
1.motivation
本文也是为了解决multi-source domain adaptation的问题,作者认为以前的MDA方法存在以下的问题:
-
为了学习到domain invariant feature,牺牲了特征提取器的性能;
-
认为多个source domain的贡献是一致的,忽略了不同source domain和target domain之间的不同的discrepancy,
-
认为同一个源域中不同样本贡献是一样的,忽略了不同的样本和target domain的相似性不一样
-
基于adversarial 学习的方式会出现gradient问题,当分类器性能很好的时候(具体可以参见WGAN)
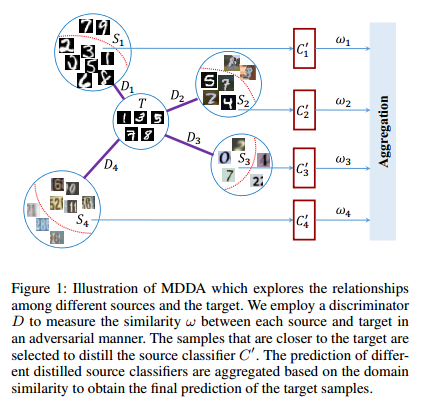
从Figure 1可以看出 S 1 , S 2 S_1, S_2 S1,S2相比 S 3 , S 4 S_3, S_4 S3,S4和 T T T更接近,在 S 2 S_2 S2中不同样本和 T T T的相似性也不同,作者用红线做了区分。
2.Method
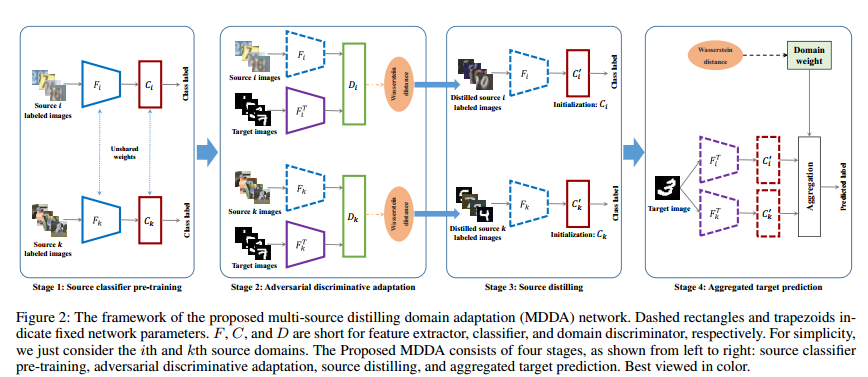
如图2所示,作者提出了multi-source distilling domain adaptation(MDDA) Network. MDDA一共分为四个阶段:
-
Source Classifier Pre-training. 不用于以往的方法使用共享的backbone来提取多个源域的特征,作者认为采用共享的参数会让特征提取关注domain invariant feature从而对损失提取discriminative 的特征的能力。这里对每一个源域都训练一个独立的特征提取器 F i F_i Fi和分类器 C i C_i Ci(没有共享参数)并且采用交叉熵来优化
L c l s ( F i , C i ) = − E ( x i , y i ) ∼ p i 1 [ n = y i ] l o g ( σ ( C i ( F i ( x i ) ) ) ) L_{cls}(F_i, C_i) = -E_{(x_i, y_i)sim p_i}1_{[n=y_i]}log(sigma(C_i(F_i(x_i)))) Lcls(Fi,Ci)=−E(xi,yi)∼pi1[n=yi]log(σ(Ci(Fi(xi)))) -
Adversarial Discriminative Adaptation. 在pre-train阶段后,学习独立的target encoder将特征映射到源域空间 S i S_i Si,不同于以往的方法将所有域都映射到同一个domain。这里将target分别映射到N个source domain,来进行adversarial 的学习,并采用wassertein distance来优化
L w d D ( D i ) = E x i ∼ p i D i ( F i ( x i ) ) − E x T ∼ p T [ D i ( F i T ( x T ) ) ] L w d F ( F i T ) = − E x T ∼ p T D i ( F i T ( x T ) ) L_{wd_D}(D_i) = E_{x_isim p_i}D_i(F_i(x_i)) - E_{x^Tsim p_T}[D_i(F_i^T(x_T))]\ L_{wd_F}(F_i^T)=-E_{x^Tsim p_T}D_i(F_i^T(x_T)) LwdD(Di)=Exi∼piDi(Fi(xi))−ExT∼pT[Di(FiT(xT))]LwdF(FiT)=−ExT∼pTDi(FiT(xT))
target encoder尽量让domain d分辨器 D i D_i Di,通过最小化target的feature和source的feature之间Wasserstein距离。这样不同source domain的target domain之间的差距就可以通过wassertein distance来量化 -
Source distilling. 在distilling 不同域的区别后,作者进一步关注同一个domain中不同样本和target domain之间的差异。也是基于Wassertein distance来选择和target domain接近的样本来finetune 分类器。对于每一个样本 x i j x_i^j xij 在第 i i i个source domain中,计算Wasserstein distance
τ i j = ∣ ∣ D i ( F i ( x j ) ) − 1 N T ∑ k = 1 N T D i ( F i T ( x k ) ) ∣ ∣ tau_i^j=||D_i(F_i(x_j))-frac{1}{N_T}sum_{k=1}^{N_T}D_i(F_i^T(x_k))|| τij=∣∣Di(Fi(xj))−NT1k=1∑NTDi(FiT(xk))∣∣
选择那些距离比较大的样本来finetune
L
d
i
s
t
i
l
l
(
C
i
)
=
−
E
(
x
i
^
,
y
i
^
)
∼
p
i
∑
1
[
n
=
y
i
^
]
l
o
g
(
σ
(
C
i
(
F
i
(
x
i
^
)
)
)
)
L_{distill}(C_i)=-E_{(hat{x_i},hat{y_i})sim p_i}sum1_{[n=hat{y_i}]}log(sigma(C_i(F_i(hat{x_i}))))
Ldistill(Ci)=−E(xi^,yi^)∼pi∑1[n=yi^]log(σ(Ci(Fi(xi^))))
- Aggregated Target Prediction最后在测试阶段,是将target在不同域特征提取器
F
i
T
(
x
T
)
F_i^T(x_T)
FiT(xT) ,在通过finetune的分类器
C
i
′
(
F
i
T
(
x
T
)
)
C_i^{'}(F_i^T(x_T))
Ci′(FiT(xT)) ,最后将所有的结果加权
R e s u l t ( x T ) = ∑ i = 1 N ω i C i ′ ( F i T ( x T ) ) ω i = e − L w d D i 2 2 Result(x_T)=sum_{i=1}^Nomega_iC_i^{'}(F_i^T(x_T))\ omega_i=e^{frac{-L^2_{wd_{D_i}}}{2}} Result(xT)=i=1∑NωiCi′(FiT(xT))ωi=e2−LwdDi2
Experiment
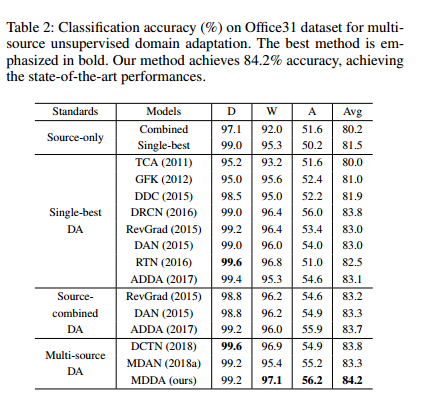
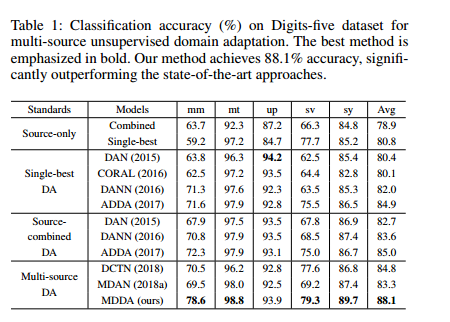
ablation study
- visualization

target domain的feature 变得更加的dense(红色部分)了(并且target和source domain分布更加接近
- weighting strategy
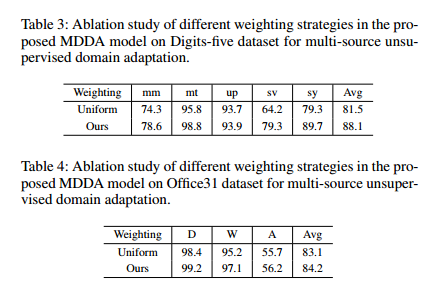
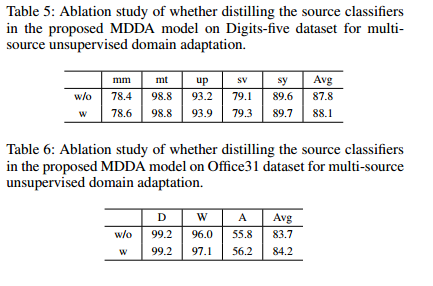
- source distilling for fine-tuning
对比可以看到其实不同域对target影响是远远大于 在同一个域里面不同样本的影响
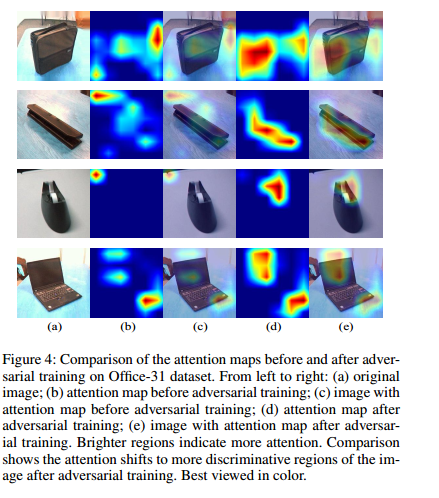
通过adversial 训练之后模型更加关注物体 学习到了domain invariant的特征
感想:
感觉论文表达的意思还是很直接的,也是target domain的分布用source domain的加权分布来逼近,不同的是每一个source domain都训练一个discriminator和特征提取器,并且用wassestein loss类训练,并且作为后续combine的依据。还加入同一个域不同样本的finetune. bonus是加入了一些可视化的解释。
最后
以上就是聪明红牛最近收集整理的关于Multi-source Distilling Domain Adaptation的全部内容,更多相关Multi-source内容请搜索靠谱客的其他文章。








发表评论 取消回复