Ref:https://blog.csdn.net/legotime/article/details/51871724#
测试数据
hello spark hello hadoop csdn hadoop csdn csdn hello world结果
(spark,1) (hadoop,2) (csdn,3) (hello,3) (world,1)
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WC {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("WC").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val path = "file:///" + System.getProperty("user.dir") + "/data4test/WC.txt"
val outpath="file:///" + System.getProperty("user.dir") + "/data4test/WC4result.txt"
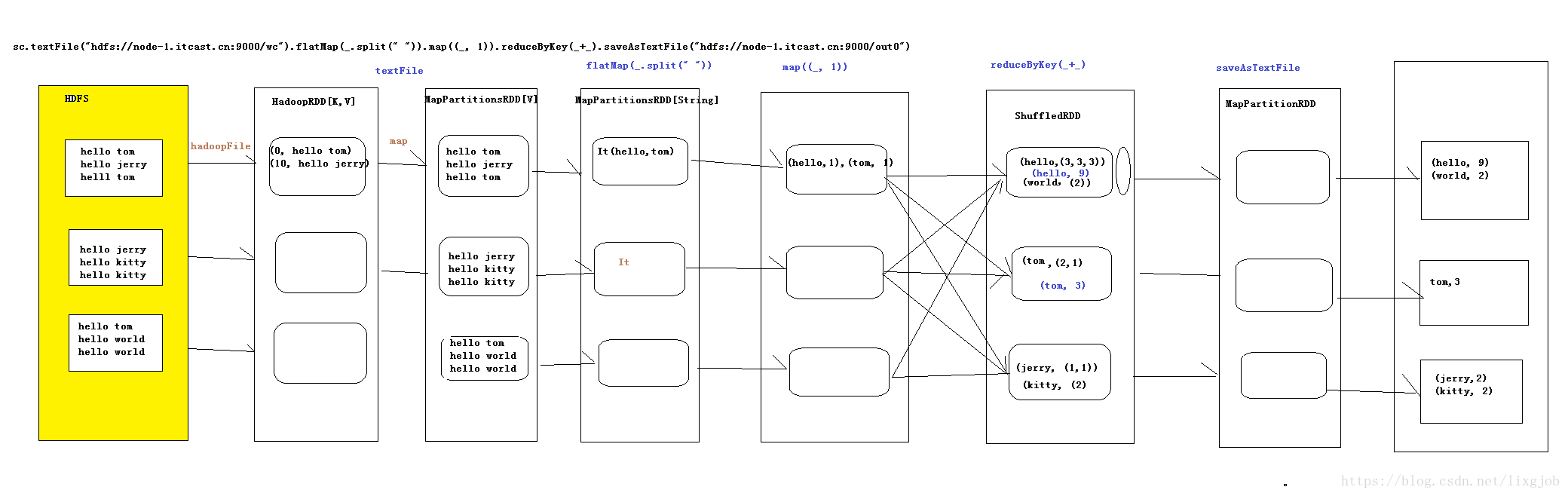
//textFile会产生两个RDD HadoopRDD 和 MapPartitionsRDD
val hadoopRDD: RDD[String] = sc.textFile(path)
//产生一个RDD==>MapPartitionsRDD
val mapPartitionsRDD_1: RDD[String] = hadoopRDD.flatMap(line => line.split(" "))
//产生一个RDD==>MapPartitionsRDD
val mapPartitionsRDD_2: RDD[(String, Int)] = mapPartitionsRDD_1.map(word => (word, 1))
//产生一个RDD==>ShuffledRDD
val shuffleRDD: RDD[(String, Int)] = mapPartitionsRDD_2.reduceByKey((a,b)=>a+b)
shuffleRDD.saveAsTextFile(outpath)
sc.stop()
}
} 

SparkContext--textFile函数
源码过程
| SparkContext.scala | HadoopRDD.scala |
| textFile => hadoopFile=> | HadoopRDD |
HadoopRDD
/**
* Read a text file from HDFS, a local file system (available on all nodes), or any
* Hadoop-supported file system URI, and return it as an RDD of Strings.
*/
def textFile(
path: String,
minPartitions: Int = defaultMinPartitions): RDD[String] = withScope {
assertNotStopped()
hadoopFile(path, classOf[TextInputFormat], classOf[LongWritable], classOf[Text],
minPartitions).map(pair => pair._2.toString).setName(path)
}分析参数:
path: String 是一个URI,這个URI可以是HDFS、本地文件(全部的节点都可以),或者其他Hadoop支持的文件系统URI返回的是一个字符串类型的RDD,也就是是RDD的内部形式是Iterator[(String)]
minPartitions= math.min(defaultParallelism, 2) 是指定数据的分区,如果不指定分区,
当你的核数大于2的时候,不指定分区数那么就是 2
当你的数据大于128M时候,Spark是为每一个快(block)创建一个分片(Hadoop-2.X之后为128m一个block)
def hadoopFile[K, V](
path: String,
inputFormatClass: Class[_ <: InputFormat[K, V]],
keyClass: Class[K],
valueClass: Class[V],
minPartitions: Int = defaultMinPartitions): RDD[(K, V)] = withScope {
assertNotStopped()
// A Hadoop configuration can be about 10 KB, which is pretty big, so broadcast it.
// 广播hadoop配置文件
val confBroadcast = broadcast(new SerializableConfiguration(hadoopConfiguration))
val setInputPathsFunc = (jobConf: JobConf) => FileInputFormat.setInputPaths(jobConf, path)
new HadoopRDD(
this,//SparkContext
confBroadcast,
Some(setInputPathsFunc),
inputFormatClass,
keyClass,
valueClass,
minPartitions).setName(path)
}
1、从当前目录读取一个文件
val path = "Current.txt" //Current fold file
val rdd1 = sc.textFile(path,2)
从当前目录读取一个Current.txt的文件
2、从当前目录读取多个文件
val path = "Current1.txt,Current2.txt," //Current fold file
val rdd1 = sc.textFile(path,2)
从当前读取两个文件,分别是Cuttent1.txt和Current2.txt
3、从本地系统读取一个文件
val path = "file:///usr/local/spark/spark-1.6.0-bin-hadoop2.6/README.md" //local file
val rdd1 = sc.textFile(path,2)
从本地系统读取一个文件,名字是README.md
4、从本地系统读取整个文件夹
val path = "file:///usr/local/spark/spark-1.6.0-bin-hadoop2.6/licenses/" //local file
val rdd1 = sc.textFile(path,2)
从本地系统中读取licenses这个文件夹下的所有文件
這里特别注意的是,比如這个文件夹下有35个文件,上面分区数设置是2,那么整个RDD的分区数是35*2?
這是错误的,這个RDD的分区数不管你的partition数设置为多少时,只要license這个文件夹下的這个文件a.txt
(比如有a.txt)没有超过128m,那么a.txt就只有一个partition。那么就是说只要这35个文件其中没有一个超过
128m,那么分区数就是 35个
5、从本地系统读取多个文件
val path = "file:///usr/local/spark/spark-1.6.0-bin-hadoop2.6/licenses/LICENSE-scala.txt,file:///usr/local/spark/spark-1.6.0-bin-hadoop2.6/licenses/LICENSE-spire.txt" //local file
val rdd1 = sc.textFile(path,2)
从本地系统中读取file:///usr/local/spark/spark-1.6.0-bin-hadoop2.6/licenses/下的LICENSE-spire.txt和LICENSE-scala.txt两个文件。上面分区设置是2,那个RDD的整个分区数是2*2
6、从本地系统读取多个文件夹下的文件(把如下文件全部读取进来)
val path = "/usr/local/spark/spark-1.6.0-bin-hadoop2.6/data/*/*" //local file
val rdd1 = sc.textFile(path,2)
采用通配符的形式来代替文件,来对数据文件夹进行整体读取。但是后面设置的分区数2也是可以去除的。因为一个文件没有达到128m,所以上面的一个文件一个partition,一共是20个。
7、采用通配符,来读取多个文件名类似的文件
比如读取如下文件的people1.txt和people2.txt,但google.txt不读取
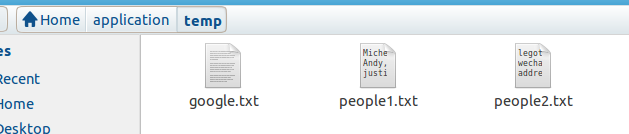
for (i <- 1 to 2){
val rdd1 = sc.textFile(s"/root/application/temp/people$i*",2)
}
8、采用通配符读取相同后缀的文件
val path = "/usr/local/spark/spark-1.6.0-bin-hadoop2.6/data/*/*.txt" //local file
val rdd1 = sc.textFile(path,2)
9、从HDFS读取一个文件
val path = "hdfs://master:9000/examples/examples/src/main/resources/people.txt"
val rdd1 = sc.textFile(path,2)
从HDFS中读取文件的形式和本地上一样,只是前面的路径要表明是HDFS中的
最后
以上就是俊逸黑夜最近收集整理的关于Spark---WC---Spark从外部读取数据之textFile的全部内容,更多相关Spark---WC---Spark从外部读取数据之textFile内容请搜索靠谱客的其他文章。








发表评论 取消回复