先讲使用,再讲原理
队列是遵循先进先出(First-In-First-Out)模式的,但有时需要在队列中基于优先级处理对象。
举两个例子:
- 作业系统中的调度程序,当一个作业完成后,需要在所有等待调度的作业中选择一个优先级最高的作业来执行,并且也可以添加一个新的作业到作业的优先队列中。
- 每日交易时段生成股票报告的应用程序中,需要处理大量数据并且花费很多处理时间。客户向这个应用程序发送请求时,实际上就进入了队列。我们需要首先处理优先客户再处理普通用户。在这种情况下,Java的PriorityQueue(优先队列)会很有帮助。
PriorityQueue类在Java1.5中引入并作为 Java Collections Framework 的一部分。PriorityQueue是基于优先堆的一个无界队列,这个优先队列中的元素可以默认自然排序或者通过提供的Comparator(比较器)在队列实例化的时排序。
优先队列不允许空值,而且不支持non-comparable(不可比较)的对象,比如用户自定义的类。优先队列要求使用Java Comparable和Comparator接口给对象排序,并且在排序时会按照优先级处理其中的元素。
优先队列的头是基于自然排序或者Comparator排序的最小元素。如果有多个对象拥有同样的排序,那么就可能随机地取其中任意一个。当我们获取队列时,返回队列的头对象。
优先队列的大小是不受限制的,但在创建时可以指定初始大小。当我们向优先队列增加元素的时候,队列大小会自动增加。
PriorityQueue是非线程安全的,所以Java提供了PriorityBlockingQueue(实现BlockingQueue接口)用于Java多线程环境。
我们有一个用户类Customer,它没有提供任何类型的排序。当我们用它建立优先队列时,应该为其提供一个比较器对象。
Customer.java
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
|
我们使用Java随机数生成随机用户对象。对于自然排序,我们使用Integer对象,这也是一个封装过的Java对象。
下面是最终的测试代码,展示如何使用PriorityQueue:
PriorityQueueExample.java
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
|
注意我用实现了Comparator接口的Java匿名类,并且实现了基于id的比较器。
当我运行以上测试程序时,我得到以下输出:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
从输出结果可以清楚的看到,最小的元素在队列的头部因而最先被取出。如果不实现Comparator,在建立customerPriorityQueue时会抛出ClassCastException。
| 1 2 3 4 5 6 7 |
|
实现原理:
Java中PriorityQueue通过二叉小顶堆实现,可以用一棵完全二叉树表示(任意一个非叶子节点的权值,都不大于其左右子节点的权值),也就意味着可以通过数组来作为PriorityQueue的底层实现。
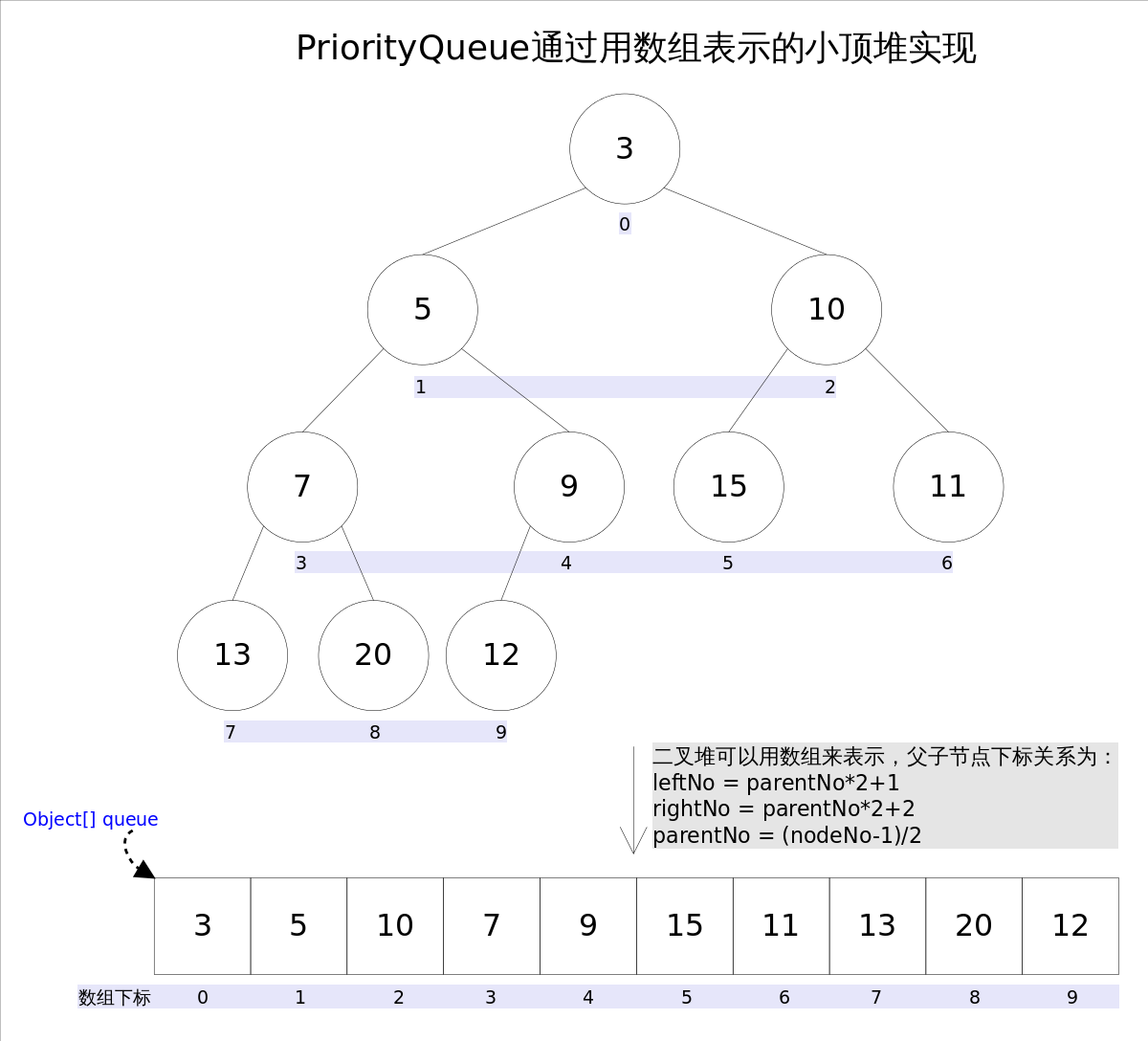
上图中我们给每个元素按照层序遍历的方式进行了编号,如果你足够细心,会发现父节点和子节点的编号是有联系的,更确切的说父子节点的编号之间有如下关系:
leftNo = parentNo*2+1
rightNo = parentNo*2+2
parentNo = (nodeNo-1)/2
通过上述三个公式,可以轻易计算出某个节点的父节点以及子节点的下标。这也就是为什么可以直接用数组来存储堆的原因。
PriorityQueue的peek()和element操作是常数时间,add(), offer(), 无参数的remove()以及poll()方法的时间复杂度都是log(N)。
方法剖析
add()和offer()
add(E e)和offer(E e)的语义相同,都是向优先队列中插入元素,只是Queue接口规定二者对插入失败时的处理不同,前者在插入失败时抛出异常,后则则会返回false。对于PriorityQueue这两个方法其实没什么差别。
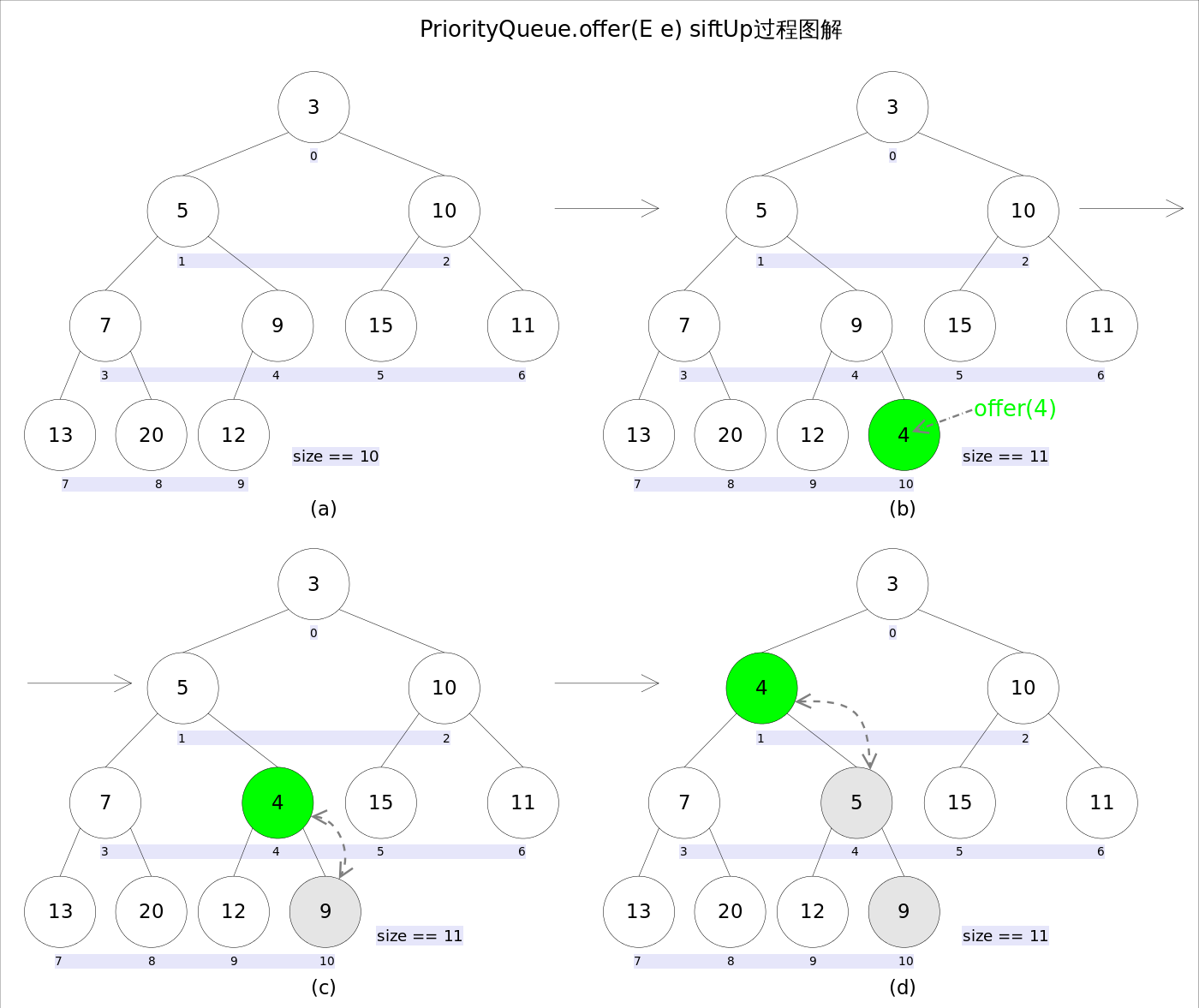
新加入的元素可能会破坏小顶堆的性质,因此需要进行必要的调整。
//offer(E e)
public boolean offer(E e) {
if (e == null)//不允许放入null元素
throw new NullPointerException();
modCount++;
int i = size;
if (i >= queue.length)
grow(i + 1);//自动扩容
size = i + 1;
if (i == 0)//队列原来为空,这是插入的第一个元素
queue[0] = e;
else
siftUp(i, e);//调整
return true;
}上述代码中,扩容函数grow()类似于ArrayList里的grow()函数,就是再申请一个更大的数组,并将原数组的元素复制过去,这里不再赘述。需要注意的是siftUp(int k, E x)方法,该方法用于插入元素x并维持堆的特性。
//siftUp()
private void siftUp(int k, E x) {
while (k > 0) {
int parent = (k - 1) >>> 1;//parentNo = (nodeNo-1)/2
Object e = queue[parent];
if (comparator.compare(x, (E) e) >= 0)//调用比较器的比较方法
break;
queue[k] = e;
k = parent;
}
queue[k] = x;
}新加入的元素x可能会破坏小顶堆的性质,因此需要进行调整。调整的过程为:从k指定的位置开始,将x逐层与当前点的parent进行比较并交换,直到满足x >= queue[parent]为止。注意这里的比较可以是元素的自然顺序,也可以是依靠比较器的顺序。
element()和peek()
element()和peek()的语义完全相同,都是获取但不删除队首元素,也就是队列中权值最小的那个元素,二者唯一的区别是当方法失败时前者抛出异常,后者返回null。根据小顶堆的性质,堆顶那个元素就是全局最小的那个;由于堆用数组表示,根据下标关系,0下标处的那个元素既是堆顶元素。所以直接返回数组0下标处的那个元素即可。
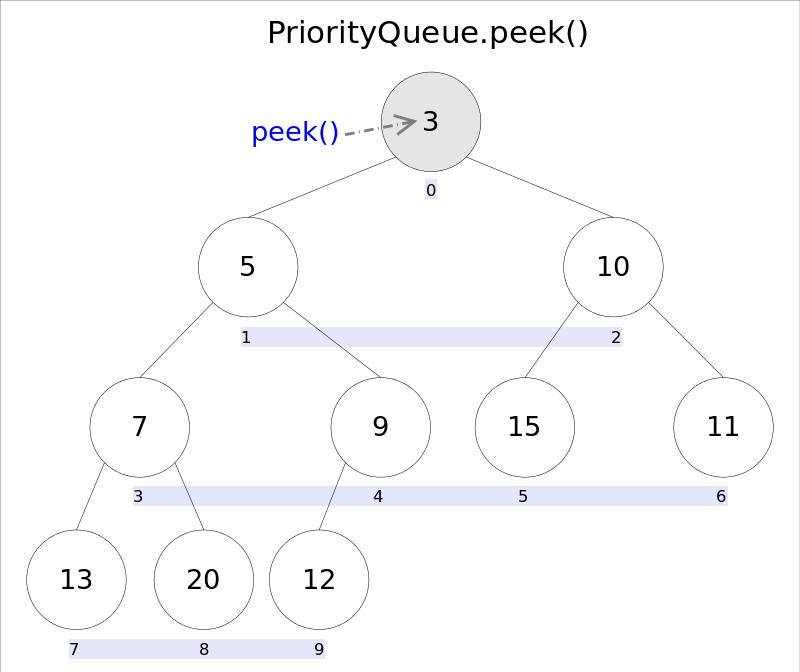
代码也就非常简洁:
//peek()
public E peek() {
if (size == 0)
return null;
return (E) queue[0];//0下标处的那个元素就是最小的那个
}remove()和poll()
remove()和poll()方法的语义也完全相同,都是获取并删除队首元素,区别是当方法失败时前者抛出异常,后者返回null。由于删除操作会改变队列的结构,为维护小顶堆的性质,需要进行必要的调整。
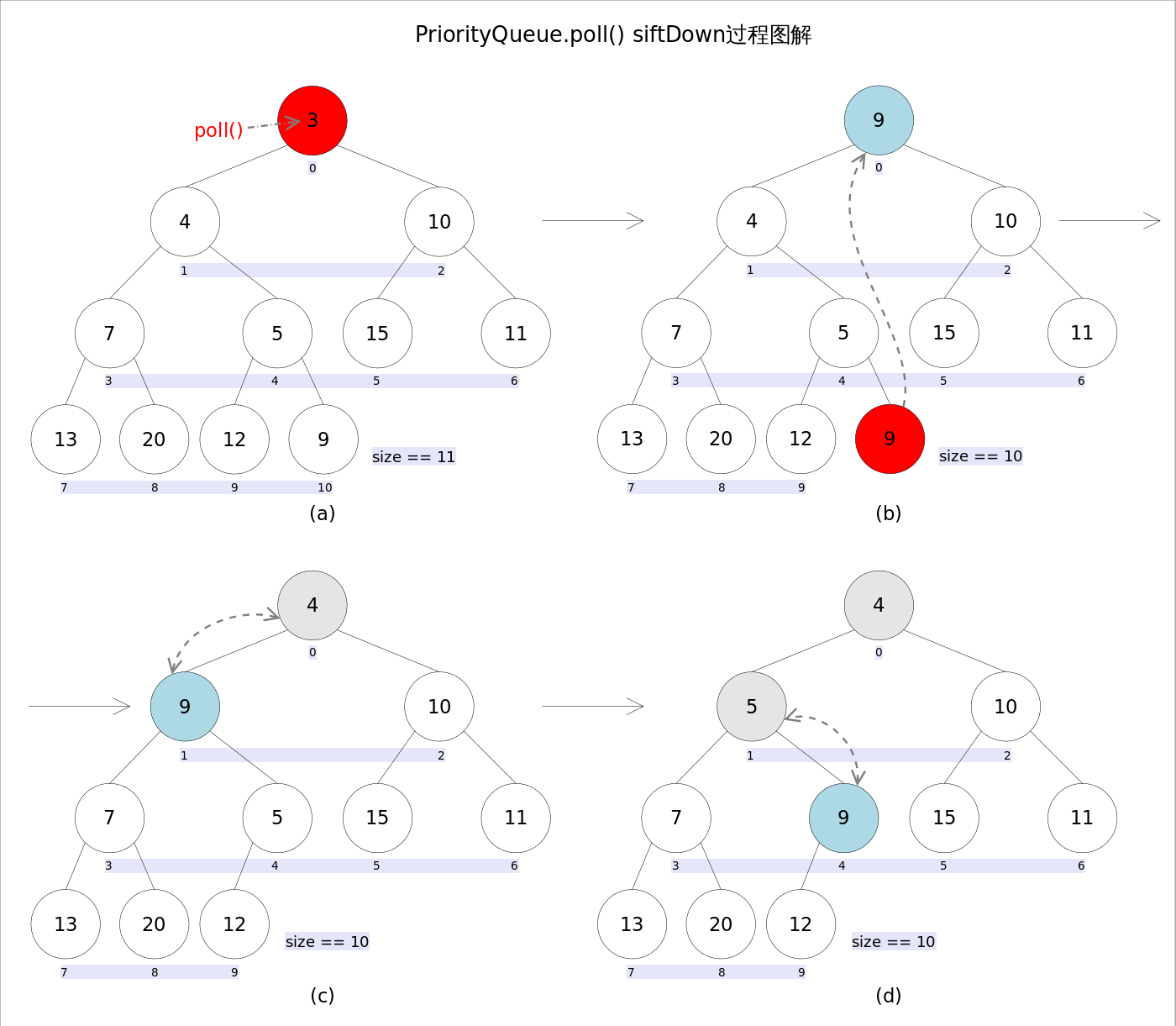
代码如下:
public E poll() {
if (size == 0)
return null;
int s = --size;
modCount++;
E result = (E) queue[0];//0下标处的那个元素就是最小的那个
E x = (E) queue[s];
queue[s] = null;
if (s != 0)
siftDown(0, x);//调整
return result;
}上述代码首先记录0下标处的元素,并用最后一个元素替换0下标位置的元素,之后调用siftDown()方法对堆进行调整,最后返回原来0下标处的那个元素(也就是最小的那个元素)。重点是siftDown(int k, E x)方法,该方法的作用是从k指定的位置开始,将x逐层向下与当前点的左右孩子中较小的那个交换,直到x小于或等于左右孩子中的任何一个为止。
//siftDown()
private void siftDown(int k, E x) {
int half = size >>> 1;
while (k < half) {
//首先找到左右孩子中较小的那个,记录到c里,并用child记录其下标
int child = (k << 1) + 1;//leftNo = parentNo*2+1
Object c = queue[child];
int right = child + 1;
if (right < size &&
comparator.compare((E) c, (E) queue[right]) > 0)
c = queue[child = right];
if (comparator.compare(x, (E) c) <= 0)
break;
queue[k] = c;//然后用c取代原来的值
k = child;
}
queue[k] = x;
}remove(Object o)
remove(Object o)方法用于删除队列中跟o相等的某一个元素(如果有多个相等,只删除一个),该方法不是Queue接口内的方法,而是Collection接口的方法。由于删除操作会改变队列结构,所以要进行调整;又由于删除元素的位置可能是任意的,所以调整过程比其它函数稍加繁琐。具体来说,remove(Object o)可以分为2种情况:1. 删除的是最后一个元素。直接删除即可,不需要调整。2. 删除的不是最后一个元素,从删除点开始以最后一个元素为参照调用一次siftDown()即可。此处不再赘述。
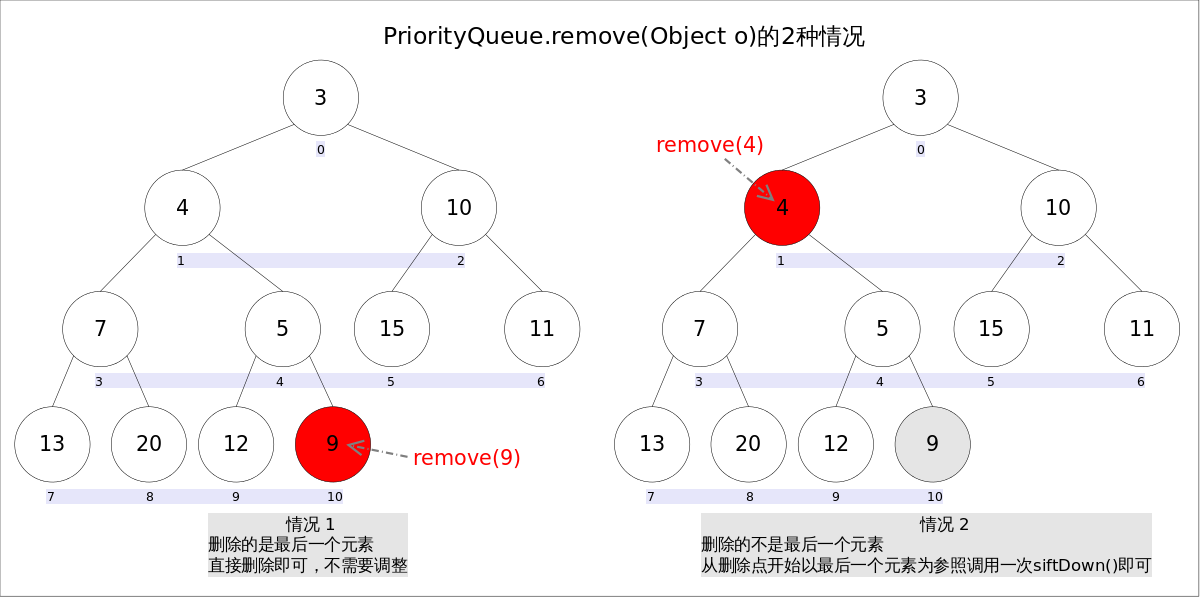
具体代码如下:
//remove(Object o)
public boolean remove(Object o) {
//通过遍历数组的方式找到第一个满足o.equals(queue[i])元素的下标
int i = indexOf(o);
if (i == -1)
return false;
int s = --size;
if (s == i) //情况1
queue[i] = null;
else {
E moved = (E) queue[s];
queue[s] = null;
siftDown(i, moved);//情况2
......
}
return true;
}参考文献:
https://www.cnblogs.com/CarpenterLee/p/5488070.html
http://www.importnew.com/6932.html
最后
以上就是老实小懒虫最近收集整理的关于PriorityQueue的用法和底层实现原理先讲使用,再讲原理实现原理:方法剖析的全部内容,更多相关PriorityQueue内容请搜索靠谱客的其他文章。








发表评论 取消回复