我是靠谱客的博主 执着枫叶,这篇文章主要介绍缩尾处理(winsorize)-数据分析、数据处理原理浅析一个例子说清楚怎么用Python实现一个正态分布缩尾处理的例子see also,现在分享给大家,希望可以做个参考。
文章目录
- 原理浅析
- 一个例子说清楚怎么用Python实现
- 一个正态分布缩尾处理的例子
- see also
原理浅析
和经常听到的“去掉一个最低分去掉一个最高分”操作类似,缩尾处理相当于对数据进行掐头(尾)去尾,然后再按照一定的方法填补被掐掉的数据。需要注意的是,缩尾处理并不是掐掉指定个数的数据,而是按照比例,比方说删掉前10%和后20%的数据。
一个例子说清楚怎么用Python实现
话不多说,直接搬运scipy.stats.mstats.winsorize
一个例子说的清清楚楚,而且还把轮子也搬出来了。Python调个包就能用了
>>> from scipy.stats.mstats import winsorize
>>> import numpy as np
>>> a = np.array([10, 4, 9, 8, 5, 3, 7, 2, 1, 6])
>>> winsorize(a, limits=[0.1, 0.2])
masked_array(data=[8, 4, 8, 8, 5, 3, 7, 2, 2, 6],
mask=False,
fill_value=999999)
代码注释:
- 将一个从1到10的数组的顺序打乱,得到a
- 掐掉最小的10%的数据,同时用2去替换
- 掐掉最大的20%的数据,同时用8去替换
一个正态分布缩尾处理的例子
import numpy as np
from scipy.stats.mstats import winsorize
import matplotlib.pyplot as plt
np.random.seed(12345)
data = np.random.standard_normal(12345)
data_winsorize = winsorize(data, limits=[0.025, 0.025])
lower_band = np.percentile(data, 2.49) # 避开临界点
upper_band = np.percentile(data, 97.51) # 避开临界点
bins = [min(data), lower_band, -1, 0, 1, upper_band, max(data)] # 注意区间是左闭右开,所以要避开临界点
plt.hist(
data,
# alpha=0.15,
label='data',
bins=bins,
color='b'
)
plt.figure()
plt.hist(
np.array(data_winsorize),
# alpha=0.15,
label='data_winsorize',
bins=bins,
color='r'
)
plt.legend()
结果如图所示
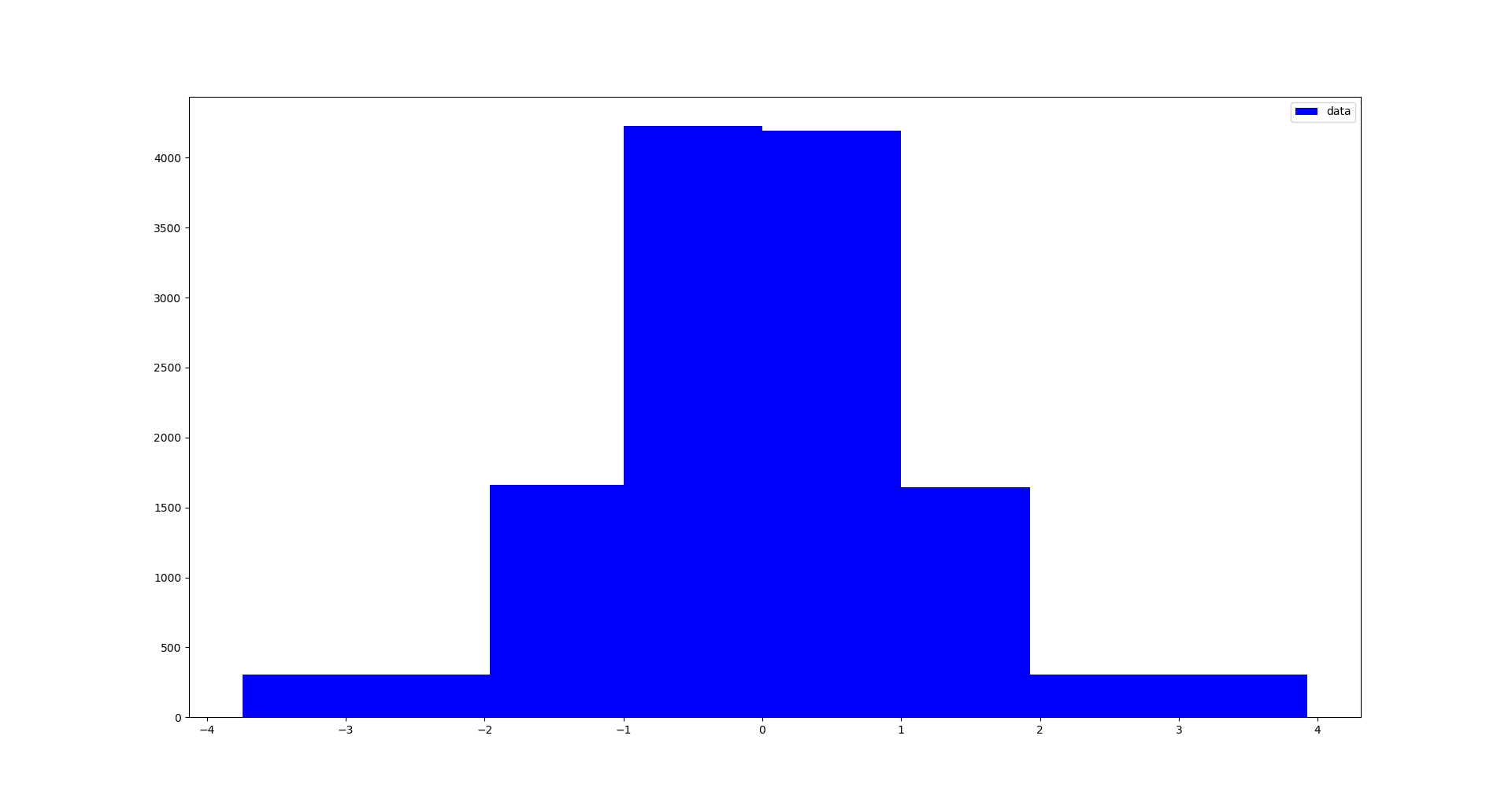
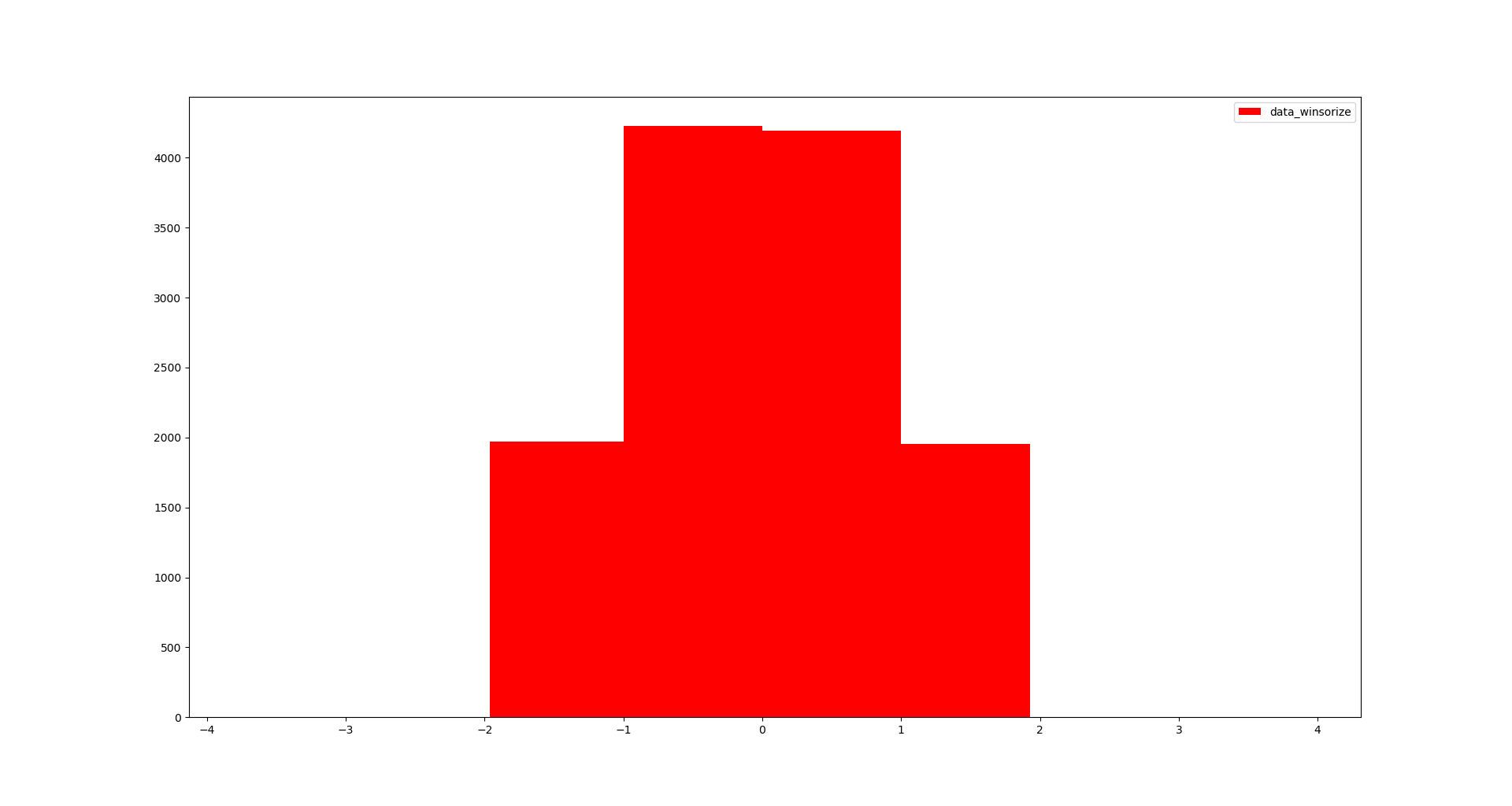
see also
- SciPy专栏
- 时间序列特征提取
- sklearn/scikit-learn孤立森林(IsolationForest)中decision_function和score_samples函数的区别和联系
最后
以上就是执着枫叶最近收集整理的关于缩尾处理(winsorize)-数据分析、数据处理原理浅析一个例子说清楚怎么用Python实现一个正态分布缩尾处理的例子see also的全部内容,更多相关缩尾处理(winsorize)-数据分析、数据处理原理浅析一个例子说清楚怎么用Python实现一个正态分布缩尾处理的例子see内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复