java 机器学习模型
我之前的教程“ 面向Java开发人员的机器学习”介绍了如何设置机器学习算法并开发Java预测功能。 我演示了机器学习算法的内部工作原理,并逐步介绍了开发和训练机器学习模型的过程。 本教程将继续讲解。 我将向您展示如何建立机器学习数据管道,介绍将开发过程中的机器学习模型带入生产环境的分步过程,并简要讨论在基于Java的机器上部署经过训练的机器学习模型的技术生产环境。
要求以及对本教程的期望
部署机器学习模型是与开发模型不同的工作,通常是由不同的团队来实施。 开发机器学习模型需要理解基础数据,并且对数学和统计知识有很好的掌握。 对于具有软件工程和运营经验的人员来说,在生产环境中部署机器学习模型通常是一项工作。
本教程向您展示如何在高度可扩展的生产环境中使用机器学习模型。 我假设您具有一定的开发经验,并且对机器学习模型和算法有基本的了解; 否则,您可能需要阅读“ Java开发人员的机器学习,第1部分 ”。
我将首先简要介绍有监督的学习,包括一个示例应用程序,我将使用它来演示如何训练,部署和处理用于生产的机器学习模型。
有监督的机器学习:复习
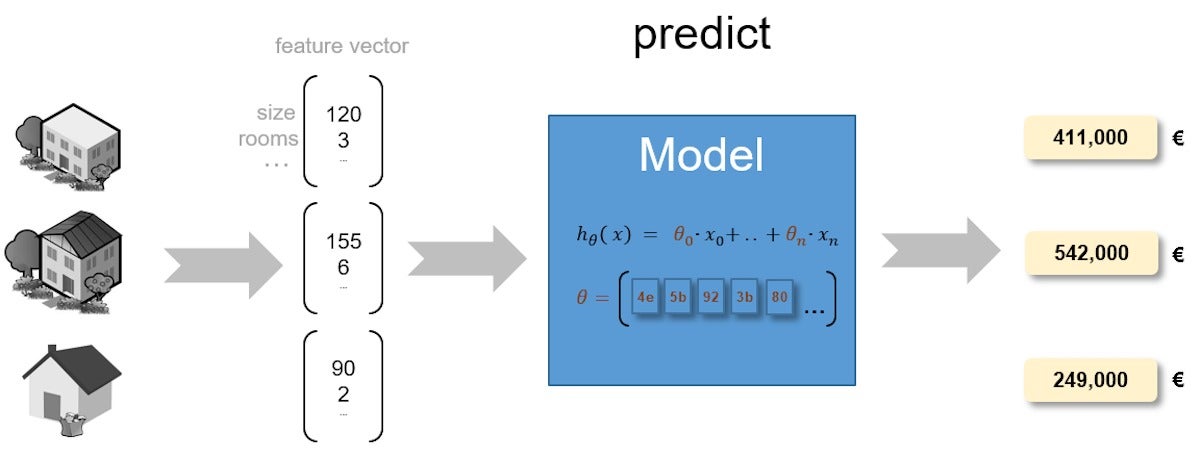
我将使用一个简单的,受监督的机器学习模型来说明机器学习部署过程。 图1所示的示例机器学习模型可用于预测房屋的预期售价。
 格里戈尔·罗斯(Gregor Roth)
格里戈尔·罗斯(Gregor Roth)
图1.用于价格预测的训练有素的监督机器学习模型
回想一下,机器学习模型是一个具有内部可学习参数的函数,该参数将输入映射到输出。 在上图中,线性回归函数hθ (x)用于基于各种功能预测房屋的销售价格。 函数的x变量表示输入数据。 θ (θ)变量表示内部可学习的模型参数。
要预测房屋的销售价格,您必须首先创建x变量的输入数据数组。 此阵列包含诸如地块的大小或房屋中的房间数之类的特征。 此数组称为特征向量 。
因为大多数机器学习功能都需要数字表示特征,所以您可能必须执行一些数据转换才能构建特征向量。 例如,指定车库位置的特征可能包括必须映射到数值的标签,例如“贴在家里”或“内置”。 当您执行房价预测时,机器学习功能将与此输入特征向量以及内部训练有素的模型参数一起应用。 该函数的输出是估计的房价。 此输出称为标签 。
训练模型
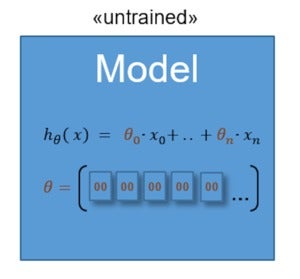
内部可学习的模型参数(θ)是从训练数据中学到的模型的一部分。 可学习的参数将在培训过程中设置。 为了进行有用的预测,必须训练一种类似于以下所示的有监督的机器学习模型。
 格里戈尔·罗斯(Gregor Roth)
格里戈尔·罗斯(Gregor Roth)
图2.未经训练的监督式机器学习模型
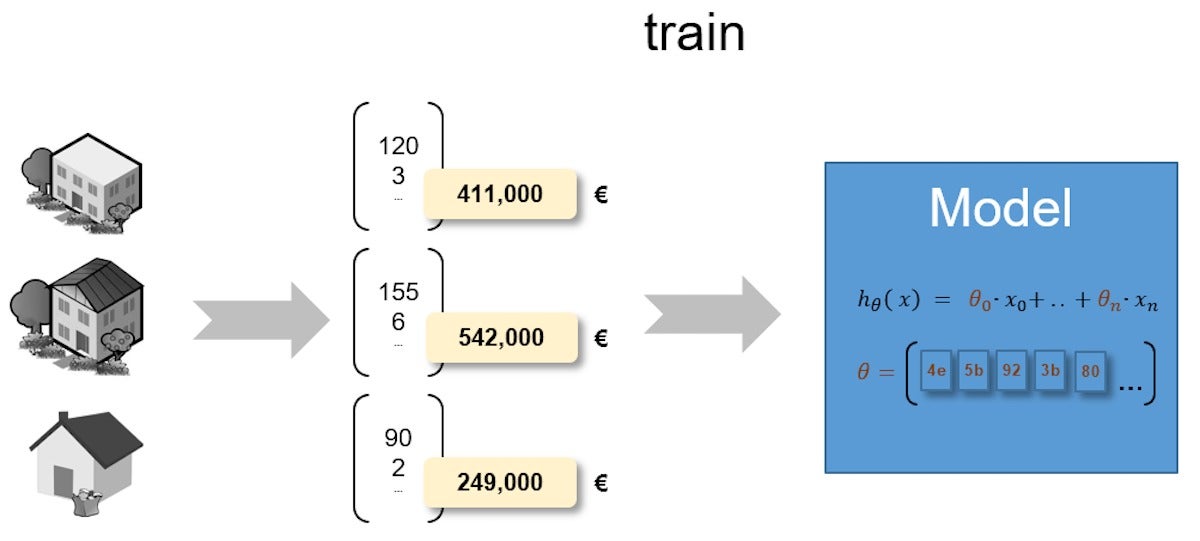
通常,训练过程从未经训练的模型开始,在该模型中,所有可学习的参数都设置有初始值(例如零)。 该模型使用有关各种房屋功能的数据以及实际房价。 逐步地,它确定了房屋功能和房价之间的相关性,以及这些关系的权重。 该模型调整其内部可学习的模型参数,并使用它们进行预测。
 格里戈尔·罗斯(Gregor Roth)
格里戈尔·罗斯(Gregor Roth)
图3.训练有素的监督机器学习模型
在训练过程之后,该模型将能够通过评估房屋的功能来估计房屋的销售价格。
Java代码中的机器学习算法
HousePriceModel提供了两种方法。 一种方法实现了学习算法来训练(或拟合 )模型。 另一种方法用于预测。
 格里戈尔·罗斯(Gregor Roth)
格里戈尔·罗斯(Gregor Roth)
图4.机器学习模型中的两种方法
fit()方法
fit()方法用于训练模型。 它使用房屋功能以及房屋价格作为输入参数,但不返回任何内容。 fit()方法需要正确的“答案”才能调整其内部模型参数。 通过将房屋清单与售价配对,学习算法可以在训练数据中查找模式。 由此产生的模型参数可以从这些模式中得出。 随着输入数据变得更加准确,将调整模型的内部参数。
清单1. fit()方法用于训练机器学习模型
// load training data
// ...
// e.g. [{MSSubClass=60.0, LotFrontage=65.0, ...}, {MSSubClass=20.0, ...}]
List<Map<String, Double>> houses = ...;
// e.g. [208500.0, 181500.0, 223500.0, 140000.0, 250000.0, ...]
List<Double> prices = ...;
// create and train the model
var model = new HousePriceModel();
model.fit(houses, prices);
请注意,房屋特征在代码中是双键入的。 这是因为用于实现fit()方法的机器学习算法需要数字作为输入。 所有房屋特征都必须用数字表示,以便可以将它们用作线性回归公式中的x参数,如下所示:
ħθ(X)=θ0 * X 0 + ... +θN *×n个
经过训练的房价预测模型可能看起来像您在下面看到的那样:
price = -490130.8527 * 1 + -241.0244 * MSSubClass + -143.716 * LotFrontage + … * …
在这里,输入房屋特征(例如MSSubClas或LotFrontage表示为x变量。 可学习的模型参数(θ)设置为-490130.8527或-241.0244,这些值是在训练过程中获得的。
本示例使用简单的机器学习算法,该算法仅需要几个模型参数。 一个更复杂的算法,例如用于深度神经网络的算法,可能需要数百万个模型参数。 这是训练此类算法的过程需要高计算能力的主要原因之一。
的predict()方法
训练完模型后,可以使用predict()方法确定房屋的估计售价。 此方法使用有关房屋功能的数据并产生估计的销售价格。 实际上,房地产公司的代理人可以输入诸如地块(面积),房间数量或整体房屋质量之类的功能,以便获得给定房屋的估计售价。
转换非数值
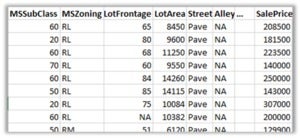
您经常会遇到包含非数字值的数据集。 例如,用于Kaggle房屋价格竞赛的Ames房屋数据集包括房屋特征的数字列表和文本列表:
 格雷戈尔·罗斯(Gregor Roth)。
格雷戈尔·罗斯(Gregor Roth)。
图5. Kaggle房屋价格数据集的样本
为了使事情更复杂,Kaggle数据集还包含空值(标记为NA),清单1所示的线性回归算法无法处理这些空值。
现实世界中的数据记录通常不完整,不一致,缺少所需的行为或趋势,并且可能包含错误。 这通常发生在使用不同源连接了输入数据的情况下。 输入数据必须先转换为干净的数据集,然后再输入模型。
在上面的示例中,您将需要替换缺少的(NA)数字LotFrontage值。 您还需要用数字值替换文本值,例如MSZoning “ RL”或“ RM”。 这些转换对于将原始数据转换为可以由模型处理的语法正确格式是必需的。
将数据转换为通常可读的格式后,您可能仍需要进行其他更改以提高输入数据的质量。 例如,您可以删除不遵循数据总体趋势的值,或将不经常出现的类别放入单个总括类别。
数据转换的重要性
您选择的机器学习算法可能非常强大,但是如果没有准备好的数据,那么经过训练的算法将无法产生准确的预测。 数据科学家通常会花费大量时间来编写转换,以提高训练数据的质量。 数据转换是有效机器学习的关键步骤。
如何建立您的机器学习数据管道
通常,将数据准备或预处理步骤安排为管道。 例如,下面的简化房屋预测管道会安排一组带有最终房屋预测模型的预处理变压器组件。
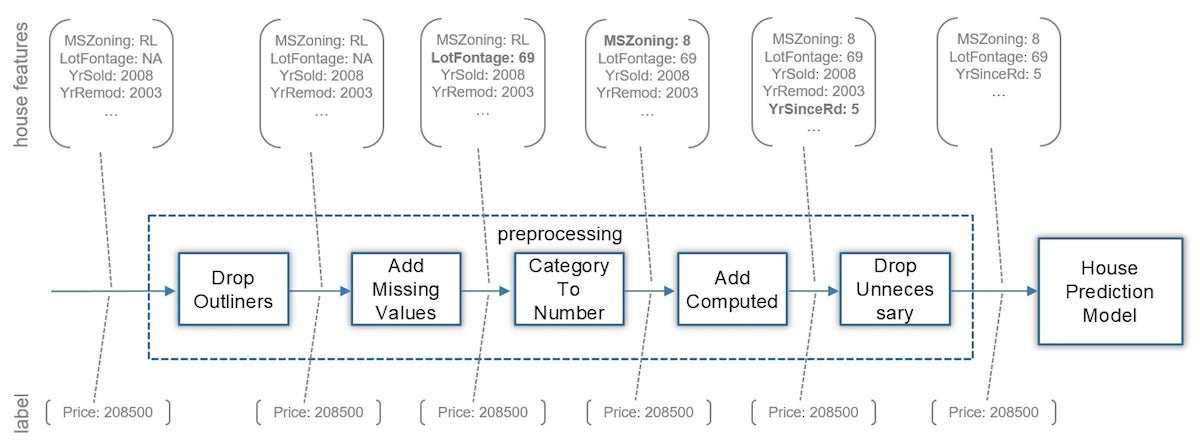 格里戈尔·罗斯(Gregor Roth)
格里戈尔·罗斯(Gregor Roth)
图6.数据预处理的示例步骤
转换器组件清除原始数据,并将其转换为模型可以使用的格式。 在转换的每个阶段之后,数据变得更适合于模型。
管道模式使您可以组织转换代码,以便每个转换器组件都有一个职责。 例如,下面的CategoryToNumberTransformer类用数字替换所有文本要素值。 由于此转换器实现不处理空值,因此必须在应用AddMissingValuesTransformer之后处理转换AddMissingValuesTransformer 。 在内部, CategoryToNumberTransformer使用文本要素值作为键并使用唯一的生成数字作为值来保存地图。 MSZoning功能的映射可能如下所示:
{FV=1, RH=2, RM=3, C=5, …, RL=8, «default»=-1} 调用transform()方法时,将使用映射集合检测文本值并将其转换为数字,如清单2所示。
清单2.用数字值替换文本特征值
public class CategoryToNumberTransformer implements Transformer<Object, Double, Double> {
private final CategoryToNumberResolver categoryToNumber = new CategoryToNumberResolver();
public List<Map<String, Double>> transform(List<Map<String, Object>> houses) {
return houses.stream().map(this::transform).collect(Collectors.toList());
}
private Map<String, Double> transform(Map<String, Object> house) {
return house.entrySet()
.stream()
.collect(Collectors.toMap(feature -> feature.getKey(),
feature -> (feature.getValue() instanceof String)
? categoryToNumber.map(feature)
: (Double) feature.getValue()));
}
public void fit(List<Map<String, Object>> houses , List<Double> prices) {
houses.forEach(house -> house.entrySet()
.stream()
.filter(feature -> feature.getValue() instanceof String)
.forEach(categoryToNumber::add));
}
private static final class CategoryToNumberResolver {
private final Map<String, Double> categoryToNumberMapping = Maps.newHashMap();
void add(Map.Entry<String, Object> feature) {
// ..
}
Double map(Map.Entry<String, Object> feature) {
// ..
}
}
}
有两种创建内部类别-数字映射的方法。 要手动执行此操作,您将在开发期间将所有可能的条目添加到地图。 如上所示,要动态执行此操作,您将在训练时扫描所有可用记录。 在此示例中, fit()训练方法可动态构建类别到数字的映射。 首先,它提取一组所有文本值,然后使用该值集构建一个映射,其中包括新生成的与唯一文本值相关联的数字。
配置机器学习数据管道
在大多数情况下,预处理逻辑特定于模型,因此更新预处理组件的逻辑需要重新训练模型。 因此,预处理代码和模型代码通常打包在一起,如下所示。 这里,使用通用Pipeline类将变压器与最终房屋预测模型一起布置。
清单3.通用Pipeline类
var pipeline = Pipeline.add(new DropNumericOutliners("LotArea", 10))
.add(new AddMissingValuesTransformer())
.add(new CategoryToNumberTransformer())
.add(new AddComputedFeatureTransformer())
.add(new DropUnnecessaryFeatureTransformer("YrSold", "YearRemodAdd"))
.add(new HousePriceModel());
pipeline.fit(houses, prices);
// …
一些机器学习库提供类似于上面示例的管道抽象。 其他仅提供可配置和可定制的预处理组件。
训练机器学习数据管道
翻译自: https://www.infoworld.com/article/3454363/machine-learning-for-java-developers-part-2-deploying-your-machine-learning-model.html
java 机器学习模型
最后
以上就是认真超短裙最近收集整理的关于java 机器学习模型_Java开发人员的机器学习,第2部分:部署模型的全部内容,更多相关java内容请搜索靠谱客的其他文章。








发表评论 取消回复