Data2Text Studio从结构化数据生成自动文本
原文链接:https://pdfs.semanticscholar.org/79dd/2ee41e4a7de3b3142fea43b8c48d20224ef2.pdf
摘要
Data2Text Studio是一个从结构化数据生成自动文本的平台。 它配备了Semi-HMMs模型,可以自动从并行数据中提取高质量的模板和相应的触发条件,从而提高生成文本的交互性和可解释性。 此外,还为开发人员提供了几种易于使用的工具来编辑预先训练的模型模板,并且发布API以供开发人员调用预先训练的模型以在第三方应用程序中生成文本。 我们在ROTOWIRE数据集上进行实验,以进行模板提取和文本生成。 结果表明,我们的模型在两个任务上都实现了改进。
简介
数据到文本生成是一种将结构化数据作为输入并生成充分和流利地描述该数据的文本作为输出的技术,在生成体育新闻(Chen and Mooney, 2008; Kim and Mooney, 2010; Mei et al., 2016; Wiseman et al., 2017), 产品说明 (Wang et al., 2017), 天气报告(Liang et al., 2009; Angeli et al., 2010; Mei et al., 2016) 和短传记 (Lebret et al., 2016; Chisholm et al., 2017)等方面具有各种应用。在另一种情况下,像Microsoft Cortana这样的虚拟助手在回复用户查询时显示出结构化数据可能有点尴尬。 虚拟助手以自然语言识别和显示出结构化数据的基本部分,使其更易于理解,这对用户更友好。 在这些情况下,使用人类作者生成文本是低效且昂贵的,而自动文本生成系统将是有帮助的。
数据到文本生成系统存在两个主要挑战:1)交互性:对于开发人员,它应该能够自定义文本生成模型并控制生成的文本。 2)可解释性:生成的文本应与结构化数据一致。例如,对于笔记本电脑,我们可以说“带有8GB的大容量内存”,而“2GB的大容量”是不合适的。基于规则的方法(Moore和Paris,1993; Hovy,1993; Reiter and Dale,2000; Belz,2007; Bouayad-Agha等,2011)将领域知识编码到生成系统中,然后生成高质量的文本,同时系统的构建是昂贵的,并且在很大程度上取决于领域专家。统计方法通过从历史数据中学习规则来采用来减少大规模的开发时间(Langkilde and Knight,1998; Liang等,2009; Duboue和McKeown,2003; Howald等,2013)。但是,统计方法容易产生错误的文本,因为他们不知道如何在各种应用条件下使用特定短语。
为了解决第二个挑战,我们提出了一种Semi-HMM模型,用于从并行训练数据中自动提取模板和相应的触发条件。触发条件是配对的结构化数据和文本之间的明确的潜在语义注释,其支持学习如何在特定条件下使用特定短语,然后与传统的基于模板的方法相比提高生成的文本的交互性和可解释性。更重要的是,与其他商业系统相比,从对齐分布自动获得文本生成触发条件可以显着减少人工编辑工作量。 例如,尽管WordSmith提供了帮助开发人员创建模板和生成规则的功能工具,但仍需要手动创建规则。
对于第一个挑战,我们演示了Data2Text Studio,这是一个配备了所提出的Semi-HMMs模型的强大平台,可以帮助开发人员在他们自己的应用程序中从结构化数据生成文本。目前,该系统提供了几个涵盖不同领域的预训练模型:体育标题生成,简历生成,产品描述生成等。开发人员还可以通过上传并行数据来训练他们自己的模型。 在模型培训之后,开发人员可以修改模型,预览生成的文本或调用API以在第三方应用程序中生成文本。 所有流程都简单友好。
我们对ROTOWIRE数据集(Wiseman等,2017)进行了实验,以评估模板提取和整体文本生成的性能。 结果表明,我们的模型在两个任务上都实现了改进。 本文的其余部分组织如下:第2节描述了Data2Text Studio的体系结构。 第3节提出了主要算法。 第4节显示了实验结果。
Data2Text Studio的体系结构
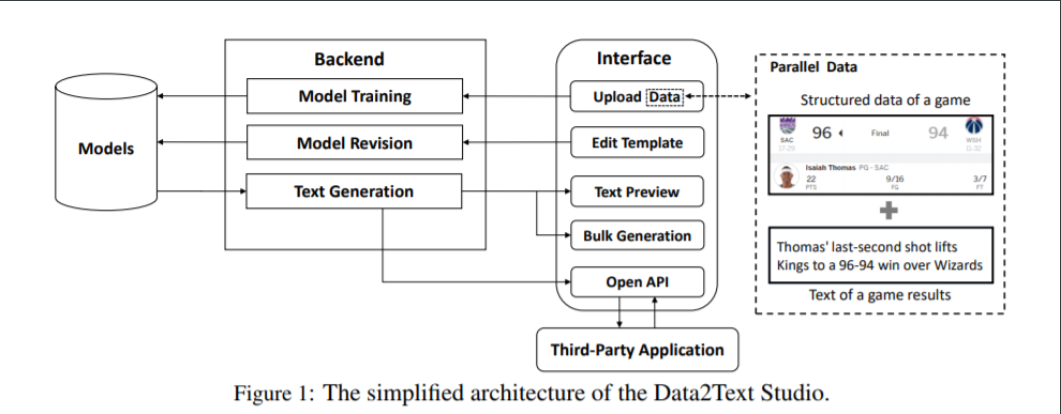
图1显示了Data2Text Studio的简化架构。 它主要由三部分组成:1)模型训练,2)模型修正,3)文本生成。 对于典型用法,开发人员可以直接选择预先训练的模型来生成高质量的文本。 开发定制的文本生成模型:首先,开发人员需要上传由文本和相应的结构化数据组成的并行数据来训练模型,然后训练组件将自动从训练数据中提取模板和相应的触发条件; 其次,开发人员可以利用内置工具进一步自主修改提取的模板和触发条件; 最后,开发人员可以预览自定义模型的生成文本,并提供API以批量生成文本或在第三方应用程序中生成文本。 在下文中,我们将详细介绍这些模块。
模型训练
我们为Data2Text Studio采用基于模板的解决方案。 它可以生成高精度和流畅的文本,可以直接用于商业应用。 之前的几项研究(Liang et al., 2009; Wang et al., 2017; Kondadadi et al., 2013) 可用于从并行数据中提取模板。 为了解决第1节中提出的挑战,我们提出了一种半HMM模型,用于从并行数据中提取模板和相应的触发条件(参见第3.1节的算法)。 图2显示了来自NBA标题并行数据的提取模板的示例,其中包括记分板和相应的新闻。

模型修正
经过训练的模型为开发人员提供了一个更好的起点,可以避免从头开始创建模型。 如有必要,开发人员可以通过编辑提取的模板及其相应的触发条件来修改训练模型。 图3a显示了模板编辑的界面。
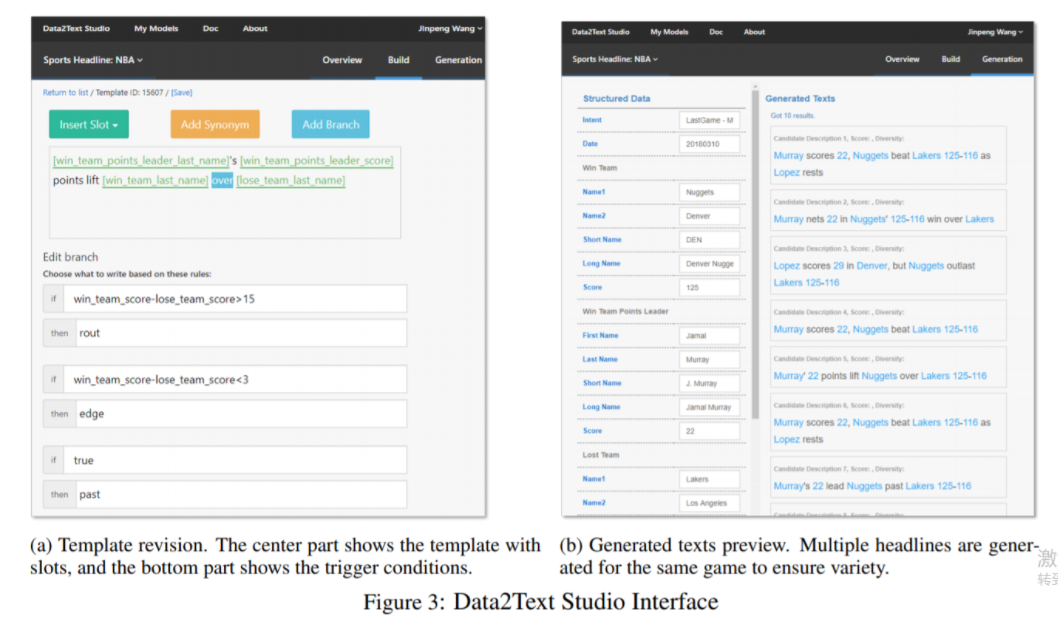
设计了三种机制来管理模板和相应的触发条件:1)数据槽:输入结构化数据将填入槽中以生成文本。 2)同义词:它由短语列表构成,其中一个将在生成过程中随机选择。 3)分支:定义特定短语的使用场景的触发条件。 我们在3.1节中的半HMM模型可以自动学习这些数据槽和触发条件。 同时,如有必要,开发人员也可以修改它们。
文本生成
给定结构化数据,系统将使用训练的模型生成相应的文本。 图3b显示了NBA标题生成的示例。 左侧显示包含比赛属性的输入结构化数据。 右侧显示了此比赛的多个生成文本,以帮助开发人员检查生成的文本的质量。
第三方应用程序的API
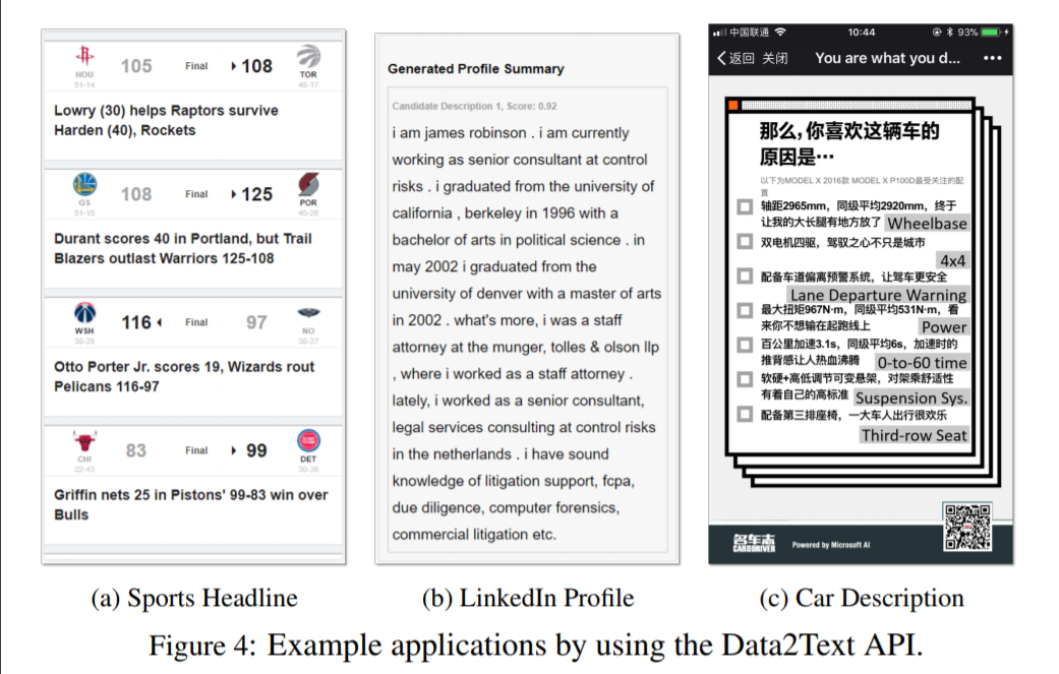
要在第三方应用程序中使用文本生成服务,需要为每个训练模型创建一个API。 一旦通过API发布结构化数据,系统将自动将生成的文本传递回第三方应用程序。 通过这种方式,开发人员可以将开发工作留给Data2Text Studio中的文本生成模型。 图4显示了三种应用场景:体育标题生成,基于LinkedIn数据的用户配置文件生成和汽车评价生成。
算法
在本节中,我们介绍了提出的用于模板提取和相应的触发条件挖掘的算法。
模板提取
模板提取的主要挑战是文本和结构化数据之间的对齐。 我们采用Liang等人(2009)给出的模型,该模型提供了一个3层HMM,可以自动将单词与结构化数据字段对齐。 这些对齐的单词可以是字符串,如品牌名称,也可以是从数据中复制的数字。
另一个挑战是词汇选择,它指的是选择适合语境的词来表达非语言数据。 例如,在篮球比赛报告中,作者倾向于仅在得分差异非常大时才使用blow out。词汇选择非常微妙,并且因作者而异,因此我们使用数据中从单词到数字的高斯发射概率(a Gaussian emission probability from words to numbers )来丰富对齐模型。
在Liang等人的原始模型中,垃圾收集问题是严重的,这意味着大多数单词错误地与应该保持不对齐的不频繁字段对齐(i.e, aligned to null) 。在这里,我们结合了Graca等人提出的后验正则化,它可以在具有潜在变量的模型中添加约束,同时保持模型易于处理。在实践中,我们设置了未对齐单词数量的下限,这可以显着减轻垃圾收集问题。

我们推导出期望最大化(EM)算法以执行最大似然估计,并引入软统计正则化以指导模型朝向更好的解决方案。 具体来说,我们为未对齐的单词设计了一个特殊的NULL标记,我们“鼓励”它注释至少一半的单词。有关详细信息请参阅《Learning Latent Semantic Annotations for Grounding Natural Language to Structured Data》。
触发机制
如3.1中所提出的,我们使用高斯分布来模拟数值和短语之间的对齐概率。因此,我们的模型不仅可以告诉我们这个词的来源,还可以告诉我们它与之对齐的数字的分布。例如,在训练之后,我们的模型成功地将“blow out”与分数差异对齐,并且表明当使用此短语时,分数差异的平均值为17。有了这些信息,我们可以在对齐的单词上设置“触发器”。 触发器是一种确定在何种条件下可以使用何种模板的方案。 例如,只有在得分差异大约为17时才能使用与“得分差异”对齐的“blow out”模板,其中blow out的概率高于defeated的概率。 所以我们可以得到这样的规则:

有了这样的规则,我们的模型将能够在各种条件下使用不同的单词。
现在模板和触发器已经可以使用,对于文本生成,我们在相应的适用触发条件下使用结构化数据填充模板。
实验
在本节中,我们将报告所提出的模型在模板提取和整体文本生成方面的性能,两者都在Wiseman数据集的ROTOWIRE子集上进行评估。
模板提取评估
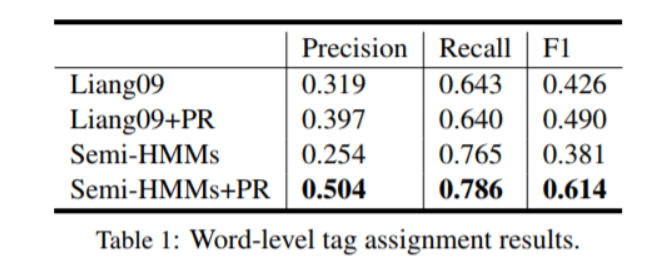
我们可以观察到,我们的初始模型在回忆中确实优于基线系统,而后正则化有助于在不牺牲召回性能的情况下避免来自应该被标记为NLL的无关信息的干扰。
整体文本生成评估
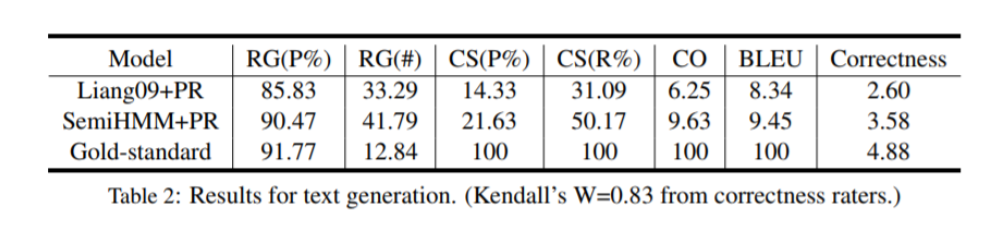
我们还使用第3.2节中描述的相同启发式方法与基线进行比较,测试整个文本生成中提取模板的性能。为了生成文档级文本,我们首先生成一个描述每场比赛的得分线结果的句子,然后是三个描述团队绩效的其他信息的句子。在保持不重复使用模板的同时,我们选择按其比赛得分排序的前十名玩家得分最高的模板。我们报告自动指标,包括BLEU得分和基于Wiseman提出的关系提取的指标:精确度和生成中的唯一关系数(RG),内容选择(CS)的精确度和召回率以及内容排序(CO)得分。除了NLG中各方面的这些自动指标外,我们还对信息正确性进行人工评估(1-5级评级,越高越好)。我们要求四位精通英语并熟悉篮球的人类评估者对30场随机比赛的输出进行评分。结果显示在表2中,其中Kendall的W测量了注释器间的一致性。我们可以观察到,从我们的模型派生的模板确实胜过基线系统的模板。
结论和未来的工作
总而言之,Data2Text Studio是一个从结构化数据生成自动文本的平台。它不仅提供了几种预先训练的模型,可以从数据生成高质量的文本,而且通过上传并行数据很容易训练新模型。 此外,该系统还配备了所提出的半HMMs模型,该模型可以自动从并行数据中提取模板和相应的触发条件,并支持学习如何在特定条件下使用特定短语。 ROTOWIRE数据集上的实验结果表明,所提出的模型优于模板提取和文本生成的基线。
在未来,我们将在数据域和文本保真度方面将更强大的预训练模型集成到该系统中。 对于模板提取模型,我们将学习更复杂的接地规则以增强模型能力。
最后
以上就是满意蛋挞最近收集整理的关于Data2Text Studio: Automated Text Generation from Structured Data 论文笔记Data2Text Studio从结构化数据生成自动文本的全部内容,更多相关Data2Text内容请搜索靠谱客的其他文章。








发表评论 取消回复