raw_data("Frozen").cast("Double"),
raw_data("Detergents_Paper").cast("Double"),
raw_data("Delicassen").cast("Double")
).cache()
// 将类别特征转换为二元编码
将Channel特征转换为二元编码
val dataHot1 = new OneHotEncoder().setInputCol("Channel").setOutputCol("ChannelVec").setDropLast(false)
将Region特征转换为二元编码
val dataHot2 = new OneHotEncoder().setInputCol("Region").setOutputCol("RegionVec").setDropLast(false)
// 将新生成的2个特征及原来的6个特征组成一个特征向量
val featuresVecArray = Array("ChannelVec","RegionVec","Fresh","Milk","Grocery","Frozen","Detergents_Paper","Delicassen")
// 把原数据组合成向量features
val vecDF = new VectorAssembler().setInputCols(featuresVecArray).setOutputCol("features")
// 对特征进行规范化
val scaledDF = new StandardScaler().setInputCol("features").setOutputCol("scaledFeatures").setWithStd(true).setWithMean(false)
10.5 组装
// KMeans
val kMeans = new KMeans().setFeaturesCol("scaledFeatures").setK(4).setSeed(123L)
// 把转换二元向量、特征规范化转换等组装到流水线上,因pipeline中无聚类的评估函数,这里流水线中不纳入kmeans
val pipeline1 = new Pipeline().setStages(Array(dataHot1, dataHot2, vecDF, scaledDF))
val data2 = pipeline1.fit(data1).transform(data1)
// 训练模型
val model = kMeans.fit(data2)
val results = model.transform(data2)
// 评估模型
val WSSSE = model.computeCost(data2)
println(s"Within Set Sum of Squared Errors = $WSSSE")
// 显示聚类结果
println("Cluster Centers: ")
model.clusterCenters.foreach(println)
results.collect().foreach(row => {println( row(10) + " is predicted as cluster " + row(11))})
// 当k=4的记录数
scala> results.select("scaledFeatures", "prediction").groupBy("prediction").count.show()
+----------+-----+
|prediction|count|
+----------+-----+
| 1| 10|
| 3| 136|
| 2| 64|
| 0| 230|
+----------+-----+
// 由此可知,簇0,3较大,1,2较小
results.select("scaledFeatures", "prediction").filter(i=> i(1)==0).show(20)
val result0 = results.select("scaledFeatures", "prediction").filter(i=> i(1)==0).select("scaledFeatures")
10.6 模型优化
val KSSE = (2 to 20 by 1).toList.map{ k =>
val kMeans = new KMeans().setFeaturesCol("scaledFeatures").setK(4).setSeed(123L)
val model = kMeans.fit(data2)
val WSSSE = model.computeCost(data2)
// K,实际迭代次数,SSE,聚类类别编号,每类的记录数,类中心点
(k, model.getMaxIter, WSSSE, model.summary.cluster, model.summary.clusterSizes, model.clusterCenters)
}
// 显示结果
KSSE.map(x=>(x._1, x._3)).sortBy(x=>x._2).foreach(println)
// 显示结果保存(注:这个保存到的路径是hdfs路径)
KSSE.map(x=>(x._1, x._3)).sortBy(x=>x._2).toDF.write.save("/u01/bigdata/ksse")
最后
以上就是舒适大白最近收集整理的关于《深度实践Spark机器学习》第10章 构建Spark ML聚类模型的全部内容,更多相关《深度实践Spark机器学习》第10章内容请搜索靠谱客的其他文章。








发表评论 取消回复