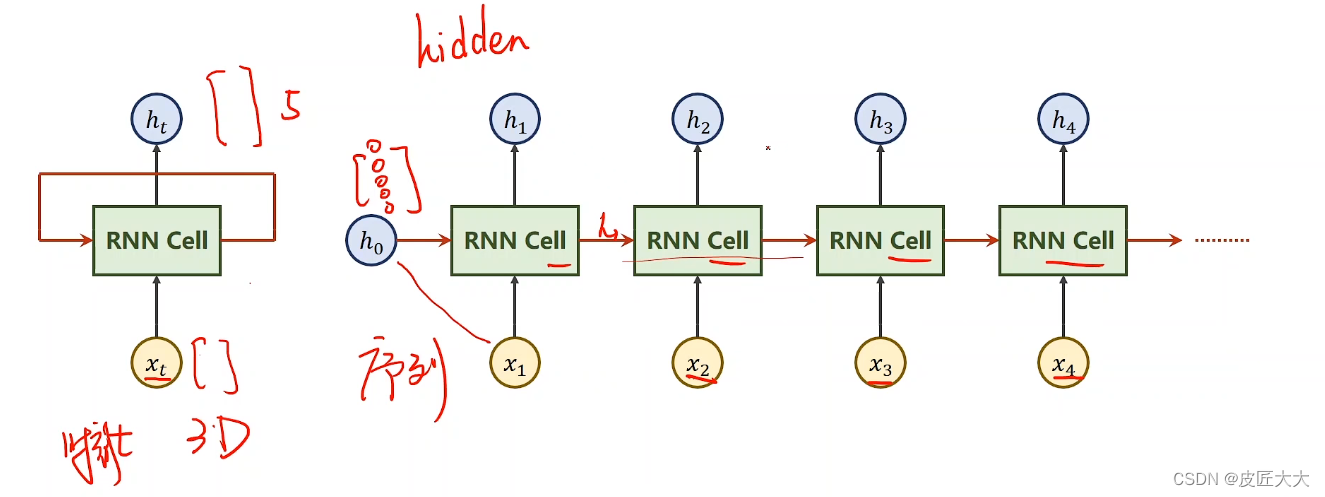
RNN计算过程
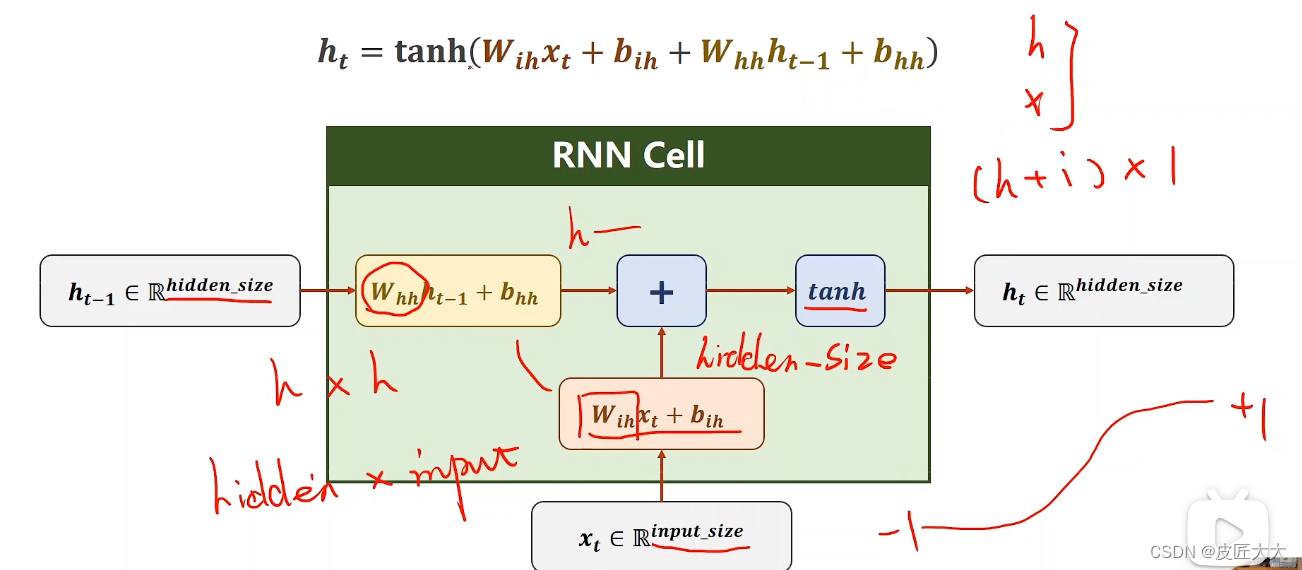
RNNcell的具体计算过程
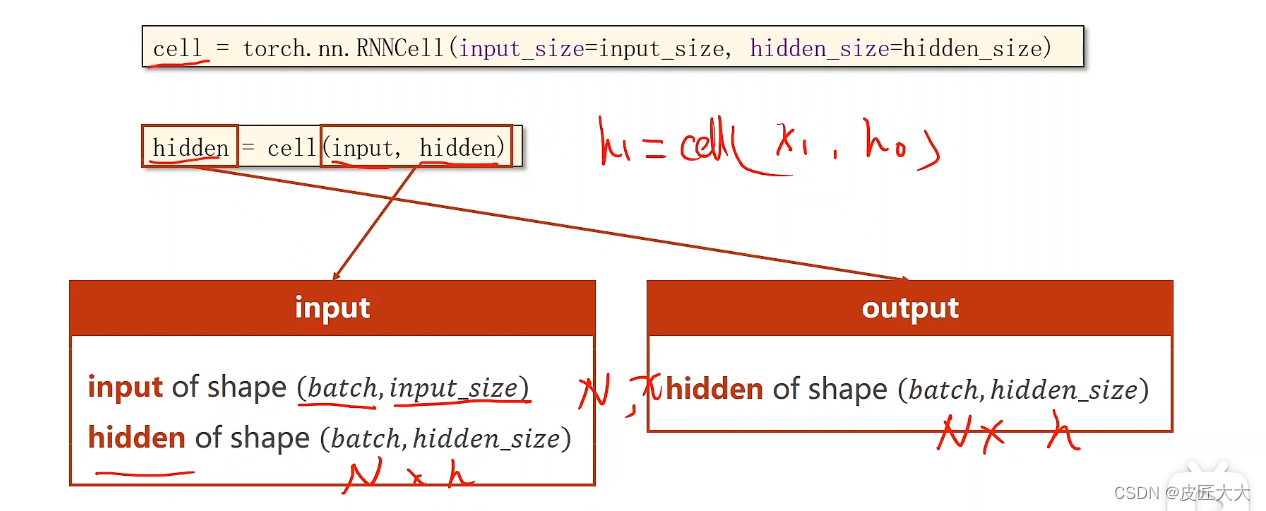
pytorch中构建RNN的第一种方法:RNNcell:
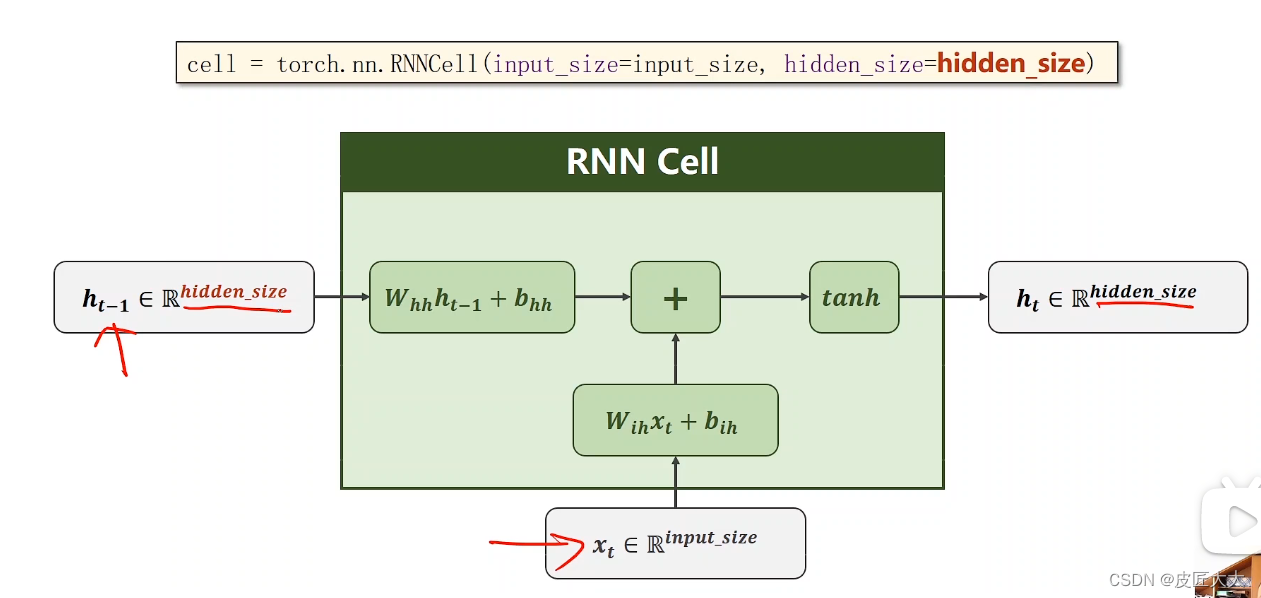
- 初始化定义的时候,只有两个参数:input_size、hidden_size
- 实际使用的时候,也有两个参数,input张量、hidden张量
其中input张量的大小为batch_size * input_size
hidden张量的大小为batch_size * hidden_size
返回值为一个新的hidden张量,大小为batch_size * hidden_size
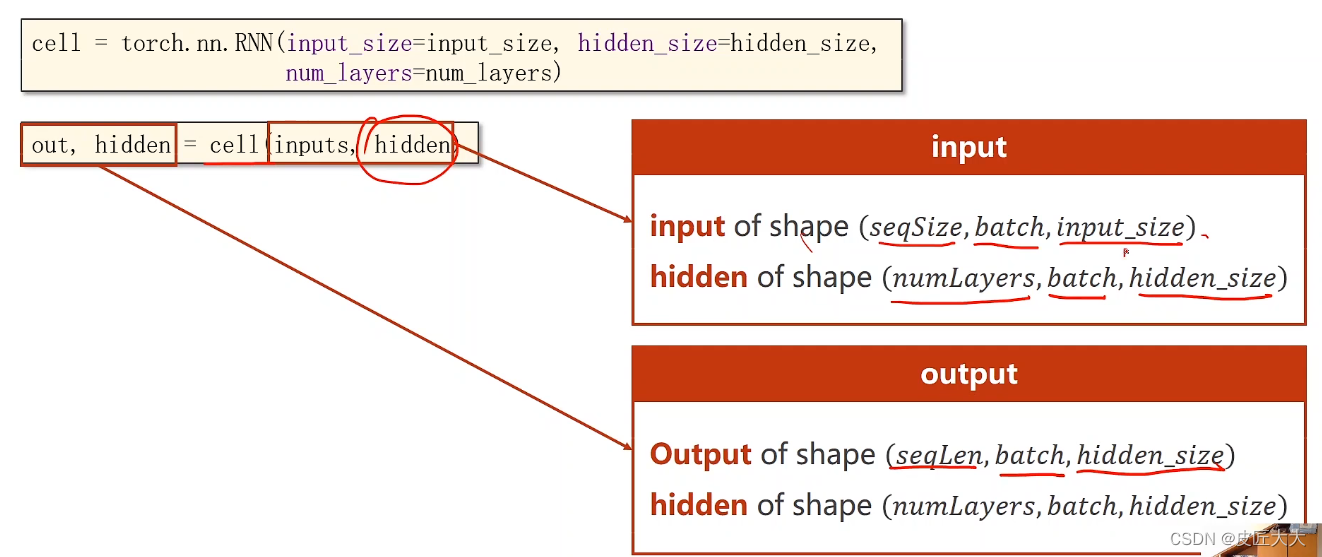
pytorch中构建RNN的第二种方法:RNN:
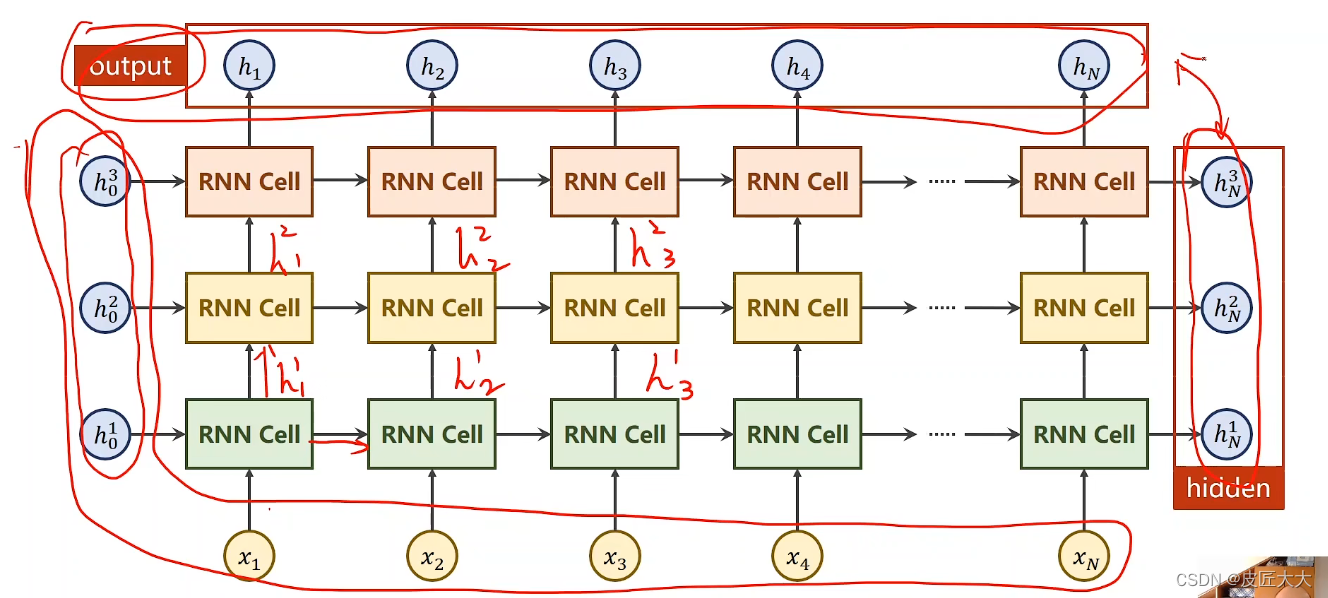
- 构造初始化时,参数有3个:input_size、hidden_size、num_layers(有多少个RNNcell层)
!!!注意numlayers和seqSize的区别:
1. numlayers是指RNNcell处理的层数(比如下图中的RNNcell只有一行,那就只有一层),不是RNNcell的个数
2. seqSize是指自变量x的个数,比如一句话有多少个token - 实际调用时:
- 有两个输入参数,input张量、hidden张量
input张量的大小为(seqSize * Batch * input_size)
hidden张量的大小为(numlayers * batch * hidden_size) - 有两个输出参数,output张量、hidden张量
output张量对应h1 - hn的所有hidden张量的综合(大小为:seqSize * batch * hidden_size )
hidden张量就是最后的hn张量(大小为:num_layers * batch * hidden_size)
- 有两个输入参数,input张量、hidden张量
小实践举例(RNN和RNNCell)
任务:seq2seq(把hello单词转化成ohlol)
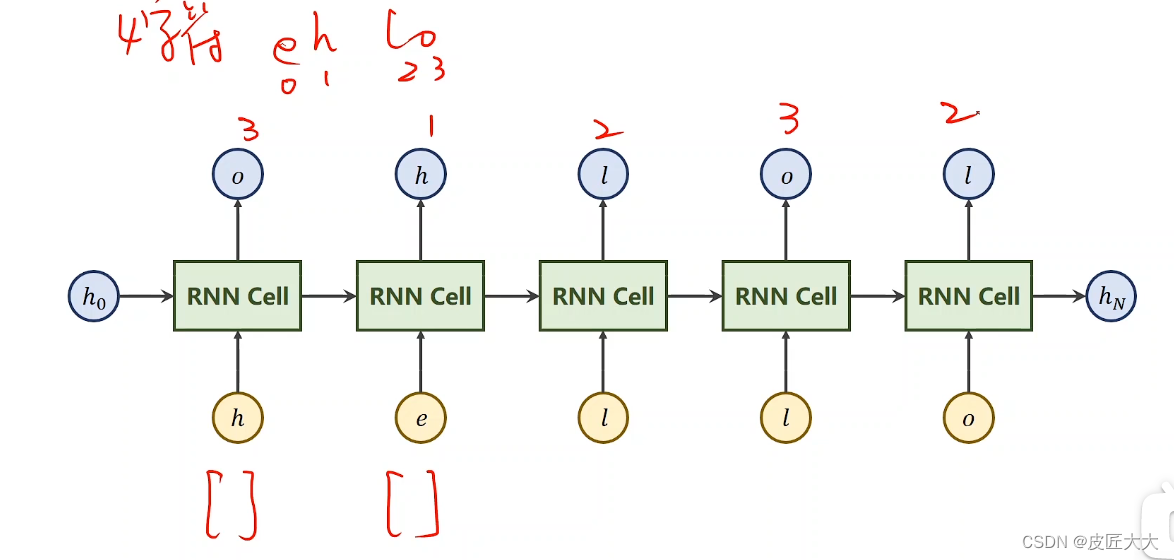
具体过程:
参数:
- input_size = 4,input的字母有多少种,那么每一个token的one_hot向量的维度就是多少
- output_size = 4,同样output的字母有多少种,那么每一个token的one_hot向量的维度就是多少,那么hidden_size = output_size = 4
- seqSize = 5,因为hello有5个字母
- batch = 1,因为目前只有这一个单词
完整代码见链接:
RNN、RNNcell代码基础篇
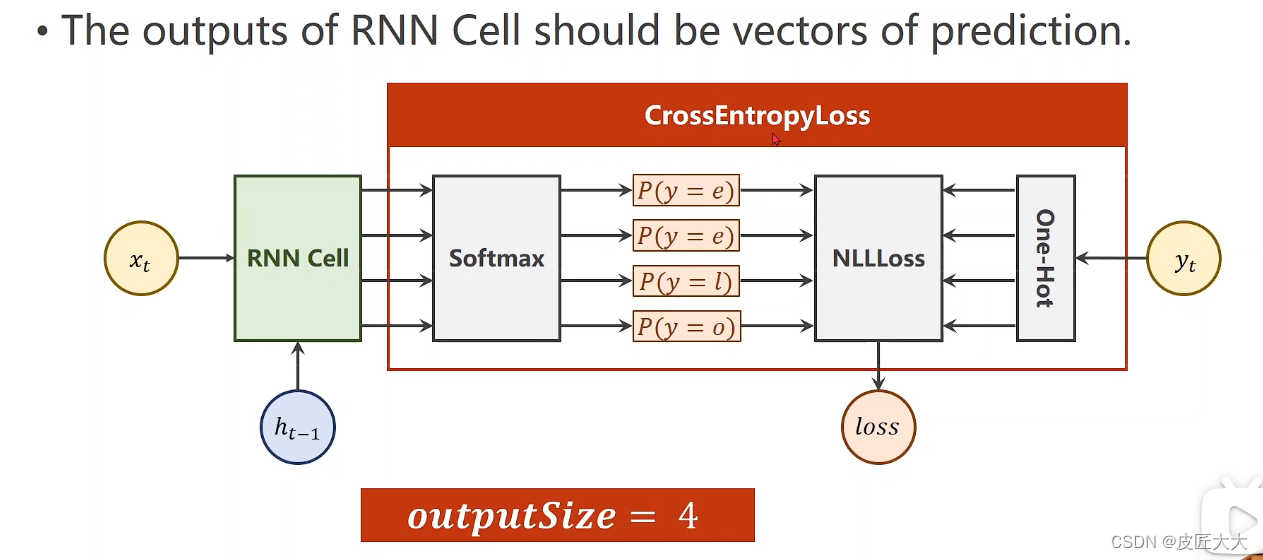
注意想不通的一点是cross-entropy的两个输入(预测的向量,真实的y值)
二者的维度不同!
下图中的标注部分是一个token的one-hot预测向量、和其对应的真实y值,这样就直接cross-entropy了,有什么不明白的(笨!)
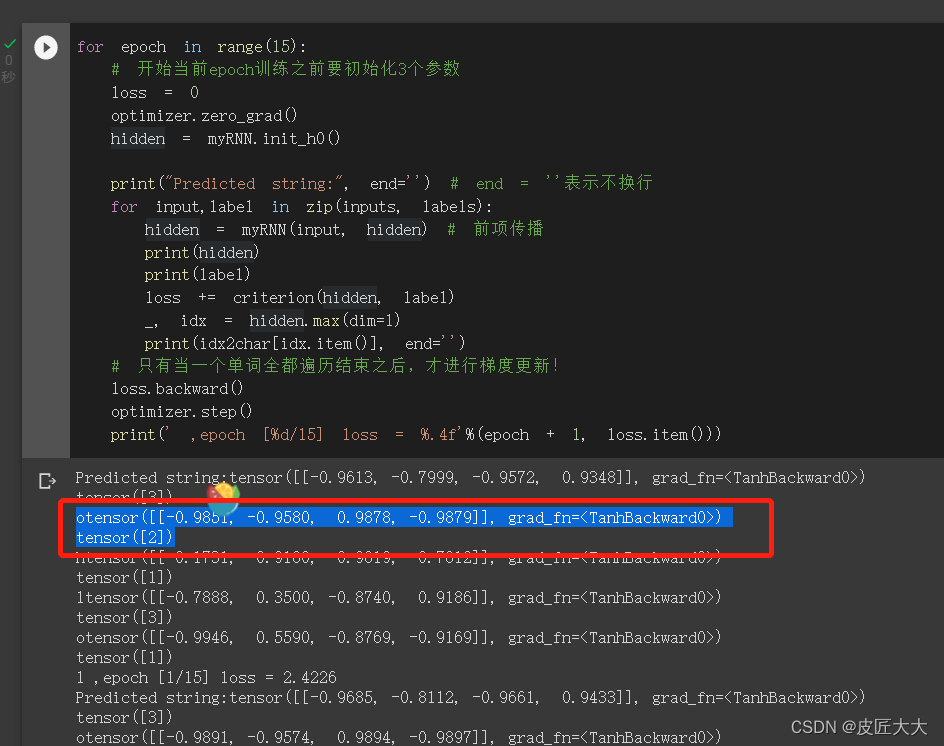
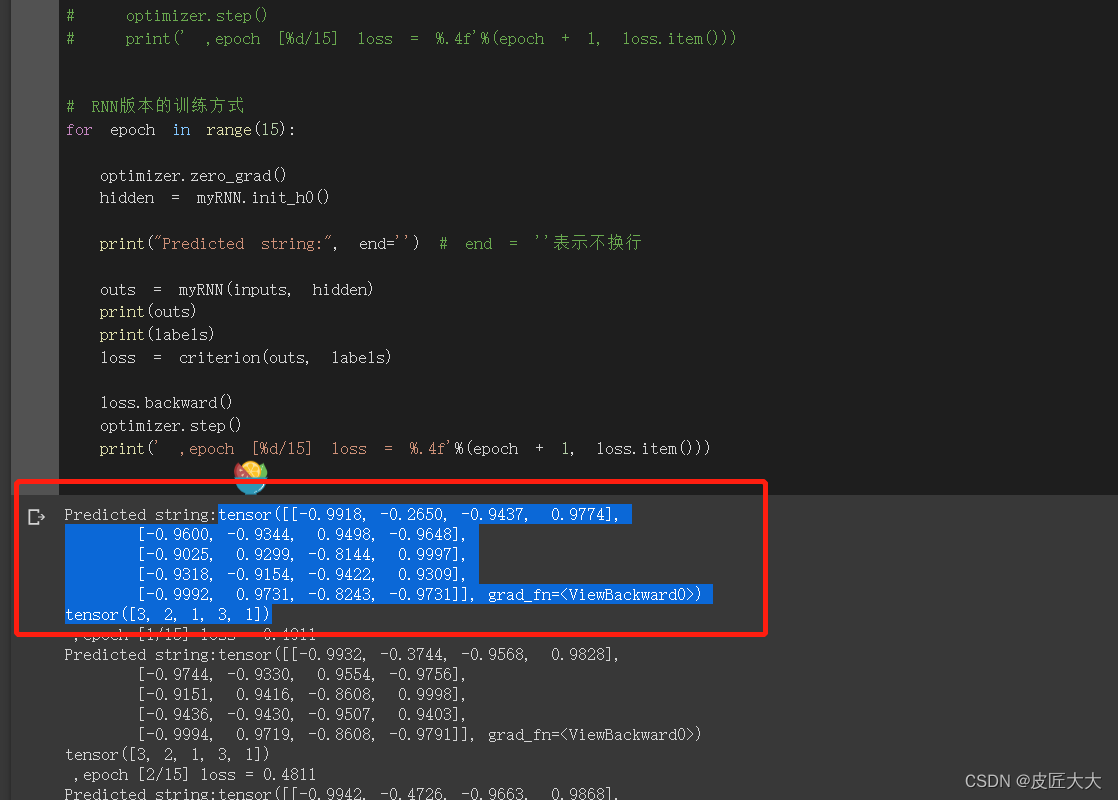
!!!!!注意RNN和RNNcell的cross-entropy的区别,在于
- RNNCell是一个one-hot对应一个数字label
- 而RNN是多个one-hot向量组成的序列,对应一个由多个label数字组成的label序列
添加了embedding的RNN
多了两个地方的修改
- 在RNN之前,添加embedding
- 在RNN之后,添加线性层
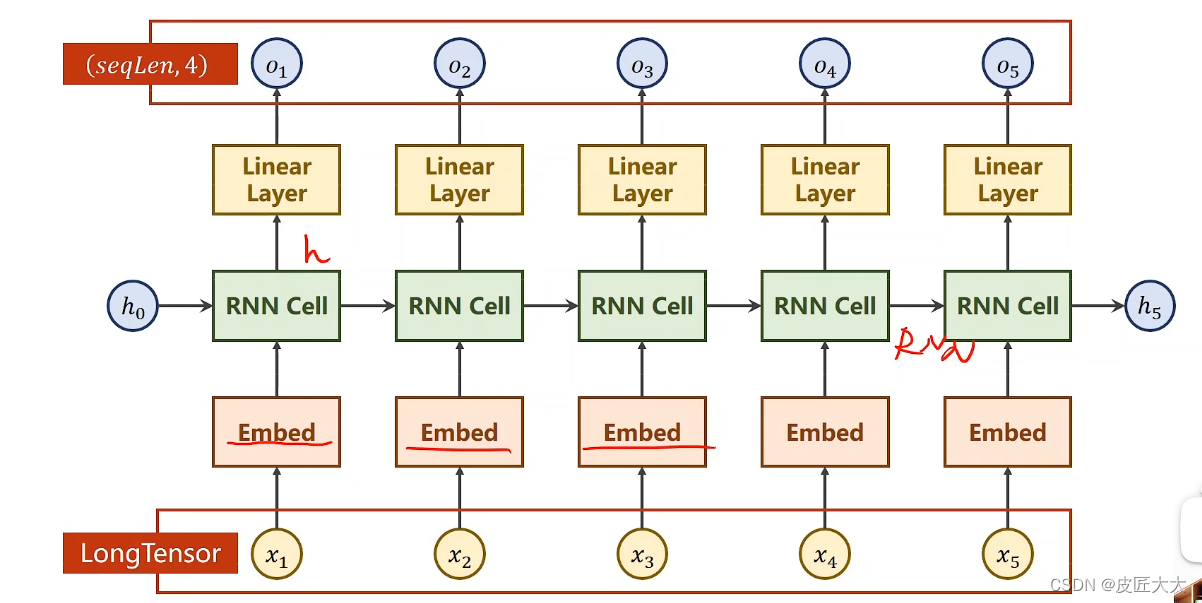
1、embedding的作用,就是把高维的、稀疏的one-hot的张量进行压缩处理,让其变成低纬的密集的矩阵(数据降维)(就是把input_size映射到embedding_size)
embedding层其实就是一个矩阵,它的两个输入为:
1. num_embeddings:就是input的size(矩阵的长)
2. embedding_dim:就是output的size(矩阵的宽)
2、线性层的作用
有时候hidden_size = output_size,但是有时候hidden_size不等于output_size,此时我们用线性层把RNN输出的hidden_size映射到output_size
具体代码链接:RNN、RNNcell代码基础篇
注意点:
- input的张量必须是long类型(为了embedding)
- input不再需要把输入转化为one-hot向量,embedding会自动转
- 注意设置标准的x_data和y_data的格式:
idx2char = ['e','l','h','o']
x_data = [[2,0,1,1,3]] #(batch, seq_len) list
y_data = [3,2,1,3,1] # #(batch * seq_len)
LSTM实践举例
方法1:手动敲一份LSTM的模型出来
具体原理也可以看这里的链接
手写LSTM模型的实践代码
方法2:直接用LSTM的接口,LSTM的参数说明
LSTM使用的官方文档
parameter参数部分和RNN几乎一模一样
不同的是input和output
LSTM的输入有3个(input,(h0,c0))
输出也有3个(output,(hn,cn))
修改的过程就是在原有的RNN+embedding基础上修改两个地方:
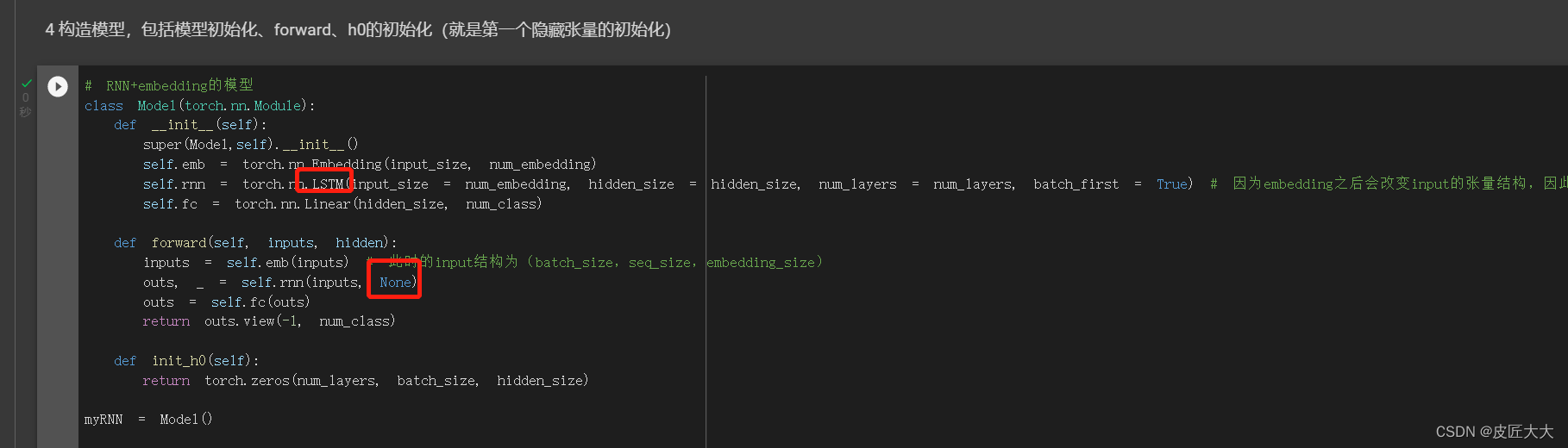
修改完成的代码链接:
具体代码链接:LSTM训练链接
GRU训练实践
原理+参数说明见官方文档:
GRU说明
具体到使用上来,只要把RNN+embedding那个版本的代码的RNN模型改成GRU即可
(GRU的原理很像LSTM,但是调用方式很像RNN。没有像LSTM一样的c0向量,输出也没有c0)
具体代码链接:GRU训练链接
最后
以上就是笨笨滑板最近收集整理的关于RNN笔记(刘二大人)pytorch中构建RNN的第一种方法:RNNcell:pytorch中构建RNN的第二种方法:RNN:小实践举例(RNN和RNNCell)添加了embedding的RNNLSTM实践举例GRU训练实践的全部内容,更多相关RNN笔记(刘二大人)pytorch中构建RNN内容请搜索靠谱客的其他文章。








发表评论 取消回复